溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
作者簡介:運籌 百度資深數據架構師
負責百度智能運維算法和策略的研究工作,致力于用算法和數據的力量解決運維問題。
干貨概覽
人生病了要去看醫生,程序生病了看的就是運維工程師了。醫生給病人看病要做很多檢查,然后拿著結果單子分析病因。運維工程師分析系統故障也會查看采集的監控指標,然后判斷根因是什么。
查看指標這事兒,說起來也不難。只要畫出指標的趨勢圖(指標值隨時間變化的曲線),有經驗的工程師很容易就能看出有沒有毛病,進而推斷故障的原因。不過呢,都說脫離開劑量說食物的毒性是耍流氓,查看指標這事也差不多。如果只有幾條指標需要查看,做個儀表盤就能一目了然,可是如果有成千上萬的指標呢?人家查抄大老虎的時候點鈔機都燒壞了好幾臺,如果人工查看這么多指標,腦子的下場估計也好不到哪兒去。所以說還是得靠“機器人”。
等等,“機器人”怎么能知道什么指標有毛病,什么指標沒毛病呢?就算能知道,把有毛病的指標挑出來工程師憑啥就能知道根因呢?所以,我們的“機器人醫生”必須能夠識別出指標的異常,然后還需要能把識別出的異常整理成工程師容易理解的報告才行。
傳統的辦法
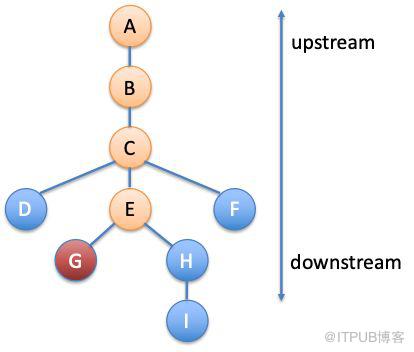
圖1 模塊調用關系圖
人工診斷故障的時候,工程師往往是根據腦子里的模塊調用關系圖(圖 1)來排查系統。很多時候,故障都是因為在最上游的前端模塊(圖 1中的A)上看到了很多失敗的請求發現的。這時,工程師就會沿著A往下查。因為A調用了B模塊,所以需要查看B的指標,如果有指標異常那么就懷疑是B導致了故障。然后再檢查B的直接下游模塊C,以此類推。在這個過程中,懷疑通過模塊的調用關系不斷往下傳遞,直到傳不下去為止。在圖 1的例子中懷疑最后就停在了倒霉蛋G的頭上,誰讓它沒有下游模塊呢。
總的來說,這就是模塊間把責任想辦法往下游推的過程。當然,真實的場景要更加復雜一些。并不是只要下游有異常就可以推的,還需要考察異常的程度。比如,如果倒霉蛋G的異常程度比E的異常程度小很多,根因就更有可能在E里面。
找到了根因模塊再去分析根因就容易多了,所以尋找根因模塊是故障診斷中很重要的步驟。
上面的過程可以很直接地變成一個工具:
做一個頁面展示模塊調用關系圖
工程師為每個指標配置黃金指標,以及黃金指標的閾值
在模塊圖中標出黃金指標有異常的模塊以及它們到達前端模塊的可能路徑
這個工具通過配置黃金指標及閾值的方式解決了指標以及如何判斷異常的問題,然后再通過模塊調用關系圖的方式呈現異常判斷的結果,解決了異常判斷和結果整理這兩個核心問題。
不過,傳統的辦法在實際使用中還是會碰到很多問題:
活的系統一定是不斷演化的,模塊的調用關系也隨之發生改變。為了保證工具里面的關系圖不會過時,就需要不斷從真實系統同步。干過系統梳理這種活的工程師都知道,這可不容易。如果整個系統使用統一的RPC中間件在模塊中通訊,那就可以通過分析RPC trace log的方式挖掘出調用關系圖來,不過“歷史代碼”通常會趴在路中間攔著你。
每個黃金指標通常只能覆蓋一部分的故障類型,新的故障一出現,就需要增加黃金指標。這樣一來配置工作——尤其是閾值的配置——就會不斷出現。另外,指標多了,就很容易出現“全國山河一片紅”的情況。大多數的模塊都被標出來的時候,工具也就沒啥用了。
大型的系統為了保證性能和可用性,常常需要在好幾個機房中部署鏡像系統。因為大多數的故障只發生在一個機房的系統中,所以工程師不但需要知道根因模塊是誰,還需要知道在哪個機房。這樣一來,每個機房都得有一個調用關系圖,工程師得一個一個地看。
理想的效果
傳統的方法作出來的診斷工具最多也就是半自動的,應用起來也受到很多的限制,所以我們就想做一個真正全自動、智能化的工具。
首先,我們希望新工具不要過于依賴于黃金指標,這樣指標的配置工作就能減少。但是,這反過來說明全自動的工具必須能夠掃描所有模塊上的所有指標,這樣才能做到沒有遺漏。所以,異常判斷不能再通過人工設置閾值的方式來進行,而必須是基本上無監督的(Unsupervised)。另外,不同指標的語意有很大差異,異常判斷的算法也必須足夠靈活,以適應不同指標的特點。
其次,我們希望工具不要太過依賴于調用關系圖,這意味著我們需要尋找一種新的方式來整理和呈現結果。其實,調用關系圖并不是必須的。在使用傳統診斷方法時,我們就發現一部分工程師經常脫離調用關系圖,直接按照黃金指標的異常程度從大到小檢查模塊。這是因為這部分工程師負責的系統黃金指標代表性強、容易理解,更重要的是不同模塊黃金指標的異常程度可以比較。
所以說,我們完全可以做一個診斷工具來產出根因模塊的推薦報告,報告的內容必須易于理解,推薦的順序也必須足夠準確。
實例指標的自動排查分析
我們以實例指標為例,介紹如何實現一個指標排查工具,達成理想的效果。排查工具的總體流程如圖 2所示。
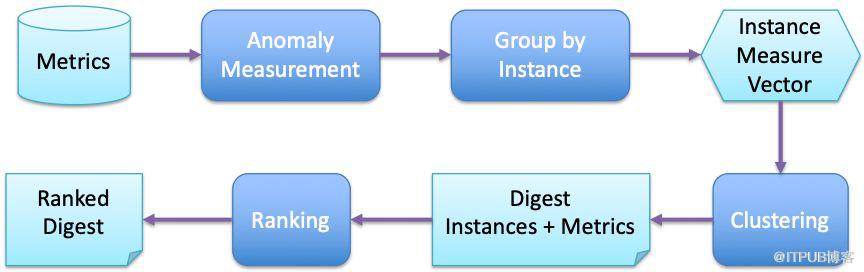
圖2 實例指標自動排查的總體流程
在第一步,所有被收集來的指標都會通過異常檢測算法賦予它們一個異常分數。比較兩個指標的異常分數就能夠知道它們的異常程度誰大誰小了。這一步的核心是要尋找一個方法能夠量化地衡量每個指標的異常,而且這個量化衡量出來的分數還可以在不同實例的不同指標之間比較。
第二步,我們把異常分數按照它們所屬的實例分組,每組形成一個向量(vector)。這時,每個實例都會對應一個向量,向量中的每個元素就是一個指標的異常分數。然后,模式(pattern)差不多的向量就可以通過聚類(clustering)算法聚成若干個摘要(digest)。這樣一來,工程師們就容易理解分析的結果了。
第三步,我們可以根據摘要中包含的實例以及指標的異常分數排序(ranking),形成推薦報告。
本文介紹了一種在服務發生故障時自動排查監控指標的工具,第一步利用了概率統計的方式估算每個指標的異常分數,第二步用聚類的方式把異常模式相近的實例聚集在一起形成摘要,第三步用ranking的方式向工程師推薦最有可能是根因的摘要。
由于運維場景的特點是數據量大,但是標定很少,生成標定的代價高昂而且容易出錯,接下來我們會詳細介紹如何利用概率統計、非監督學習和監督學習的方法來解決這個問題,敬請期待吧~
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





