溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了Hadoop中HDFS文件讀寫流程是怎么樣的,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
一、文件讀流程說明
讀取操作是對于Cient端是透明操作,感覺是連續的數據流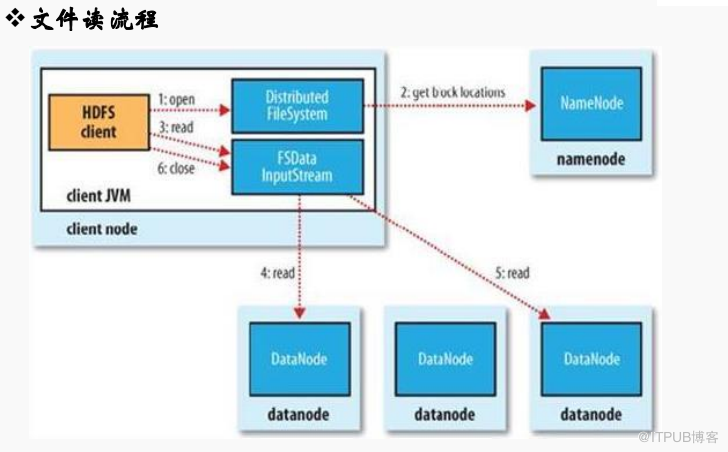
1、Client 通過FileSystem.open(filePath)方法,去與NameNode進行RPC通信,返回該文件的部分
或全部block列表,也就是返回FSDatainputstream對象;
2、Client調用FSDatainputStream對象的read()方法;
a. 去與第一個最近的DN進行read,讀取完后會check;如果ok會關閉與當前的DN通信;check fail
會記錄失敗的block+DN信息下次不會讀,然后去讀取第二個DN地址
b. 第二個塊最近的DN上進行讀取,check后關閉與DN通信
c. block列表讀取完了,文件還沒有結束,FileSystem會從NameNode獲取下一批的block列表;
3、Client條用FSDatainput對象的close方法,關閉輸入流;
總結
client > filesystem.open()與NameNode進行RPC通信返回get block list
client > 調用inputstream對象read()方法
if ok > 關閉DN通信調用inputstream.close()方法關閉輸入流
if fail > 記錄DN和block信息,向第二個DN去讀取最后close();
block列表read out , file over year > filesystem獲取下一批block列表
二、文件寫流程說明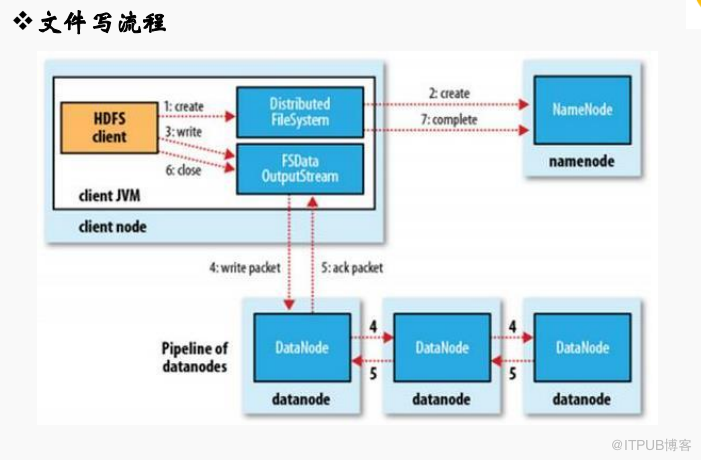
1、Client調用FileSystem.create(filepath)方法,與NameNode進行RPC通信,check該路徑的文件是否存在和是否有創建該文件權限,假如ok就創建一個新文件,但并不關聯任何的block,返回一個FSDataOutputStream對象;
2、Client調用FSDataOutputStream對象的write()方法,將第一個塊寫入第一個DataName,依次傳給第二個節點,第三個節點,第三個節點寫完返回一個ack packet給第二個節點,第二個節點返回第一個節點,第一個節點返回給ack packet給FSDataOutputstream對象,意味著第一個塊寫完,副本數為3;后面剩余塊依次這樣寫;
3、文件寫入數據完成后,Client調用FSDataOutputStream.close()方法,關閉輸出流,刷新緩存區的數據包;
4、最后調用FileSystem.complate()方法,告訴NameNode節點寫入成功;
總結:File.System.create()方法 > NameNode check(qx and exists )
if ok > 返回 FSDataOutStream對象 | if fail > return error
client 調用FSDataOutstream.write()方法 > 寫入DN,teturn ack packet > FSDataOutStream對象
client 調用FSDataOutstream.close()方法關閉輸出流 >flush緩存
最后FileSystem.complate() 方法 > NameNode write ok
感謝你能夠認真閱讀完這篇文章,希望小編分享的“Hadoop中HDFS文件讀寫流程是怎么樣的”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





