溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
貝葉斯定理相信不少人都接觸過,這個看似只屬于數學領域的定理,在AI產品經理看來有怎樣的魅力呢?

我們常常遇到這樣的場景。與友人聊天時,一開始可能不知道他要說什么,但是他說了一句話之后,你就能猜到接下來他要講什么內容。友人給的信息越多,我們越能夠推斷出他想表達的含義,這也是貝葉斯定理所闡述的思考方式。
貝葉斯定理得以廣泛應用是因為它符合人類認知事物的自然規律。
我們并非生下來就知道一切事情的內在的規律,大多數時候,我們面對的是信息不充分、不確定的情況。這個時候我們只能在有限資源的情況下,作出決定,再根據后續的發展進行修正。
貝葉斯分類是一類分類算法的總稱,這類算法均以“貝葉斯定理”為基礎,以“特征條件獨立假設”為前提。而樸素貝葉斯分類是貝葉斯分類中最常見的一種分類方法,同時它也是最經典的機器學習算法之一。
在很多場景下處理問題直接又高效,因此在很多領域有著廣泛的應用,如垃圾郵件過濾、文本分類與拼寫糾錯等。同時對于產品經理來說,貝葉斯分類法是一個很好的研究自然語言處理問題的切入點。
樸素貝葉斯分類是一種十分簡單的分類算法,說它十分簡單是因為它的解決思路非常簡單。即對于給出的待分類項,求解在此項出現的條件下各個類別出現的概率,哪個最大,就認為此待分類項屬于哪個類別。
舉個形象的例子,若我們走在街上看到一個黑皮膚的外國友人,讓你來猜這位外國友人來自哪里。十有八九你會猜是從非洲來的,因為黑皮膚人種中非洲人的占比最多,雖然黑皮膚的外國人也有可能是美洲人或者是亞洲人。但是在沒有其它可用信息幫助我們判斷的情況下,我們會選擇可能出現的概率最高的類別,這就是樸素貝葉斯的基本思想。
值得注意的是,樸素貝葉斯分類并非是瞎猜,也并非沒有任何理論依據。它是以貝葉斯理論和特征條件獨立假設為基礎的分類算法。
想要弄明白算法的原理,首先需要理解什么是“特征條件獨立假設”以及“貝葉斯定理”,而貝葉斯定理又牽涉到“先驗概率”、“后驗概率”及“條件概率”的概念。
如下圖所示,雖然概念比較多但是都比較容易理解,下面我們逐個詳細介紹。
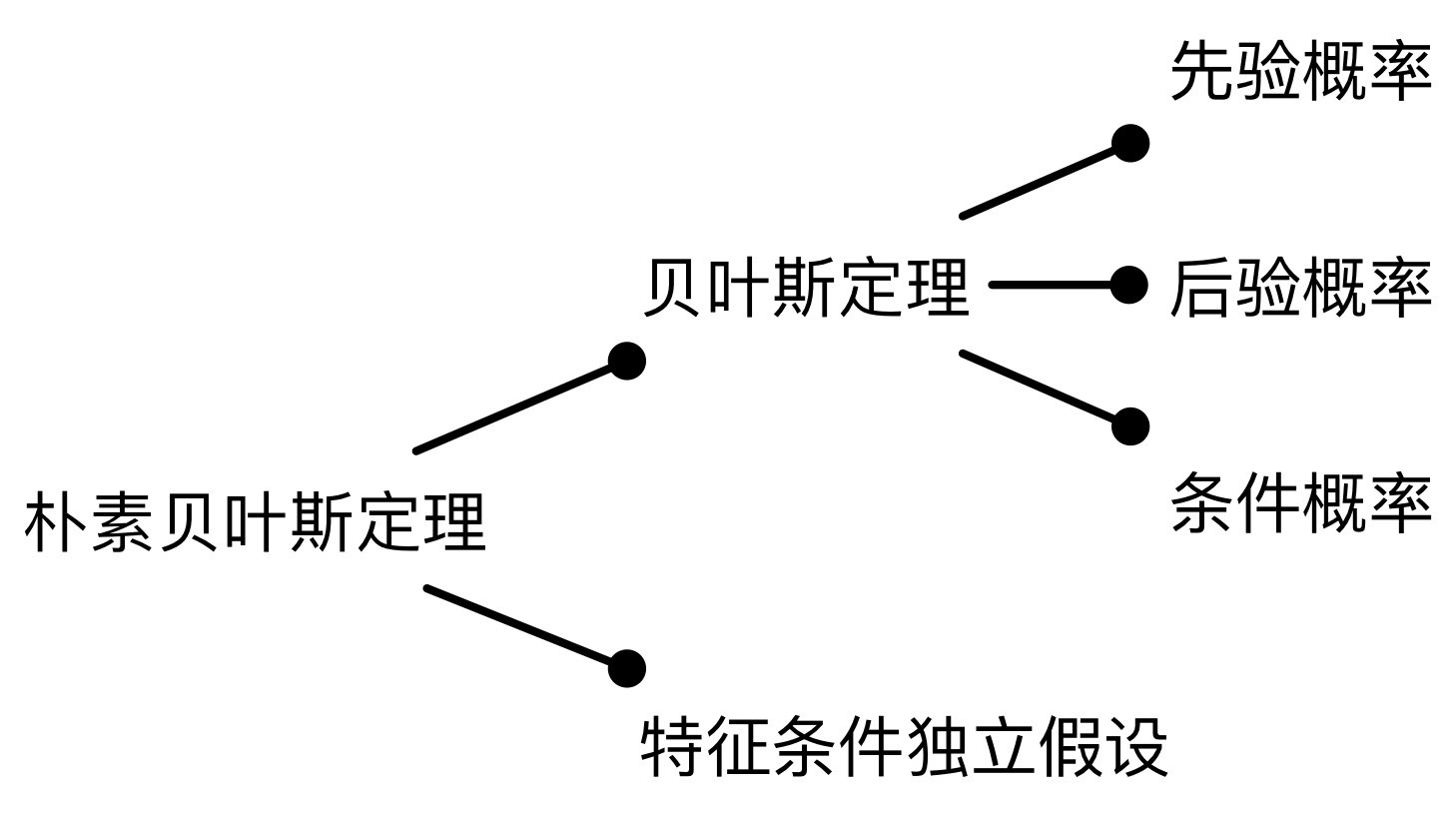
特征條件獨立假設是貝葉斯分類的基礎,意思是假定該樣本中每個特征與其他特征之間都不相關。
例如在預測信用卡客戶逾期的例子中,我們會通過客戶的月收入、信用卡額度、房車情況等不同方面的特征綜合判斷。兩件看似不相關的事情實際上可能存在內在聯系,就像蝴蝶效應一樣。普遍情況下,銀行批給收入較高的客戶的信用卡額度也比較高。
同時收入高也代表這個客戶更有能力購買房產,所以這些特征之間存在一定的依賴關系,某些特征是由其他特征決定的。
然而在樸素貝葉斯算法中,我們會忽略這種特征之間的內在關系,直接認為客戶的月收入、房產與信用卡額度之間沒有任何關系,三者是各自獨立的特征。
接下來我們重點講解什么是“理論概率”與“條件概率”,以及“先驗概率”與“后驗概率”之間的區別。
首先我們進行一個小實驗。
假設將一枚質地均勻的硬幣拋向空中,理論上,因為硬幣的正反面質地均勻,落地時正面朝上或反面朝上的概率都是50%。這個概率不會隨著拋擲次數的增減而變化,哪怕拋了10次結果都是正面朝上,下一次是正面朝上的概率仍然是50%。
但在實際測試中,如果我們拋100次硬幣,正面朝上和反面朝上的次數通常不會恰好都是50次。有可能出現40次正面朝上和60次反面朝上的情況,也有可能出現35次正面朝上和65次反面朝上的情況。
只有我們一直拋,拋了成千上萬次,硬幣正面朝上與反面朝上的次數才會逐漸趨向于相等。
因此,我們說“正面朝上和反面朝上各有50%的概率”這句話所指的概率是理論上的客觀概率。只有當拋擲次數接近無數次時,才會達到這種理想中的概率。在理論概率下,盡管拋10次硬幣,前面5次都是正面朝上,第6次是反面朝上的概率仍然是50%。
但是在實際中,拋過硬幣的人都有這樣的感覺——如果出現連續5次正面朝上的情況,下一次是反面朝上的可能性極大。大到什么程度?有沒有什么方法可以求出實際的概率呢?
為了解決這個問題,一位名叫托馬斯·貝葉斯(ThomasBayes)的數學家發明了一種方法用于計算“在已知條件下,另外一個事件發生”的概率。該方法要求我們先預估一個主觀的先驗概率,再根據后續觀察到的結果進行調整。隨著調整次數的增加,真實的概率會越來越精確。
這句話怎么理解呢?
我們通過一個坐地鐵的例子解釋這句話的含義。深圳地鐵一號線從車公廟出發至終點站共有18站,每天早上小林要從車公廟出發經過5個站到高新園上班,如下圖所示:
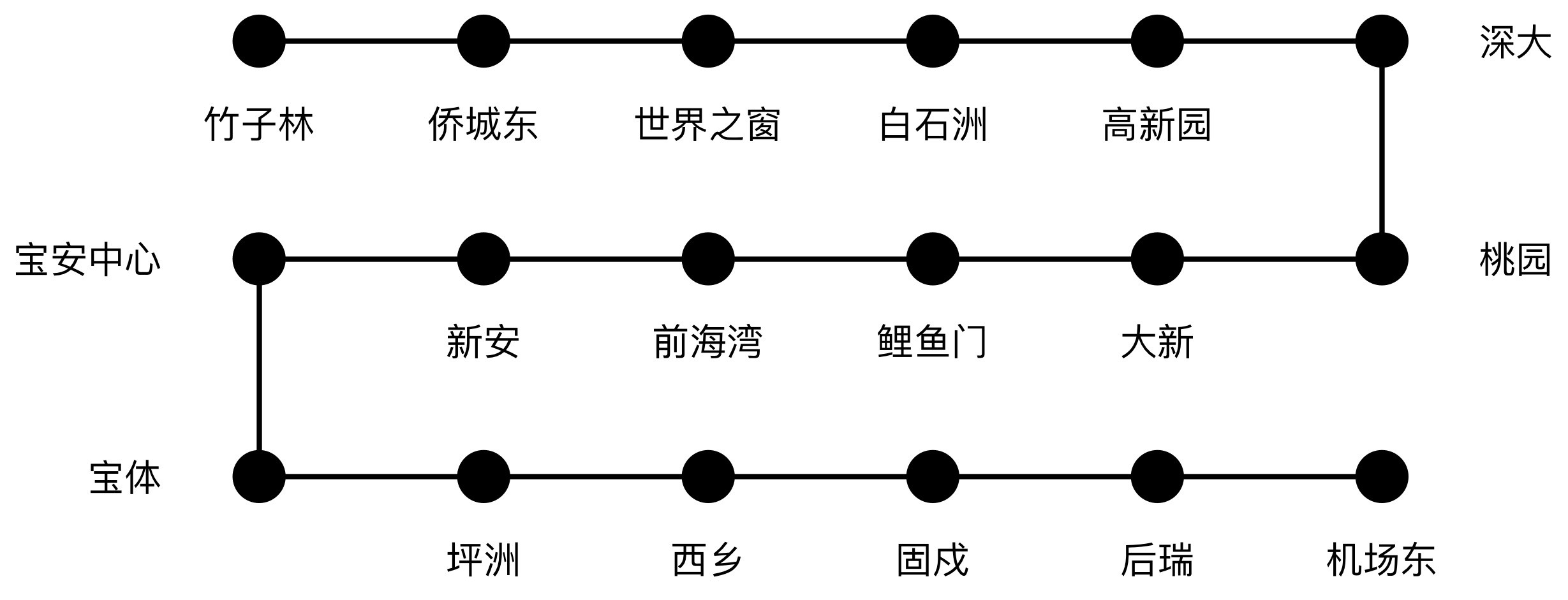
某天早高峰,小林被站立的人群遮擋住視線并且戴著耳機聽不到報站的內容,因此他不知道列車是否到達高新園站。
如果下一站列車到站時,他直接出站,理論上他正好到高新園站的概率只有1/18,出對站的概率非常小。這時候小林恰巧在人群中看到一個同事,他正走出站臺。
小林心想,盡管不知道這個同事要去哪里,但在早高峰時段,同事去公司的概率顯然更高。因此在獲得這個有效信息后,小林跟隨出站,正好到達高新園站——這種思考方式就是貝葉斯定理所闡述的思考方式。
在概率論與統計學中,貝葉斯定理描述了一個事件發生的可能性,這個可能性是基于事先掌握了一些與該事件相關的情況從而推測的。
假設癌癥是否會發病與每個人的年齡有關。如果使用貝葉斯定理,當我們知道一個人的年齡,可以用于更準確地評估他得癌癥是否會發病的概率。也就是說,貝葉斯理論是指根據一個已發生事件的概率,計算另一個事件的發生概率。
從數學上貝葉斯理論可以表示為:
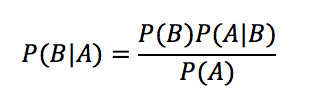
這時候我們再來看貝葉斯定理,這個公式說明了兩個互換的條件概率之間的關系,它們通過聯合概率關聯起來。在這種情況下,若知道P(A|B) 的值,就能夠計算P(B|A)的值。
因此貝葉斯公式實際上闡述了這么一個事情,如下圖所示:
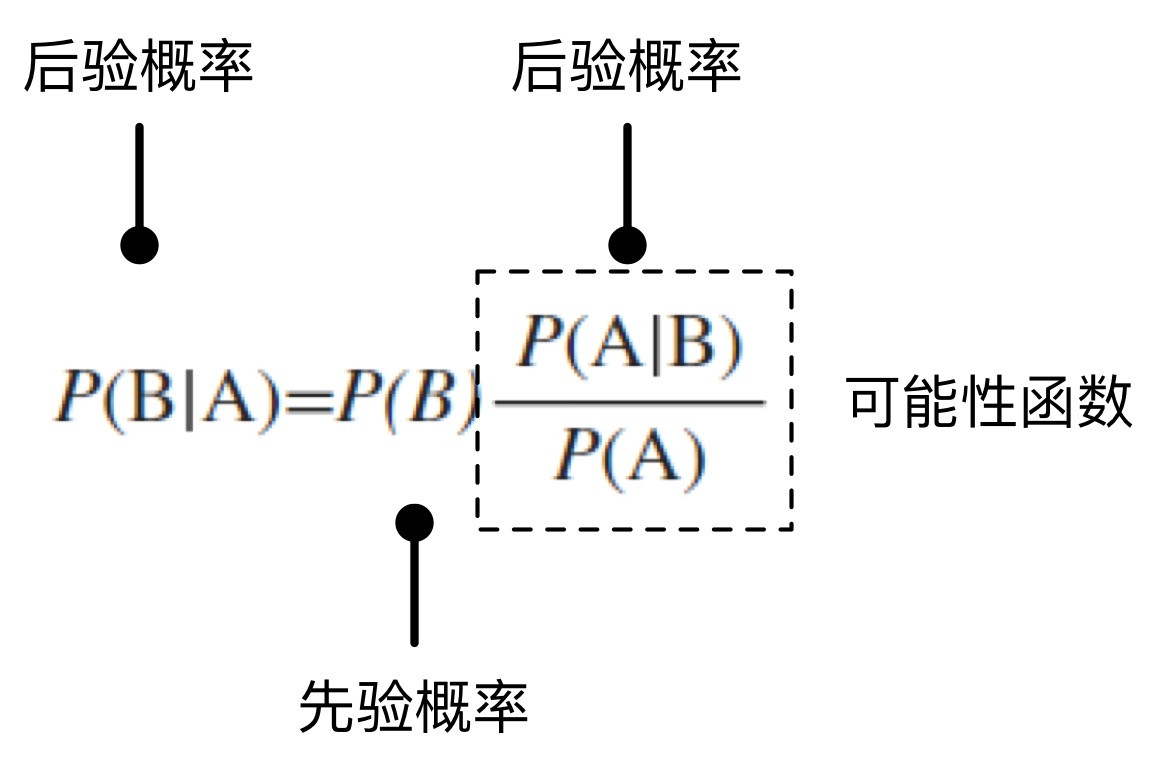
我們可以用文氏圖可以加深對貝葉斯定理的理解,如下圖所示:
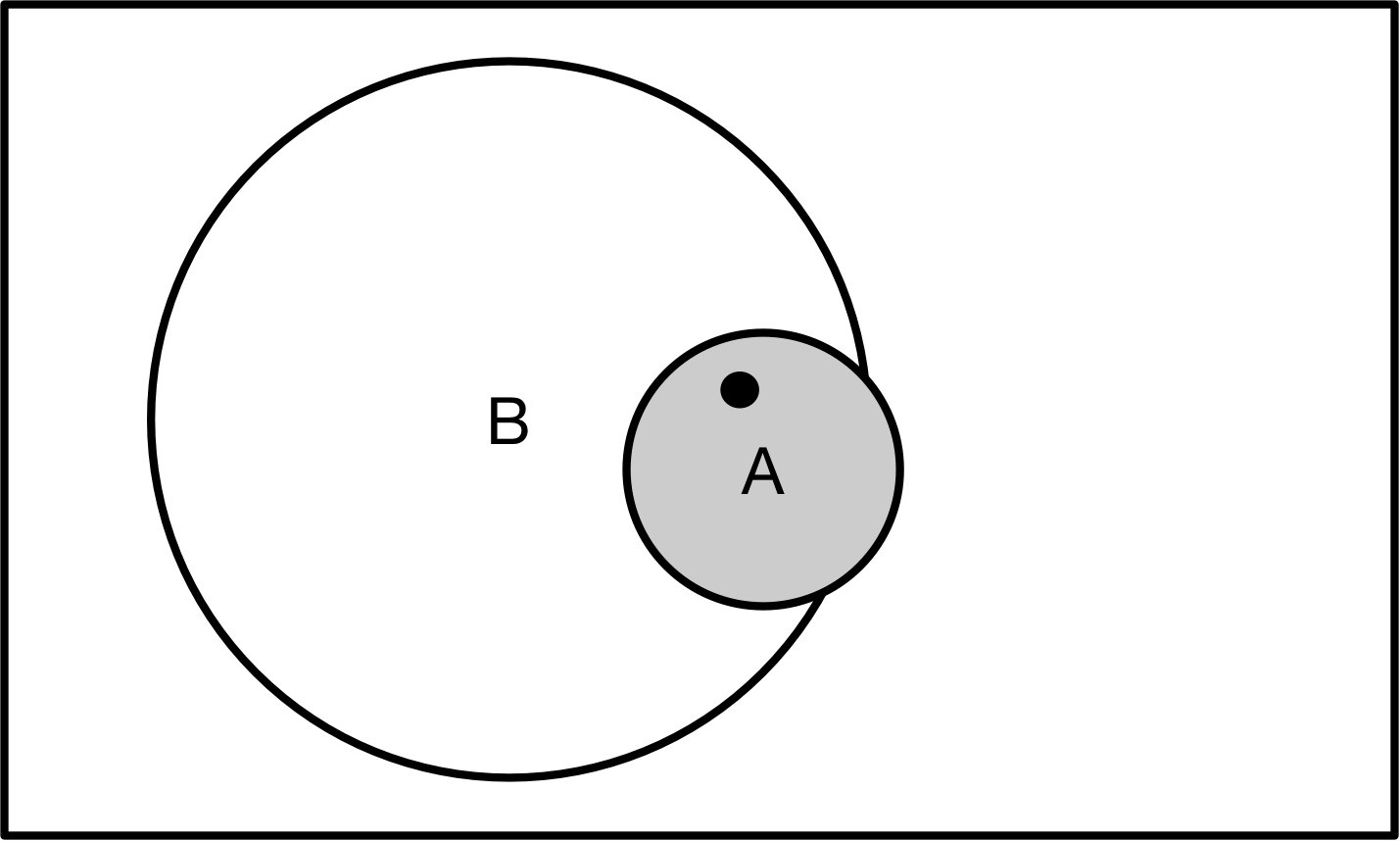
上述例子中小林剛好在早高峰時段看到同事出站,代表出現了新的信息。就像是上圖中已知黑點已經落入A區域了,由于A區域大部分區域與B區域相交,因此推斷黑點也在B區域的概率會變大。我們想獲得的結果其實是P(B|A),即我們想知道,在考慮了一些現有的因素后,這個隨機事件會以多大概率出現。
參考這個概率結果,在很多事情上我們可以有針對性地作出決策。我們需要同時知道P(B)、P(A|B)與P(A)才能算出目標值P(B|A),但是P(A)的值似乎比較難求。
仔細想一想,P(A)與P(B)之間似乎沒有任何關聯,兩者本身就是獨立事件,無論P(B)的值是大還是小,P(A)都是固定的分母。也就是說我們計算P(A)各種取值的可能性并不會對各結果的相對大小產生影響,因此可以忽略P(A)的取值。
假設P(A)的取值為m,P(B)的可能取值為b1、b2或者是b3,已知:
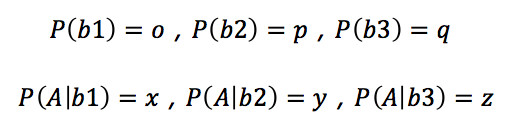
那么計算P(B|A)時,分別會得到結果:
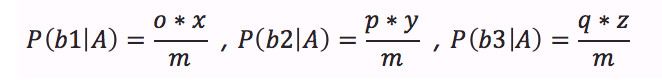
且由于P(b1|A)、P(b2|A)與P(b3|A)三者之和一定為1,因此可以得出ox+py+qz=m。即使m的值不知道也沒關系,因為ox,py,qz的值都是可以計算出來的,m自然也就知道了。剩下的工作就是計算P(B)、P(A|B),而這兩個概率必須要通過我們手上有的數據集來進行估計。
關于貝葉斯算法有一段小插曲。貝葉斯算法被發明后,曾有接近200年的時間無人問津。
因為經典統計學在當時完全能夠解決客觀上能夠解釋的簡單概率問題;而且相比需要靠主觀判斷的貝葉斯算法,顯然當時的人們更愿意接受建立在客觀事實上的經典統計學,他們更愿意接受一個硬幣無論拋多少次后正反面朝上的概率都是50%的事實。
但我們生活中還存在很多無法預知概率的復雜問題,例如臺風侵襲、地震規律等等。經典統計學在面對復雜問題時,往往無法獲得足夠多的樣本數據,導致其無法推斷總體規律。總不能說每天預測臺風來的概率都是50%,只有來或者不來兩種情況。
數據的稀疏性令貝葉斯定理頻頻碰壁。隨著近代計算機技術的飛速發展后,數據的大量運算不再是困難的事情,貝葉斯算法這才被人們重新重視起來。
講到這里部分讀者可能會問,雖然貝葉斯定理模擬了人類思考的過程,但是它又能夠幫助我們解決什么樣的問題呢?我們先來看一個幾乎是講到貝葉斯定理時必定會提到的經典案例。
在疾病檢測領域,假設某種疾病在所有人群中的感染率是0.1%,醫院現有的技術對于該疾病檢測準確率能夠達到99%。也就是說,在已知某人已經患病情況下,有99%的可能性檢查出陽性;而正常人去檢查有99%的可能性是正常的。如果從人群中隨機抽一個人去檢測,醫院給出的檢測結果為陽性,這個人實際得病的概率是多少?
也許很多讀者都會脫口而出 “99%”。但真實的得病概率其實遠低于此,原因在于很多讀者將先驗概率和后驗概率搞混了。
如果用A表示這個人患有該疾病,用B表示醫院檢測的結果是陽性,那么 P(B|A)=99%表示的是“已知一個人已經得病的情況下醫院檢測出陽性的概率”。而我們現在問的是“對于隨機抽取的這個人,已知檢測結果為陽性的情況下這個人患病的概率”,即P(A|B),通過計算可得P(A|B)=9%。所以即使被醫院檢測為陽性,實際患病的概率其實還不到10%,有很大可能是假陽性。因此需要通過復診,引入新的信息,才有更大把握確診。
通過以上例子可以看出,生活中我們經常會把先驗概率與后驗概率弄混淆,從而得出錯誤的判斷。貝葉斯定理正是幫我們理清概率的先后條件之間的邏輯關系,并得到更精確的概率。
實際上,這個定理所闡述的核心思想對 產品經理的思考方式也有很大的啟發:
一方面是我們要搞清楚需求場景中的先驗概率是什么?后驗概率是什么?不要被數據的表象蒙蔽了雙眼;
另一方面我們可以借助貝葉斯定理搭建一個思考的框架——在這個框架中需要不斷調整我們對某事物的看法,在經過一系列的新的事情被證實后,才形成比較穩定、正確的看法。
當我們的腦子里有新想法出現時,大多數情況下,我們只能根據經驗大概判斷某個產品靠譜不靠譜,投入到市場中反響有多大沒有人能夠說清楚。
因此很多時候我們需要嘗試,需要做一個簡單的版本投入到市場上快速驗證自己的想法;然后不斷想辦法獲得“事件B”,不斷增加新產品的成功率——這樣我們的產品才有可能獲得成功。
因此 “小步快跑,快速迭代”才是提升容錯率最好的辦法。
http://www.woshipm.com/ai/2850961.html
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





