溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關如何使用Python的簡化方法的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
邏輯回歸的目標是什么?
在邏輯回歸中,我們希望根據一個或多個自變量(X)對因變量(Y)進行建模。這是一種分類方法。此算法用于分類的因變量。Y使用一個函數建模,該函數為X的所有值提供0到1之間的輸出。在邏輯回歸中,使用Sigmoid(aka Logistic)函數。
使用混淆矩陣進行模型評估
在針對某些訓練數據訓練邏輯回歸模型之后,我們將評估模型在某些測試數據上的性能。為此,我們使用混淆矩陣(Confusion Matrix)。混淆矩陣是一個表,通常用于描述分類模型在一組已知真實值的測試數據上的性能。下面給出的是混淆矩陣。
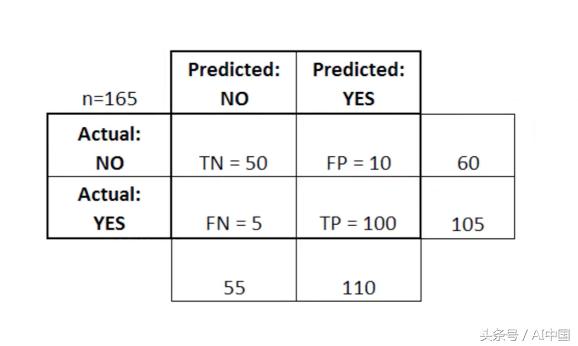
TP代表真正例(True Positive),即我們預測為"是(yes)"且實際值為"真(true)"的情況。TN代表真負例(True Negative),即我們預測為"否(no)"且實際值為"假(false)"的情況。FP代表假正例(False Positive),這是我們預測為"是(yes)",實際值為"假(false)"的情況。FN代表假負例(False Negative),這是案例我們預測為"否(no)",實際值是"真(true)"的情況。
我們從混淆矩陣中推斷出什么?
混淆矩陣有助于我們確定模型預測是正確的,或者換句話說,模型的準確性。通過上面的表格,它給出:
(TP+TN )/Total = 100+50/165 =0.91
這意味著該模型的正確度為91%。混淆矩陣還用于測量錯誤率,該錯誤率由下式給出:
(FP+ FN)/Total=15/165 = 0.09
模型中有9%的錯誤。
在本文中,我們將在python中處理非常簡單的步驟來模擬邏輯回歸。
Python代碼詳細解釋
我們將觀察數據、分析數據,將其可視化,清理數據,構建邏輯回歸模型,分成訓練和測試數據,進行預測并最終評估。所有這些都將一步一步完成,我們將要處理的數據是kaggle.com提供的"泰坦尼克號數據集"。這是一個非常著名的數據集,通常是學生基于分類學習機器學習的第一步。我們正在嘗試預測分類:生存或死亡
首先,我們將導入numpy和pandas庫:

我們來進行可視化導入:

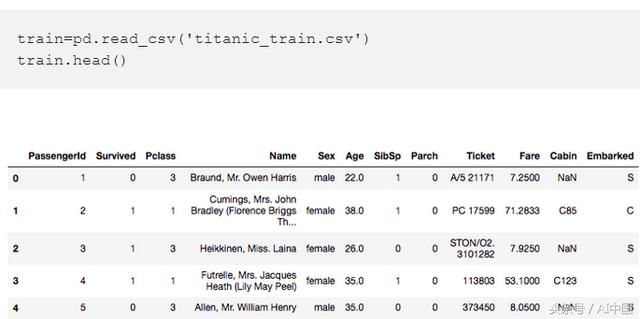
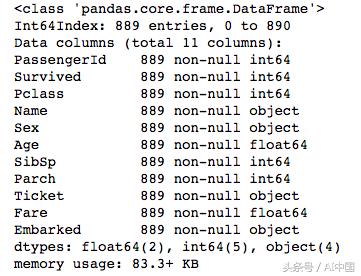
我們將繼續將泰坦尼克號數據集導入pandas數據幀。之后,我們將檢查數據框的頭部,以便清楚地了解數據框中的所有列。
我們遇到的大多數數據都缺少數據。我們將檢查缺失的數據,并將其可視化以獲得更好的想法并將其刪除。

在這里,我們找到布爾值。True表示該值為null,False表示負值,反之亦然。由于有大量數據,我們使用seaborn庫來顯示空值。在這種情況下,我們的任務變得更加容易。

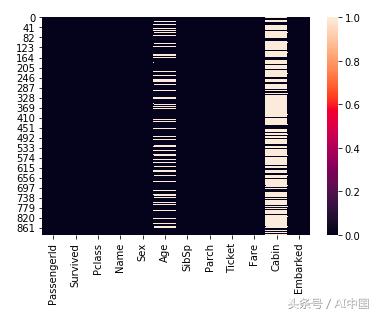
年齡(Age)和船艙(Cabin)列具有空值。我在之前的博客中處理過處理NA值的問題。有興趣可以查看。
使用數據并充分利用可視化庫來獲取數據是一種很好的做法。

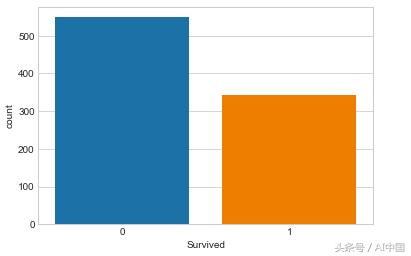
這是一個計數圖,顯示幸存的人數,這是我們的目標變量。此外,我們可以根據性別(SEX)和乘客(train)類別繪制計數圖。

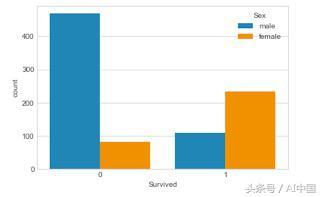
在這里,我們看到一種趨勢,即女性比男性幸存的更多。

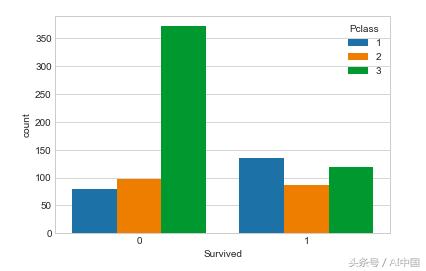
從上圖可以看出,屬于3級的乘客死亡人數最多。
我們可以通過更多方式可視化數據。但是,我不是在這里討論它們,因為我們需要進入模型構建的步驟。
數據清理
我們想要填寫缺少的年齡(Age)數據,而不是僅刪除缺少的年齡(Age)數據行。一種方法是填寫所有乘客(train)的平均年齡(估算)。但是,我們可以更加明智地按乘客(train)級別檢查平均年齡。例如:

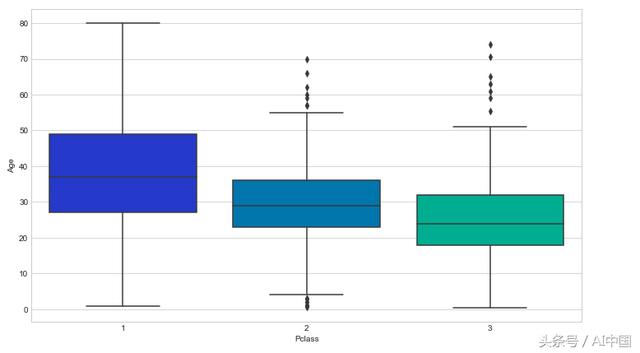
我們可以看到較高級別中較富裕的乘客(train)往往年齡較大,這是有道理的。我們將根據年齡的Pclass使用這些平均年齡值來估算。

現在應用該功能!

現在讓我們再次檢查熱圖。

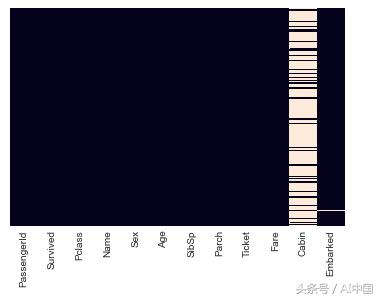
很好!讓我們繼續看船艙(Cabin)列。

轉換分類功能
我們需要使用pandas庫將分類特征轉換為虛擬變量!否則,我們的機器學習算法將無法直接將這些特征作為輸入。


在這里,我們正在篩選性別之后并列出專欄。在篩選之后,我們將丟棄其他不需要的列。

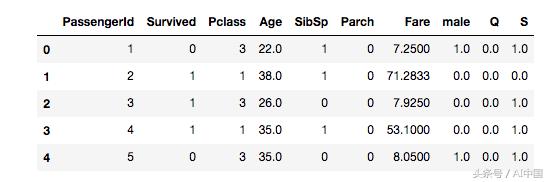
我們將連接新的性別并將列導入數據框。

現在,數據框看起來像這樣:
測試訓練劃分

訓練和預測

評估
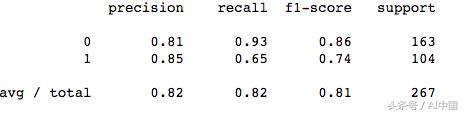
我們可以使用分類報告來檢查精確度、召回率、f1分數

感謝各位的閱讀!關于“如何使用Python的簡化方法”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





