溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
1,給安徽的同事安裝了一個生產Oracle數據庫,最近一段時間 總是在2點-10點之間出現數據庫連不上的情況,具體tomcat應用日志如下:
08:58:09 ERROR c.d.web.controller.DBAppController - 查詢更新版本請求異常org.springframework.dao.DataAcce***esourceFailureException:
### Error querying database. Cause: java.sql.SQLException: Io exception: Connection timed out
### The error may exist in file [/usr/local/tomcat/xx/WEB-INF/classes/mapper/DBAppMapper.xml]
### The error may involve com.dabay.web.dao.DBAppDao.selectProperties-Inline
### The error occurred while setting parameters
### SQL: SELECT KEY,VALUE,DESCRIPTION FROM APP_PROPERTIES WHERE KEY=? AND DATA_STATUS!='9'
### Cause: java.sql.SQLException: Io exception: Connection timed out
; SQL []; Io exception: Connection timed out; nested exception is java.sql.SQLException: Io exception: Connection timed out
08:58:09 ERROR c.d.web.controller.DBAppController - DGW_0922084243406:查詢輪播圖請求異常org.springframework.dao.DataAcce***esourceFailureException:
### Error querying database. Cause: java.sql.SQLException: Io exception: Connection timed out
### The error may exist in file [/usr/local/tomcat/xx/WEB-INF/classes/mapper/DBAppMapper.xml]
### The error may involve defaultParameterMap
### The error occurred while setting parameters
### SQL: SELECT TITLE, URL, REMARKS, PNGURL FROM INFO_BANNER WHERE DATA_STATUS!='9' AND ROWNUM<6 ORDER BY ORDERDESC asc,CREATE_TIME desc
### Cause: java.sql.SQLException: Io exception: Connection timed out
; SQL []; Io exception: Connection timed out; nested exception is java.sql.SQLException: Io exception: Connection timed out
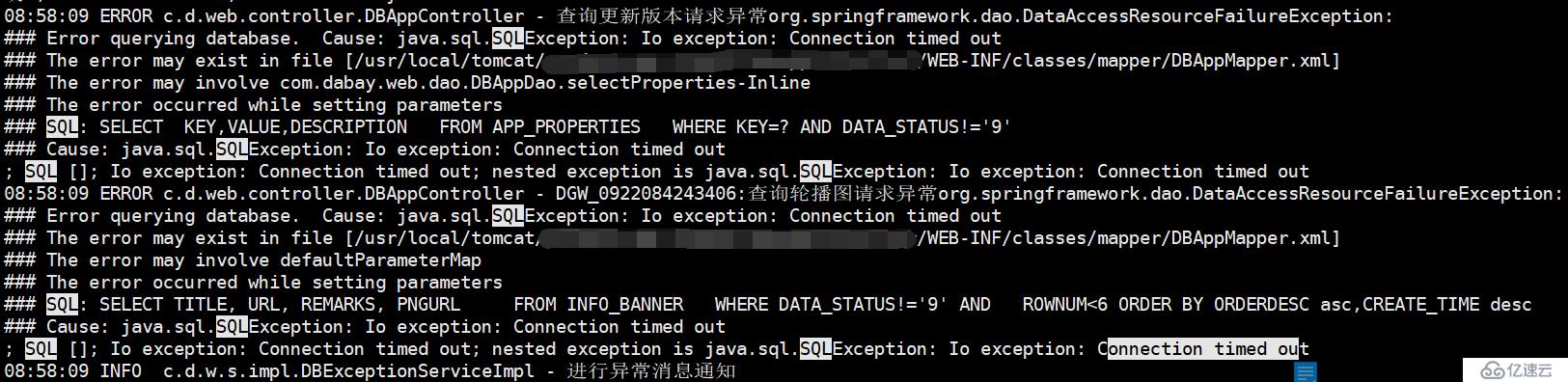
2,想到排查ORACLE數據庫是否正常,百度到了如下三個結果
一:查看數據庫監聽是否啟動
lsnrctl status
二:查看數據庫運行狀態,是否open
select instance_name,status from v$instance;
三:查看alert日志,查看是否有錯誤信息
SQL> show parameter background_dump
NAME TYPE
------------------------------------ ----------------------
VALUE
------------------------------
background_dump_dest string
/u01/app/oracle/diag/rdbms/just_test/test/trace
是的,有alert日志,接下來查看alert日志,如下
db_recovery_file_dest_size of 3882 MB is 45.88% used. This is a
user-specified limit on the amount of space that will be used by this
database for recovery-related files, and does not reflect the amount of
space available in the underlying filesystem or ASM diskgroup.
Fri Sep 22 02:01:05 2017
Starting background process CJQ0
Fri Sep 22 02:01:05 2017
CJQ0 started with pid=22, OS id=6797
Fri Sep 22 02:06:05 2017
Starting background process SMCO
Fri Sep 22 02:06:05 2017
SMCO started with pid=32, OS id=7393
Fri Sep 22 04:21:10 2017
Thread 1 cannot allocate new log, sequence 221
Private strand flush not complete
Current log# 1 seq# 220 mem# 0: /u01/app/oracle/oradata/hsrs_pro/redo01.log
Thread 1 advanced to log sequence 221 (LGWR switch)
Current log# 2 seq# 221 mem# 0: /u01/app/oracle/oradata/hsrs_pro/redo02.log
Fri Sep 22 09:00:35 2017
先看到了 Thread 1 cannot allocate new log, sequence 221,于是又百度了一下,找到了如下結果
(摘自 http://blog.csdn.net/zonelan/article/details/7613519)
這個實際上是個比較常見的錯誤。通常來說是因為在日志被寫滿時會切換 日志組,這個時候會觸發一次checkpoint,DBWR會把內存中的臟塊往數據文件中寫,只要沒寫結束就不會釋放這個日志組。如果歸檔模式被開啟的 話,還會伴隨著ARCH寫歸檔的過程。如果redo log產生的過快,當CPK或歸檔還沒完成,LGWR已經把其余的日志組寫滿,又要往當前的日志組里面寫redo log的時候,這個時候就會發生沖突,數據庫就會被掛起。并且一直會往alert.log中寫類似上面的錯誤信息。
于是有了以下的操作:
SQL> select group#,sequence#,bytes,members,status from v$log; #查看每組日志的狀態
GROUP# SEQUENCE# BYTES MEMBERS STATUS
---------- ---------- ---------- ---------- --------------------------------
1 220 52428800 1 INACTIVE ##空閑的
2 221 52428800 1 CURRENT ##當前的
3 219 52428800 1 INACTIVE ##空閑的
SQL> alter database add logfile group 4 ('/u01/app/oracle/oradata/xx/redo04.log') size 500M; 增加日志組
Database altered.
SQL> alter database add logfile group 5 ('/u01/app/oracle/oradata/xx/redo05.log') size 500M;
Database altered.
SQL> alter system switch logfile; 切換日志組SQL> select group#,sequence#,bytes,members,status from v$log; #查看狀態發現有了區別 GROUP# SEQUENCE# BYTES MEMBERS STATUS ---------- ---------- ---------- ---------- -------------------------------- 1 22052428800 1 INACTIVE 2 22152428800 1 ACTIVE 3 21952428800 1 INACTIVE 4 222 524288000 1 ACTIVE 5 223 524288000 1 CURRENT 經理過如上操作,突然看到了alert日志中有一個recovery 并且 tomcat應用日志中也有recovery這個單詞,于是又百度了一番。分別執行了如下命令(不懂什么意思) SQL> select * from v$flash_recovery_area_usage; SQL> select * from v$recovery_file_dest; 查看recovery的實際大小: NAME -------------------------------------------------------------------------------- SPACE_LIMIT SPACE_USED SPACE_RECLAIMABLE NUMBER_OF_FILES ----------- ---------- ----------------- --------------- /u01/app/oracle/recovery_area 4070572032 3926630400 2059067392 41 SQL> select * from v$flash_recovery_area_usage 2 ; FILE_TYPE PERCENT_SPACE_USED ---------------------------------------- ------------------ PERCENT_SPACE_RECLAIMABLE NUMBER_OF_FILES ------------------------- --------------- CONTROL FILE 0 00 REDO LOG 0 00 ARCHIVED LOG 0 00 FILE_TYPE PERCENT_SPACE_USED ---------------------------------------- ------------------ PERCENT_SPACE_RECLAIMABLE NUMBER_OF_FILES ------------------------- --------------- BACKUP PIECE 53.96 50.58 37 IMAGE COPY 42.5 04 FLASHBACK LOG 0 00 FILE_TYPE PERCENT_SPACE_USED ---------------------------------------- ------------------ PERCENT_SPACE_RECLAIMABLE NUMBER_OF_FILES ------------------------- --------------- FOREIGN ARCHIVED LOG 0 00 7 rows selected. SQL> show parameter db_recovery_file_dest_size; 最后發現這個才是我要找的 查看當前recovery的限制大小 NAME TYPE ------------------------------------ ---------------------- VALUE ------------------------------ db_recovery_file_dest_size big integer 3882M SQL> alter system set db_recovery_file_dest_size=5882M scope=spfile; 改大一點? System altered. SQL> show parameter db_recovery_file_dest_size; 但是好像并沒有用,還是這么大 NAME TYPE ------------------------------------ ---------------------- VALUE ------------------------------ db_recovery_file_dest_size big integer 3882M 好吧,仍然百度:)執行了如下命令好像管用了 SQL> alter system set db_recovery_file_dest_size=10G; System altered. SQL> show parameter db_recovery_file_dest_size; NAME TYPE ------------------------------------ ---------------------- VALUE ------------------------------ db_recovery_file_dest_size big integer 10G
先觀察看看吧~應用日志10點好像沒有超時報錯了~~ 完
補充一下,下面這倆貨的區別
scope=both scope=spfile Oracle spfile就是動態參數文件,里面設置了Oracle 的各種參數。所謂的動態, 就是說你可以在不關閉數據庫的情況下,更改數據庫參數,記錄在spfile里面。更改參數 的時候,有4種scope選項,scope就是范圍。 scope=spfile 僅僅更改spfile里面的記載,不更改內存,也就是不立即生效,而是等 下次數據庫啟動生效。 有一些參數只允許用這種方法更改,scope=memory 僅僅更改內存,不改spfile。也就是下次 啟動就失效了 scope=both 內存和spfile都更改,不指定scope參數,等同于scope=both。 ========================================================================================= 好吧,問題好像解決了 oracle 在每天凌晨2點自動重啟,登錄EM 查了一下jobs果然2點是有一個自動備份策略的,具體步驟如下: 1, su oracle 2, source .bash_profile 3, sqlplus /nolog 4, conn /as sysdba 5, emctl status dbconsole 檢查EM是否啟動,如果沒有==》 emctl start dbconsole [oracle@xx ~]$ emctl status dbconsole Oracle Enterprise Manager 11g Database Control Release 11.2.0.1.0 Copyright (c) 1996, 2009 Oracle Corporation. All rights reserved. https://xx:1158/em/console/aboutApplication Oracle Enterprise Manager 11g is running. ------------------------------------------------------------------ Logs are generated in directory /u01/app/oracle/product/11.2.0/dbhome_1/xx/sysman/log 6, 獲取到如上的地址(https://xx:1158/em/console/aboutApplication),在瀏覽器訪問 7,點開job
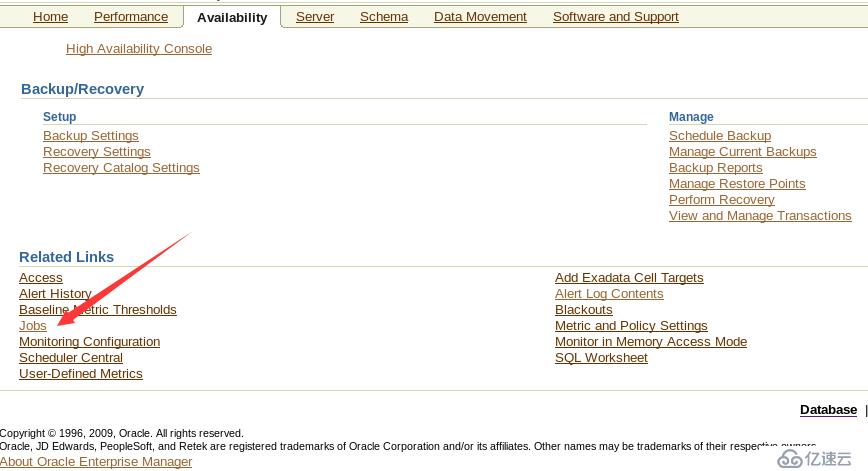 8,刪除job
8,刪除job
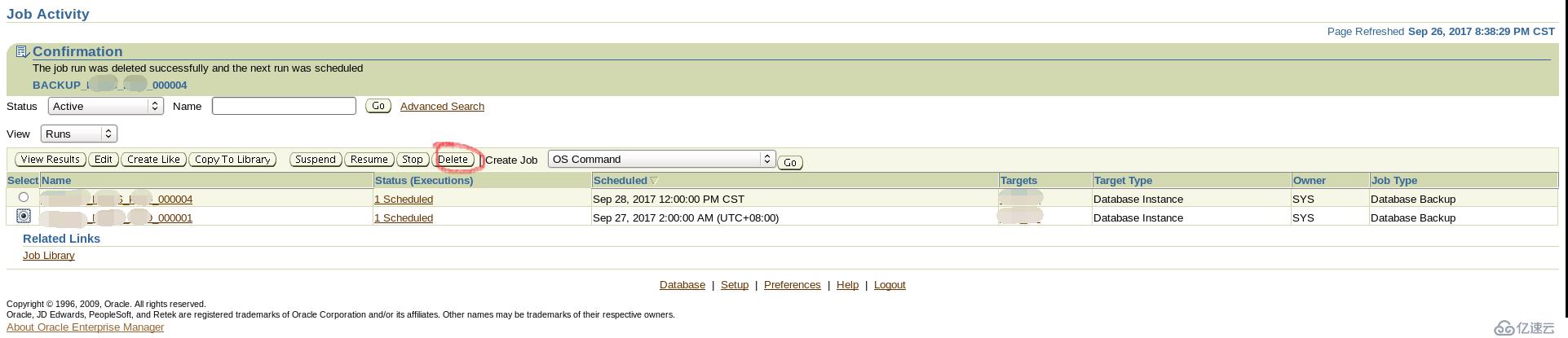
先這么觀察一下。明天看結果,另外,上面查看job步驟是可以修改備份策略的。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





