溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
注意力機制
顧名思義,注意力機制是本質上是為了模仿人類觀察物品的方式。通常來說,人們在看一張圖片的時候,除了從整體把握一幅圖片之外,也會更加關注圖片的某個局部信息,例如局部桌子的位置,商品的種類等等。在翻譯領域,每次人們翻譯一段話的時候,通常都是從句子入手,但是在閱讀整個句子的時候,肯定就需要關注詞語本身的信息,以及詞語前后關系的信息和上下文的信息。在自然語言處理方向,如果要進行情感分類的話,在某個句子里面,肯定會涉及到表達情感的詞語,包括但不限于“高興”,“沮喪”,“開心”等關鍵詞。而這些句子里面的其他詞語,則是上下文的關系,并不是它們沒有用,而是它們所起的作用沒有那些表達情感的關鍵詞大。
在以上描述下,注意力機制其實包含兩個部分:
注意力機制需要決定整段輸入的哪個部分需要更加關注;
從關鍵的部分進行特征提取,得到重要的信息。
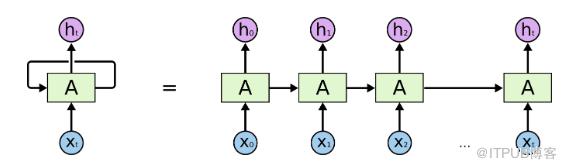
通常來說,在機器翻譯或者自然語言處理領域,人們閱讀和理解一句話或者一段話其實是有著一定的先后順序的,并且按照語言學的語法規則來進行閱讀理解。在圖片分類領域,人們看一幅圖也是按照先整體再局部,或者先局部再整體來看的。再看局部的時候,尤其是手寫的手機號,門牌號等信息,都是有先后順序的。為了模擬人腦的思維方式和理解模式,循環神經網絡(RNN)在處理這種具有明顯先后順序的問題上有著獨特的優勢,因此,Attention 機制通常都會應用在循環神經網絡上面。
雖然,按照上面的描述,機器翻譯,自然語言處理,計算機視覺領域的注意力機制差不多,但是其實仔細推敲起來,這三者的注意力機制是有明顯區別的。
在機器翻譯領域,翻譯人員需要把已有的一句話翻譯成另外一種語言的一句話。例如把一句話從英文翻譯到中文,把中文翻譯到法語。在這種情況下,輸入語言和輸出語言的詞語之間的先后順序其實是相對固定的,是具有一定的語法規則的;
在視頻分類或者情感識別領域,視頻的先后順序是由時間戳和相應的片段組成的,輸入的就是一段視頻里面的關鍵片段,也就是一系列具有先后順序的圖片的組合。NLP 中的情感識別問題也是一樣的,語言本身就具有先后順序的特點;
圖像識別,物體檢測領域與前面兩個有本質的不同。因為物體檢測其實是在一幅圖里面挖掘出必要的物體結構或者位置信息,在這種情況下,它的輸入就是一幅圖片,并沒有非常明顯的先后順序,而且從人腦的角度來看,由于個體的差異性,很難找到一個通用的觀察圖片的方法。由于每個人都有著自己觀察的先后順序,因此很難統一成一個整體。
在這種情況下,機器翻譯和自然語言處理領域使用基于 RNN 的 Attention 機制就變得相對自然,而計算機視覺領域領域則需要必要的改造才能夠使用 Attention 機制。
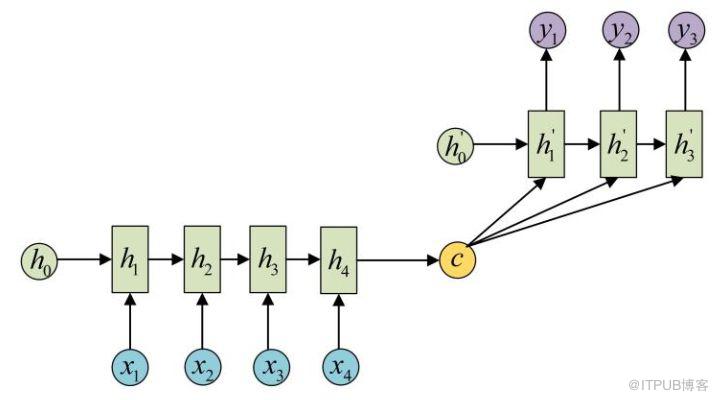
通常來說,RNN 等深度神經網絡可以進行端到端的訓練和預測,在機器翻譯領域和或者文本識別領域有著獨特的優勢。對于端到端的 RNN 來說,有一個更簡潔的名字叫做 sequence to sequence,簡寫就是 seq2seq。顧名思義,輸入層是一句話,輸出層是另外一句話,中間層包括編碼和解碼兩個步驟。
而基于 RNN 的注意力機制指的是,對于 seq2seq 的諸多問題,在輸入層和輸出層之間,也就是詞語(Items)與詞語之間,存在著某種隱含的聯系。例如:“中國” -> “China”,“Excellent” -> “優秀的”。在這種情況下,每次進行機器翻譯的時候,模型需要了解當前更加關注某個詞語或者某幾個詞語,只有這樣才能夠在整句話中進行必要的提煉。在這些初步的思考下,基于 RNN 的 Attention 機制就是:
建立一個編碼(Encoder)和解碼(Decoder)的非線性模型,神經網絡的參數足夠多,能夠存儲足夠的信息;
除了關注句子的整體信息之外,每次翻譯下一個詞語的時候,需要對不同的詞語賦予不同的權重,在這種情況下,再解碼的時候,就可以同時考慮到整體的信息和局部的信息。
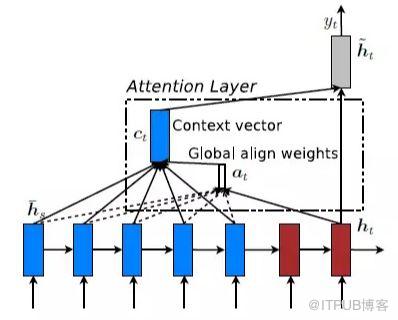
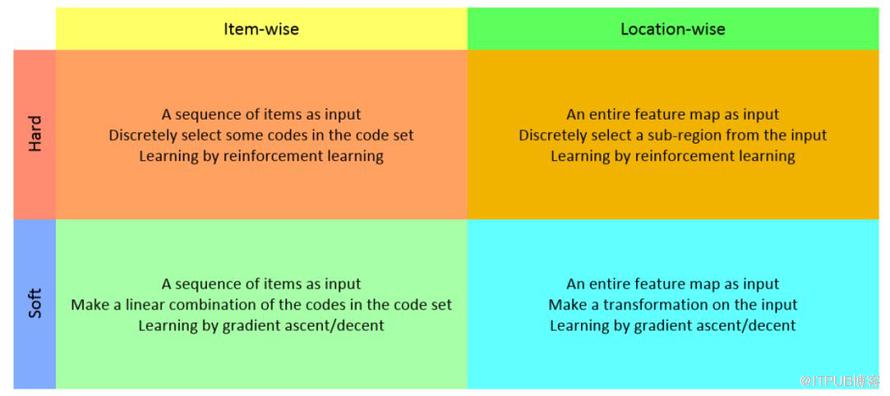
從初步的調研情況來看,注意力機制有兩種方法,一種是基于強化學習(Reinforcement Learning)來做的,另外一種是基于梯度下降(Gradient Decent)來做的。強化學習的機制是通過收益函數(Reward)來激勵,讓模型更加關注到某個局部的細節。梯度下降法是通過目標函數以及相應的優化函數來做的。無論是 NLP 還是 CV 領域,都可以考慮這些方法來添加注意力機制。
下面將會簡單的介紹幾篇近期閱讀的計算機視覺領域的關于注意力機制的文章。
在圖像識別領域,通常都會遇到給圖片中的鳥類進行分類,包括種類的識別,屬性的識別等內容。為了區分不同的鳥,除了從整體來對圖片把握之外,更加關注的是一個局部的信息,也就是鳥的樣子,包括頭部,身體,腳,顏色等內容。至于周邊信息,例如花花草草之類的,則顯得沒有那么重要,它們只能作為一些參照物。因為不同的鳥類會停留在樹木上,草地上,關注樹木和草地的信息對鳥類的識別并不能夠起到至關重要的作用。所以,在圖像識別領域引入注意力機制就是一個非常關鍵的技術,讓深度學習模型更加關注某個局部的信息。
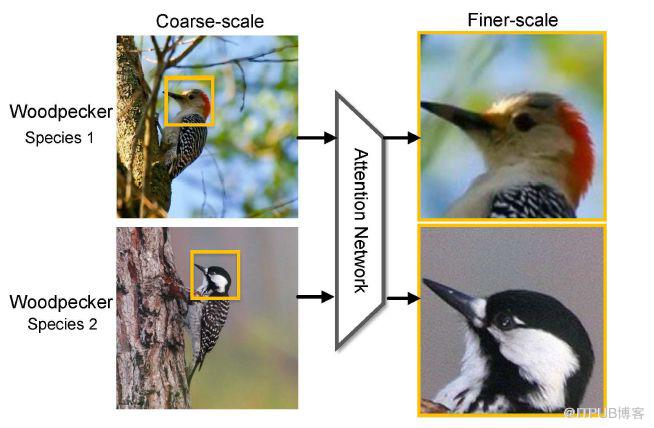
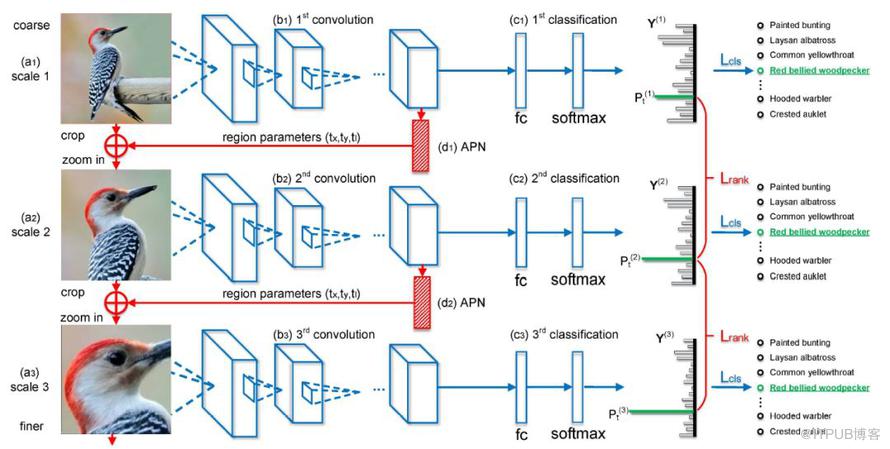
在這篇文章里面,作者們提出了一個基于 CNN 的注意力機制,叫做 recurrent attention convolutional neural network(RA-CNN),該模型遞歸地分析局部信息,從局部的信息中提取必要的特征。同時,在 RA-CNN 中的子網絡(sub-network)中存在分類結構,也就是說從不同區域的圖片里面,都能夠得到一個對鳥類種類劃分的概率。除此之外,還引入了 attention 機制,讓整個網絡結構不僅關注整體信息,還關注局部信息,也就是所謂的 Attention Proposal Sub-Network(APN)。這個 APN 結構是從整個圖片(full-image)出發,迭代式地生成子區域,并且對這些子區域進行必要的預測,并將子區域所得到的預測結果進行必要的整合,從而得到整張圖片的分類預測概率。
RA-CNN 的特點是進行一個端到端的優化,并不需要提前標注 box,區域等信息就能夠進行鳥類的識別和圖像種類的劃分。在數據集上面,該論文不僅在鳥類數據集(CUB Birds)上面進行了實驗,也在狗類識別(Stanford Dogs)和車輛識別(Stanford Cars)上進行了實驗,并且都取得了不錯的效果。

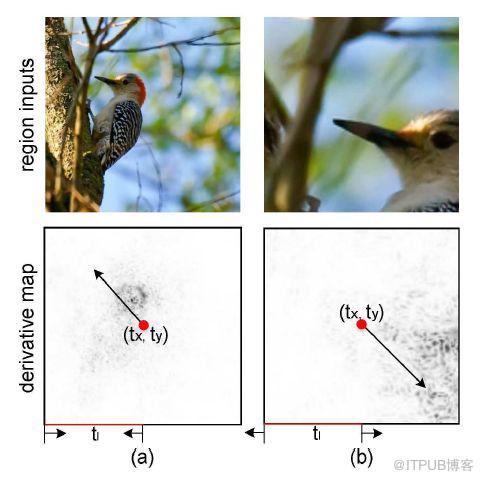
從深度學習的網絡結構來看,RA-CNN 的輸入時是整幅圖片(Full Image),輸出的時候就是分類的概率。而提取圖片特征的方法通常來說都是使用卷積神經網絡(CNN)的結構,然后把 Attention 機制加入到整個網絡結構中。從下圖來看,一開始,整幅圖片從上方輸入,然后判斷出一個分類概率;然后中間層輸出一個坐標值和尺寸大小,其中坐標值表示的是子圖的中心點,尺寸大小表示子圖的尺寸。在這種基礎上,下一幅子圖就是從坐標值和尺寸大小得到的圖片,第二個網絡就是在這種基礎上構建的;再迭代持續放大圖片,從而不停地聚焦在圖片中的某些關鍵位置。不同尺寸的圖片都能夠輸出不同的分類概率,再將其分類概率進行必要的融合,最終的到對整幅圖片的鳥類識別概率。
因此,在整篇論文中,有幾個關鍵點需要注意:
分類概率的計算,也就是最終的 loss 函數的設計;
從上一幅圖片到下一幅圖片的坐標值和尺寸大小。
只要獲得了這些指標,就可以把整個 RA-CNN 網絡搭建起來。



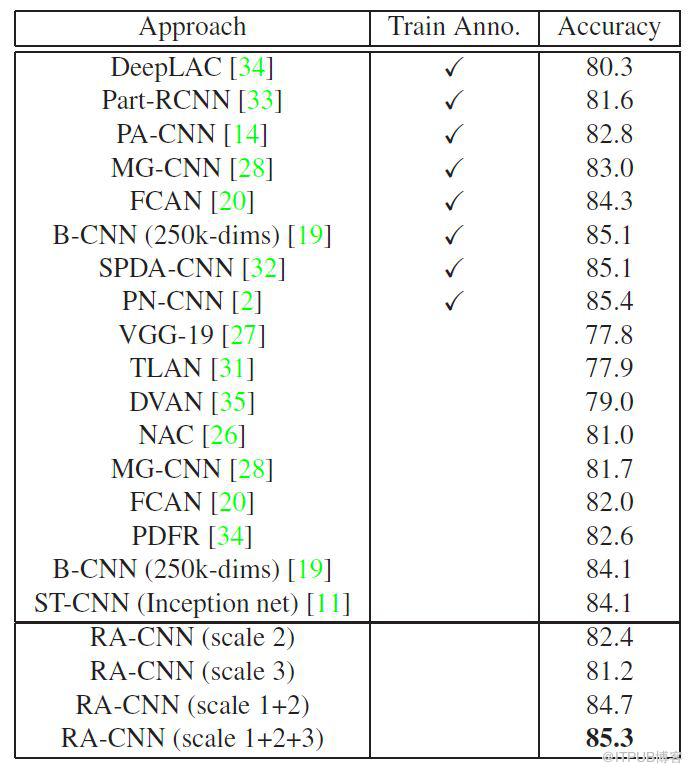
RA-CNN 的實驗效果如下:
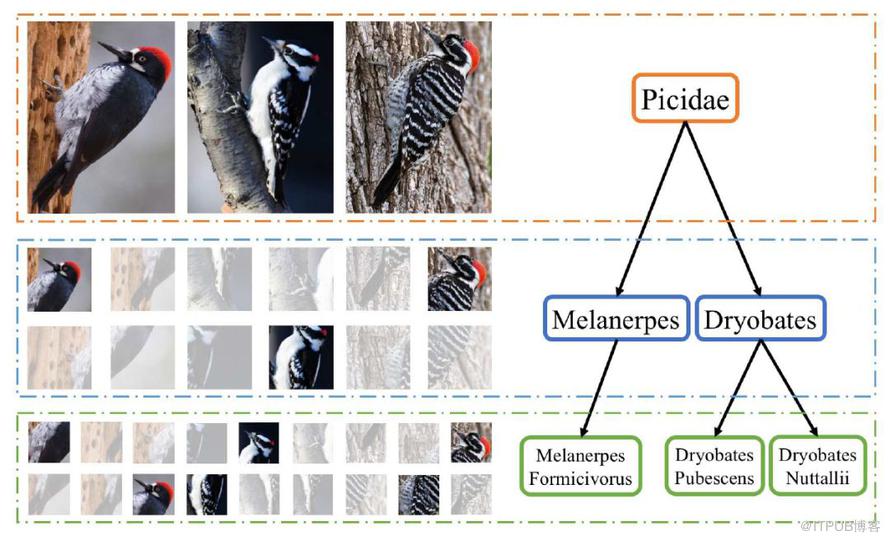
這篇文中同樣做了鳥類的分類工作,與 RA-CNN 不同之處在于它使用了層次的結構,因為鳥類的區分是按照一定的層次關系來進行的,粗糙來看,有科 -> 屬 -> 種三個層次結構。
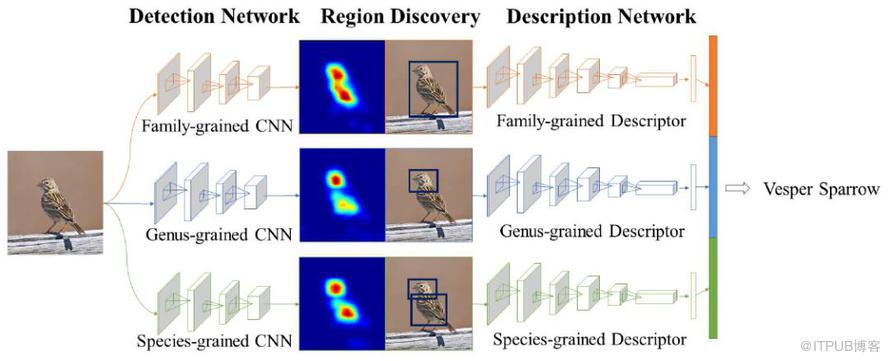
因此,在設計網絡結構的過程中,需要有并行的網絡結構,分別對應科,屬,種三個層次。從前往后的順序是檢測網絡(Detection Network),區域發現(Region Discovery),描述網絡(Description Network)。并行的結構是 Family-grained CNN + Family-grained Descriptor,Genus-grained CNN + Genus-grained Descriptor,Species-grained CNN + Species-grained Descriptor。而在區域發現的地方,作者使用了 energy 的思想,讓神經網絡分別聚焦在圖片中的不同部分,最終的到鳥類的預測結果。

在計算機視覺中引入注意力機制,DeepMind 的這篇文章 recurrent models of visual attention 發表于 2014 年。在這篇文章中,作者使用了基于強化學習方法的注意力機制,并且使用收益函數來進行模型的訓練。從網絡結構來看,不僅從整體來觀察圖片,也從局部來提取必要的信息。
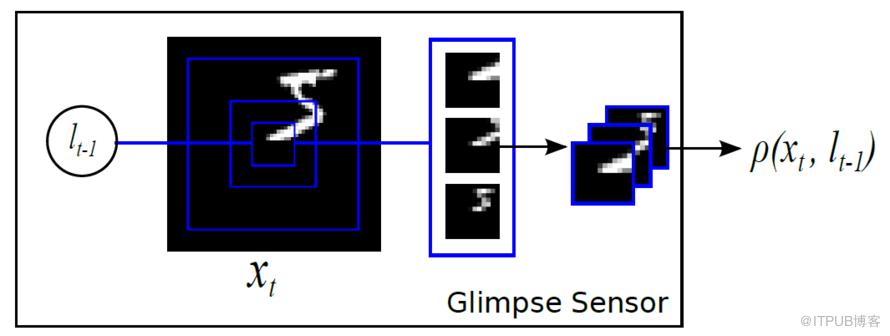
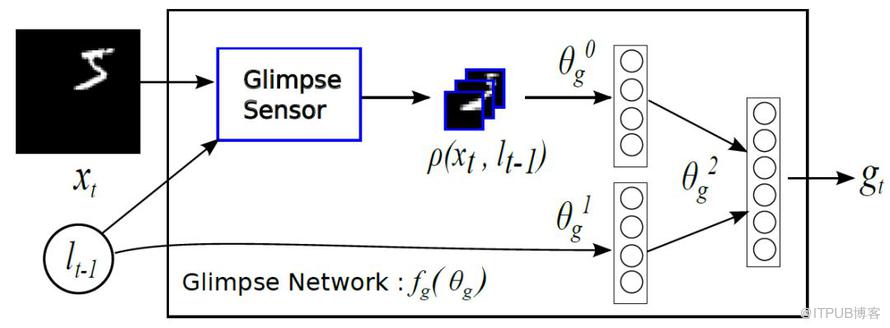
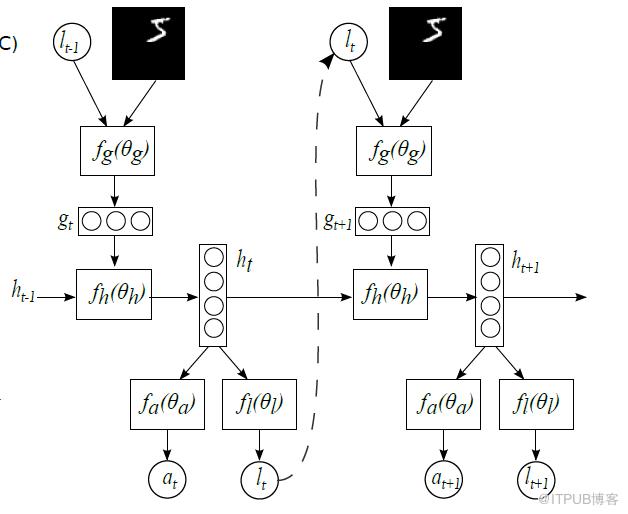
整體來看,其網絡結構是 RNN,上一個階段得到的信息和坐標會被傳遞到下一個階段。這個網絡只在最后一步進行分類的概率判斷,這是與 RA-CNN 不同之處。這是為了模擬人類看物品的方式,人類并非會一直把注意力放在整張圖片上,而是按照某種潛在的順序對圖像進行掃描。Recurrent Models of Visual Attention 本質上是把圖片按照某種時間序列的形式進行輸入,一次處理原始圖片的一部分信息,并且在處理信息的過程中,需要根據過去的信息和任務選擇下一個合適的位置進行處理。這樣就可以不需要進行事先的位置標記和物品定位了。
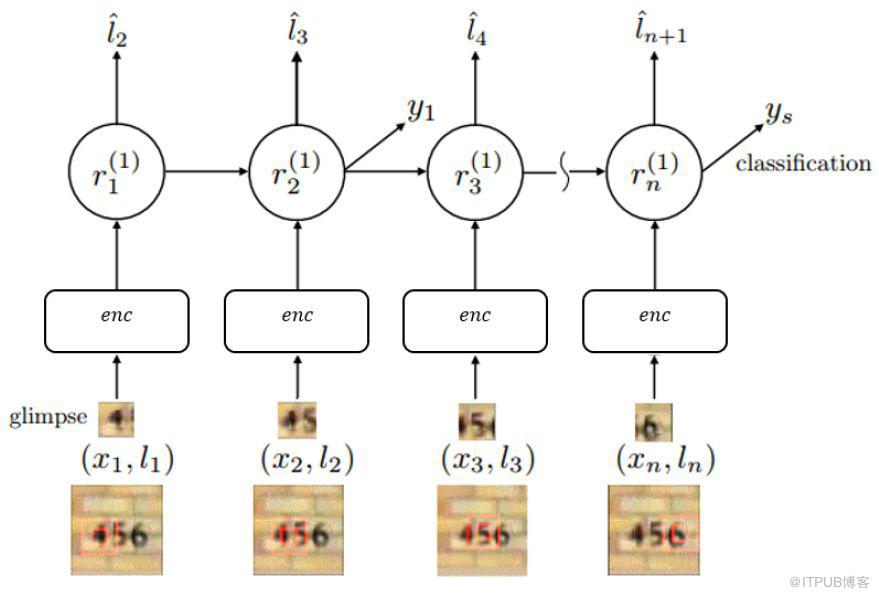


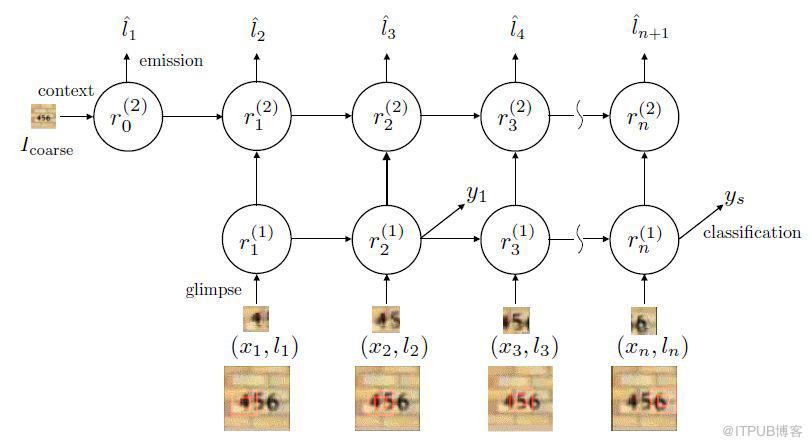
在門牌識別里面,該網絡是按照從左到右的順序來進行圖片掃描的,這與人類識別物品的方式極其相似。除了門牌識別之外,該論文也對手寫字體進行了識別,同樣取得了不錯的效果。

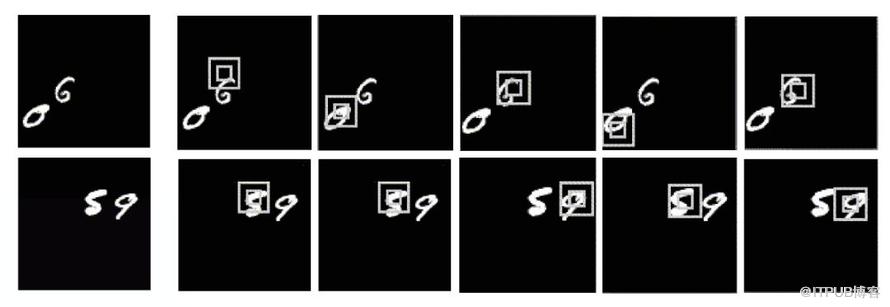
實驗效果如下:
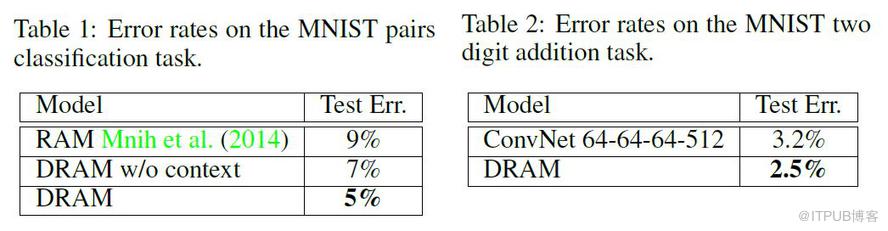
本篇 文章初步介紹了計算機視覺中的 Attention 機制,除了這些方法之外,應該還有一些更巧妙的方法,希望各位讀者多多指教。
Look Closer to See Better:Recurrent Attention Convolutional Neural Network for Fine-grained Image Recognition,CVPR,2017.
Recurrent Models of Visual Attention,NIPS,2014
GitHub 代碼:Recurrent-Attention-CNN,github.com/Jianlong-Fu/
Multiple Granularity Descriptors for Fine-grained Categorization,ICCV,2015
Multiple Object Recognition with Visual Attention,ICRL,2015
Understanding LSTM Networks,Colah's Blog,2015,colah.github.io/posts/2
Survey on the attention based RNN model and its applications in computer vision,2016
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





