溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹消息中間件Kafka+Zookeeper集群的概念、部署和實踐是怎樣的,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
Kafka是一種高吞吐量的 分布式 發布訂閱消息系統,它可以處理消費者規模的網站中所有動作流數據。Kafka的目的是通過 Hadoop 并行加載機制統一線上和離線消息處理,并通過 集群 提供實時消息。內容較基礎,主要圍繞kafka的體系架構和功能展開。
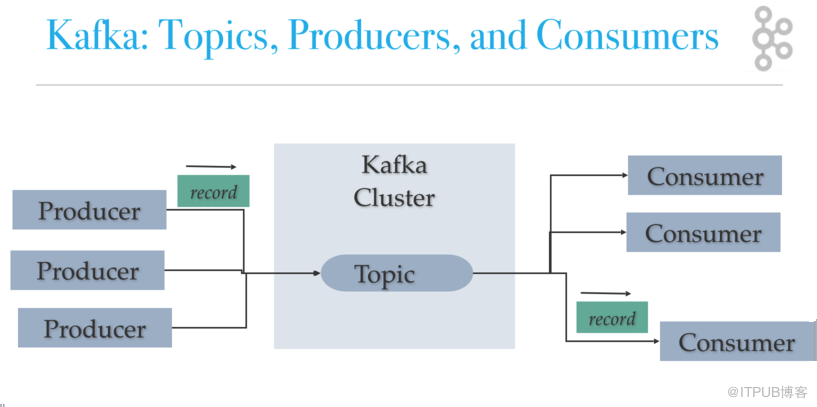
正文開始之前,我們先了解一下Kafka中涉及的相關術語:
1、Broker——Kafka集群包含一個或多個服務器,這種服務器被稱為broker ;
2、Topic——每條發布到Kafka集群的消息都有一個類別,這個類別被稱為Topic。(物理上不同Topic的消息分開存儲,邏輯上一個Topic的消息雖然保存于一個或多個broker上但用戶只需指定消息的Topic即可生產或消費數據而不必關心數據存于何處)
3、Partition——Partition是物理上的概念,每個Topic包含一個或多個Partition.
4、Producer——負責發布消息到Kafka broker
5、Consumer——消息消費者,向Kafka broker讀取消息的客戶端。
6、Consumer Group——每個Consumer屬于一個特定的Consumer Group(可為每個Consumer指定group name,若不指定group name則屬于默認的group)。
Kafka的topic可以看做是一個記錄流 ("/orders", "/user-signups"),每個topic都有一個日志,它存儲在磁盤上。每個topic又被分成多個partition(區),每個partition在存儲層面是append log文件,任何發布到partition的消息都會被直接追加到日志文件的尾部,Kafka Producer API用于生成數據記錄流,Kafka Consumer API用于使用Kafka的記錄流。
Kafka架構:Topic、Partition、Producer、Consumer
通常,一個普通的工作流程是Kafka的producer向topic寫入消息,consumer從topic中讀取消息。topic與日志相關聯,日志是存儲在磁盤上的數據結構,Kafka將producer的記錄附加到topic日志的末尾。topic日志由分布在多個文件上的許多分區組成,這些文件可以分布在多個Kafka集群節點上。Kafka在集群的不同節點上分發topic日志分區,以實現具有水平可伸縮性的高性能。Spreading 分區有助于快速寫入數據,Kafka將分區復制到許多節點以提供故障轉移。
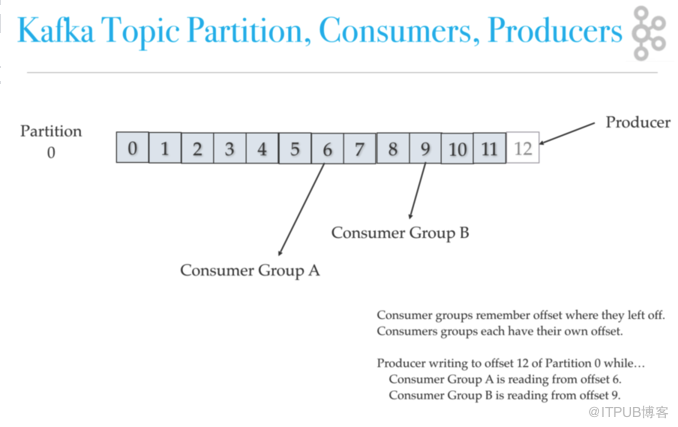
如果多個producer和consumer同時讀取和寫入相同的Kafka主題日志,Kafka如何擴展?首先,Kafka本身的寫入速度很快,順序寫入文件系統本身就不需要太多時間;其次,在現代的快速驅動器上,Kafka可以輕松地每秒寫入700 MB或更多字節的數據。
集群部署和測試
Kafka使用ZooKeeper管理集群,ZooKeeper用于協調服務器或集群拓撲,ZooKeeper是配置信息的一致性文件系統。你可以選擇Kafka自帶的Zookeeper,也可以選擇單獨部署,一臺Linux主機開放三個端口即可構建一個簡單的偽ZooKeeper集群。
ZooKeeper可以將拓撲更改發送到Kafka,如果集群中的某臺服務器宕機或者某個topic被添加、刪除,集群中的每個節點都可以知道新服務器何時加入,ZooKeeper提供Kafka Cluster配置的同步視圖。Kafka和ZooKeeper的搭建都需要java環境,對于jdk的下載安裝本文不過多贅述,可以自行網上查詢,二者的安裝包也可以在Apache官網自行下載。自建Zookeeper集群的配置過程如下:
創建目錄 ZooKeeper:mkdir zookeeper
拷貝最少三個實例,進入ZooKeeper目錄,其他實例進行同樣的操作:
創建目錄zkdata、zkdatalog

進入conf目錄,
拷貝zoo_sample.cfg 為zoo.cfg,詳細配置如下:
Java代碼
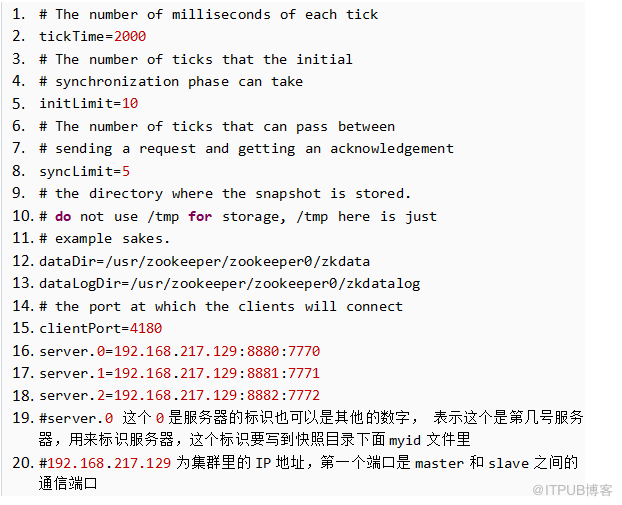
使用Kafka自帶的ZooKeeper集群:
查看配置文件
進入Kafka的config的目錄:
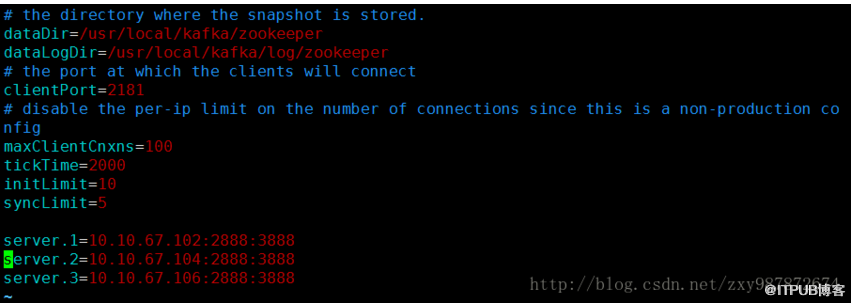
先建立zk集群,直接使用Kafka自帶的ZooKeeper建立zk集群,修改zookeeper.properties文件:
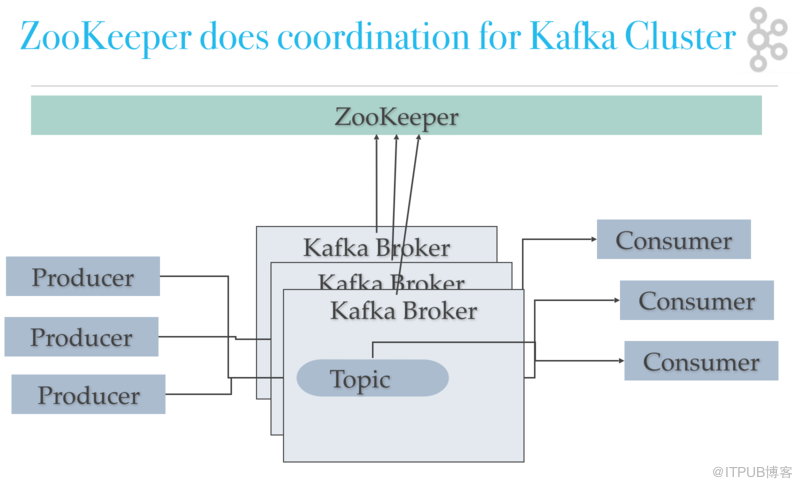
Kafka服務器
Kafka集群由多個Kafka Brokers組成。每個Kafka Broker都有一個唯一的ID(編號)。Kafka Brokers包含主題日志分區,如果希望獲得故障處理能力,需要保證至少有三到五個服務器,Kafka集群最大可同時存在10,100或1,000個服務器。Kafka將每個partition數據復制到多個server上,任何一個partition有一個leader和多個follower(可以沒有);備份的個數可以通過broker配置文件來設定.當leader失效時,需在followers中選取出新的leader,可能此時follower落后于leader,因此需要選擇一個"up-to-date"的follower。
例如,如果在AWS中運行kafka集群,其中一個Kafka Broker發生故障,作為ISR(同步副本)的Kafka Broker可以迅速提供數據。
請注意,對于如何設置Kafka集群本身并沒有硬性規定。例如,可以在單個AZ中設置整個集群,以便使用AWS增強型網絡和放置組獲得更高的吞吐量,然后使用Mirror Maker將集群鏡像到同一區域中的熱災備AZ。
關于消息中間件Kafka+Zookeeper集群的概念、部署和實踐是怎樣的就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





