溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!

元數據是自動化運維的基礎,對元數據的管理和查詢貫穿整個運維的生命周期。我們從一個元數據的使用場景開始:
雙十一搶購火熱進行中,某電商后端實例的日志中出現了502錯誤碼,運維平臺監測到該異常并發送告警給相關運維。
在這個過程中,運維元數據發揮了什么作用?回答這個問題前,我們先回顧下元數據是什么。
運維系統中的元數據包括服務、機器及其關聯關系。服務元數據有服務名稱、所屬節點、運維人員以及域名等;機器元數據包含序列號、內存等資產信息,IP、機房等網絡信息、自定義標簽信息以及運行實例等部署信息。這些數據由資源管理模塊維護。
資源管理模塊對業務以樹的形態劃分層級,形成服務樹,從上到下依次為產品線、系統和應用三類節點。
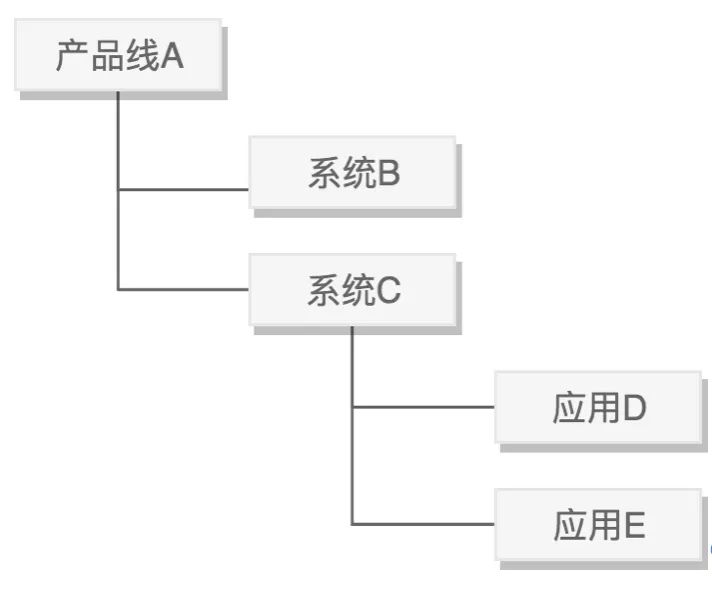
每個層級都可以關聯機器,且上層節點包含下層節點的機器。
通過添加節點的運維及研發角色,可以實現對服務和機器的權限控制。
這種層級結構將服務與服務,服務與機器關聯起來,可以直觀的表達服務和機器的歸屬關系,便于實現權限和配置的繼承。
回到上面的問題,報警流程中,服務所在機器的監控客戶端查詢自己所屬的應用,然后從配置管理模塊拉取相應監控配置,實現對日志的監控;監控業務端收到監控數據后,查找該機器對應的節點信息,將報警發送給節點的運維等人員。
此外,在DevOps落地實踐中,還存在多種其他應用場景
服務間關系拓撲可由遠程過程調用協議(RPC)間的調用關系鏈自動更新或者在應用上簡單維護服務間上下游關系。根據RPC調用關系鏈自動更新的關系拓撲圖主要用在業務運維上,可以幫助運維人員進行故障診斷,對整個業務系統運行狀態和部署架構全局一覽,清晰便捷. 應用上手工維護服務間上下游關系,可以用于上線版本依賴控制。上線申請單中指定上線版本依賴服務的版本,上線時系統自動檢查依賴的版本是否已經完成上線,如果依賴版本未上線,終止本次操作。
基于應用服務樹節點及權限,規范化批量任務執行操作。日常運維過程中,運維需要對線上機器進行一些批量操作,比如升級軟件版本、打補丁,清理日志等。為了避免手工操作帶來的風險,只允許運維同學,選擇所屬權限目標機器,進行操作。對于高危命令,可添加審批機制,增加流程規范。
當機器規模、人員規模逐漸擴大時,如何管理人、機器、權限會變得很復雜。通過元數據的動態管理,用戶只需要在服務樹上對人員進行角色設置,即可登錄堡壘機,獲得自己有權限的列表。通過服務樹的角色同樣可以添加哪些角色擁有su權限等訪問策略控制。
持續集成、自動化測試、持續交付都可以基于元數據,實現數據的唯一性管理。研發側,提交代碼,自動觸發服務樹應用對應的編譯任務,根據編譯規范生成部署包,放到版本庫;運維側,則對資源進行分配抽象到服務樹,將版本庫里面的代碼發布到服務樹實例對應的機器上;對于用戶側,通過負載均衡的接入,可以動態的進行服務樹實例流量的開關和擴縮容;部署日志則可以按照應用日志服務模塊進行檢索,方便排查問題。
在上面的監控流程中,客戶端和業務端是機器和服務關系數據的消費方,現實的運維場景中,二者也是運維數據的主要需求方。
客戶端指安裝在機器上,用以執行特定任務的程序,其需要的數據包括當前機器相關的信息,如機器機房、機架等設備屬性和歸屬節點、部署服務等業務屬性。
業務端主要指運維平臺中的上層系統,比如監控、部署等,當然也有跨平臺的其他系統,其需求涵蓋服務、機器與權限之間的相互查詢。
生產環境中,客戶端需要頻繁發起查詢請求,以保證其數據的準確性。持續增長的機器規模給系統帶來的壓力不容小覷。業務端由于復雜多樣的業務場景,其查詢條件多種多樣,查詢頻率和規模無法估量、難以控制,對系統可靠性和可用性提出了較高的要求。
傳統關系型數據庫難以承受高并發的查詢壓力,簡單的緩存又難以滿足條件復雜的查詢需求。
如何面對以上壓力,提供高效高可用的查詢服務,是亟需解決的問題。
為了應對以上兩種場景的挑戰,Devops引入了專注于提供數據查詢的名字服務,既可以實現服務的解耦,防止外部查詢影響資源管理模塊的性能,又可以提供高效穩定的查詢功能。
服務和機器數據由資源管理模塊維護,存儲到數據庫。名字服務定時從資源管理模塊同步數據,直接面向其他業務端和客戶端提供查詢服務。為提高響應速度,減少IO,元數據以map的形式存儲于內存中。
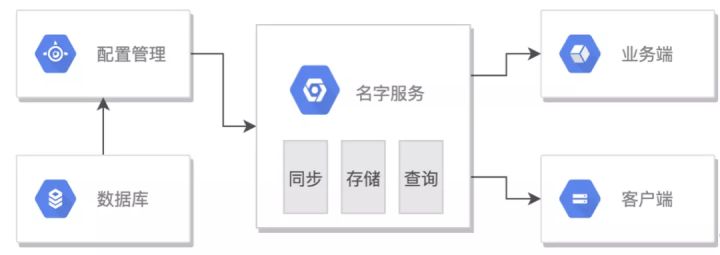
名字服務有三個邏輯層級,分別是同步、存儲和查詢,我們從這三個方面了解下其如何實現高可用:
保證數據的實效性和服務的可擴展性
同步的流程如下
由于該模塊定時從資源管理模塊增量/全量更新數據,在保證數據的準確性的同時對數據庫的壓力是線性且可控的,并且運行過程不依賴其他服務,因此查詢壓力增加時,可以通過水平擴容來迅速提高請求承載量。
回顧下開始的那個場景:監控客戶端會定期查詢獲取最新的數據。假設每分鐘請求一次,那么10萬臺機器就帶來了上千的 qps,如果每個客戶端請求多個接口或者每個機器部署多種客戶端,這個數值就會翻倍。
針對這種常用的查詢場景,名字服務通過緩存熱點數據來提高查詢性能。
假設客戶端需要通過 ip(也可能是uuid)查詢實例列表,而內存中實例是以id為key存儲的。如果依次遍歷全部實例進行ip匹配,會有一定的性能開銷。此時如果有一份ip與實例id的關聯關系的緩存,即可首先定位到對應實例的id,然后直接獲取id對應實例的詳情。
諸如此類的緩存,可以是產品線與機器的歸屬關系、機房與機器的關聯關系以及應用與實例從屬關系等。
由于數據同步環節是由名字服務主動發起的,所以該索引可以在每次更新之后重新生成,來保證其準確性。
上述緩存不能窮舉所有查詢信息,服務節點和機器的屬性(如機房、運行環境等)和標簽(如報警策略和其他運維自定義的標識等)都可能成為數據查詢的條件。針對此種情況,名字服務在緩存數據時將屬性和標簽解析為key-value模型,使用規定的請求格式便可實現查詢。
格式定義為Key1_value1.Keys_value2.keyN_valueN,其中常規屬性的key以大寫字母開頭,自定義標簽的 key以小寫字母開頭。例如,當名字服務收到格式為Product_trade.Idc_huabei.env_pre的查詢請求時,會先根據Product獲取trade產品線的機器ID集合,然后與huabei機房的機器ID集合取交集,再根據該ID集合獲取機器集合,最后在機器集合中根據標簽匹配出pre環境的機器集合。
DevOps將元數據的管理與查詢業務分開維護,元數據的變更通過資源管理實現,數據查詢通過名字服務實現。
資源管理通過層級結構維護了服務和機器的關系,并通過角色實現權限的劃分。
名字服務只依賴資源管理,便于搭建,易于擴容,可以提供穩定的服務;結合業務場景,通過對熱數據緩存實現了較高的查詢效率;支持多條件查詢,滿足復雜的業務需求。
歡迎點擊“ 京東云 ”了解更多精彩內容

免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





