溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Java緩存技術怎么使用”,在日常操作中,相信很多人在Java緩存技術怎么使用問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Java緩存技術怎么使用”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
為什么我們需要緩存?
很久很久以前,在還沒有緩存的時候……用戶經常是去請求一個對象,而這個對象是從數據庫去取,然后,這個對象變得越來越大,這個用戶每次的請求時間也越來越長了,這也把數據庫弄得很痛苦,他無時不刻不在工作。所以,這個事情就把用戶和數據庫弄得很生氣,接著就有可能發生下面兩件事情:
1.用戶很煩,在抱怨,甚至不去用這個應用了(這是大多數情況下都會發生的)
2.數據庫為打包回家,離開這個應用,然后,就出現了麻煩(沒地方去存儲數據了)(發生在極少數情況下)
上帝派來了緩存
在幾年之后,IBM(60年代)的研究人員引進了一個新概念,它叫“緩存”。
什么是緩存?
正如開篇所講,緩存是“存貯數據(使用頻繁的數據)的臨時地方,因為取原始數據的代價太大了,所以我可以取得快一些。”
緩存可以認為是數據的池,這些數據是從數據庫里的真實數據復制出來的,并且為了能正確取回,被標上了標簽(鍵 ID)。太棒了
programmer one 已經知道這點了,但是他還不知道下面的緩存術語。
命中:
當客戶發起一個請求(我們說他想要查看一個產品信息),我們的應用接受這個請求,并且如果是在第一次檢查緩存的時候,需要去數據庫讀取產品信息。
如果在緩存中,一個條目通過一個標記被找到了,這個條目就會被使用、我們就叫它緩存命中。所以,命中率也就不難理解了。
Cache Miss:
但是這里需要注意兩點:
1. 如果還有緩存的空間,那么,沒有命中的對象會被存儲到緩存中來。
2. 如果緩存滿了,而又沒有命中緩存,那么就會按照某一種策略,把緩存中的舊對象踢出,而把新的對象加入緩存池。而這些策略統稱為替代策略(緩存算法),這些策略會決定到底應該提出哪些對象。
存儲成本:
當沒有命中時,我們會從數據庫取出數據,然后放入緩存。而把這個數據放入緩存所需要的時間和空間,就是存儲成本。
索引成本:
和存儲成本相仿。
失效:
當存在緩存中的數據需要更新時,就意味著緩存中的這個數據失效了。
替代策略:
當緩存沒有命中時,并且緩存容量已經滿了,就需要在緩存中踢出一個老的條目,加入一條新的條目,而到底應該踢出什么條目,就由替代策略決定。
最優替代策略:
最優的替代策略就是想把緩存中最沒用的條目給踢出去,但是未來是不能夠被預知的,所以這種策略是不可能實現的。但是有很多策略,都是朝著這個目前去努力。
緩存算法
沒有人能說清哪種緩存算法優于其他的緩存算法
Least Frequently Used(LFU):
大家好,我是 LFU,我會計算為每個緩存對象計算他們被使用的頻率。我會把最不常用的緩存對象踢走。
Least Recently User(LRU):
我是 LRU 緩存算法,我把最近最少使用的緩存對象給踢走。
我總是需要去了解在什么時候,用了哪個緩存對象。如果有人想要了解我為什么總能把最近最少使用的對象踢掉,是非常困難的。
瀏覽器就是使用了我(LRU)作為緩存算法。新的對象會被放在緩存的頂部,當緩存達到了容量極限,我會把底部的對象踢走,而技巧就是:我會把最新被訪問的緩存對象,放到緩存池的頂部。
所以,經常被讀取的緩存對象就會一直呆在緩存池中。有兩種方法可以實現我,array 或者是 linked list。
我的速度很快,我也可以被數據訪問模式適配。我有一個大家庭,他們都可以完善我,甚至做的比我更好(我確實有時會嫉妒,但是沒關系)。我家庭的一些成員包括 LRU2 和 2Q,他們就是為了完善 LRU 而存在的。
First in First out(FIFO):
我是先進先出,我是一個低負載的算法,并且對緩存對象的管理要求不高。我通過一個隊列去跟蹤所有的緩存對象,最近最常用的緩存對象放在后面,而更早的緩存對象放在前面,當緩存容量滿時,排在前面的緩存對象會被踢走,然后把新的緩存對象加進去。我很快,但是我并不適用。
Second Chance:
大家好,我是 second chance,我是通過 FIFO 修改而來的,被大家叫做 second chance 緩存算法,我比 FIFO 好的地方是我改善了 FIFO 的成本。我是 FIFO 一樣也是在觀察隊列的前端,但是很FIFO的立刻踢出不同,我會檢查即將要被踢出的對象有沒有之前被使用過的標志(1一個 bit 表示),沒有被使用過,我就把他踢出;否則,我會把這個標志位清除,然后把這個緩存對象當做新增緩存對象加入隊列。你可以想象就這就像一個環隊列。當我再一次在隊頭碰到這個對象時,由于他已經沒有這個標志位了,所以我立刻就把他踢開了。我在速度上比 FIFO 快。
其他的緩存算法還考慮到了下面幾點:
成本:如果緩存對象有不同的成本,應該把那些難以獲得的對象保存下來。
容量:如果緩存對象有不同的大小,應該把那些大的緩存對象清除,這樣就可以讓更多的小緩存對象進來了。
時間:一些緩存還保存著緩存的過期時間。電腦會失效他們,因為他們已經過期了。
根據緩存對象的大小而不管其他的緩存算法可能是有必要的。
看看緩存元素(緩存實體)
public class CacheElement
{
private Object objectValue;
private Object objectKey;
private int index;
private int hitCount; // getters and setters
}這個緩存實體擁有緩存的key和value,這個實體的數據結構會被以下所有緩存算法用到。
緩存算法的公用代碼
public final synchronized void addElement(Object key, Object value)
{
int index;
Object obj;
// get the entry from the table
obj = table.get(key);
// If we have the entry already in our table
// then get it and replace only its value.
obj = table.get(key);
if (obj != null)
{
CacheElement element;
element = (CacheElement) obj;
element.setObjectValue(value);
element.setObjectKey(key);
return;
}
}上面的代碼會被所有的緩存算法實現用到。這段代碼是用來檢查緩存元素是否在緩存中了,如果是,我們就替換它,但是如果我們找不到這個 key 對應的緩存,我們會怎么做呢?那我們就來深入的看看會發生什么吧!
現場訪問
今天的專題很特殊,因為我們有特殊的客人,事實上他們是我們想要聽的與會者,但是首先,先介紹一下我們的客人:Random Cache,FIFO Cache。讓我們從 Random Cache開始。
看看隨機緩存的實現
public final synchronized void addElement(Object key, Object value)
{
int index;
Object obj;
obj = table.get(key);
if (obj != null)
{
CacheElement element;// Just replace the value.
element = (CacheElement) obj;
element.setObjectValue(value);
element.setObjectKey(key);
return;
}// If we haven't filled the cache yet, put it at the end.
if (!isFull())
{
index = numEntries;
++numEntries;
}
else { // Otherwise, replace a random entry.
index = (int) (cache.length * random.nextFloat());
table.remove(cache[index].getObjectKey());
}
cache[index].setObjectValue(value);
cache[index].setObjectKey(key);
table.put(key, cache[index]);
}看看FIFO緩算法的實現
public final synchronized void addElement(Objectkey, Object value)
{
int index;
Object obj;
obj = table.get(key);
if (obj != null)
{
CacheElement element; // Just replace the value.
element = (CacheElement) obj;
element.setObjectValue(value);
element.setObjectKey(key);
return;
}
// If we haven't filled the cache yet, put it at the end.
if (!isFull())
{
index = numEntries;
++numEntries;
}
else { // Otherwise, replace the current pointer,
// entry with the new one.
index = current;
// in order to make Circular FIFO
if (++current >= cache.length)
current = 0;
table.remove(cache[index].getObjectKey());
}
cache[index].setObjectValue(value);
cache[index].setObjectKey(key);
table.put(key, cache[index]);
}看看LFU緩存算法的實現
public synchronized Object getElement(Object key)
{
Object obj;
obj = table.get(key);
if (obj != null)
{
CacheElement element = (CacheElement) obj;
element.setHitCount(element.getHitCount() + 1);
return element.getObjectValue();
}
return null;
}
public final synchronized void addElement(Object key, Object value)
{
Object obj;
obj = table.get(key);
if (obj != null)
{
CacheElement element; // Just replace the value.
element = (CacheElement) obj;
element.setObjectValue(value);
element.setObjectKey(key);
return;
}
if (!isFull())
{
index = numEntries;
++numEntries;
}
else
{
CacheElement element = removeLfuElement();
index = element.getIndex();
table.remove(element.getObjectKey());
}
cache[index].setObjectValue(value);
cache[index].setObjectKey(key);
cache[index].setIndex(index);
table.put(key, cache[index]);
}
public CacheElement removeLfuElement()
{
CacheElement[] elements = getElementsFromTable();
CacheElement leastElement = leastHit(elements);
return leastElement;
}
public static CacheElement leastHit(CacheElement[] elements)
{
CacheElement lowestElement = null;
for (int i = 0; i < elements.length; i++)
{
CacheElement element = elements[i];
if (lowestElement == null)
{
lowestElement = element;
}
else {
if (element.getHitCount() < lowestElement.getHitCount())
{
lowestElement = element;
}
}
}
return lowestElement;
}最重點的代碼,就應該是 leastHit 這個方法,這段代碼就是把hitCount 最低的元素找出來,然后刪除,給新進的緩存元素留位置
看看LRU緩存算法實現
private void moveToFront(int index)
{
int nextIndex, prevIndex;
if(head != index)
{
nextIndex = next[index];
prevIndex = prev[index];
// Only the head has a prev entry that is an invalid index
// so we don't check.
next[prevIndex] = nextIndex;
// Make sure index is valid. If it isn't, we're at the tail
// and don't set prev[next].
if(nextIndex >= 0)
prev[nextIndex] = prevIndex;
else
tail = prevIndex;
prev[index] = -1;
next[index] = head;
prev[head] = index;
head = index;
}
}
public final synchronized void addElement(Object key, Object value)
{
int index;Object obj;
obj = table.get(key);
if(obj != null)
{
CacheElement entry;
// Just replace the value, but move it to the front.
entry = (CacheElement)obj;
entry.setObjectValue(value);
entry.setObjectKey(key);
moveToFront(entry.getIndex());
return;
}
// If we haven't filled the cache yet, place in next available
// spot and move to front.
if(!isFull())
{
if(_numEntries > 0)
{
prev[_numEntries] = tail;
next[_numEntries] = -1;
moveToFront(numEntries);
}
++numEntries;
}
else { // We replace the tail of the list.
table.remove(cache[tail].getObjectKey());
moveToFront(tail);
}
cache[head].setObjectValue(value);
cache[head].setObjectKey(key);
table.put(key, cache[head]);
}這段代碼的邏輯如 LRU算法 的描述一樣,把再次用到的緩存提取到最前面,而每次刪除的都是最后面的元素。
一般而言,現在互聯網應用(網站或App)的整體流程,可以概括如圖1所示,用戶請求從界面(瀏覽器或App界面)到網絡轉發、應用服務再到存儲(數據庫或文件系統),然后返回到界面呈現內容。
隨著互聯網的普及,內容信息越來越復雜,用戶數和訪問量越來越大,我們的應用需要支撐更多的并發量,同時我們的應用服務器和數據庫服務器所做的計算也越來越多。但是往往我們的應用服務器資源是有限的,且技術變革是緩慢的,數據庫每秒能接受的請求次數也是有限的(或者文件的讀寫也是有限的),如何能夠有效利用有限的資源來提供盡可能大的吞吐量?一個有效的辦法就是引入緩存,打破標準流程,每個環節中請求可以從緩存中直接獲取目標數據并返回,從而減少計算量,有效提升響應速度,讓有限的資源服務更多的用戶。
緩存也是一個數據模型對象,那么必然有它的一些特征:
命中率=返回正確結果數/請求緩存次數,命中率問題是緩存中的一個非常重要的問題,它是衡量緩存有效性的重要指標。命中率越高,表明緩存的使用率越高。
緩存中可以存放的最大元素的數量,一旦緩存中元素數量超過這個值(或者緩存數據所占空間超過其最大支持空間),那么將會觸發緩存啟動清空策略根據不同的場景合理的設置最大元素值往往可以一定程度上提高緩存的命中率,從而更有效的時候緩存。
如上描述,緩存的存儲空間有限制,當緩存空間被用滿時,如何保證在穩定服務的同時有效提升命中率?這就由緩存清空策略來處理,設計適合自身數據特征的清空策略能有效提升命中率。常見的一般策略有:
FIFO(first in first out)
先進先出策略,最先進入緩存的數據在緩存空間不夠的情況下(超出最大元素限制)會被優先被清除掉,以騰出新的空間接受新的數據。策略算法主要比較緩存元素的創建時間。在數據實效性要求場景下可選擇該類策略,優先保障最新數據可用。
LFU(less frequently used)
最少使用策略,無論是否過期,根據元素的被使用次數判斷,清除使用次數較少的元素釋放空間。策略算法主要比較元素的hitCount(命中次數)。在保證高頻數據有效性場景下,可選擇這類策略。
LRU(least recently used)
最近最少使用策略,無論是否過期,根據元素最后一次被使用的時間戳,清除最遠使用時間戳的元素釋放空間。策略算法主要比較元素最近一次被get使用時間。在熱點數據場景下較適用,優先保證熱點數據的有效性。
除此之外,還有一些簡單策略比如:
根據過期時間判斷,清理過期時間最長的元素;
根據過期時間判斷,清理最近要過期的元素;
隨機清理;
根據關鍵字(或元素內容)長短清理等。
雖然從硬件介質上來看,無非就是內存和硬盤兩種,但從技術上,可以分成內存、硬盤文件、數據庫。
內存:將緩存存儲于內存中是最快的選擇,無需額外的I/O開銷,但是內存的缺點是沒有持久化落地物理磁盤,一旦應用異常break down而重新啟動,數據很難或者無法復原。
硬盤:一般來說,很多緩存框架會結合使用內存和硬盤,在內存分配空間滿了或是在異常的情況下,可以被動或主動的將內存空間數據持久化到硬盤中,達到釋放空間或備份數據的目的。
數據庫:前面有提到,增加緩存的策略的目的之一就是為了減少數據庫的I/O壓力。現在使用數據庫做緩存介質是不是又回到了老問題上了?其實,數據庫也有很多種類型,像那些不支持SQL,只是簡單的key-value存儲結構的特殊數據庫(如BerkeleyDB和Redis),響應速度和吞吐量都遠遠高于我們常用的關系型數據庫等。
緩存有各類特征,而且有不同介質的區別,那么實際工程中我們怎么去對緩存分類呢?在目前的應用服務框架中,比較常見的,時根據緩存雨應用的藕合度,分為local cache(本地緩存)和remote cache(分布式緩存):
本地緩存:指的是在應用中的緩存組件,其最大的優點是應用和cache是在同一個進程內部,請求緩存非常快速,沒有過多的網絡開銷等,在單應用不需要集群支持或者集群情況下各節點無需互相通知的場景下使用本地緩存較合適;同時,它的缺點也是應為緩存跟應用程序耦合,多個應用程序無法直接的共享緩存,各應用或集群的各節點都需要維護自己的單獨緩存,對內存是一種浪費。
分布式緩存:指的是與應用分離的緩存組件或服務,其最大的優點是自身就是一個獨立的應用,與本地應用隔離,多個應用可直接的共享緩存。
目前各種類型的緩存都活躍在成千上萬的應用服務中,還沒有一種緩存方案可以解決一切的業務場景或數據類型,我們需要根據自身的特殊場景和背景,選擇最適合的緩存方案。緩存的使用是程序員、架構師的必備技能,好的程序員能根據數據類型、業務場景來準確判斷使用何種類型的緩存,如何使用這種緩存,以最小的成本最快的效率達到最優的目的。
個別場景下,我們只需要簡單的緩存數據的功能,而無需關注更多存取、清空策略等深入的特性時,直接編程實現緩存則是最便捷和高效的。
a. 成員變量或局部變量實現
簡單代碼示例如下:
public void UseLocalCache(){
//一個本地的緩存變量
Map<String, Object> localCacheStoreMap = new HashMap<String, Object>();
List<Object> infosList = this.getInfoList();
for(Object item:infosList){
if(localCacheStoreMap.containsKey(item)){ //緩存命中 使用緩存數據
// todo
} else { // 緩存未命中 IO獲取數據,結果存入緩存
Object valueObject = this.getInfoFromDB();
localCacheStoreMap.put(valueObject.toString(), valueObject);
}
}
}
//示例
private List<Object> getInfoList(){
return new ArrayList<Object>();
}
//示例數據庫IO獲取
private Object getInfoFromDB(){
return new Object();
}以局部變量map結構緩存部分業務數據,減少頻繁的重復數據庫I/O操作。缺點僅限于類的自身作用域內,類間無法共享緩存。
b. 靜態變量實現
最常用的單例實現靜態資源緩存,代碼示例如下:
public class CityUtils {
private static final HttpClient httpClient = ServerHolder.createClientWithPool();
private static Map<Integer, String> cityIdNameMap = new HashMap<Integer, String>();
private static Map<Integer, String> districtIdNameMap = new HashMap<Integer, String>();
static {
HttpGet get = new HttpGet("http://gis-in.sankuai.com/api/location/city/all");
BaseAuthorizationUtils.generateAuthAndDateHeader(get,
BaseAuthorizationUtils.CLIENT_TO_REQUEST_MDC,
BaseAuthorizationUtils.SECRET_TO_REQUEST_MDC);
try {
String resultStr = httpClient.execute(get, new BasicResponseHandler());
JSONObject resultJo = new JSONObject(resultStr);
JSONArray dataJa = resultJo.getJSONArray("data");
for (int i = 0; i < dataJa.length(); i++) {
JSONObject itemJo = dataJa.getJSONObject(i);
cityIdNameMap.put(itemJo.getInt("id"), itemJo.getString("name"));
}
} catch (Exception e) {
throw new RuntimeException("Init City List Error!", e);
}
}
static {
HttpGet get = new HttpGet("http://gis-in.sankuai.com/api/location/district/all");
BaseAuthorizationUtils.generateAuthAndDateHeader(get,
BaseAuthorizationUtils.CLIENT_TO_REQUEST_MDC,
BaseAuthorizationUtils.SECRET_TO_REQUEST_MDC);
try {
String resultStr = httpClient.execute(get, new BasicResponseHandler());
JSONObject resultJo = new JSONObject(resultStr);
JSONArray dataJa = resultJo.getJSONArray("data");
for (int i = 0; i < dataJa.length(); i++) {
JSONObject itemJo = dataJa.getJSONObject(i);
districtIdNameMap.put(itemJo.getInt("id"), itemJo.getString("name"));
}
} catch (Exception e) {
throw new RuntimeException("Init District List Error!", e);
}
}
public static String getCityName(int cityId) {
String name = cityIdNameMap.get(cityId);
if (name == null) {
name = "未知";
}
return name;
}
public static String getDistrictName(int districtId) {
String name = districtIdNameMap.get(districtId);
if (name == null) {
name = "未知";
}
return name;
}
}O2O業務中常用的城市基礎基本信息判斷,通過靜態變量一次獲取緩存內存中,減少頻繁的I/O讀取,靜態變量實現類間可共享,進程內可共享,緩存的實時性稍差。
這類緩存實現,優點是能直接在heap區內讀寫,最快也最方便;缺點同樣是受heap區域影響,緩存的數據量非常有限,同時緩存時間受GC影響。主要滿足單機場景下的小數據量緩存需求,同時對緩存數據的變更無需太敏感感知,如上一般配置管理、基礎靜態數據等場景。
Ehcache是現在最流行的純Java開源緩存框架,配置簡單、結構清晰、功能強大,是一個非常輕量級的緩存實現,我們常用的Hibernate里面就集成了相關緩存功能。
主要特性:
快速,針對大型高并發系統場景,Ehcache的多線程機制有相應的優化改善。
簡單,很小的jar包,簡單配置就可直接使用,單機場景下無需過多的其他服務依賴。
支持多種的緩存策略,靈活。
緩存數據有兩級:內存和磁盤,與一般的本地內存緩存相比,有了磁盤的存儲空間,將可以支持更大量的數據緩存需求。
具有緩存和緩存管理器的偵聽接口,能更簡單方便的進行緩存實例的監控管理。
支持多緩存管理器實例,以及一個實例的多個緩存區域。
注意:Ehcache的超時設置主要是針對整個cache實例設置整體的超時策略,而沒有較好的處理針對單獨的key的個性的超時設置(有策略設置,但是比較復雜,就不描述了),因此,在使用中要注意過期失效的緩存元素無法被GC回收,時間越長緩存越多,內存占用也就越大,內存泄露的概率也越大。
memcached是應用較廣的開源分布式緩存產品之一,它本身其實不提供分布式解決方案。在服務端,memcached集群環境實際就是一個個memcached服務器的堆積,環境搭建較為簡單;cache的分布式主要是在客戶端實現,通過客戶端的路由處理來達到分布式解決方案的目的。客戶端做路由的原理非常簡單,應用服務器在每次存取某key的value時,通過某種算法把key映射到某臺memcached服務器nodeA上。
無特殊場景下,key-value能滿足需求的前提下,使用memcached分布式集群是較好的選擇,搭建與操作使用都比較簡單;分布式集群在單點故障時,只影響小部分數據異常,目前還可以通過Magent緩存代理模式,做單點備份,提升高可用;整個緩存都是基于內存的,因此響應時間是很快,不需要額外的序列化、反序列化的程序,但同時由于基于內存,數據沒有持久化,集群故障重啟數據無法恢復。高版本的memcached已經支持CAS模式的原子操作,可以低成本的解決并發控制問題。
Redis是一個遠程內存數據庫(非關系型數據庫),性能強勁,具有復制特性以及解決問題而生的獨一無二的數據模型。它可以存儲鍵值對與5種不同類型的值之間的映射,可以將存儲在內存的鍵值對數據持久化到硬盤,可以使用復制特性來擴展讀性能,還可以使用客戶端分片來擴展寫性能。
個人總結了以下多種Web應用場景,在這些場景下可以充分的利用Redis的特性,大大提高效率。
在主頁中顯示最新的項目列表:Redis使用的是常駐內存的緩存,速度非常快。LPUSH用來插入一個內容ID,作為關鍵字存儲在列表頭部。LTRIM用來限制列表中的項目數最多為5000。如果用戶需要的檢索的數據量超越這個緩存容量,這時才需要把請求發送到數據庫。
刪除和過濾:如果一篇文章被刪除,可以使用LREM從緩存中徹底清除掉。
排行榜及相關問題:排行榜(leader board)按照得分進行排序。ZADD命令可以直接實現這個功能,而ZREVRANGE命令可以用來按照得分來獲取前100名的用戶,ZRANK可以用來獲取用戶排名,非常直接而且操作容易。
按照用戶投票和時間排序:排行榜,得分會隨著時間變化。LPUSH和LTRIM命令結合運用,把文章添加到一個列表中。一項后臺任務用來獲取列表,并重新計算列表的排序,ZADD命令用來按照新的順序填充生成列表。列表可以實現非常快速的檢索,即使是負載很重的站點。
過期項目處理:使用Unix時間作為關鍵字,用來保持列表能夠按時間排序。對current_time和time_to_live進行檢索,完成查找過期項目的艱巨任務。另一項后臺任務使用ZRANGE…WITHSCORES進行查詢,刪除過期的條目。
計數:進行各種數據統計的用途是非常廣泛的,比如想知道什么時候封鎖一個IP地址。INCRBY命令讓這些變得很容易,通過原子遞增保持計數;GETSET用來重置計數器;過期屬性用來確認一個關鍵字什么時候應該刪除。
特定時間內的特定項目:這是特定訪問者的問題,可以通過給每次頁面瀏覽使用SADD命令來解決。SADD不會將已經存在的成員添加到一個集合。
Pub/Sub:在更新中保持用戶對數據的映射是系統中的一個普遍任務。Redis的pub/sub功能使用了SUBSCRIBE、UNSUBSCRIBE和PUBLISH命令,讓這個變得更加容易。
隊列:在當前的編程中隊列隨處可見。除了push和pop類型的命令之外,Redis還有阻塞隊列的命令,能夠讓一個程序在執行時被另一個程序添加到隊列。
前面一節說到了《 為什么說Redis是單線程的以及Redis為什么這么快!》,今天給大家整理一篇關于Redis經常被問到的問題:緩存雪崩、緩存穿透、緩存預熱、緩存更新、緩存降級等概念的入門及簡單解決方案。
緩存雪崩我們可以簡單的理解為:由于原有緩存失效,新緩存未到期間(例如:我們設置緩存時采用了相同的過期時間,在同一時刻出現大面積的緩存過期),所有原本應該訪問緩存的請求都去查詢數據庫了,而對數據庫CPU和內存造成巨大壓力,嚴重的會造成數據庫宕機。從而形成一系列連鎖反應,造成整個系統崩潰。
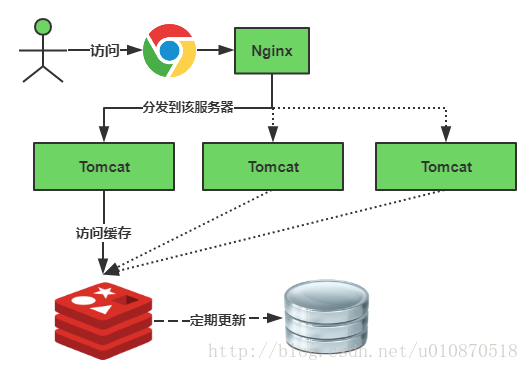
緩存正常從Redis中獲取,示意圖如下:
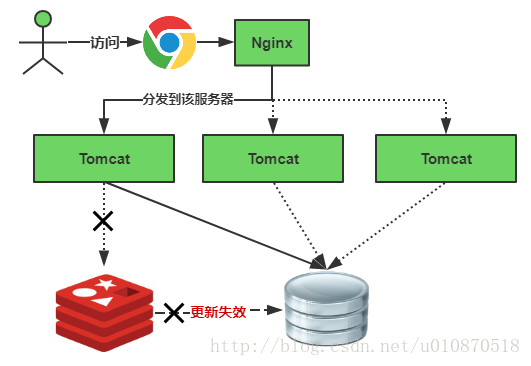
緩存失效瞬間示意圖如下:
緩存失效時的雪崩效應對底層系統的沖擊非常可怕!大多數系統設計者考慮用加鎖或者隊列的方式保證來保證不會有大量的線程對數據庫一次性進行讀寫,從而避免失效時大量的并發請求落到底層存儲系統上。還有一個簡單方案就時講緩存失效時間分散開,比如我們可以在原有的失效時間基礎上增加一個隨機值,比如1-5分鐘隨機,這樣每一個緩存的過期時間的重復率就會降低,就很難引發集體失效的事件。
以下簡單介紹兩種實現方式的偽代碼:
(1)碰到這種情況,一般并發量不是特別多的時候,使用最多的解決方案是加鎖排隊,偽代碼如下:
//偽代碼
public object GetProductListNew() {
int cacheTime = 30;
String cacheKey = "product_list";
String lockKey = cacheKey;
String cacheValue = CacheHelper.get(cacheKey);
if (cacheValue != null) {
return cacheValue;
} else {
synchronized(lockKey) {
cacheValue = CacheHelper.get(cacheKey);
if (cacheValue != null) {
return cacheValue;
} else {
//這里一般是sql查詢數據
cacheValue = GetProductListFromDB();
CacheHelper.Add(cacheKey, cacheValue, cacheTime);
}
}
return cacheValue;
}
}加鎖排隊只是為了減輕數據庫的壓力,并沒有提高系統吞吐量。假設在高并發下,緩存重建期間key是鎖著的,這是過來1000個請求999個都在阻塞的。同樣會導致用戶等待超時,這是個治標不治本的方法!
注意:加鎖排隊的解決方式分布式環境的并發問題,有可能還要解決分布式鎖的問題;線程還會被阻塞,用戶體驗很差!因此,在真正的高并發場景下很少使用!
(2)還有一個解決辦法解決方案是:給每一個緩存數據增加相應的緩存標記,記錄緩存的是否失效,如果緩存標記失效,則更新數據緩存,實例偽代碼如下:
//偽代碼
public object GetProductListNew() {
int cacheTime = 30;
String cacheKey = "product_list";
//緩存標記
String cacheSign = cacheKey + "_sign";
String sign = CacheHelper.Get(cacheSign);
//獲取緩存值
String cacheValue = CacheHelper.Get(cacheKey);
if (sign != null) {
return cacheValue; //未過期,直接返回
} else {
CacheHelper.Add(cacheSign, "1", cacheTime);
ThreadPool.QueueUserWorkItem((arg) -> {
//這里一般是 sql查詢數據
cacheValue = GetProductListFromDB();
//日期設緩存時間的2倍,用于臟讀
CacheHelper.Add(cacheKey, cacheValue, cacheTime * 2);
});
return cacheValue;
}
}解釋說明:
1、緩存標記:記錄緩存數據是否過期,如果過期會觸發通知另外的線程在后臺去更新實際key的緩存;
2、緩存數據:它的過期時間比緩存標記的時間延長1倍,例:標記緩存時間30分鐘,數據緩存設置為60分鐘。 這樣,當緩存標記key過期后,實際緩存還能把舊數據返回給調用端,直到另外的線程在后臺更新完成后,才會返回新緩存。
關于緩存崩潰的解決方法,這里提出了三種方案:使用鎖或隊列、設置過期標志更新緩存、為key設置不同的緩存失效時間,還有一各被稱為“二級緩存”的解決方法,有興趣的讀者可以自行研究。
緩存穿透是指用戶查詢數據,在數據庫沒有,自然在緩存中也不會有。這樣就導致用戶查詢的時候,在緩存中找不到,每次都要去數據庫再查詢一遍,然后返回空(相當于進行了兩次無用的查詢)。這樣請求就繞過緩存直接查數據庫,這也是經常提的緩存命中率問題。
有很多種方法可以有效地解決緩存穿透問題,最常見的則是采用布隆過濾器,將所有可能存在的數據哈希到一個足夠大的bitmap中,一個一定不存在的數據會被這個bitmap攔截掉,從而避免了對底層存儲系統的查詢壓力。
另外也有一個更為簡單粗暴的方法,如果一個查詢返回的數據為空(不管是數據不存在,還是系統故障),我們仍然把這個空結果進行緩存,但它的過期時間會很短,最長不超過五分鐘。通過這個直接設置的默認值存放到緩存,這樣第二次到緩沖中獲取就有值了,而不會繼續訪問數據庫,這種辦法最簡單粗暴!
//偽代碼
public object GetProductListNew() {
int cacheTime = 30;
String cacheKey = "product_list";
String cacheValue = CacheHelper.Get(cacheKey);
if (cacheValue != null) {
return cacheValue;
}
cacheValue = CacheHelper.Get(cacheKey);
if (cacheValue != null) {
return cacheValue;
} else {
//數據庫查詢不到,為空
cacheValue = GetProductListFromDB();
if (cacheValue == null) {
//如果發現為空,設置個默認值,也緩存起來
cacheValue = string.Empty;
}
CacheHelper.Add(cacheKey, cacheValue, cacheTime);
return cacheValue;
}
}把空結果,也給緩存起來,這樣下次同樣的請求就可以直接返回空了,即可以避免當查詢的值為空時引起的緩存穿透。同時也可以單獨設置個緩存區域存儲空值,對要查詢的key進行預先校驗,然后再放行給后面的正常緩存處理邏輯。
緩存預熱這個應該是一個比較常見的概念,相信很多小伙伴都應該可以很容易的理解,緩存預熱就是系統上線后,將相關的緩存數據直接加載到緩存系統。這樣就可以避免在用戶請求的時候,先查詢數據庫,然后再將數據緩存的問題!用戶直接查詢事先被預熱的緩存數據!
解決思路:
1、直接寫個緩存刷新頁面,上線時手工操作下;
2、數據量不大,可以在項目啟動的時候自動進行加載;
3、定時刷新緩存;
除了緩存服務器自帶的緩存失效策略之外(Redis默認的有6中策略可供選擇),我們還可以根據具體的業務需求進行自定義的緩存淘汰,常見的策略有兩種:
(1)定時去清理過期的緩存;
(2)當有用戶請求過來時,再判斷這個請求所用到的緩存是否過期,過期的話就去底層系統得到新數據并更新緩存。
兩者各有優劣,第一種的缺點是維護大量緩存的key是比較麻煩的,第二種的缺點就是每次用戶請求過來都要判斷緩存失效,邏輯相對比較復雜!具體用哪種方案,大家可以根據自己的應用場景來權衡。
當訪問量劇增、服務出現問題(如響應時間慢或不響應)或非核心服務影響到核心流程的性能時,仍然需要保證服務還是可用的,即使是有損服務。系統可以根據一些關鍵數據進行自動降級,也可以配置開關實現人工降級。
降級的最終目的是保證核心服務可用,即使是有損的。而且有些服務是無法降級的(如加入購物車、結算)。
在進行降級之前要對系統進行梳理,看看系統是不是可以丟卒保帥;從而梳理出哪些必須誓死保護,哪些可降級;比如可以參考日志級別設置預案:
(1)一般:比如有些服務偶爾因為網絡抖動或者服務正在上線而超時,可以自動降級;
(2)警告:有些服務在一段時間內成功率有波動(如在95~100%之間),可以自動降級或人工降級,并發送告警;
(3)錯誤:比如可用率低于90%,或者數據庫連接池被打爆了,或者訪問量突然猛增到系統能承受的最大閥值,此時可以根據情況自動降級或者人工降級;
(4)嚴重錯誤:比如因為特殊原因數據錯誤了,此時需要緊急人工降級。
到此,關于“Java緩存技術怎么使用”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。