溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了怎么將傳統關系數據庫的數據導入Hadoop,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
大多數企業的關鍵數據存在于OLTP數據庫中,存儲在這些數據庫中的數據包含有關用戶,產品和其他有用信息。如果要分析此數據,傳統方法是定期將該數據復制到OLAP數據倉庫中。Hadoop已經出現在這個領域并扮演了兩個角色:數據倉庫的替代品;結構化、非結構化數據和數據倉庫之間的橋梁。圖5.8顯示了第一個角色,其中Hadoop在將數據導到OLAP系統(BI應用程序的常用平臺)之前用作大規模加入和聚合工具。
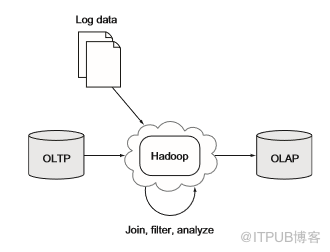
圖5.8 使用Hadoop進行OLAP數據輸入輸出和處理
以Facebook為例,該企業已成功利用Hadoop和Hive作為OLAP平臺來處理數PB數據。圖5.9顯示了類似于Facebook的架構。該體系結構還包括OLTP系統的反饋循環,可用于推送在Hadoop中發現的洞察,例如為用戶提供建議。
在任一使用模型中,我們都需要一種將關系數據引入Hadoop的方法,還需要將其輸出到關系數據庫中。本節,我們將使用Sqoop簡化將關系數據輸出到Hadoop的過程。
實踐:使用Sqoop從MySQL導入數據
Sqoop是一個可用于將關系數據輸入和輸出Hadoop的項目。它是一個很好的高級工具,封裝了與關系數據移動到Hadoop相關的邏輯,我們需要做的就是為Sqoop提供確定輸出哪些數據的SQL查詢。該技術提供了有關如何使用Sqoop將MySQL中的某些數據移動到HDFS的詳細信息。

圖5.9 使用Hadoop進行OLAP并反饋到OLTP系統
本節使用Sqoop 1.4.4版本,此技術中使用的代碼和腳本可能無法與其他版本的Sqoop一起使用,尤其是Sqoop 2,它是作為Web應用程序實現的。
問題
將關系數據加載到集群中,并確保寫入有效且冪等。
解決方案
在這種技術中,我們將看到如何使用Sqoop作為將關系數據引入Hadoop集群的簡單機制。我們會介紹將數據從MySQL導入Sqoop的過程,還將介紹使用快速連接器的批量導入(連接器是提供數據庫讀寫訪問的特定于數據庫的組件)。
討論
Sqoop是一個關系數據庫輸入和輸出系統,由Cloudera創建,目前是Apache項目。
執行導入時,Sqoop可以寫入HDFS、Hive和HBase,對于輸出,它可以執行相反操作。導入分為兩部分:連接到數據源以收集統計信息,然后觸發執行實際導入的MapReduce作業。圖5.10顯示了這些步驟。
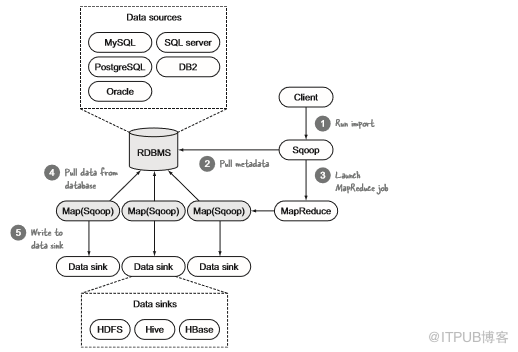
圖5.10 Sqoop導入:連接到數據源并使用MapReduce
Sqoop有連接器的概念,它包含讀寫外部系統所需的專用邏輯。Sqoop提供兩類連接器:用于常規讀取和寫入的通用連接器,以及使用數據庫專有批處理機制進行高效導入的快速連接器。圖5.11顯示了這兩類連接器及其支持的數據庫。
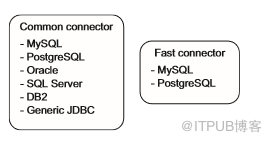
圖5.11用于讀寫外部系統的Sqoop連接器
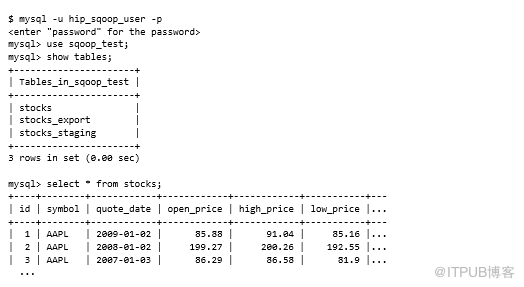
在繼續之前,我們需要訪問MySQL數據庫,并且MySQL JDBC JAR需要可用。以下腳本將創建必要的MySQL用戶和模式并加載數據。該腳本創建了一個hip_sqoop_user MySQL用戶,并創建了包含三個表的sqoop_test數據庫:stocks,stocks_export和stocks_staging。然后,它將stock樣本數據加載到表中。所有這些步驟都通過運行以下命令來執行:

這是快速瀏覽腳本功能:
第一個Sqoop命令是基本導入,在其中指定MySQL數據庫和要導出的表連接信息:

MySQL表名稱
Linux中的MySQL表名稱區分大小寫,確保在Sqoop命令中提供的表名使用正確的大小寫。
默認情況下,Sqoop使用表名作為HDFS中的目標目錄,用于執行導入的MapReduce作業。如果再次運行相同的命令,MapReduce作業將失敗,因為該目錄已存在。
我們來看看HDFS中的stocks目錄:
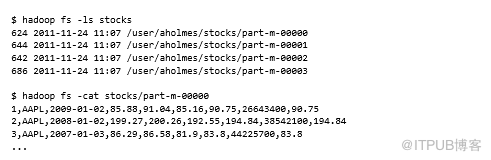
導入數據格式
Sqoop已將數據導入為逗號分隔的文本文件。它支持許多其他文件格式,可以使用表5.6中列出的參數激活它們。
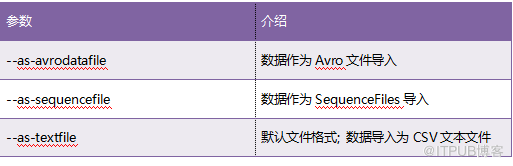
表5.6 控制導入文件格式的Sqoop參數
如果要導入大量數據,則可能需要使用Avro等文件格式,這是一種緊湊的數據格式,并將其與壓縮結合使用。以下示例將Snappy壓縮編解碼器與Avro文件結合使用。它還使用--target-dir選項將輸出寫入表名的不同目錄,并指定應使用--where選項導入行的子集。可以使用--columns指定要提取的特定列:
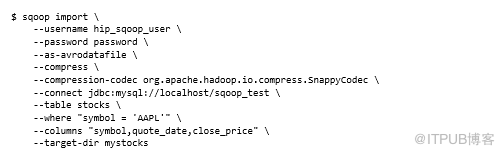
請注意,必須在io.compression.codecs屬性下的配置文件core-site.xml中定義在命令行上提供的壓縮。Snappy壓縮編解碼器要求安裝Hadoop本機庫。有關壓縮設置和配置等更多詳細信息,請參見第4章,鏈接見文末。
可以通過引入AvroDump工具來了解Avro文件結構,以了解Sqoop如何布局記錄。Sqoop使用Avro的GenericRecord進行記錄級存儲(有關詳細信息,請參閱第3章,鏈接見文末)。如果針對HDFS中Sqoop生成的文件運行AvroDump,將看到以下內容:

將Sqoop與SequenceFiles結合使用
SequenceFiles難以使用的一個原因是,沒有通用的方法來訪問SequenceFile中的數據。必須有權訪問用于寫入數據的Writable類。在Sqoop的情況下,代碼可生成此文件,這引入了一個主要問題:如果轉移到較新版本的Sqoop,并且該版本修改了代碼生成器,那么舊代碼生成的類可能無法與SequenceFiles一起使用。需要將所有舊的SequenceFiles遷移到新版本,或者具有可以使用這些SequenceFiles不同版本的代碼。由于此限制,不建議將SequenceFiles與Sqoop一起使用。如果正在尋找有關SequenceFiles如何工作的更多信息,請運行Sqoop導入工具并查看在工作目錄中生成的stocks.java文件。
可以更進一步,使用--query選項指定整個查詢,如下所示:


保護密碼
到目前為止,我們一直在命令行中使用明文密碼,這是一個安全漏洞,因為主機上的其他用戶可以輕松列出正在運行的進程并查看密碼。幸運的是,Sqoop有一些機制可以用來避免密碼泄露。
第一種方法是使用-P選項,這將導致Sqoop提示輸入密碼。這是最安全的方法,因為它不需要存儲密碼,但這意味著無法自動執行Sqoop命令。
第二種方法是使用--password-file選項,可以在其中指定包含密碼的文件。請注意,此文件必須存在于已配置的文件系統中(通常可能是HDFS),而不是存在于Sqoop客戶端本地磁盤上。你可能希望鎖定文件,以便只有你對此文件具有讀取權限。 這仍然不是最安全的選項,因為文件系統上的root用戶仍然可以窺探文件,除非運行安全級別較高的Hadoop,否則即使非root用戶也可以輕松訪問。
最后一個選項是使用選項文件。創建一個名為?/.sqoop-import-opts的文件:

不要忘記鎖定文件以避免用戶窺探:

然后,我們可以通過--options-file選項將此文件名提供給Sqoop作業,Sqoop將讀取文件中指定的選項,這意味著無需在命令行上提供它們:

數據拆分
Sqoop如何在多個mapper之間并行化導入?在圖5.10中,我展示了Sqoop的第一步是如何從數據庫中提取元數據。它檢查導入的表以確定主鍵,并運行查詢以確定表中數據的下限和上限(見圖5.12)。Sqoop假設在最小和最大鍵內的數據接近均勻分布,因為它將delta(最小和最大鍵之間的范圍)按照mapper數量拆分。然后,為每個mapper提供包含一系列主鍵的唯一查詢。

圖5.12 確定查詢拆分的Sqoop預處理步驟
我們可以將Sqoop配置為使用帶有--split-by參數的非主鍵,這在最小值和最大值之間沒有均勻分布的情況下非常有用。但是,對于大型表,需要注意--split-by中指定的列已編制索引以確保最佳導入時間,可以使用--boundary-query參數構造備用查詢以確定最小值和最大值。
增量導入
Sqoop支持兩種導入類型:追加用于隨時間遞增的數值數據,例如自動增量鍵;lastmodified適用于帶時間戳的數據。在這兩種情況下,都需要使用--check-column指定列,通過--incremental參數指定模式(值必須是append或lastmodified),以及用于通過--last-value確定增量更改的實際值。
例如,如果要導入2005年1月1日更新的stock數據,則執行以下操作:

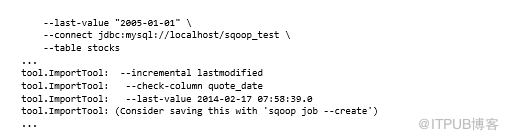
假設還有另一個系統繼續寫入該表,可以使用此作業的--last-value輸出作為后續Sqoop作業的輸入,這樣只會導入比該日期更新的行。
Sqoop作業和Metastore
可以在命令輸出中看到增量列的最后一個值。如何才能最好地自動化可以重用該值的流程?Sqoop有一個作業的概念,可以保存這些信息并在后續執行中重復使用:

執行上述命令會在Sqoop Metastore中創建一個命名作業,該作業會跟蹤所有作業。默認情況下,Metastore包含在.sqoop下的主目錄中,僅用于自己的作業。如果要在用戶和團隊之間共享作業,則需要為Sqoop的Metastore安裝符合JDBC的數據庫,并在發出作業命令時使用--meta-connect參數指定其位置。
在上一個示例中執行的作業創建命令除了將作業添加到Metastore之外沒有做任何其他操作。要運行作業,需要顯式執行,如下所示:
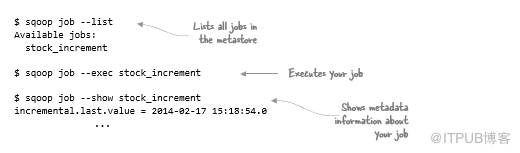
--show參數顯示的元數據包括增量列的最后一個值。這實際上是執行命令的時間,而不是表中的最后一個值。如果正在使用此功能,請確保數據庫服務器和與服務器(包括Sqoop客戶端)交互的任何客戶端的時鐘與網絡時間協議(NTP)同步。
Sqoop將在運行作業時提示輸入密碼。要使其在自動腳本中運行,需要使用Expect(一種Linux自動化工具)在檢測到Sqoop提示輸入密碼時從本地文件提供密碼,可以在GitHub上找到與Sqoop一起使用的Expect腳本,網址為:https://github.com/alexholmes/hadoop-book/blob/master/bin/sqoop-job.exp。
Sqoop作業也可以刪除,如下所示:
$ sqoop job --delete stock_increment
快速MySQL導入
如果想完全繞過JDBC并使用快速MySQL Sqoop連接器進行HDFS的高吞吐量加載,該怎么辦?該方法使用MySQL附帶的mysqldump實用程序來執行加載。必須確保mysqldump位于運行MapReduce作業的用戶路徑中。要啟用快速連接器,必須指定--direct參數:

快速連接器有哪些缺點? 快速連接器僅適用于文本輸出文件 ,指定Avro或SequenceFile,因為導入的輸出格式不起作用。
導入到Hive
此技術的最后一步是使用Sqoop將數據導入Hive表。HDFS導入和Hive導入之間的唯一區別是Hive導入有一個后處理步驟,其中創建并加載Hive表,如圖5.13所示。
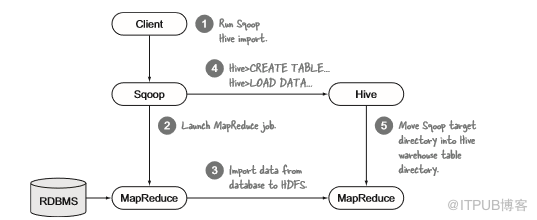
圖5.13 Sqoop Hive導入事件序列
當數據從HDFS文件或目錄加載到Hive時,如Sqoop Hive導入的情況(圖中的步驟4),Hive將目錄移動到其倉庫而不是復制數據(步驟5)以提高效率。導入后,Sqoop MapReduce作業寫入的HDFS目錄將不存在。
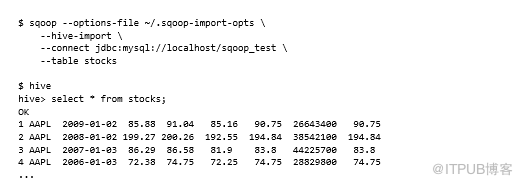
Hive導入是通過--hive-import參數觸發的。就像快速連接器一樣,此選項與--as-avrodatafile和--as -sequencefile選項不兼容:
導入包含Hive分隔符的字符串
如果要導入可以包含任何Hive分隔符(\n,\r和\01字符)的列,則可能會出現下游處理問題。在這種情況下,有兩種選擇:指定--hive-drop-import-delims,它將刪除導入部分的沖突字符,或指定--hive-delims-replacement,它將用不同的字符替換它們。
如果Hive表已存在,則數據將附加到現有表。如果這不是所需的行為,則可以使用--hive-overwrite參數指示應使用導入的數據替換現有表。Sqoop目前僅支持Hive的文本輸出,因此LZOP壓縮編解碼器是最佳選擇,因為它可以在Hadoop中拆分(詳見第4章)。以下示例顯示如何結合使用--hive-overwrite LZOP壓縮。為此,我們需要在集群上構建并安裝LZOP,因為默認情況下它不與Hadoop(或CDH)捆綁在一起。有關詳細信息,請參閱第4章(鏈接見文末):


最后,我們可以使用--hive-partition-key和--hive-partition-value參數根據要導入的列的值創建不同的Hive分區。例如,如果要按stock名稱對輸入進行分區,請執行以下操作:

現在,前面的例子無論如何都不是最優的。理想情況下,單個導入將能夠創建多個Hive分區。因為僅限于指定單個鍵和值,所以每個唯一的分區值需要運行一次導入,這很費力。最好導入到未分區的Hive表中,然后在加載后在表上追溯創建分區。
此外,提供給Sqoop的SQL查詢還必須注意過濾掉結果,以便僅包含與分區匹配的那些。換句話說,如果Sqoop用符號=“AAPL”更新WHERE子句,那將會很有用。
連續Sqoop執行
如果需要定期安排導入HDFS,Oozie可以進行Sqoop集成,允許定期執行導入和導出。Oozie workflow.xml示例如下:

<command>元素中不支持單引號和雙引號,因此如果需要指定包含空格的參數,則需要使用<arg>元素:

使用Oozie的Sqoop時的另一個考慮因素是需要為Oozie提供JDBC驅動程序JAR。我們可以將JAR復制到工作流的lib/目錄中,也可以使用JAR更新Hadoop安裝的lib目錄。
感謝你能夠認真閱讀完這篇文章,希望小編分享的“怎么將傳統關系數據庫的數據導入Hadoop”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





