溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
各位老鐵們,你們有沒有想老張,最近老張的才華被工作的繁忙所限制了,所以一直沒時間更博,今兒個時隔數日我們終于再次見面啦(很開心)!最近有部特別火的宮廷戲,不知道大家有沒有看,劇名叫做《延禧攻略》,講述得是一個宮女,一路過關斬將,最后成為皇上最寵愛的令貴妃的故事。加上我本人巨愛這類題材,所以癡迷得不得了。(好像暴露了自己沒有更博的真正原因哈哈)。宮廷類的劇,都是后宮嬪妃之間的爾虞吾詐,勾心斗角,有你沒我,有我沒你的殘酷事實。勝者為王,敗者為寇這種思想好像從古代就一直延續到今日。非要分出個勝負,分出個誰好,誰壞才罷休。
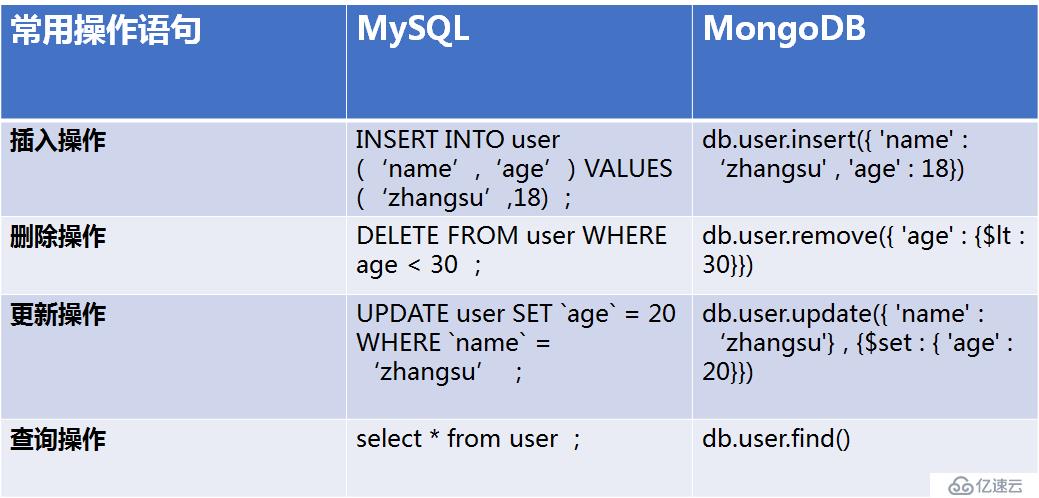
在數據庫領域也會有此類問題,老張我混跡開源數據庫圈多年。MySQL數據庫占領著開源數據庫的頭把交椅,MongoDB占領著NoSQL數據庫的第一位。我們來看下數據庫的整體排名情況;
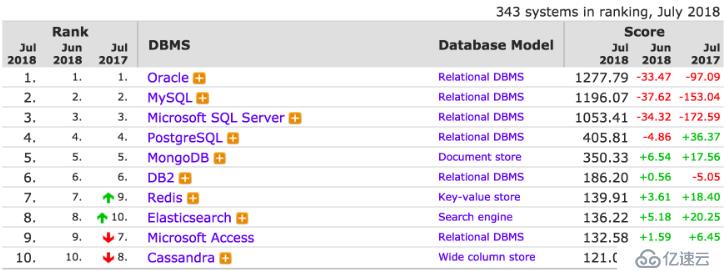
兩者都是第一,所有總會拿來比較。也會經常被人問及到諸如此類的問題MongoDB4.0已經問世了,而且支持事務了,是不是將來可以取代MySQL了。MySQL和MongoDB哪個數據庫好用啊。今天老張想通過這篇文章,帶著大家全方位解讀MySQL與MongoDB的區別。讓有困惑的老鐵們明白,沒有誰替代誰,只有哪個場景更適合誰。
我們從下面四個方向依次闡明兩者的區別。只有更了解彼此,讓能更好地利用它們的功能性。
我們先來了解一下MySQL這個數據庫;
再來學習一下MySQL數據庫的特點;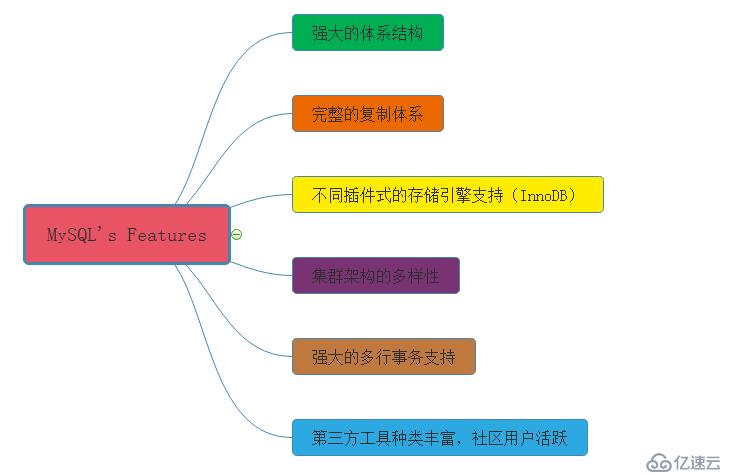
MySQL了解完,同理我們來了解MongoDB及其特點的介紹;
MongoDB特點介紹: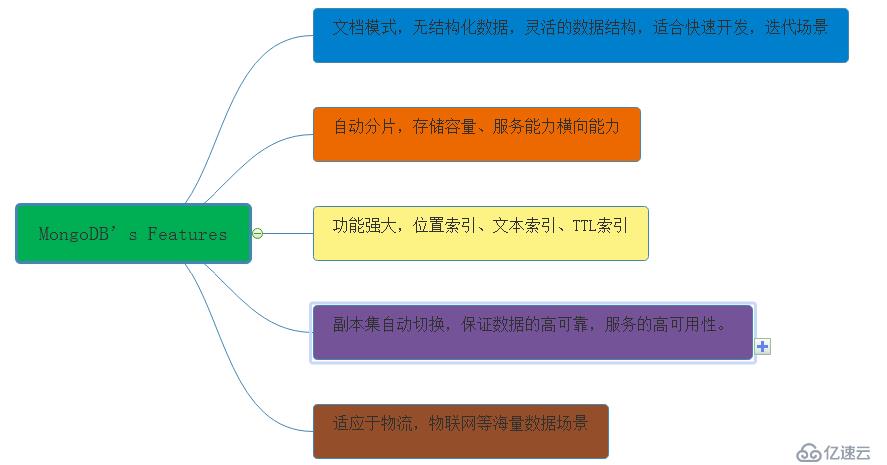
學習完第一部分之后,我們對兩者數據庫都有了一定的認識;接下來去從運維的角度來檢驗兩者的不同;


結論可以看出,關系型數據庫中的表,在MongoDB中叫做集合。行在MongoDB中叫做文檔。所以經常管MongoDB叫做文檔型數據庫。

在關系型數據庫中設計表,有些信息需要多表記錄。
而在MongoDB中,上面的三張表,就變成下面的這一段代碼就可以實現了。
{
_id:"M416",
name:"zhangsu",
phone:[1234,5678],
.....
}MongoDB表設計的特點
MySQL數據庫的配置叫做my.cnf,我們來看下它的記錄方式;
[client]
port = 3306
socket = /data/mysql/mysql.sock
[mysql]
prompt="\u@db \R:\m:\s [\d]> "
no-auto-rehash
[mysqld]
user = mysql
port = 3306
basedir = /usr/local/mysql
datadir = /data/mysql/
socket = /data/mysql/mysql.sock
pid-file = db.pid
character-set-server = utf8mb4
skip_name_resolve = 1
open_files_limit = 65535
back_log = 1024
max_connections = 512
max_connect_errors = 1000000
table_open_cache = 1024
table_definition_cache = 1024
table_open_cache_instances = 64
thread_stack = 512K
external-locking = FALSE
max_allowed_packet = 32M
sort_buffer_size = 4M
join_buffer_size = 4M
thread_cache_size = 768
#query_cache_size = 0
#query_cache_type = 0
interactive_timeout = 600
wait_timeout = 600
tmp_table_size = 32M
max_heap_table_size = 32M
slow_query_log = 1
slow_query_log_file = /data/mysql/slow.log
log-error = /data/mysql/error.log
long_query_time = 0.1
server-id = 3306101
log-bin = /data/mysql/mybinlog
sync_binlog = 1
binlog_cache_size = 4M
max_binlog_cache_size = 1G
max_binlog_size = 1G
expire_logs_days = 7
master_info_repository = TABLE
relay_log_info_repository = TABLE
gtid_mode = on
enforce_gtid_consistency = 1
log_slave_updates=1
binlog_format = row
relay_log_recovery = 1
relay-log-purge = 1
key_buffer_size = 32M
read_buffer_size = 8M
read_rnd_buffer_size = 4M
bulk_insert_buffer_size = 64M
#myisam_sort_buffer_size = 128M
#myisam_max_sort_file_size = 10G
#myisam_repair_threads = 1
lock_wait_timeout = 3600
explicit_defaults_for_timestamp = 1
innodb_thread_concurrency = 0
innodb_sync_spin_loops = 100
innodb_spin_wait_delay = 30
secure_file_priv=''
super_read_only=0
transaction_isolation = REPEATABLE-READ
#innodb_additional_mem_pool_size = 16M
innodb_buffer_pool_size = 1024M
innodb_buffer_pool_instances = 8
innodb_buffer_pool_load_at_startup = 1
innodb_buffer_pool_dump_at_shutdown = 1
innodb_data_file_path = ibdata1:100M:autoextend
innodb_flush_log_at_trx_commit = 1
innodb_log_buffer_size = 32M
innodb_log_file_size = 2G
innodb_log_files_in_group = 2
innodb_max_undo_log_size = 4G
innodb_io_capacity = 4000
innodb_io_capacity_max = 8000
innodb_flush_neighbors = 0
innodb_write_io_threads = 8
innodb_read_io_threads = 8
innodb_purge_threads = 4
innodb_page_cleaners = 4
innodb_open_files = 65535
innodb_max_dirty_pages_pct = 50
innodb_flush_method = O_DIRECT
innodb_lru_scan_depth = 4000
innodb_checksum_algorithm = crc32
#innodb_file_format = Barracuda
#innodb_file_format_max = Barracuda
innodb_lock_wait_timeout = 10
innodb_rollback_on_timeout = 1
innodb_print_all_deadlocks = 1
innodb_file_per_table = 1
innodb_online_alter_log_max_size = 4G
internal_tmp_disk_storage_engine = InnoDB
innodb_stats_on_metadata = 0
innodb_status_file = 1
[mysqldump]
quick
max_allowed_packet = 32M
MongoDB配置文件使用Yaml格式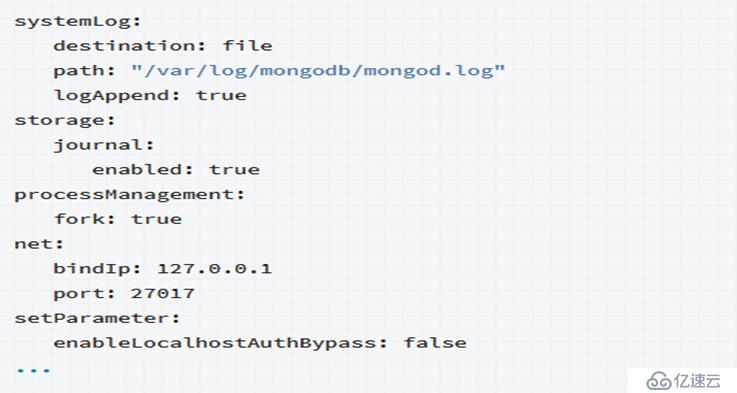
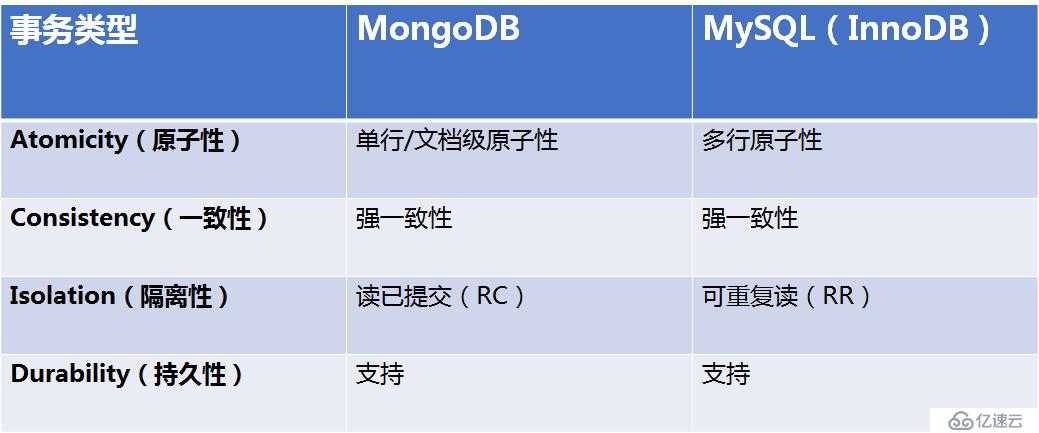
但隨著MongoDB 4.0的問世,它將支持多文檔事務,屆時MongoDB將成為唯一能夠同時支持速度,靈活性,JSON文檔模型優勢 和ACID數據完整性保證的數據庫。
所謂的多文檔事務,可以理解為關系型數據庫的多行事務。在關系型的事務支持中,大家幾乎無一例外支持同一事務內操作的原子性,即要么全部提交,要么全部回滾。這個同一事務內可以有多個操作,針對于多個表,或者是同一個表內的多行數據。
總結:隨著事務支持的增加,MongoDB功能上更接近于關系型數據庫,但是和關系型還是有本質上的區別:MySQL是基于關系模型的數據庫,對各種數據多變的場景如物聯網或社交化并沒有MongoDB支持得好。MongoDB的JSON模型則具有動態靈活,數據庫無須下線就可以進行模式變遷升級,在這種場景下面,選擇MongoDB會特別合適。
MySQL備份方式: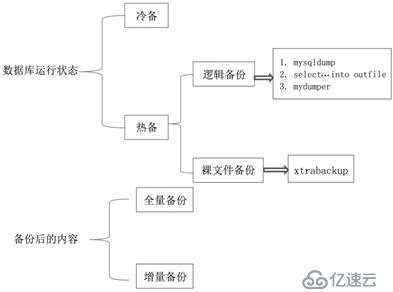
MongoDB備份方式:
邏輯備份與恢復
1.mongodump
2.mongorestore
3.mongoexport
4.mongoimport
注:MongoDB目前為止還沒有像xtrabackup這種好用的備份工具。所以一般來說,都是使用邏輯備份方式來進行操作
從運維角度我們對它們有了更深的認識之后,我們來從集群架構的維度出發,去探究其更深的不同之處。
我們先從MySQL復制的角度入手;然后再介紹MySQL高可用集群架構
MySQL主從復制原理圖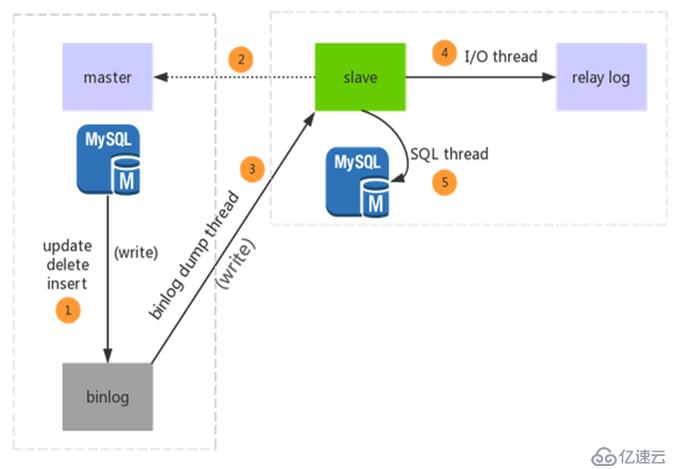
MySQL復制種類總結;
異步復制:
通常沒說明指的都是異步,即主庫執行完Commit后,在主庫寫入Binlog日志后即可成功返回客戶端,無需等Binlog日志傳送給從庫,一旦主庫宕機,有可能會丟失日志。
半同步復制:MySQL5.5版本之后引入了半同步復制功能,主從服務器必須同時安裝半同步復制插件,才能開啟該復制功能。在該功能下,確保從庫接收完主庫傳遞過來的binlog內容已經寫入到自己的relay log里面了,才會通知主庫上面的等待線程,該操作完畢。如果等待超時,超過rpl_semi_sync_master_timeout參數設置的時間,則關閉半同步復制,并自動轉換為異步復制模式,直到至少有一臺從庫通知主庫已經接收到binlog信息了為止。
多源復制:
所謂多源復制,就是把多臺主庫的數據同步到一臺從庫服務器上,從庫會創建通往每個主庫的管道。在MySQL5.7之前的版本中,只能實現一主一從、一主多從或者多主多從的復制架構,如果想要實現多主一從的復制,只能使用MariaDB。MySQL 5.7版本已經可以實現多主一從的復制。
并行復制:
使用MySQL5.7的并行復制功能。在5.6版本中就有了并行的概念,但其中的并行復制是基于庫級別的,即slave_parallel_type=database。但在這種模式下,只是基于多庫少表的情況,并不適用于真實的生產環境下。在MySQL 5.7版本中,真正實現了基于組提交的并行復制,簡單說就是主庫并行執行SQL語句,從庫也可以通過多個workers線程并發執行relay log中主庫提交的事務。想要開啟MySQL5.7的并行復制可以在從庫設置參數slave_parallel_workers>0,并把5.7版本中新添加的slave_parallel_type參數設置為LOGICAL_CLOCK。該參數有DATABASE和 LOGICAL_CLOCK兩個值。MySQL5.6默認是database。
MySQL高可用集群架構分類圖;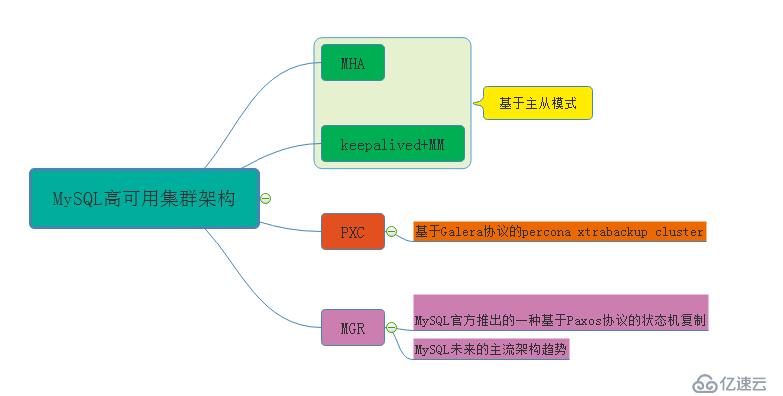
MHA: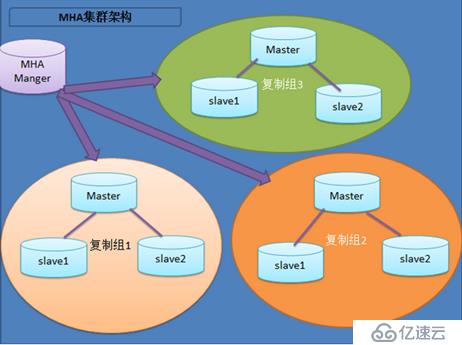
MHA的目的在于維持MySQL Replication中master庫的高可用性,其最大特點是可以修復多個slave之間的差異日志,最終使所有slave保持數據一致,然后從中選擇一個充當新的master,并將其他slave指向它。當master出現故障時,可以通過對比slave之間I/O thread 讀取主庫binlog的position號,選取最接近的slave作為備選主庫(備胎)。其他的從庫可以通過與備選主庫對比生成差異的中繼日志。在備選主庫上應用從原來master保存的binlog,同時將備選主庫提升為master。最后在其他slave上應用相應的差異中繼日志并從新的master開始復制。
雙主+keepalived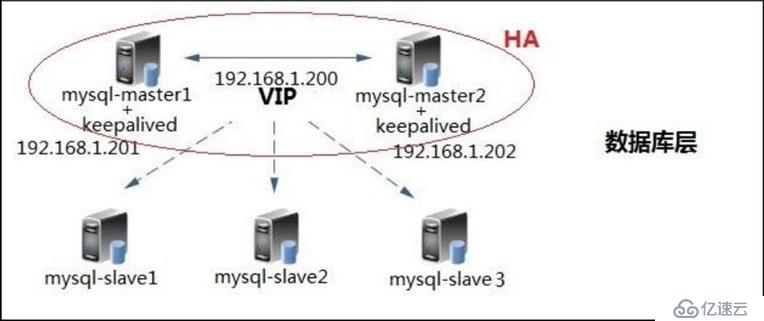
中小型規模的時候,采用這種架構是最省事的。
兩個節點可以采用簡單的一主一從模式,或者雙主模式,并且放置于同一個VLAN中,在master節點發生故障后,利用keepalived/heartbeat的高可用機制實現快速切換到slave節點。
PXC集群: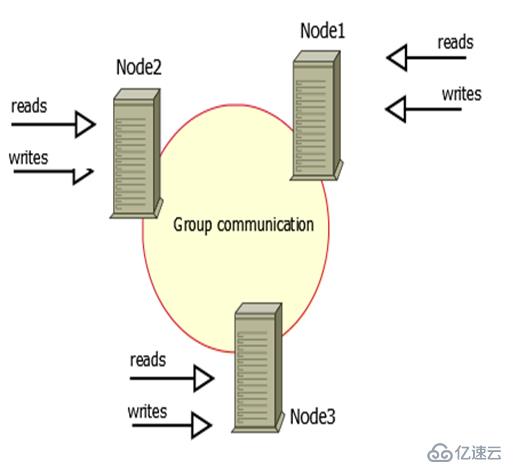
PXC是基于Galera協議的MySQL高可用集群架構。Galera產品是以Galera Cluster方式為MySQL提供高可用集群解決方案的。Galera Cluster就是集成了Galera插件的MySQL集群。Galera replication是Codership提供的MySQL數據同步方案,具有高可用性,方便擴展,并且可以實現多個MySQL節點間的數據同步復制與讀寫,可保障數據庫的服務高可用及數據強一致性。
MGR架構: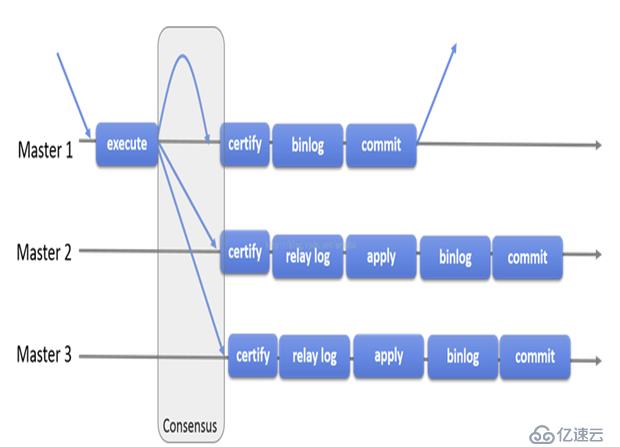
MySQL官方在5.7.17版本正式推出組復制(MySQL Group Replication,簡稱MGR)。master1,master2,master3,所有成員獨立完成各自的事務。當客戶端先發起一個更新事務,該事務先在本地執行,執行完成之后就要發起對事務的提交操作了。在還沒有真正提交之前需要將產生的復制寫集廣播出去,復制到其他成員。如果沖突檢測成功,組內決定該事務可以提交,其他成員可以應用,否則就回滾。最終,這意味著所有組內成員以相同的順序接收同一組事務。因此組內成員以相同的順序應用相同的修改,保證組內數據強一致性。
接下來介紹MongoDB的復制情況;
MongoDB復制集: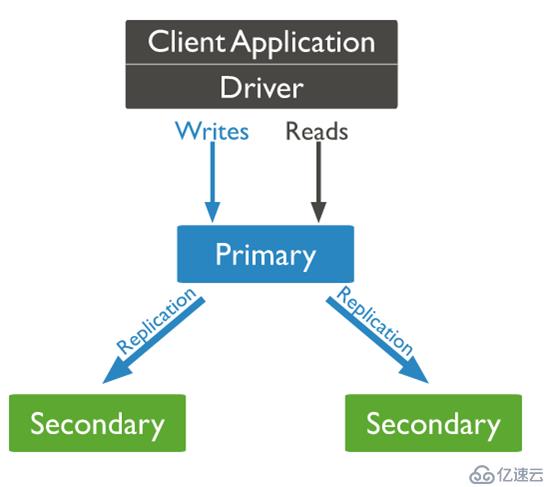
三副本架構是最基礎的復制集的架構,一主兩備模式。主節點接受外界的讀寫請求,向備節點進行數據同步。當主節點宕掉,會自動切換到備節點,不影響線上業務,防止單點故障。
MongoDB復制集自動切換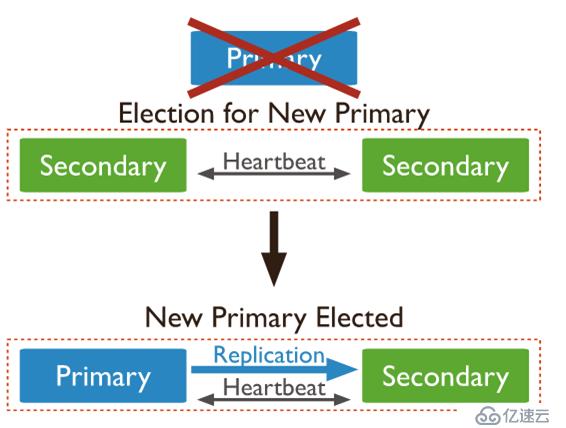
副本集的所有成員都可以接受讀取操作。 但是,默認情況下,應用程序將其讀取操作指向primary。
副本集可以有至多一個primary節點,primary節點宕機后,集群會觸發選舉以選出新的primary節點
在以下三成員節點副本集架構中,primary宕機后,觸發了一次選舉,從剩下的兩個secondary節點里,選舉出了一個新的primary節點。
MongoDB復制集讀寫分離設置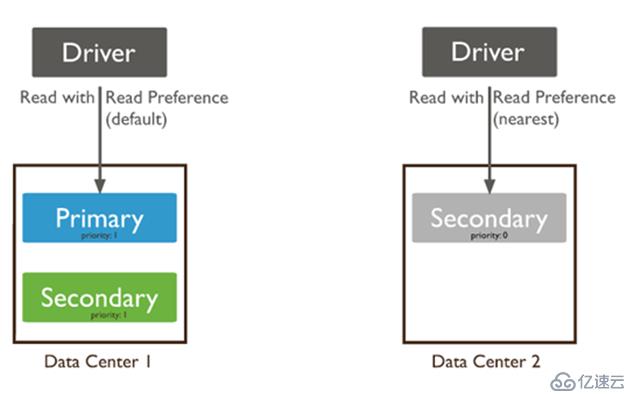
read preference 決定MongoDB客戶端從哪個節點上讀取數據。
默認情況下,應用程序將其讀取操作指向副本集中的primary節點。
指定read preference 選項時要注意:因為使用異步復制,復制延遲會導致secondary上的數據可能不是最新的。
默認情況下,復制集的所有讀請求都發到Primary,Driver可通過設置Read Preference來將讀請求路由到其他的節點。
primary: 默認規則,所有讀請求發到Primary
primaryPreferred: Primary優先,如果Primary不可達,請求Secondary
secondary: 所有的讀請求都發到secondary
secondaryPreferred:Secondary優先,當所有Secondary不可達時,請求Primary
nearest:讀請求發送到最近的可達節點上(通過ping探測得出最近的節點)
MongoDB分片架構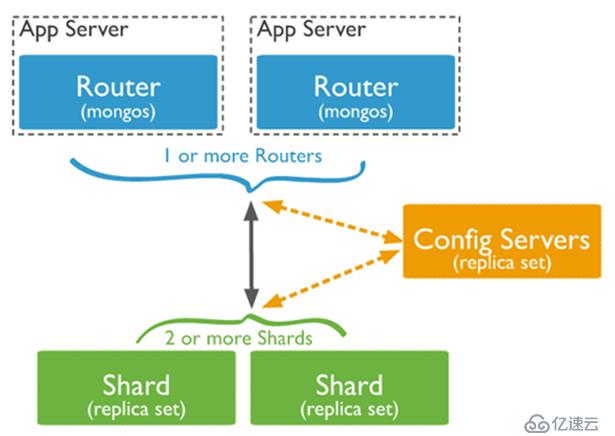
分片是一種在多臺機器上分配數據的方法。 MongoDB使用分片架構有助于您去管理非常大數量的數據集和高吞吐量操作的集群。
大數據量和高吞吐量的業務情況對單臺服務器來講是具備很大的挑戰性的。例如,高查詢率可能耗盡服務器的CPU容量。工作集大小超過系統內存,那么壓力則會給到磁盤上,這對IO來講不是我們所希望看到的。
MongoDB支持通過分片進行水平縮放。
總結:MySQL的復制種類很多,集群架構在選擇性上來說也比較多。但橫向擴展能力上,沒有MongoDB的分片架構擴展能力強。
最后一部分,我們來通過MySQL與MongoDB的不同應用場景;來對兩種數據庫做一個最后的總結;
正如開篇介紹MySQL特點時說的,MySQL使用得覆蓋率已經接近100%。從大型BAT,電商平臺,游戲公司,甚至諸多傳統行業也無不例外都在往MySQL數據庫方向靠攏,達到逐漸壟斷的趨勢。對于MongoDB 的應用也已經×××到各個領域,比如游戲、物流、電商、內容管理、社交、物聯網、視頻直播等。
2.物流場景:使用MongoDB存儲訂單信息,訂單狀態在運送過程中會不斷更新,以MongoDB內嵌數組的形式來存儲,一次查詢就能將訂單所有的變更讀取出來。
3.社交場景:使用MongoDB存儲用戶信息,以及用戶發表的朋友圈信息,通過地理位置索引實現附近的人、地點等功能
4.物聯網場景:使用MongoDB存儲所有接入的智能設備信息,以及設備匯報的日志信息,并對這些信息進行多維度的分析
對我而言,2009年開始接觸MySQL,我在2012年接觸的MongoDB的第一個版本2.1,對于這兩個數據庫真是手心手背都是肉。在我孤獨寂寞的時候,都是它們一直陪伴著我,感謝技術給我們帶來的簡單快樂。無論未來發展如何,沒有所謂的誰會替代誰,只是說它們各自都有不同的特點,促使在不同的應用場景下,我們使用誰更合適而已。這里沒有宮廷內斗,沒有爾虞我詐,只有那份最簡單地做技術的心,是現實版的延禧攻略!
對老張而言,寫篇文章很簡單,但真得希望可以幫助到那些剛入門或者想深入學習數據庫的同學們。能力有限,水平一般,哪里有介紹不到的地方,還望大家海涵!
在我們最愛的51CTO 13歲生日之際,作為51CTO專家博主,數據庫專家,我推出了自己的訂閱專欄十年老兵教你練一套正宗的MySQL降龍十八掌
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





