溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關Kubernetes Scheduler有什么用的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
Kubernetes
Scheduler 的作用是根據特定的調度算法將pod調度到指定的工作節點(Node)上,這一過程也叫綁定(bind)。Scheduler 的輸入為需要調度的 Pod 和可以被調度的節點(Node)的信息,輸出為調度算法選擇的 Node,并將該 pod bind 到這個 Node 。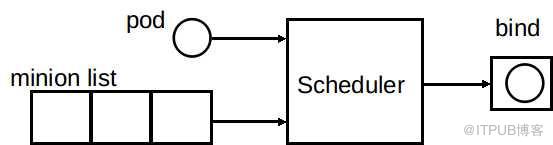
Kubernetes
Scheduler中調度算法分為兩個階段:
預選 : 根據配置的 Predicates Policies(默認為 DefaultProvider 中定義的 default predicates policies 集合)過濾掉那些不滿足Policies的Nodes,剩下的Nodes作為優選的輸入。
優選 : 根據配置的 Priorities Policies(默認為 DefaultProvider 中定義的 default priorities policies 集合)給預選后的Nodes進行打分排名,得分最高的Node即作為最適合的Node,該Pod就Bind到這個Node。

預先規則主要用于過濾出不符合規則的Node節點,剩下的節點作為優選的輸入。在1.6.1版本中預選規則包括:
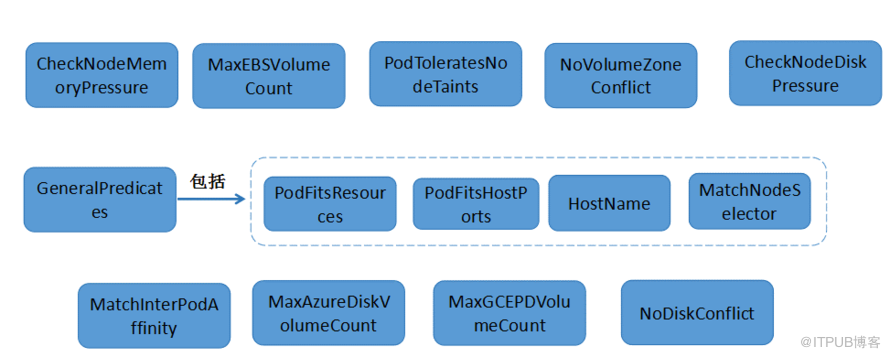
詳細的規則說明:
(1) NoDiskConflict : 檢查在此主機上是否存在卷沖突。如果這個主機已經掛載了卷,其它使用這個卷的Pod不能調度到這個主機上。GCE 、Amazon EBS 和 Ceph RBD 使用的規則如下:
1. GCE 允許同時掛載多個卷,只要這些卷都是只讀的。
2. Amazon EBS 不允許不同的 Pod 掛載同一個卷。
3.
Ceph RBD 不允許任何兩個 pods 分享相同的 monitor,match pool 和 image。
注:ISCSI 與 GCE 一樣,在卷都是只讀的情況下,允許掛載兩個 IQN 相同的卷。
(2) NoVolumeZoneConflict : 檢查在給定的 zone 限制前提下,檢查在此主機上部署 Pod 是否存在卷沖突,目前指對 PV 資源進行檢查(NewVolumeZonePredicate對象predicate函數)。
(3) MaxEBSVolumeCount : 確保已掛載的 EBS 存儲卷不超過設置的最大值。默認值是39。它會檢查直接使用的存儲卷,和間接使用這種類型存儲的 PVC 。計算不同卷的總目,如果新的 Pod 部署上去后卷的數目會超過設置的最大值,那么 Pod 就不能調度到這個主機上。
(4) MaxGCEPDVolumeCount : 確保已掛載的 GCE 存儲卷不超過設置的最大值。默認值是16。規則同MaxEBSVolumeCount。
(5) MaxAzureDiskVolumeCount : 確保已掛載的Azure存儲卷不超過設置的最大值。默認值是16。規則同MaxEBSVolumeCount。
(6) CheckNodeMemoryPressure : 判斷節點是否已經進入到內存壓力狀態,如果是則只允許調度內存為0標記的 Pod。
(7) CheckNodeDiskPressure : 判斷節點是否已經進入到磁盤壓力狀態,如果是則不調度新的Pod。
(8) PodToleratesNodeTaints : Pod 是否滿足節點容忍的一些條件。
(9) MatchInterPodAffinity : 節點親和性篩選。
(10) GeneralPredicates : 包含一些基本的篩選規則(PodFitsResources、PodFitsHostPorts、HostName、MatchNodeSelector)。
(11) PodFitsResources : 檢查節點上的空閑資源(CPU、Memory、GPU資源)是否滿足 Pod 的需求。
(12) PodFitsHostPorts : 檢查 Pod 內每一個容器所需的 HostPort 是否已被其它容器占用。如果有所需的HostPort不滿足要求,那么 Pod 不能調度到這個主機上。
(13) 檢查主機名稱是不是 Pod 指定的 HostName。
(14) 檢查主機的標簽是否滿足 Pod 的 nodeSelector 屬性需求。
優選規則對符合需求的主機列表進行打分,最終選擇一個分值最高的主機部署 Pod。kubernetes 用一組優先級函數處理每一個待選的主機。每一個優先級函數會返回一個0-10的分數,分數越高表示主機越“好”,同時每一個函數也會對應一個表示權重的值。最終主機的得分用以下公式計算得出:
finalScoreNode = (weight1 priorityFunc1) + (weight2 priorityFunc2) + … + (weightn * priorityFuncn)
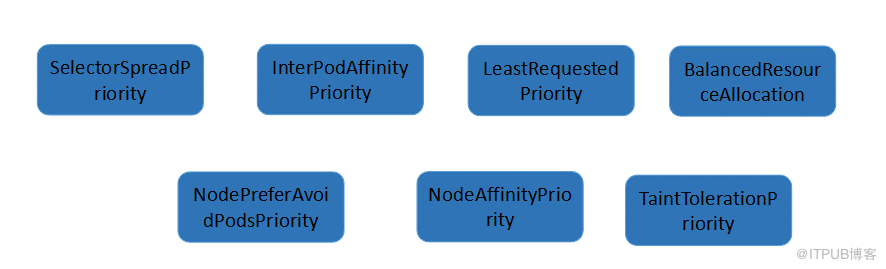
詳細的規則說明:
(1) SelectorSpreadPriority
: 對于屬于同一個 service、replication controller 的 Pod,盡量分散在不同的主機上。如果指定了區域,則會盡量把 Pod 分散在不同區域的不同主機上。調度一個 Pod 的時候,先查找 Pod 對于的 service或者 replication controller,然后查找 service 或 replication controller 中已存在的 Pod,主機上運行的已存在的 Pod 越少,主機的打分越高。
(2) LeastRequestedPriority : 如果新的 pod 要分配一個節點,這個節點的優先級就由節點空閑的那部分與總容量的比值((總容量-節點上pod的容量總和-新pod的容量)/總容量)來決定。CPU 和 memory 權重相當,比值最大的節點的得分最高。需要注意的是,這個優先級函數起到了按照資源消耗來跨節點分配 pods 的作用。計算公式如下:
cpu((capacity – sum(requested)) 10 /
capacity) + memory((capacity – sum(requested)) 10 / capacity)
/ 2
(3) BalancedResourceAllocation : 盡量選擇在部署 Pod 后各項資源更均衡的機器。BalancedResourceAllocation 不能單獨使用,而且必須和 LeastRequestedPriority 同時使用,它分別計算主機上的 cpu 和 memory 的比重,主機的分值由 cpu 比重和 memory 比重的“距離”決定。計算公式如下:score = 10 – abs(cpuFraction-memoryFraction)*10
(4) NodeAffinityPriority : Kubernetes 調度中的親和性機制。Node Selectors(調度時將 pod 限定在指定節點上),支持多種操作符(In、 NotIn、 Exists、DoesNotExist、 Gt、 Lt),而不限于對節點 labels 的精確匹配。另外,Kubernetes 支持兩種類型的選擇器,一種是 “ hard(requiredDuringSchedulingIgnoredDuringExecution)” 選擇器,它保證所選的主機滿足所有Pod對主機的規則要求。這種選擇器更像是之前的 nodeselector,在 nodeselector 的基礎上增加了更合適的表現語法。另一種 “ soft(preferresDuringSchedulingIgnoredDuringExecution)” 選擇器,它作為對調度器的提示,調度器會盡量但不保證滿足 NodeSelector 的所有要求。
(5) InterPodAffinityPriority : 通過迭代 weightedPodAffinityTerm 的元素計算和,并且如果對該節點滿足相應的PodAffinityTerm,則將 “weight” 加到和中,具有最高和的節點是最優選的。
(6) NodePreferAvoidPodsPriority(權重1W) : 如果 Node 的 Anotation 沒有設置 key-value:scheduler. alpha.kubernetes.io/ preferAvoidPods = "...",則該 node 對該 policy 的得分就是10分,加上權重10000,那么該node對該policy的得分至少10W分。如果Node的Anotation設置了,scheduler.alpha.kubernetes.io/preferAvoidPods = "..." ,如果該 pod 對應的 Controller 是 ReplicationController 或 ReplicaSet,則該 node 對該 policy 的得分就是0分。
(7) TaintTolerationPriority : 使用 Pod 中 tolerationList 與 Node 節點 Taint 進行匹配,配對成功的項越多,則得分越低。
另外在優選的調度規則中,有幾個未被默認使用的規則:
(1) ImageLocalityPriority : 據主機上是否已具備 Pod 運行的環境來打分。ImageLocalityPriority 會判斷主機上是否已存在 Pod 運行所需的鏡像,根據已有鏡像的大小返回一個0-10的打分。如果主機上不存在 Pod 所需的鏡像,返回0;如果主機上存在部分所需鏡像,則根據這些鏡像的大小來決定分值,鏡像越大,打分就越高。
(2) EqualPriority : EqualPriority 是一個優先級函數,它給予所有節點一個相等的權重。
(3) ServiceSpreadingPriority : 作用與 SelectorSpreadPriority 相同,已經被 SelectorSpreadPriority 替換。
(4) MostRequestedPriority : 在 ClusterAutoscalerProvider 中,替換 LeastRequestedPriority,給使用多資源的節點,更高的優先級。計算公式為:(cpu(10 sum(requested) / capacity) + memory(10sum(requested) / capacity)) / 2
感謝各位的閱讀!關于“Kubernetes Scheduler有什么用”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





