溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
做成一件事兒不容易,而坑恒在。
鮑捷博士于5月10日在將門創投的線上 talk 中盤點了人工智能項目的大坑小坑,選出了看上去非常 反常識的十個經典坑。
這是一篇大實話合集,但別絕望,最后將會放出從二十年踩坑經驗中總結出的彩蛋,共勉。
作者介紹
鮑捷博士,文因互聯 CEO。擁有20年學術界和工業界的相關經驗。美國Iowa State University人工智能博士,RPI博士后,MIT訪問研究員,W3C OWL(Web本體語言)工作組成員,前三星美國研發中心研究員,三星問答系統SVoice第二代系統核心設計師。主要研究領域涵蓋人工智能的諸多分支,包括機器學習、神經網絡、數據挖掘、自然語言處理、形式推理、語義網和本體工程等,發表了70多篇領域內相關論文。是中文信息學會語言與知識計算專委會委員,中國計算機協會會刊編委,W3C顧問會員會代表。2010年以來關注金融智能化的研究和應用,成果有XBRL語義模型,基于知識圖譜的基本面分析、金融問答引擎、財務報告自動化提取、自動化監管等。
以下為演講原文:
鮑捷博士:我今天的題目是
《確保搞砸人工智能項目的十種方法》,按照這十種方法,基本上可以搞砸項目。(笑)
之所以能夠講這個題目,是因為我自己之前也搞砸過很多項目,下面列表里超過一半的項目最后是失敗的:

我開始想,為什么大部分的項目最后做不成?
我經歷了好幾次很痛苦的時刻,比如剛到RPI(倫斯特理工學院)做博士后,這個學校有全美做知識圖譜最好的實驗室,實驗室的James Hendler和Deborah Mcguinness, 都是這個領域最好的老師。
我在那里做了一個知識管理系統,在我看來,我們是世界上最好的語義網實驗室,也是最專業的一群人,不用這個技術來武裝自己好像說不過去,所以我就做了一個語義檢索系統,但是后來沒有人用。
我就在反思 到底問題在哪,為什么這行真正最好的專家,做出這樣一個系統,連自己都不用?

我不停地在想, 人工智能項目失敗的核心原因到底有哪些?
當然,后來經歷了更多的失敗。基于這些直接或者間接失敗的經歷,我逐漸總結出來確保一個項目會失敗的一些原因。這些原因很多時候看起來是反直覺的,我會逐一地跟大家講。
在最后,我也會總結如果想要避免這10個坑,應該做什么。
第一種確保你的項目失敗的方法: 一下子砸很多的錢。
我目前也在創業,有VC問我:“你們做的這個事,如果BAT砸很多的錢,是不是就一下子能趕上你們?”
我說不會,通常舉的例子,就是日本的五代機。當初日本舉全國之力,砸了幾百億日元,最終沒有做成。
五代機是什么?1970年代末是人工智能的第一次冬天開始回升的時候。80年代開始進入人工智能第二個高峰。這時候,日本啟動了一個新的項目,叫第五代計算機。
什么叫第五代計算機?前四代計算機,分別是電子管的、晶體管的、集成電路的,和大規模集成電路的。日本到第五代計算機的時候,他們認為 要想做人工智能,就必須用人工智能的專有硬件。
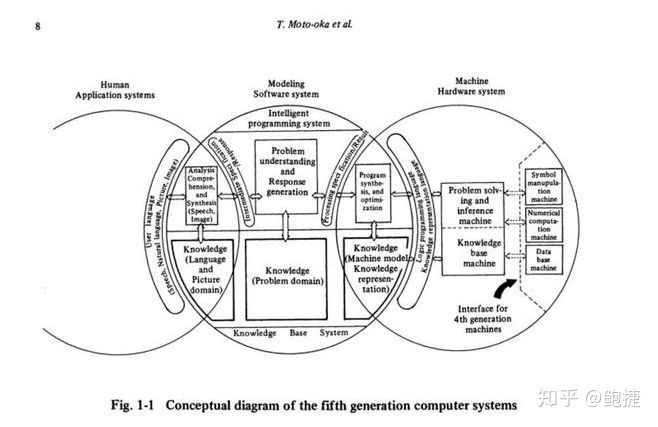
(《知識信息處理系統的挑戰:第五代計算機系統初步報告》中第五代計算機系統概念圖)
這個話是不是聽起來很耳熟?最近在做深度學習的時候,看到了很多關于深度學習芯片的想法。這個想法并不新,因為在30年前,日本人在五代機的計算里,就已經有這樣的想法了,只是當時的人工智能芯片,不是現在深度學習的芯片,而是Prolog的芯片。
Prolog是人工智能的一種語言,主要是一種邏輯建模語言。如果能夠用Prolog來建計算機,計算機就可以進行思維,可以處理各種各樣認知的任務。這是一個非常大型的國家項目,最終花了幾百億日元,耗掉10年時間以后,在1992年,終于 勝利地失敗了。
這不是個例,很多大型的項目,最后都失敗了。
一開始砸很多錢,為什么還會失敗?你要想,做一個項目,通常是有目標的。當你有一個大預算的時候,你的目標通常也定得很高。像五代機的目標,不單當時是做不到的,三十年后的今天,也是做不到的。
雖然五代機失敗了,但是日本的人工智能技術,在五代機的研發當中得到了很大的提升,所以到了20年后,語義網興起的時候,日本的語義網研究水平還是相當好的,那些錢沒有白花,它 培養了很多的人才。
在日本做五代機的同時,美國也有類似的研究,主要是LISP machine,LISP是人工智能的另外一種語言,也是邏輯建模的語言。其中有一個公司叫think machine。當時至少有100家LISP公司。
為什么單獨要提到think machine?創始人在失敗之后沉寂了一段時間,開了一個新的公司叫MetaWeb,MetaWeb是2005年的時候成立的,這個公司有一個產品叫Freebase,用Wikipedia做了一個很好的知識庫。
2010年這個公司被谷歌收購,改名叫谷歌知識圖譜。所以今天谷歌的知識圖譜有很多歷史淵源,可以追溯到30年前LISP machine的研究里面。
羅馬不是一天建成的,所以一下子砸很多錢,就會導致項目的目標過高,從而導致這個項目有極大的失敗概率。
我曾經遇到過一個大型國企的人,他跟我說,他們要花3000萬建一個企業內部知識管理系統。我就問他,你那個3000萬是怎么投的?他說我第一年就要投3000萬。然后我沒說話,因為我的想法是這個項目一定會失敗。后來這個項目的的確確失敗了。
也有一些大公司投比這還多得多的錢來做AI項目。這些都不一定讓事情更容易成功。
這是第一種方法,一下子砸很多錢。
第二種方法: 根據最新的論文來決定技術路線,這可能也是一個反常識的事情。
因為最新的技術不是最好的技術,要注意,在工程領域里面,通常面臨著實際的約束來解決問題的。而論文是一種實驗室的環境,是不一樣的。
比如說實驗室里,可以假設有一些數據,可以假設這些數據已經被集成了,被清洗了,是沒有噪聲的。可以假設目標是清晰的, 但所有的這些假設在現實中都不一定成立的。
最好的例子,就是信息抽取,這是2013年的EMNLP上的一篇文章,我拆出來的圖。
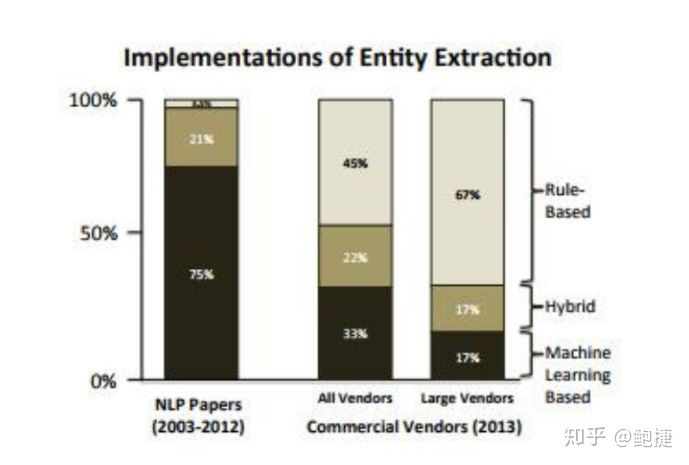
這個圖告訴我們做NLP的論文和實際的工業系統所采用的技術路線有什么不一樣的地方。
從2003年到2012年整整10年,學術界所發表的自然語言處理論文的實體抽取子領域里,完全用機器學習的方法論文占到了75%,混合機器學習和基于規則的方法論文占到了21%,完全只用規則方法的論文,只有百分之一點幾,非常低的比例。
但是當看到工業界的實際應用的時候,發現了完全不同的技術占比分布,用規則方法的占到了45%。
如果光看大型的供應商,比如說IBM這樣的公司,67%的軟件是完全基于規則方法的。完全基于統計方法即machine learning方法的軟件,在所有的供應商那里占33%,在大型的供應商那里只占了17%。
所以從學術界的研究到工業界的實踐,有一個 非常巨大的差異。為什么會有這樣的差異?就是我剛才提到的,在發表論文的時候,完全不需要考慮現實中所會遇到的那些約束條件。在知識提取、實體提取領域,盡管現在從理論上來說,已經解決了,比如說實體識別問題、NER問題、分詞問題,但是到了真正現實的語料中,發現這些方法都不好用。這也可以用另外一個問題來驗證這一點,就是問答系統。
今天看到大部分的論文——我沒有做精確的統計,只是基于模糊定性的看法—— 能看到大部分發表的問答系統的論文都是基于統計方法的。特別是這兩年基于NLP的方法,尤其是基于端到端的方法的。無一例外,能夠真正在工業中應用起來的問答系統,除了小冰這樣的閑聊系統之外, 真正的面向解決任務型的問答系統,全部都是用規則系統的。我還不知道哪一個是用深度學習的,當然也可能有用在某一個具體的細節,或者某一個組件上面,我沒有見到過用于整體架構上。
所以當決定一個工程問題技術路線的時候,不一定要按照最新的論文趨勢來做這件事情,甚至,論文和十年之后的技術都不一定有相關性。 一定要根據現實的情況,根據現實的約束,來決定技術路線。
第三種方法: 如果脫離了真正的應用場景,項目就注定會失敗。
這里我用OWL2來說明。OWL2是一種語言,對于做語義網的同學們很熟悉了。
在Web上所知道的所有的這些標準化的格式,比如說HTML都是W3C,即萬維網聯盟設計的。萬維網聯盟也會負責Web上其他的協議,其中有一個協議叫OWL。它是在講,在互聯網上如何表達我們的知識。
比如說,一個餐館要發布它的菜單,該用什么樣的格式來發布?或者我現在要在網上發布我的簡歷,希望被谷歌更好地檢索到。我要告訴谷歌,我是一個人,我姓什么,叫什么,出生年月是什么,我應該用什么樣的格式發布這樣的數據。其中一個格式就是OWL。OWL的第一個版本在2004年發布,第二個版本是在2010年發布。
OWL WORKING GROUP比較活躍的工作組的成員里面,有相當多的知名大學的老師,還有一些知名公司的科學家,包括IBM、Oracle、惠普。你們注意到,我剛才提到這些大公司的時候,有一些名字沒有出現,比如說谷歌和Facebook。
OWL2本來希望想做的事情,是設計如何在網上表達并發布日常生活衣食住行信息的。但是,最終工作組成員的構成,一種是大學研究人員,另外一種是大公司做企業級應用的, 大部分是遠離場景的。
最終設計出來的產品,也就是OWL2語言, 脫離了真正想去服務的那個場景。OWL WORKING GROUP在開會的時候,寫了大概好幾十個應用案例,但是大部分的案例都是這樣的:一個制藥公司要做一個藥,應該怎么表達制藥的知識,或者一個醫生如何表達病歷、疾病或基因,大體上都是這樣的應用。沒有任何一個案例是在講述在網上如何找一個朋友,或者如何跟朋友聊天,或者如何去訂餐,日常生活中的案例都是沒有的。
OWL2最終寫出來以后,有600頁紙,這是一個非常復雜的語言。事實上,也就是在一些少量的企業級應用里面被用到了,在真正的日常應用當中,成功的案例幾乎沒有。這就是個典型的脫離了應用場景的項目,所以這個項目,花了很多錢,最終沒有達到真實想達到的目標。
第四種方法, 使用過于領先的架構。
這也是跟前面第二種方法相呼應的,第二種方法說,你不能根據最新的論文來決定你的技術路線。第四種方法是在講,如果你使用了一種特別先進的架構,反而有可能導致你的項目失敗。
Twine在2007年被稱為世界上第一個大規模的語義網的應用。當時是一個明星企業,這個公司到了2010年的時候關門了。為什么?Twine在成立的時候,想做一個語義書簽的應用。比如說我讀了一篇文章,我覺得很好,把它保存下來,留著以后再讀。Twine的機器人就會分析我保存下來的這篇文章到底在說啥,然后給這個文章一個語義標簽。如果有人訂閱了我的標簽,他就可以不斷地看到我這個標簽下收藏的好東西,就這么一個想法。
Twine在底層用了一個叫RDF的新數據庫,RDF是一種語義網的語言,比關系數據庫增強很多,它是可以進行推理的數據庫。但是當Twine用戶量達到200萬的時候,它就遇到了一個瓶頸,數據庫的性能不夠。所以Twine的CEO就決定,開發一個新的數據庫。
當時這個公司大概是40個人,用20個人來研發基礎性的東西——一個新的語義數據庫。2008年的時候,情況還不錯,他們發現自己做的東西是個很好的東西,突然就在想,我們做的東西為什么只搜索書簽?完全可以搜索整個Web上的東西。于是他們就做了一次轉型,去做整個Web的語義搜索。步子太大,就把公司拖死了。到了2008年經濟危機爆發的時候,資金鏈斷裂,撐了一年以后就死了。
在死的時候,Twine的CEO Nova Spivack ,是我們領域非常值得尊重的一個先行者,也是一個技術大拿,同時也是一個非常成功的投資人。他就檢討了Twine的失敗。 他說我試圖在太多的地方進行革新,我應該要么革新一個平臺,要么革新一個應用,要么革新一個商業模式,但是我似乎在太多的地方都進行革新了,而且我使用了一種非常超前的架構,就是RDF數據庫,導致了我要追求的目標太大,我無法達到這個目標。
我想他說的這個話,即使到今天,也是非常值得思考的。
這個項目相關的分析文章,我差不多每過兩年都要仔仔細細地看一遍。Twine失敗了以后, Nova Spivack 對公司進行了一次轉型,成立了一個新的公司叫 Bottlenose,還是用了同樣的技術,用在了更聚焦的應用場景上,從2C的服務轉到2B的服務上去。
Bottlenose這個公司,到目前為止已經8年時間了,還是很成功的。2B的應用相對而言不太需要這么大量的數據,不用解決系統可伸縮性問題,突出了這個系統最核心的優勢,即語義分析和理解能力。
像Twine這樣失敗的例子是不罕見的。用一個過于先進的架構的時候,通常會面臨一開始很難去預期的一些風險,甚至不僅僅是像RDF數據庫這樣的小眾的產品,更加大眾的產品,也有可能會遇到這樣的情況。
比如說有人經常會問我說,你們做知識圖譜的應用,是不是一定要用圖數據庫?我就通常回答說不一定。
如果你熟悉圖數據庫,比如說你對 Neo4j 整個運維都非常地熟悉了,你知道它的JAVA虛擬機如果出錯的時候,該如何處理;你知道它內存不夠的時候,該怎么辦;你知道怎么進行數據的分片,知道怎么進行主從的復制……所有這些運維問題都很熟悉的時候,你就可以試一試上這個應用。
在上應用的時候不要太著急,如果你只是一個在線應用,可以放一放,先把離線的這部分運維的工作搞清楚以后,然后再上線,也可以先用一個小數據集試一試。 總之,步子不要太大。
第五種方法,不能管理用戶預期。
這是一個特別常見的項目失敗的原因, 甚至不是因為技術上做不到,而是用戶預期更大。
我先說一個技術上完全做不到的,比如說有一個銀行,他們推出了所謂的機器人大堂經理,你可以跟一個機器人對話辦理業務。顯然,這個東西如果真的能夠做到,應該是非常令人吃驚的事情,這已經遠遠超出當前技術邊界。
最近有一個比較有名的騙局,就是 機器人索菲亞。沙特阿拉伯還給了它第一個公民的身份,這是一個非常典型的詐騙。

這種類型的機器人是不太可能出現的。
在其他應用當中也會遇到這樣的情況,尤其是對話機器人是最容易引起用戶的圖靈測試欲望。當用戶發現跟他對話的是一個機器人的時候,他就會試圖去調戲這個機器人。比如很多人都會去調戲siri,所以siri積累了很多段子,準備應對大家調戲。
如果你是提供了一個搜索引擎,那么大家的預期是比較低的。但如果你以一個問答引擎的形式,提供同樣的內容,大家的預期就會高很多。
我們最早提供了一個終端級產品,用戶的評價就不是特別好,后來我們調整了一下定位,把它調整成用搜索界面來提供服務,系統頂層的智能程度沒有太大改變,但是用戶的預期和評價馬上就好起來了,因為用戶預期降低了。這樣的語義搜索引擎,相比其他的搜索引擎,其實還是好一些的。
對話機器人其實也一樣,如果你給用戶的預期,是能夠跟他平等對話的機器人的話,通常是很難達到的。用戶通常玩一玩就會發現好傻,然后就不玩了,所以大家注意到谷歌機器人跟Apple的siri機器人定位有很大區別,谷歌機器人不僅僅做對話,它能夠預先幫你去做一些事情,甚至主動地去幫你做一些自動化的事情,其實這是非常聰明的選擇。
目前能夠跟人長期進行交互的機器人,其實是一個更加偏秘書型的,或者說它就是一個幫助你進行任務自動化的機器。如果你是立足于對話,其實很難滿足用戶預期,但是如果你立足于自動化,就比較容易達到用戶預期。 同樣的技術,你用不同的方法去服務用戶,用戶預期不一樣,用戶的感覺就完全不一樣。所以要盡可能地讓用戶感知到產品的成熟度,在他的預期之上,這個產品才有可能成功,他才愿意付費。
第六點叫做 不能理解認知復雜性。
這個事情我在剛開始的時候就提到了,這個例子就是Semantic Wiki,我寫了很多個這樣的系統,Semantic Wiki是什么呢?大家肯定都用過維基百科或者百度百科,這只是一個典型的維基系統,有很多人去寫一個頁面。Semantic Wiki也是基于協作的,也是一個Wiki,只不過在這個Wiki的頁面上,你可以打一些標簽,加一些注釋。
它可以解決什么問題呢?比如可以解決頁面之間的數據一次性問題,就是一個頁面上的數據,可以流到另外一個頁面上去,舉個例子,比如說在維基百科上面,可以看到很多國家的GDP,就是國民生產總值,在中國的頁面上,會有中國GDP,在亞洲國家的GDP列表上面,也會有中國GDP,然后在世界國家的GDP列表上,也會有中國GDP,那么是不是可以有一個機制,比如在一個頁面,寫下中國的GDP是多少,只要這個數字改變,其他所有頁面上的數字會同步改變,用Semantic Wiki技術就可以做到這一點。當然Semantic wiki還可以做很多很酷的其他的事情,很強大。
我從2004年開始就開始寫Semantic Wiki系統,前前后后寫了三個Semantic Wiki系統,后來我加入了一個開源社區,叫 Semantic MediaWiki, 基于這樣的系統,我做了一個很好的知識管理系統。
2010年我們試圖來推廣這個系統,當時是做了一個實驗,也是一個美國的國家機構委托我們做的,就是要測試用這種協作的知識管理系統來記錄一些事件,能不能記錄得很好,好到可以后面讓機器自動進行處理。
當時做的對比實驗是找了一群RPI的計算機系本科生,讓他們來看電視連續劇,看完以后描述情節。一部分人用自然語言來進行描述,一部分人用Semantic Wiki,以更加結構化的方式來進行描述。然后再找了學生來分別閱讀前兩組學生的描述,最后讓他們來做題,看哪個組能夠更精準地來復原電視劇情節。 最后得到的結果發現是用自然語言描述是更容易,就是描述得更精準,速度更快。
然后我們仔細去看那些學生寫的結構化的描述,發現是錯誤百出,比如說張三擁抱了李四,對于一般的所謂有過知識工程訓練的人來看,很明顯擁抱應該是一個關系,張三和李四應該是兩個人,一個是主語,一個是賓語,那么就應該是主謂賓,張三擁抱李四是很清楚的一個知識建模,但是相當多的學生,他們把這么一個特別簡單的建模就給搞錯了,他們沒有辦法理解什么叫概念?什么叫關系?什么叫屬性?甚至他們不知道什么叫主語和賓語?然后發現在一開始設想這件事情的時候,忽視了絕大多數的人,在他們的教育生涯中比如高中教育里面,是沒有結構化思維的訓練的,這是一種事先無法意識到的認知復雜性。
由于我們都經過十年以上的訓練,所以就完全把這些東西當成是天然的事情。后來在OWL WORKING GROUP也遇到了同樣的事情,有人說這個東西太復雜了,其中有一個邏輯學家就抗議說,這東西不復雜,這東西在計算機上跑的時候,它的算法復雜性只是多項式復雜性而已,然后我聽了這句話以后,突然意識到了一個事情,就是在這些邏輯學家的腦子里面,他們所提到的復雜性是指一個語言對于機器的復雜性,所以我們通常把它稱為計算復雜性。
但是實際上普通人所理解的復雜性不是這樣的,比如說你半頁紙就能說明白的東西,那是一個簡單的東西,如果讓我看到20頁紙,才能看明白,那這個東西是一個復雜的東西。 所以一個技術,你能不能夠讓程序員用起來,能不能讓用戶用起來,最核心的事情,你是不是能夠讓他們在認知上面覺得這東西,一看就懂,一聽就懂,一打開就懂,不用解釋,這才叫簡單。
在很多算法的設計上面也好,文檔的設計上面也好,應用的設計上也好,它最終能不能用得好,關鍵是讓人感覺到它簡單好用,這就是一個很重要的因素。斯坦福Parser,為什么在NLP領域里面被用的這么廣,一個很重要的原因,它的文檔寫的好,每一個類都有文檔,提供了足夠多的案例。
所以 好的文檔可以極大地降低一個產品的認知復雜性,即使你的產品本身是復雜的,你把文檔寫好,也足以有助于推廣這個產品,所以盡可能地讓能夠接觸到你產品的人,不管是搞語言的,搞技術的,搞算法的人都感覺到這東西簡單,是保證你的產品成功的一個關鍵。
第七點,這一點就很好理解了, 專業性不足。
我經常會遇到這樣一些人,說某某公司現在想做一個問答系統,希望投入三五個人,可能大多數情況下沒有博士,多數情況下可能就是一個工程人員,試圖很快的時間,兩三個月之內,甚至三五個月之內,把這樣一個東西做出來,也是一種幻想。當然我不會直接說破。
人工智能產品,的的確確是有它的專業性的。很多機構想試圖自己去做這樣的事情,花了1000萬、2000萬、3000萬冤枉錢,結果做不到。確實,如果沒有一個足夠專業的人是很難把這種事情給做成的。
我也經歷了很多這樣的事情,在曾經做過的一個語義理解系統里面,也經歷了這樣的問題。我想能夠完成這樣一個系統,實際上是要綜合很多不同的算法,不是一個算法就能夠解決掉的。比如說,從正面的例子來看,IBM Watson 系統里面有幾十種不同的算法,有機器學習的算法,有自然語言處理的算法,有知識圖譜的算法。 你要把所有的這些算法恰到好處地組合在一起,拿捏的尺度就是一個特別重要的能力。你該用什么樣的東西,你該不用什么樣的東西。
比如說規則系統,任何一個人都可以寫10條正則表達式,這是沒有問題的。但是如果你能夠寫好100條正則表達式,那你一定是一個非常優秀的工程人員,你的軟件工程能力很過硬。如果你能夠管理好1,000條正則表達式,那你一定是一個科班出身的,有專業級的知識管理訓練的人。如果你能夠真正地管理好10,000條正則表達式,那你一定是一個有非常豐富的規則管理經驗的人。
當然我說的1,000條、10,000條,并不是說你 copy paste 10,000次,改其中幾個字,那個不算。人工智能的很多事情,困難就在這兒。你到網上去拿一個什么開源包啥的,你把它做到80%,都很容易做得到。但難度就在于最后的20%,通常可能需要98%、99%的正確率,才能夠滿足用戶的需求,但是如果專業性不夠,最后的這些點是非常難的。
打個比方說,你要登月的話,你需要的不是梯子,是火箭。你搬個梯子,最后只能爬到樹上去,再也沒辦法往上走了。你需要的是停下來造火箭,造火箭就是專業性, 如果專業性不足,你永遠只是停留在80%的水平上,再也升不上去。
回到剛才講的語義理解的項目。當時就遇到了蠻多困難,要能夠集成規則的方法,集成統計的方法,集成自然語言處理的方法。當時全球有很多實驗室一起來做這件事情,但缺這樣一種角色,能夠把所有的尺度拿捏得特別好的。
其實IBM把Watson系統做出來,也是經歷了很多內部變遷,包括項目管理人的變化,包括各種技術選型的變化,能夠做到這一些,這種人才是非常短缺的。在中國,能夠真正從頭到尾把一個語義的理解系統架構做好的人,是非常非常少的,也許10個,也許20個,數量確實不多。我相信在其他人工智能領域,也面臨著同樣的情況。
專業性也不會僅僅只局限于程序或者技術這一塊,人工智能的產品經理,人工智能項目的運營,還有整個后面的知識系統,數據的治理,都是需要很專業的人來做, 現在這些人才都非常地短缺。
第八種方法就是 工程能力不足。
我的博士論文是一個分布式推理機,但因為編程能力不夠,一直到我畢業為止,都沒有能夠把它實現出來。當然后來到了2012年、2013年之后,圖計算,包括基于消息交換的圖計算出來之后,那時候我再來做分布式推理機就比較容易了。
但這是我特別大的一個教訓。
在這之后,我就比較關注,如果做一件事情,先能夠把我的工程能力補足。這個工程能力,包括軟件工程能力,如何寫代碼,如何管理代碼,如何做系統集成,還有回歸測試,如何進行代碼的版本控制等等。后來我面試人的時候,也比較關注這些東西。
一個人工智能的技術能不能做得好,核心往往不僅僅是算法,而是底下的架構,還有系統。比如論文中其實是很好的分布式推理算法,但是我因為缺少這個架構,就沒有辦法把這個東西實現出來。后來像深度學習也是這樣的。最近看到陳天奇他們的實驗室,把算法、架構、操作系統都放在一個實驗室里面來運作,覺得這是一個特別好的事情。目前算法和架構之間的裂縫太大了。
工程是解決人工智能的核心鑰匙。 如果代碼能力不行,架構能力不行,工程能力不行,在這個情況下,根本就不應該去談算法。優先應該把工程能力補起來,然后再談算法。
第九點, 陣容太豪華。
這一點不太好說具體的項目是什么,太敏感了。
但是我就從邏輯上給大家講一下。 因為一個項目如果太豪華,核心的問題就是沉沒成本。
我們也經常看到一些初創公司,不管是從商務上,還是從技術上,特別優秀的人組成了一個公司,最后還是會失敗。為什么?因為比較優秀的人,就是想要做大的事情。一個大的事情,很難一下子就做對。通常大的事情,是從小的事情成長起來的。 如果我們不能夠讓豪華的陣容,從小事做起,通常這樣一個事情是會失敗的。

邏輯很簡單,我就不多說了。
第十點,我可以把所有其他的因素丟到這兒, 就是時機不到、運氣不好。

其實可以把所有其他的事情都歸結為運氣不好。
比如說我們現在看深度學習,比如像attention、卷積、LSTM、聯想記憶等等所有這些概念在90年代,我讀研究生的時候,這些概念都已經有了,但是當時是做不到的。當時即使有了這些算法,也沒有這樣的算力,即使有了這樣的算力,沒有這樣的數據。
在2000年的時候,我在碩士畢業之后,就在研究一種分層的多層神經網絡。我們把它稱為hierarchical neural network,跟后來深度學習的想法非常接近。我帶著這個想法,去見我的博士導師。說我想繼續沿著這個方向往前走,但他說現在整個神經網絡都已經拿不到投資了,你再往前走,也走不下去,所以后來就放棄了這個方向,準備做語義網了。 10年之后,這個方法終于找到了機會,后來就變成了深度學習的東西。
很多時候,時機不到,即使你有這個算法,你也做不到。90年代的神經網絡,差不多花了10年的時間,才等到了自己的復蘇。
知識圖譜也是一樣的,知識圖譜大概也等了十幾年的時間,到了最近這幾年才真正地得到了大規模的應用。
讓我們來取個反,做個總結:

最后一點,時機和運氣再啰嗦一下。
很多時候,我們是真的不知道這件事情能不能做得成,也真的不知道,自己處于什么樣的歷史階段。很難預言未來是什么, 但是至少有一點,如果我們多去了解一些算法層面的發展,包括人工智能的發展史,包括相關的這些技術的發展史,能夠更好地理解未來。
所以我也推薦一下尼克老師的 《人工智能簡史》這本書。我看了兩遍都挺有收獲的。看了這東西,能更多地理解什么是時機,什么是運氣。
有時候我也經常會讀一些經典的文章,十年前或20年前的書,我讀了還是挺有啟發的。比如說,今年我又把Tim Berners-Lee 《編織萬維網》那本書又重新讀了一遍,讀了一遍以后,我就堅定信心了。
知識圖譜這樣一個互聯全世界的記憶的系統,大概率到2030年能夠實現,這還是一個很遙遠的時間,但是根據歷史規律,應該到2030年能實現了。
一方面,降低我們現在的預期,另一方面也給我們前進更大的鼓勵。

剛才反反復復提到了,要控制用戶的預期,控制自己的預期。做一個項目,要從小到大,循序漸進。最后把所有的東西抽象到更高層面上,我自己總結為一個理論,叫 場景躍遷理論。
這個理論的核心,是說 一個人工智能的公司需要多次的產品市場匹配,就是Product-Market Fit。如果提供了一個產品,市場恰恰需要,而這個市場恰恰又很大,就說得到了一個產品市場匹配。
經典的互聯網創業,通常做一次產品的市場匹配,就可以成功了。但人工智能往往要做好幾次,互聯網公司和人工智能公司很不一樣。
一個稱為養雞場模式,一個稱為養小孩模式。
互聯網公司是一種養雞場模式,它是一個大規模的復雜系統Complex system。它的關鍵是可擴展性。我養了一只雞,我發現這只雞不錯,我養1萬只雞,這就是養雞場模式。核心就是如何能養一萬只雞,這就叫可擴展性。
人工智能應用是另外一種類型的復雜系統,叫Complicated system,它是有非常多的組件,通常是上百種奇奇怪怪的組件組合在一起。它的核心并不是養一萬只雞,更多像養小孩一樣,生完孩子,從小給他換尿布,給他喂奶,教他走路,教他說話,逗他玩,小學、中學、大學,一路把他養大,每一個階段所面臨的主要任務都不一樣。 你如何能夠讓這小孩成長,我們把它稱為可演進性,這才是AI公司最核心的因素。
把一個AI的公司給養大,其實是特別不容易的事情。就跟養小孩一樣,往往前5年的時間,都在搭團隊,搞基礎,特別辛苦。公司存活的觀念就是,如何能夠在演進的過程中,逐步地掙錢,而不是試圖一步到位地找到市場產品結合點。 不僅僅是在人工智能的階段要掙錢,在人工智障的階段,也要能夠掙錢。
沒有一個完整的系統,怎么能掙錢?只能夠把系統中的某些組件拿出去,做 部分的商業化。就好像毛毛蟲到蝴蝶一樣,毛毛蟲要蛻皮,蛻好幾次,才能變成一個蝴蝶。毛毛蟲階段,它要吃樹葉子,在蝴蝶那個階段,它是要吃花蜜,所以它在兩個不同的階段,它的商業模式是完全不一樣的。人工智能公司也要蛻好幾次皮。在早期的時候,因為產品還不夠完善,所以人工智能公司早期都是外包公司,這是正常的,就應該接受,這是發展必經的階段。
總結今天所說的一切,人工智能是一種新興的事物,它是非常復雜的東西。很難用傳統的舊經驗來套這樣一種東西的發展,必須經過很長時間的演化,才能夠達到成熟的狀態。 而這個演化力才是我們想做一個成功的商業的嘗試,最關鍵的因素。如何保證在一次又一次的場景躍遷當中,團隊不散架,這樣的能力,才是決定了某一個商業上面能不能成功的最大的關鍵。
我覺得不僅僅是商業,不管是在學校里做研究也好,還是在大型跨國公司里做研究也好,很多道理都是一樣的。就是如何能夠循序漸進地,從小到大地來做,謝謝大家!
—完—
https://zhuanlan.zhihu.com/p/41061140
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





