溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章介紹的是MySQL 5.6中的字符集,基本是我以前學習MySQL 5.6手冊時整理而來。
字符集(character set)是編碼和字符符號的映射集合。排序規則(collation)是用于比較字符集中字符的規則集。
現在我們自定義一個簡單的字符集character set。假設我們有一個僅有四個字母的字母表:A、B、a、b。我們給每個字母一個數字:A = 0,B = 1,a = 2,b = 3。字母A是一個字符符號,數字0是A的編碼,這四個字母和它們編碼的映射就是一個字符集。
假設我們想要比較兩個字符串的值:A和B。最簡單的辦法就是查看它們的編碼:A的編碼為0,B的編碼為1。因為0小于1,我們說A小于B。我們所做的就是應用排序規則到字符集。這些規則的集合(在該示例中只有一條規則)就是排序規則collation:比較它們的編碼。當然,現實中的字符集和排序規則要復雜地多,但基本理念是上面所說的那樣。
repertoire是指一個字符集中字符的集合。字符串表達式都有一個repertoire屬性,這個屬性可以有兩個值:
ASCII:表達式只能包含Unicode編碼在U+0000到U+007F范圍內的字符。
UNICODE:表達式可以包含Unicode編碼在U+0000到U+10FFFF范圍內的字符。這包括那些在Basic Multilingual Plane(BMP)范圍內(U+0000 到 U+FFFF)的字符,和在BMP范圍外(U+01000 到 U+10FFFF)的增補字符。
ASCII范圍是UNICODE范圍的一個子集,因此,一個ASCII repertoire的字符串可以安全地轉換成UNICODE repertoire字符串的字符集(或任何包含ASCII范圍的字符集),而不會有任何問題。從這里我們可以得到兩個結論:
1、特定的字符集擁有特定范圍的repertoire,這就限定了使用該字符集的表/字段也就只能使用特定范圍的字符,超出范圍的字符將不會被那個字符集所支持。比如,ascii字符集的repertoire范圍就是ASCII,因此,若使用該字符集,就只能使用Unicode編碼在U+0000到U+007F范圍內的字符。
2、字符子集的字符集可以安全地轉換成它的超集的字符集,而不會有任何問題。這點在不同字符集混用時很有用,MySQL可以完成自動轉換。但是,反過來是不行的。
MySQL中的的常見字符集:
utf8字符集:是一種UTF-8編碼的Unicode字符集,每個字符占用1到3個字節。只能覆蓋BMP范圍內的字符,其中不單單有英文字符,也包括中文字符等。
utf8mb4字符集:是一種UTF-8編碼的Unicode字符集,每個字符占用1到4個字節。可以覆蓋BMP范圍內的字符和增補字符。BMP范圍內的字符編碼和utf8字符集中的編碼是完全相同的,長度也是完全一樣的,所以utf8mb4字符集可以兼容utf8字符集。
元數據(Metadata)是"關于數據的數據"。任何描述數據庫的東西 — 與數據庫中的內容相對,都是元數據。因此,列名、數據庫名、用戶名、版本名和SHOW命令的大多數字符串結果都是元數據。這對于information_schema庫中表的內容也同樣正確,因為從定義上來說,那些表包含關于數據庫對象的信息。元數據的呈現必須滿足這些要求:
所有的元數據都必須使用相同的字符集。否則,對information_schema庫中的表執行SHOW或SELECT命令將無法正常運行,因為這些操作返回的結果中,同一列的不同行將會在不同的字符集中。
元數據必須包含所有語言的所有字符。否則,用戶將無法使用它們自己本地的語言來被表或列命名。
為了滿足上面的要求,MySQL將元數據存儲在Unicode字符集中,準確地說是UTF-8。只要你不使用方言或非拉丁字符,這不會有任何問題。但如果你使用了,你應該意識到元數據是UTF-8字符集的。
MySQL將系統變量character_set_system的值設置為與元數據所使用的字符集的相同:
mysql> SHOW VARIABLES LIKE 'character_set_system'; +-----------------------+----------+ | Variable_name | Value | +-----------------------+----------+ | character_set_system | utf8 | +-----------------------+---------+ |
元數據的存儲使用Unicode并不意味著,服務器返回DESCRIBE函數的結果的列名時默認會使用character_set_system變量所設置的字符集。當你使用SELECT column1 FROM t命令時,服務器返回給客戶端的column1這個列名自身的字符集,是由系統變量character_set_results的值決定的,默認值是latin1:
mysql> SHOW VARIABLES LIKE 'character_set_results'; +-----------------------+---------+ | Variable_name | Value | +-----------------------+---------+ | character_set_results | latin1 | +-----------------------+---------+ |
如果你想要服務器返回元數據給客戶端時使用不同的字符集,就使用SET NAMES'character_set' 命令來強制服務器將當前字符集轉換成指定的character_set,該命令會自動設置character_set_results等相關的系統變量,僅對當前會話生效。如果character_set_results被設為NULL,服務器返回元數據時將不進行轉換,而使用它原本的字符集(即變量character_set_system所指示的字符集)。
另外,客戶端程序也可以在接收到服務器返回的數據后執行字符集轉換。在客戶端執行字符集轉換效率更高,但并不是所有客戶端都支持這個功能。
從上面的說明可以看出,字符集問題不單單影響數據存儲,還會影響客戶端與MySQL服務器之間的通信。如果你想要讓客戶端程序使用與默認字符集不相同的字符集與服務器端通信,你需要指明哪一個。比如,要使用 utf8 字符集,執行命令:
mysql> SET NAMES 'utf8'; |
當然,因為還沒有再MySQL配置文件中設置相關變量,所以這里的設置并不是持久的。僅在當前會話中生效。
MySQL支持在MySQL服務器(server)、數據庫(database)、表(table)和列(column)四個級別指定所使用的字符集。MySQL支持對MyISAM、MEMORY和InnoDB存儲引擎配置字符集。
1、 MySQL服務器有一個服務器字符集和服務器排序規則,分別由變量character_set_server和變量collation_server控制。你可以在MySQL配置文件中或MySQL啟動選項中設置這兩個選項的值,也支持使用set命令進行動態修改,有全局值和會話值兩種。character_set_server的默認值是latin1字符集,collation_server的默認值是latin1_swedish_ci排序規則。如果你只指定了字符集,而沒有指定排序規則,那么系統會自動將排序規則設置為該字符集的默認排序規則。比如,如果你將character_set_server的值設置為utf8mb4字符集而沒有設置collation_server的值,那么collation_server的值會自動變為utf8mb4_general_ci排序規則,因為utf8mb4_general_ci是utf8mb4字符集的默認排序規則。
[root@gw ~]# vim /usr/my.cnf [mysqld] character-set-server=utf8mb4 collation-server=utf8mb4_general_ci |
在使用CREATE DATABASE命令創建數據庫時如果沒有指定數據庫字符集和排序規則, 那么服務器端字符集和排序規則就會作為默認值,它們的用途僅在于這里。因此可以說,服務器端字符集和排序規則是MySQL數據庫中數據(除元數據外)的可能的默認值。
2、 MySQL中的每一個庫都有一個數據庫字符集和數據庫排序規則。CREATE DATABASE 和 ALTER DATABASE語句都有選項可以指定數據庫字符集和排序規則:
CREATE DATABASE db_name [[DEFAULT] CHARACTER SET charset_name] [[DEFAULT] COLLATE collation_name]
ALTER DATABASE db_name [[DEFAULT] CHARACTER SET charset_name] [[DEFAULT] COLLATE collation_name] |
MySQL按照下面的方式決定數據庫的字符集和排序規則:
如果CHARACTER SETcharset_name和COLLATEcollation_name都指定了,那么數據庫字符集和排序規則就是所指定的charset_name和collation_name。
如果只指定了CHARACTER SETcharset_name而沒有指定COLLATE,那么數據庫字符集和排序規則就是所指定的charset_name和該字符集默認的排序規則。
如果只指定了COLLATEcollation_name而沒有指定CHARACTER SET,那么數據庫字符集和排序規則就是該collation_name相關聯的字符集和所指定的collation_name。
如果CHARACTER SETcharset_name和COLLATEcollation_name都沒有指定,那么數據庫字符集和排序規則就使用MySQL服務器字符集和排序規則(見上一小節)。
數據庫默認字符集和排序規則可以從character_set_database 和 collation_database這兩個系統變量得知。要查看指定數據庫的默認字符集和排序規則,使用命令:
mysql> use db_name; mysql> SELECT @@character_set_database, @@collation_database; |
也可以使用下面的命令:
mysql> SELECT DEFAULT_CHARACTER_SET_NAME, DEFAULT_COLLATION_NAME FROM INFORMATION_SCHEMA.SCHEMATA WHERE SCHEMA_NAME = 'db_name'; |
數據庫字符集和排序規則影響服務器運行的這些方面:
對于CREATE TABLE語句,如果創建表時未顯式指定字符集和排序規則,數據庫字符集和排序規則被用做表的默認字符集和排序規則。要覆蓋該行為,顯式使用CHARACTER SET 和 COLLATE選項。
對于不包括CHARACTER SET選項的LOAD DATA語句,服務器使用變量character_set_database所指示的字符集來解析文件中的信息。要覆蓋該行為,顯式使用CHARACTER SET選項。
對于存儲的程序(過程和函數),在創建程序時如果字符數據參數(character data parameters)的聲明未使用CHARACTER SET 和 COLLATE選項,那么數據庫字符集和排序規則會用做字符數據參數的字符集和排序規則。要覆蓋該行為,顯式使用CHARACTER SET 和 COLLATE選項。
3、 每個表都有一個表字符集和表排序規則。CREATE TABLE 和 ALTER TABLE語句都有選項可以指定表字符集和排序規則:
CREATE TABLE tbl_name (column_list) [[DEFAULT] CHARACTER SET charset_name] [COLLATE collation_name]]
ALTER TABLE tbl_name [[DEFAULT] CHARACTER SET charset_name] [COLLATE collation_name] |
示例:
CREATE TABLE t1 ( ... ) CHARACTER SET latin1 COLLATE latin1_danish_ci; |
MySQL按照下面的方式決定表的字符集和排序規則:
如果CHARACTER SETcharset_name和COLLATEcollation_name都指定了,那么表字符集和排序規則就是所指定的charset_name和collation_name。
如果只指定了CHARACTER SETcharset_name而沒有指定COLLATE,那么表字符集和排序規則就是所指定的charset_name和該字符集默認的排序規則。
如果只指定了COLLATEcollation_name而沒有指定CHARACTER SET,那么表字符集和排序規則就是該collation_name相關聯的字符集和所指定的collation_name。
如果CHARACTER SETcharset_name和COLLATEcollation_name都沒有指定,那么表字符集和排序規則就使用數據庫字符集和排序規則(見上一小節)。
表字符集和排序規則被用作列定義中的默認值,如果在單個的列定義中沒有指定列字符集和排序規則。表字符集和排序規則是MySQL的擴展,并不是標準SQL中的東西。
4、 每一個"字符"列(即是,CHAR、VARCHAR或TEXT類型的列)都有一個列字符集和列排序規則。CREATE TABLE 和 ALTER TABLE語句中都有選項可以指定列字符集和排序規則:
col_name {CHAR | VARCHAR | TEXT} (col_length) [CHARACTER SET charset_name] [COLLATE collation_name] |
ENUM和SET類型的列中也有選項:
col_name {ENUM | SET} (val_list) [CHARACTER SET charset_name] [COLLATE collation_name] |
示例:
CREATE TABLE t1 ( col1 VARCHAR(5) CHARACTER SET latin1 COLLATE latin1_german1_ci );
ALTER TABLE t1 MODIFY col1 VARCHAR(5) CHARACTER SET latin1 COLLATE latin1_swedish_ci; |
MySQL按照下面的方式決定列的字符集和排序規則:
如果CHARACTER SETcharset_name和COLLATEcollation_name都指定了,那么列字符集和排序規則就是所指定的charset_name和collation_name。
如果只指定了CHARACTER SETcharset_name而沒有指定COLLATE,那么列字符集和排序規則就是所指定的charset_name和該字符集默認的排序規則。
如果只指定了COLLATEcollation_name而沒有指定CHARACTER SET,那么列字符集和排序規則就是該collation_name相關聯的字符集和所指定的collation_name。
如果CHARACTER SETcharset_name和COLLATEcollation_name都沒有指定,那么列字符集和排序規則就使用表字符集和排序規則(見上一小節)。
除了前面所說的,每一個字符串字面量(string literal)都有一個字符集和排序規則。對于簡單語句SELECT 'string',這里用到的string有一個連接默認字符集和排序規則(connection default character set and collation),分別由系統變量character_set_connection和collation_connection控制。一個字符串字面量可能會有一個可選的字符集introducer和COLLATE子句,來將它指定為使用特定字符集和排序規則的字符串:
[_charset_name]'string' [COLLATE collation_name] |
示例:
SELECT 'abc'; SELECT _latin1'abc'; SELECT _binary'abc'; SELECT _utf8'abc' COLLATE utf8_danish_ci; |
_charset_name這個表達式的正式叫法叫做introducer。它告訴解析器:它后面所接的字符串使用字符集charset_name。MySQL按照下面的方式決定字符串字面量的字符集和排序規則:
如果_charset_name和COLLATEcollation_name都指定了,那么字符串字面量字符集和排序規則就是所指定的charset_name和collation_name。
如果只指定了_charset_name而沒有指定COLLATE,那么字符串字面量字符集和排序規則就是所指定的charset_name和該字符集默認的排序規則。
如果只指定了COLLATEcollation_name而沒有指定_charset_name,那么字符串字面量字符集和排序規則就是系統變量character_set_connection所指定的連接默認字符集和所指定的collation_name。collation_name必須是連接默認字符集的排序規則之一。
如果_charset_name和COLLATEcollation_name都沒有指定,那么字符串字面量字符集和排序規則就使用系統變量character_set_connection和collation_connection所指定的連接默認字符集和排序規則。
每一個客戶端都有一個連接相關的(connection-related)字符集和排序規則。一個"connection"就是指當你連接到MySQL服務器時的連接。客戶端發送SQL語句,比如查詢,是通過到服務器的連接。服務器返回數據,比如查詢結果或錯誤信息,是通過到客戶端的連接。這導致了下面幾個與客戶端連接相關的字符集和排序規則的問題:
1、 當它離開客戶端時語句的字符集是什么?
服務器會將character_set_client系統變量的值當做是客戶端所發送的SQL語句的字符集。
2、 服務器在接收到SQL語句后,會將它轉換成什么字符集?
服務器會將客戶端所發送的SQL語句的字符集,從character_set_client轉換成character_set_connection所指向的字符集(除了那些有introducer的字符串字面量)。字符串字面量的比較則使用collation_connection所指向的排序規則。對于那些有列值的字符串的比較,則與collation_connection沒什么關系,因為列有它們自己的排序規則,那個排序規則的優先級更高。
3、 服務器在將SQL查詢結果或錯誤信息發送回給客戶端之前會將它們轉換成什么字符集?
服務器會將SQL查詢結果的字符集轉換成系統變量character_set_results所指向的字符集。要轉換的數據包括列值和元數據(比如列名和錯誤信息)。
有兩個命令可以統一設置連接相關的字符集:
1、 SET NAMES命令
SET NAMES命令告訴MySQL服務器,客戶端使用的是什么字符集與它交互的。SET NAMES命令設置的值只會對當前會話生效。語法格式:
SET NAMES 'charset_name' [COLLATE 'collation_name'] |
一條 SET NAMES 'charset_name' 語句(COLLATE 'collation_name'是可選的)實際上等同于下面的三條語句:
SET character_set_client = charset_name; SET character_set_results = charset_name; SET character_set_connection = charset_name; // 這第三條語句也隱含了將變量collation_connection設置為charset_name字符集默認的排序規則 |
2、 SET CHARACTER SET命令
SET CHARACTER SET命令類似于SET NAMES,但將character_set_connection和collation_connection設置為character_set_database和collation_database。語法格式:
SET CHARACTER SET charset_name; |
一條 SET CHARACTER SET charset_name 命令實際上等同于下面的三條語句:
SET character_set_client = charset_name; SET character_set_results = charset_name; SET collation_connection = @@collation_database; // 這第三條語句也隱含了執行命令SET character_set_connection = @@character_set_database; |
對于MySQL客戶端程序mysql、mysqladmin、mysqlcheck、mysqlimport和mysqlshow,它們是按照下面的規則來決定與MySQL服務器端通信時所使用的字符集的:
1、 在缺少其它信息的情況下,它們會使用預設的默認字符集(通常是latin1)來與MySQL服務器端通信。這個預設的默認字符集也可以在MySQL配置文件中使用下面選項指定:
[root@gw ~]# vim /usr/my.cnf [client] default-character-set=utf8mb4 |
2、 程序可以自動檢測要使用哪一個字符集,基于操作系統設置,比如LANG或LC_ALL環境變量的值。比如,如果操作系統中LANG環境變量的值為ru_RU.KOI8-R,會使得這些客戶端程序變成使用koi8r字符集。這一點會比第1點優先。
3、 這些程序支持使用選項 --default-character-set 來讓用戶顯式指定字符集,以覆蓋程序自動決定的字符集。這一點會比第1、2點都優先。
如果你想要服務器在返回SQL查詢結果或錯誤信息給客戶端時不執行字符集轉換,可以將character_set_results變量設為NULL或binary:
SET character_set_results = NULL; |
要顯示MySQL中所支持的所有字符集,可以查看information_schema.character_sets表或使用show character set命令,后面可以加上 LIKE 或 WHERE子句進行過濾:
mysql> SHOW CHARACTER SET; mysql> select * from information_schema.character_sets; |
一個給定的字符集至少會有一個排序規則。大多數的字符集支持多個排序規則,其中一個是默認的。要顯示字符集所支持的所有排序規則,可以查看information_schema.collations表或使用show collation命令,后面可以加上 LIKE 或 WHERE子句進行過濾:
mysql> SHOW COLLATION; mysql> select * from information_schema.collations; |
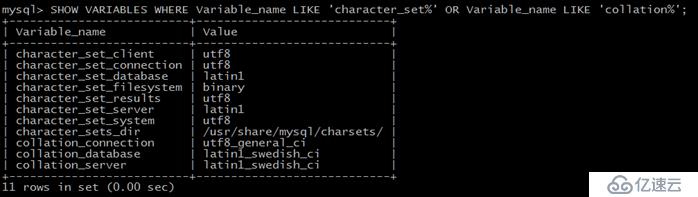
如果要使用所有跟字符集和排序規則相關的系統變量,可以使用命令:
mysql> SHOW VARIABLES WHERE Variable_name LIKE 'character_set%' OR Variable_name LIKE 'collation%'; |
執行后,可以看到有下面這些變量:
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





