溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Oracle Lead/Last函數
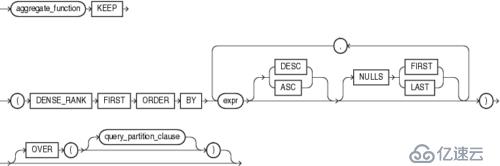
Purpose
FIRST and LAST are very similar functions.Both are aggregate and analytic functions that operate on a set of values froma set of rows that rank as the FIRST or LAST withrespect to a given sorting specification. If only one row ranks as FIRSTor LAST, then the aggregate operates on the set with only one element.
If you omit the OVERclause, then the FIRST and LAST functions are treated as aggregate functions. You can use thesefunctions as analytic functions by specifying the OVER clause. Thequery_partition_clause is the only part of the OVER clause valid with thesefunctions. If you include the OVER clause but omit thequery_partition_clause, then the function is treated as an analytic function, but the window defined for analysis is theentire table.
中文說明:省略over子句,Fisrt/Last被當做聚合函數使用,見示例1;含over關鍵字但沒query_partition_clause,Fisrt/Last被當做分析函數使用,分析的窗口是整個表,見示例2。
These functions take as an argument anynumeric data type or any nonnumeric data type that can be implicitly convertedto a numeric data type. The function returns the same data type as the numericdata type of the argument.
When you need a value from the first orlast row of a sorted group, but the needed value is not the sort key, the FIRSTand LAST functions eliminate the need for self-joins or views and enable betterperformance.
The aggregate_functionargument is any one of the MIN, MAX, SUM, AVG, COUNT, VARIANCE, or STDDEVfunctions. It operates on values from the rows thatrank either FIRST or LAST. If only one row ranks as FIRST or LAST, then theaggregate operates on a singleton (nonaggregate) set.
The KEEP keyword is for semantic clarity.It qualifies aggregate_function, indicating that only the FIRST or LAST valuesof aggregate_function will be returned.
DENSE_RANK FIRST or DENSE_RANK LASTindicates that Oracle Database will aggregate over only those rows with theminimum (FIRST) or the maximum (LAST) dense rank (also called olympic rank).
min(job_id) keep(dense_rank first order bycount(job_id) desc) over(partition by department_id)
語義:按每個部門查找工種人數最多的工種。
min:例如某個部門,人數占用最多的工種有兩個,例如某個部門A工種3人,B工種3人,這時用min返回的值就是A,相應的用max返回的值就是B。若你想用AVG這類函數,則會報錯,invalid number。其實作用就是防止返回兩個值,也不是網上說的,完全沒有意義(max和min結果是不一樣的)。
keep:關鍵字。
dense_rank:排序操作,換成row_number試了下,直接拋出異常。
over:即是分析函數分析的窗口,省略over及其后面語句,則整個結果聚合(aggregate)
select max(e.job_id) keep(dense_rank lastorder by count(job_id) desc), min(e.job_id) keep(dense_rank last order by count(job_id) desc), max(e.job_id) keep(dense_rank first order by count(job_id) desc), min(e.job_id) keep(dense_rank first order by count(job_id) desc) from employees e group by e.department_id, e.job_id;
返回的結果集如下
SA_REP AC_ACCOUNT SA_REP SA_REP
發現:整個表的聚合,也驗證了max和min的結果有時不一致。
select distinct department_id, --count(job_id), min(job_id) keep(dense_rank first order by count(job_id) desc)over(partition by department_id) job_id from employees group by department_id, job_id order by 1;
分析窗口:以部門分組
返回結果集如下
1 10 AD_ASST
2 20 MK_MAN
3 30 PU_CLERK
4 40 HR_REP
5 50 SH_CLERK
6 60 IT_PROG
7 70 PR_REP
8 80 SA_REP
9 90 AD_VP
10 100 FI_ACCOUNT
11 110 AC_ACCOUNT
12 SA_REP
返回每個部門的工種人數最多的工種,注意部門ID為空也返回了,這個是boss。
with t as (select department_id, job_id, count(job_id)cnt from employees group by department_id, job_id) select department_id, max(job_id) --再次聚合 from t where (department_id, cnt) in (selectdepartment_id, max(cnt) from t group by department_id) group by department_id order by 1;
1 10 AD_ASST
2 20 MK_REP
3 30 PU_CLERK
4 40 HR_REP
5 50 ST_CLERK
6 60 IT_PROG
7 70 PR_REP
8 80 SA_REP
9 90 AD_VP
10 100 FI_ACCOUNT
11 110 AC_MGR
總結:1. boss這個部門,即部門為空,沒有返回;
2.某個部門工種人數最多的,有兩個工種,不得不再次進行聚合。
3.代碼較為繁瑣。
select department_id, job_id from (select e.department_id, e.job_id, count(e.job_id), row_number() over(partition bydepartment_id order by count(job_id) desc) rk from employees e group by e.department_id, e.job_id) where rk = 1;
1 10 AD_ASST
2 20 MK_MAN
3 30 PU_CLERK
4 40 HR_REP
5 50 ST_CLERK
6 60 IT_PROG
7 70 PR_REP
8 80 SA_REP
9 90 AD_VP
10 100 FI_ACCOUNT
11 110 AC_ACCOUNT
12 SA_REP
總結:1.用row_number排序,然后使用外查詢過濾row_number為1的;
2.boss這個人包含的結果返回。
select /*distinct*/ department_id, count(job_id), min(job_id) keep(dense_rank first order by count(job_id) desc)over(partition by department_id) job_id from employees group by department_id, job_id order by 1;
1 10 1 AD_ASST
2 20 1 MK_MAN
3 20 1 MK_MAN
4 30 5 PU_CLERK
5 30 1 PU_CLERK
6 40 1 HR_REP
7 50 20 SH_CLERK
8 50 20 SH_CLERK
9 50 5 SH_CLERK
10 60 5 IT_PROG
11 70 1 PR_REP
12 80 5 SA_REP
13 80 29 SA_REP
14 90 1 AD_VP
15 90 2 AD_VP
16 100 5 FI_ACCOUNT
17 100 1 FI_ACCOUNT
18 110 1 AC_ACCOUNT
19 110 1 AC_ACCOUNT
20 1 SA_REP
這里按department_id, job_id分組,我們只關心department_id, job_id,SQL進行調整下
tuneSQL
select distinct department_id, --count(job_id), min(job_id) keep(dense_rank first order by count(job_id) desc)over(partition by department_id) job_id from employees group by department_id, job_id order by 1;
1 10 AD_ASST
2 20 MK_MAN
3 30 PU_CLERK
4 40 HR_REP
5 50 SH_CLERK
6 60 IT_PROG
7 70 PR_REP
8 80 SA_REP
9 90 AD_VP
10 100 FI_ACCOUNT
11 110 AC_ACCOUNT
12 SA_REP
總結:1.boss這個部門返回;
2.沒有涉及子查詢,代碼簡潔;
3.仔細對比,method2和method3的結果,還是稍有差異
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





