溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“怎么在SAP HANA Express Edition里進行文本分析”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
這個練習會使用SAP HANA Express Edition的文本語義分析引擎對JSON格式的documents進行語義分析。
首先創建一個column table,對其index開啟fuzzy text search(模糊搜索)功能。
上述描述的操作可以用下面的SQL語句來完成:
create column table food_analysis
(
name nvarchar(64),
description text FAST PREPROCESS ON FUZZY SEARCH INDEX ON
);
其中description字段開啟了模糊搜索功能。
將存儲于名為doc_store的document store collection里的json key-value鍵值對拷貝到剛剛創建的數據庫表里:
insert into food_analysis with doc_store as (select "name", "description" from food_collection) select doc_store."name" as name, doc_store."description" as description from doc_store;
執行上述的sql語句,確保數據全部拷貝到數據庫表food_analysis中:
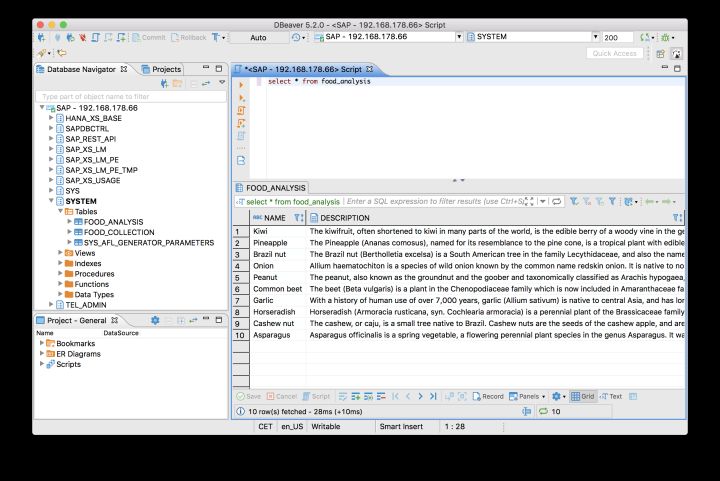
使用下列的sql語句對description字段進行模糊搜索:
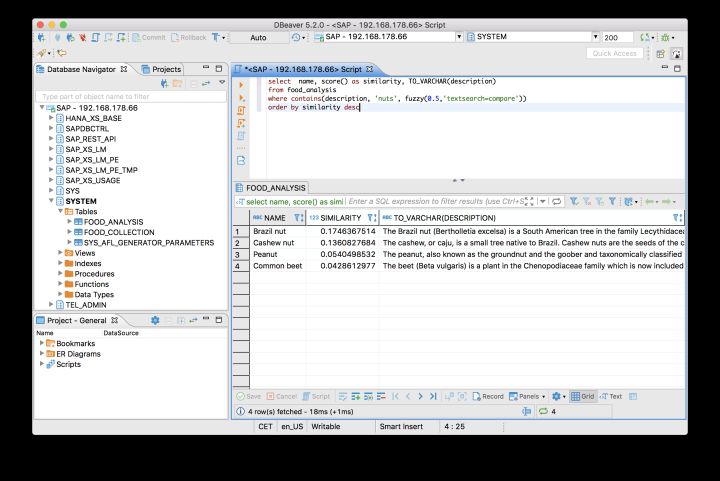
select name, score() as similarity, TO_VARCHAR(description) from food_analysis where contains(description, 'nuts', fuzzy(0.5,'textsearch=compare')) order by similarity desc
執行結果:
HANA Express Edition里的linguistic 文本分析步驟也比較簡單。
首先還是創建一個數據庫表:
create column table food_sentiment ( name nvarchar(64) primary key, description nvarchar(2048) );
將document store里的json數據拷貝到數據庫表里:
insert into food_sentiment with doc_store as (select "name", "description" from food_collection) select doc_store."name" as name, doc_store."description" as description from doc_store;
針對description字段創建一個新的index:
CREATE FULLTEXT INDEX FOOD_SENTIMENT_INDEX ON "FOOD_SENTIMENT" ("DESCRIPTION") CONFIGURATION 'GRAMMATICAL_ROLE_ANALYSIS' LANGUAGE DETECTION ('EN') SEARCH ONLY OFF FAST PREPROCESS OFF TEXT MINING OFF TOKEN SEPARATORS '' TEXT ANALYSIS ON;
上述SQL語句會自動創建一個名為$TA_FOOD_SENTIMENT_INDEX的文本分析表:
該表里的內容:
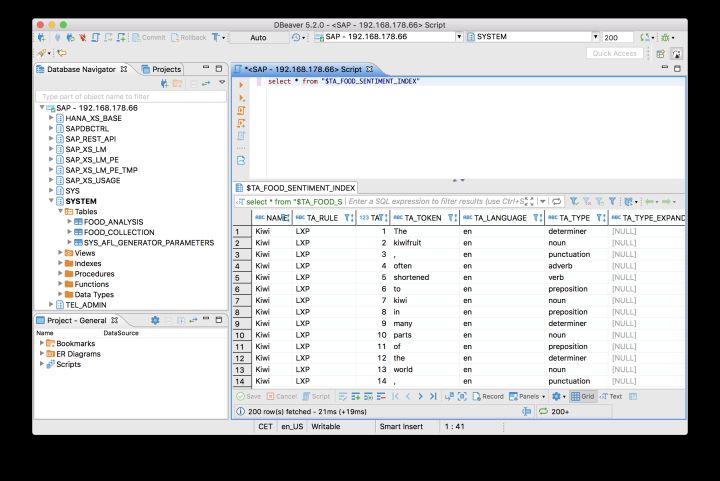
由此可以發現,之前我們導入到數據庫表里的英文句子,被HANA text engine拆解成單詞,并且每個單詞的詞性也自動被HANA解析出來了。
“怎么在SAP HANA Express Edition里進行文本分析”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





