溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文轉自: https://www.javadoop.com/
本系列文章將整理到我在GitHub上的《Java面試指南》倉庫,更多精彩內容請到我的倉庫里查看
https://github.com/h3pl/Java-Tutorial
喜歡的話麻煩點下Star哈
文章同步發于我的個人博客:
www.how2playlife.com
本文是微信公眾號【Java技術江湖】的《Java并發指南》其中一篇,本文大部分內容來源于網絡,為了把本文主題講得清晰透徹,也整合了很多我認為不錯的技術博客內容,引用其中了一些比較好的博客文章,如有侵權,請聯系作者。
該系列博文會告訴你如何全面深入地學習Java并發技術,從Java多線程基礎,再到并發編程的基礎知識,從Java并發包的入門和實戰,再到JUC的源碼剖析,一步步地學習Java并發編程,并上手進行實戰,以便讓你更完整地了解整個Java并發編程知識體系,形成自己的知識框架。
為了更好地總結和檢驗你的學習成果,本系列文章也會提供一些對應的面試題以及參考答案。
如果對本系列文章有什么建議,或者是有什么疑問的話,也可以關注公眾號【Java技術江湖】聯系作者,歡迎你參與本系列博文的創作和修訂。
今天發一篇”水文”,可能很多讀者都會表示不理解,不過我想把它作為并發序列文章中不可缺少的一塊來介紹。本來以為花不了多少時間的,不過最終還是投入了挺多時間來完成這篇文章的。
網上關于 HashMap 和 ConcurrentHashMap 的文章確實不少,不過缺斤少兩的文章比較多,所以才想自己也寫一篇,把細節說清楚說透,尤其像 Java8 中的 ConcurrentHashMap,大部分文章都說不清楚。終歸是希望能降低大家學習的成本,不希望大家到處找各種不是很靠譜的文章,看完一篇又一篇,可是還是模模糊糊。
閱讀建議:四節基本上可以進行獨立閱讀,建議初學者可按照 Java7 HashMap -> Java7 ConcurrentHashMap -> Java8 HashMap -> Java8 ConcurrentHashMap 順序進行閱讀,可適當降低閱讀門檻。
閱讀前提:本文分析的是源碼,所以至少讀者要熟悉它們的接口使用,同時,對于并發,讀者至少要知道 CAS、ReentrantLock、UNSAFE 操作這幾個基本的知識,文中不會對這些知識進行介紹。Java8 用到了紅黑樹,不過本文不會進行展開,感興趣的讀者請自行查找相關資料。
HashMap 是最簡單的,一來我們非常熟悉,二來就是它不支持并發操作,所以源碼也非常簡單。
首先,我們用下面這張圖來介紹 HashMap 的結構。
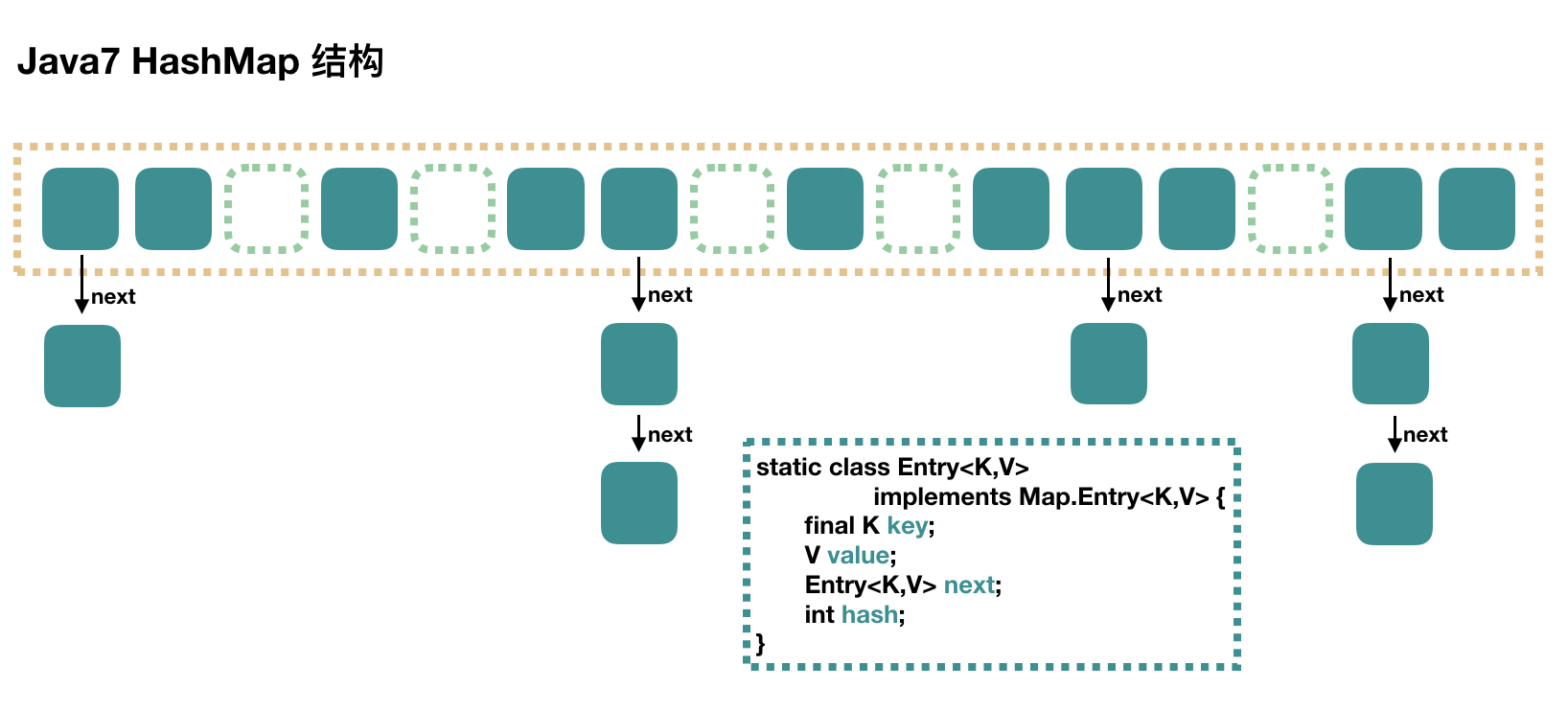
這個僅僅是示意圖,因為沒有考慮到數組要擴容的情況,具體的后面再說。
大方向上,HashMap 里面是一個 數組,然后數組中每個元素是一個 單向鏈表。
上圖中,每個綠色的實體是嵌套類 Entry 的實例,Entry 包含四個屬性:key, value, hash 值和用于單向鏈表的 next。
capacity:當前數組容量,始終保持 2^n,可以擴容,擴容后數組大小為當前的 2 倍。
loadFactor:負載因子,默認為 0.75。
threshold:擴容的閾值,等于 capacity * loadFactor
還是比較簡單的,跟著代碼走一遍吧。
public V put(K key, V value) {
// 當插入第一個元素的時候,需要先初始化數組大小
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
// 如果 key 為 null,感興趣的可以往里看,最終會將這個 entry 放到 table[0] 中
if (key == null)
return putForNullKey(value);
// 1\. 求 key 的 hash 值
int hash = hash(key);
// 2\. 找到對應的數組下標
int i = indexFor(hash, table.length);
// 3\. 遍歷一下對應下標處的鏈表,看是否有重復的 key 已經存在,
// 如果有,直接覆蓋,put 方法返回舊值就結束了
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// 4\. 不存在重復的 key,將此 entry 添加到鏈表中,細節后面說
addEntry(hash, key, value, i);
return null;
}
在第一個元素插入 HashMap 的時候做一次數組的初始化,就是先確定初始的數組大小,并計算數組擴容的閾值。
private void inflateTable(int toSize) {
// 保證數組大小一定是 2 的 n 次方。
// 比如這樣初始化:new HashMap(20),那么處理成初始數組大小是 32
int capacity = roundUpToPowerOf2(toSize);
// 計算擴容閾值:capacity * loadFactor
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
// 算是初始化數組吧
table = new Entry[capacity];
initHashSeedAsNeeded(capacity); //ignore
}
這里有一個將數組大小保持為 2 的 n 次方的做法,Java7 和 Java8 的 HashMap 和 ConcurrentHashMap 都有相應的要求,只不過實現的代碼稍微有些不同,后面再看到的時候就知道了。
這個簡單,我們自己也能 YY 一個:使用 key 的 hash 值對數組長度進行取模就可以了。
static int indexFor(int hash, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return hash & (length-1);
}
這個方法很簡單,簡單說就是取 hash 值的低 n 位。如在數組長度為 32 的時候,其實取的就是 key 的 hash 值的低 5 位,作為它在數組中的下標位置。
找到數組下標后,會先進行 key 判重,如果沒有重復,就準備將新值放入到鏈表的 表頭。
void addEntry(int hash, K key, V value, int bucketIndex) {
// 如果當前 HashMap 大小已經達到了閾值,并且新值要插入的數組位置已經有元素了,那么要擴容
if ((size >= threshold) && (null != table[bucketIndex])) {
// 擴容,后面會介紹一下
resize(2 * table.length);
// 擴容以后,重新計算 hash 值
hash = (null != key) ? hash(key) : 0;
// 重新計算擴容后的新的下標
bucketIndex = indexFor(hash, table.length);
}
// 往下看
createEntry(hash, key, value, bucketIndex);
}
// 這個很簡單,其實就是將新值放到鏈表的表頭,然后 size++
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
這個方法的主要邏輯就是先判斷是否需要擴容,需要的話先擴容,然后再將這個新的數據插入到擴容后的數組的相應位置處的鏈表的表頭。
前面我們看到,在插入新值的時候,如果 當前的 size 已經達到了閾值,并且要插入的數組位置上已經有元素,那么就會觸發擴容,擴容后,數組大小為原來的 2 倍。
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
// 新的數組
Entry[] newTable = new Entry[newCapacity];
// 將原來數組中的值遷移到新的更大的數組中
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
擴容就是用一個新的大數組替換原來的小數組,并將原來數組中的值遷移到新的數組中。
由于是雙倍擴容,遷移過程中,會將原來 table[i] 中的鏈表的所有節點,分拆到新的數組的 newTable[i] 和 newTable[i + oldLength] 位置上。如原來數組長度是 16,那么擴容后,原來 table[0] 處的鏈表中的所有元素會被分配到新數組中 newTable[0] 和 newTable[16] 這兩個位置。代碼比較簡單,這里就不展開了。
相對于 put 過程,get 過程是非常簡單的。
public V get(Object key) {
// 之前說過,key 為 null 的話,會被放到 table[0],所以只要遍歷下 table[0] 處的鏈表就可以了
if (key == null)
return getForNullKey();
//
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
getEntry(key):
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
// 確定數組下標,然后從頭開始遍歷鏈表,直到找到為止
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
ConcurrentHashMap 和 HashMap 思路是差不多的,但是因為它支持并發操作,所以要復雜一些。
整個 ConcurrentHashMap 由一個個 Segment 組成,Segment 代表”部分“或”一段“的意思,所以很多地方都會將其描述為 分段鎖。注意,行文中,我很多地方用了“ 槽”來代表一個 segment。
簡單理解就是,ConcurrentHashMap 是一個 Segment 數組,Segment 通過繼承 ReentrantLock 來進行加鎖,所以每次需要加鎖的操作鎖住的是一個 segment,這樣只要保證每個 Segment 是線程安全的,也就實現了全局的線程安全。
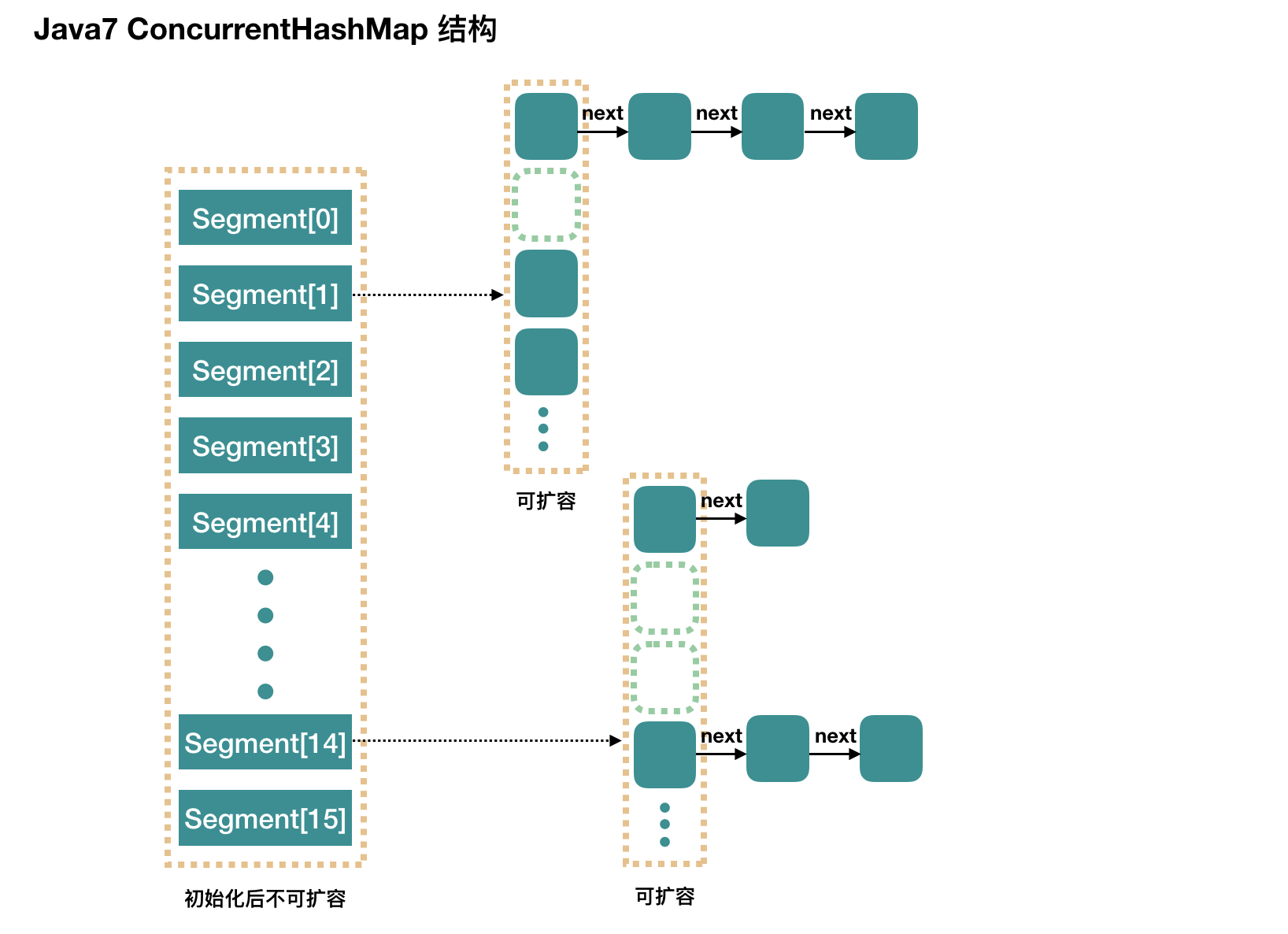
concurrencyLevel:并行級別、并發數、Segment 數,怎么翻譯不重要,理解它。默認是 16,也就是說 ConcurrentHashMap 有 16 個 Segments,所以理論上,這個時候,最多可以同時支持 16 個線程并發寫,只要它們的操作分別分布在不同的 Segment 上。這個值可以在初始化的時候設置為其他值,但是一旦初始化以后,它是不可以擴容的。
再具體到每個 Segment 內部,其實每個 Segment 很像之前介紹的 HashMap,不過它要保證線程安全,所以處理起來要麻煩些。
initialCapacity:初始容量,這個值指的是整個 ConcurrentHashMap 的初始容量,實際操作的時候需要平均分給每個 Segment。
loadFactor:負載因子,之前我們說了,Segment 數組不可以擴容,所以這個負載因子是給每個 Segment 內部使用的。
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
// 計算并行級別 ssize,因為要保持并行級別是 2 的 n 次方
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
// 我們這里先不要那么燒腦,用默認值,concurrencyLevel 為 16,sshift 為 4
// 那么計算出 segmentShift 為 28,segmentMask 為 15,后面會用到這兩個值
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// initialCapacity 是設置整個 map 初始的大小,
// 這里根據 initialCapacity 計算 Segment 數組中每個位置可以分到的大小
// 如 initialCapacity 為 64,那么每個 Segment 或稱之為"槽"可以分到 4 個
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
// 默認 MIN_SEGMENT_TABLE_CAPACITY 是 2,這個值也是有講究的,因為這樣的話,對于具體的槽上,
// 插入一個元素不至于擴容,插入第二個的時候才會擴容
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// 創建 Segment 數組,
// 并創建數組的第一個元素 segment[0]
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
// 往數組寫入 segment[0]
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
初始化完成,我們得到了一個 Segment 數組。
我們就當是用 new ConcurrentHashMap() 無參構造函數進行初始化的,那么初始化完成后:
我們先看 put 的主流程,對于其中的一些關鍵細節操作,后面會進行詳細介紹。
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
// 1\. 計算 key 的 hash 值
int hash = hash(key);
// 2\. 根據 hash 值找到 Segment 數組中的位置 j
// hash 是 32 位,無符號右移 segmentShift(28) 位,剩下高 4 位,
// 然后和 segmentMask(15) 做一次與操作,也就是說 j 是 hash 值的高 4 位,也就是槽的數組下標
int j = (hash >>> segmentShift) & segmentMask;
// 剛剛說了,初始化的時候初始化了 segment[0],但是其他位置還是 null,
// ensureSegment(j) 對 segment[j] 進行初始化
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
// 3\. 插入新值到 槽 s 中
return s.put(key, hash, value, false);
}
第一層皮很簡單,根據 hash 值很快就能找到相應的 Segment,之后就是 Segment 內部的 put 操作了。
Segment 內部是由 數組+鏈表 組成的。
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 在往該 segment 寫入前,需要先獲取該 segment 的獨占鎖
// 先看主流程,后面還會具體介紹這部分內容
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
// 這個是 segment 內部的數組
HashEntry<K,V>[] tab = table;
// 再利用 hash 值,求應該放置的數組下標
int index = (tab.length - 1) & hash;
// first 是數組該位置處的鏈表的表頭
HashEntry<K,V> first = entryAt(tab, index);
// 下面這串 for 循環雖然很長,不過也很好理解,想想該位置沒有任何元素和已經存在一個鏈表這兩種情況
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
// 覆蓋舊值
e.value = value;
++modCount;
}
break;
}
// 繼續順著鏈表走
e = e.next;
}
else {
// node 到底是不是 null,這個要看獲取鎖的過程,不過和這里都沒有關系。
// 如果不為 null,那就直接將它設置為鏈表表頭;如果是null,初始化并設置為鏈表表頭。
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
// 如果超過了該 segment 的閾值,這個 segment 需要擴容
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node); // 擴容后面也會具體分析
else
// 沒有達到閾值,將 node 放到數組 tab 的 index 位置,
// 其實就是將新的節點設置成原鏈表的表頭
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
// 解鎖
unlock();
}
return oldValue;
}
整體流程還是比較簡單的,由于有獨占鎖的保護,所以 segment 內部的操作并不復雜。至于這里面的并發問題,我們稍后再進行介紹。
到這里 put 操作就結束了,接下來,我們說一說其中幾步關鍵的操作。
ConcurrentHashMap 初始化的時候會初始化第一個槽 segment[0],對于其他槽來說,在插入第一個值的時候進行初始化。
這里需要考慮并發,因為很可能會有多個線程同時進來初始化同一個槽 segment[k],不過只要有一個成功了就可以。
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
// 這里看到為什么之前要初始化 segment[0] 了,
// 使用當前 segment[0] 處的數組長度和負載因子來初始化 segment[k]
// 為什么要用“當前”,因為 segment[0] 可能早就擴容過了
Segment<K,V> proto = ss[0];
int cap = proto.table.length;
float lf = proto.loadFactor;
int threshold = (int)(cap * lf);
// 初始化 segment[k] 內部的數組
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) { // 再次檢查一遍該槽是否被其他線程初始化了。
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
// 使用 while 循環,內部用 CAS,當前線程成功設值或其他線程成功設值后,退出
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}
總的來說,ensureSegment(int k) 比較簡單,對于并發操作使用 CAS 進行控制。
我沒搞懂這里為什么要搞一個 while 循環,CAS 失敗不就代表有其他線程成功了嗎,為什么要再進行判斷?
感謝評論區的 李子木,如果當前線程 CAS 失敗,這里的 while 循環是為了將 seg 賦值返回。
前面我們看到,在往某個 segment 中 put 的時候,首先會調用 node = tryLock() ? null : scanAndLockForPut(key, hash, value),也就是說先進行一次 tryLock() 快速獲取該 segment 的獨占鎖,如果失敗,那么進入到 scanAndLockForPut 這個方法來獲取鎖。
下面我們來具體分析這個方法中是怎么控制加鎖的。
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
// 循環獲取鎖
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
if (retries < 0) {
if (e == null) {
if (node == null) // speculatively create node
// 進到這里說明數組該位置的鏈表是空的,沒有任何元素
// 當然,進到這里的另一個原因是 tryLock() 失敗,所以該槽存在并發,不一定是該位置
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
else if (key.equals(e.key))
retries = 0;
else
// 順著鏈表往下走
e = e.next;
}
// 重試次數如果超過 MAX_SCAN_RETRIES(單核1多核64),那么不搶了,進入到阻塞隊列等待鎖
// lock() 是阻塞方法,直到獲取鎖后返回
else if (++retries > MAX_SCAN_RETRIES) {
lock();
break;
}
else if ((retries & 1) == 0 &&
// 這個時候是有大問題了,那就是有新的元素進到了鏈表,成為了新的表頭
// 所以這邊的策略是,相當于重新走一遍這個 scanAndLockForPut 方法
(f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}
這個方法有兩個出口,一個是 tryLock() 成功了,循環終止,另一個就是重試次數超過了 MAX_SCAN_RETRIES,進到 lock() 方法,此方法會阻塞等待,直到成功拿到獨占鎖。
這個方法就是看似復雜,但是其實就是做了一件事,那就是 獲取該 segment 的獨占鎖,如果需要的話順便實例化了一下 node。
重復一下,segment 數組不能擴容,擴容是 segment 數組某個位置內部的數組 HashEntry
首先,我們要回顧一下觸發擴容的地方,put 的時候,如果判斷該值的插入會導致該 segment 的元素個數超過閾值,那么先進行擴容,再插值,讀者這個時候可以回去 put 方法看一眼。
該方法不需要考慮并發,因為到這里的時候,是持有該 segment 的獨占鎖的。
// 方法參數上的 node 是這次擴容后,需要添加到新的數組中的數據。
private void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
// 2 倍
int newCapacity = oldCapacity << 1;
threshold = (int)(newCapacity * loadFactor);
// 創建新數組
HashEntry<K,V>[] newTable =
(HashEntry<K,V>[]) new HashEntry[newCapacity];
// 新的掩碼,如從 16 擴容到 32,那么 sizeMask 為 31,對應二進制 ‘000...00011111’
int sizeMask = newCapacity - 1;
// 遍歷原數組,老套路,將原數組位置 i 處的鏈表拆分到 新數組位置 i 和 i+oldCap 兩個位置
for (int i = 0; i < oldCapacity ; i++) {
// e 是鏈表的第一個元素
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
// 計算應該放置在新數組中的位置,
// 假設原數組長度為 16,e 在 oldTable[3] 處,那么 idx 只可能是 3 或者是 3 + 16 = 19
int idx = e.hash & sizeMask;
if (next == null) // 該位置處只有一個元素,那比較好辦
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
// e 是鏈表表頭
HashEntry<K,V> lastRun = e;
// idx 是當前鏈表的頭結點 e 的新位置
int lastIdx = idx;
// 下面這個 for 循環會找到一個 lastRun 節點,這個節點之后的所有元素是將要放到一起的
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
// 將 lastRun 及其之后的所有節點組成的這個鏈表放到 lastIdx 這個位置
newTable[lastIdx] = lastRun;
// 下面的操作是處理 lastRun 之前的節點,
// 這些節點可能分配在另一個鏈表中,也可能分配到上面的那個鏈表中
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
// 將新來的 node 放到新數組中剛剛的 兩個鏈表之一 的 頭部
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}
這里的擴容比之前的 HashMap 要復雜一些,代碼難懂一點。上面有兩個挨著的 for 循環,第一個 for 有什么用呢?
仔細一看發現,如果沒有第一個 for 循環,也是可以工作的,但是,這個 for 循環下來,如果 lastRun 的后面還有比較多的節點,那么這次就是值得的。因為我們只需要克隆 lastRun 前面的節點,后面的一串節點跟著 lastRun 走就是了,不需要做任何操作。
我覺得 Doug Lea 的這個想法也是挺有意思的,不過比較壞的情況就是每次 lastRun 都是鏈表的最后一個元素或者很靠后的元素,那么這次遍歷就有點浪費了。 不過 Doug Lea 也說了,根據統計,如果使用默認的閾值,大約只有 1/6 的節點需要克隆。
相對于 put 來說,get 真的不要太簡單。
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
// 1\. hash 值
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
// 2\. 根據 hash 找到對應的 segment
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
// 3\. 找到segment 內部數組相應位置的鏈表,遍歷
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
現在我們已經說完了 put 過程和 get 過程,我們可以看到 get 過程中是沒有加鎖的,那自然我們就需要去考慮并發問題。
添加節點的操作 put 和刪除節點的操作 remove 都是要加 segment 上的獨占鎖的,所以它們之間自然不會有問題,我們需要考慮的問題就是 get 的時候在同一個 segment 中發生了 put 或 remove 操作。
put 操作的線程安全性。
remove 操作的線程安全性。
remove 操作我們沒有分析源碼,所以這里說的讀者感興趣的話還是需要到源碼中去求實一下的。
get 操作需要遍歷鏈表,但是 remove 操作會”破壞”鏈表。
如果 remove 破壞的節點 get 操作已經過去了,那么這里不存在任何問題。
如果 remove 先破壞了一個節點,分兩種情況考慮。 1、如果此節點是頭結點,那么需要將頭結點的 next 設置為數組該位置的元素,table 雖然使用了 volatile 修飾,但是 volatile 并不能提供數組內部操作的可見性保證,所以源碼中使用了 UNSAFE 來操作數組,請看方法 setEntryAt。2、如果要刪除的節點不是頭結點,它會將要刪除節點的后繼節點接到前驅節點中,這里的并發保證就是 next 屬性是 volatile 的。
Java8 對 HashMap 進行了一些修改,最大的不同就是利用了紅黑樹,所以其由 數組+鏈表+紅黑樹 組成。
根據 Java7 HashMap 的介紹,我們知道,查找的時候,根據 hash 值我們能夠快速定位到數組的具體下標,但是之后的話,需要順著鏈表一個個比較下去才能找到我們需要的,時間復雜度取決于鏈表的長度,為 O(n)。
為了降低這部分的開銷,在 Java8 中,當鏈表中的元素達到了 8 個時,會將鏈表轉換為紅黑樹,在這些位置進行查找的時候可以降低時間復雜度為 O(logN)。
來一張圖簡單示意一下吧:
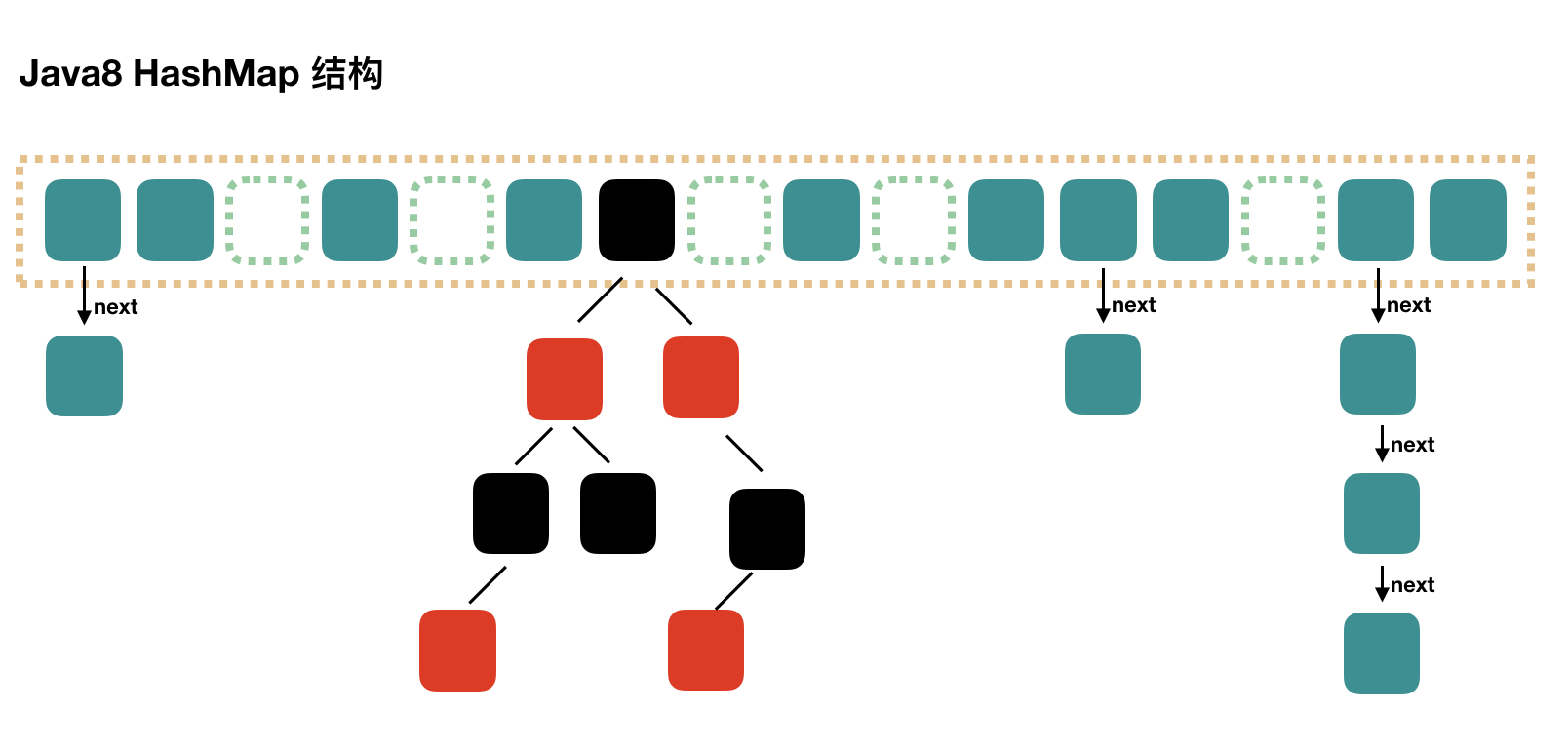
注意,上圖是示意圖,主要是描述結構,不會達到這個狀態的,因為這么多數據的時候早就擴容了。
下面,我們還是用代碼來介紹吧,個人感覺,Java8 的源碼可讀性要差一些,不過精簡一些。
Java7 中使用 Entry 來代表每個 HashMap 中的數據節點,Java8 中使用 Node,基本沒有區別,都是 key,value,hash 和 next 這四個屬性,不過,Node 只能用于鏈表的情況,紅黑樹的情況需要使用 TreeNode。
我們根據數組元素中,第一個節點數據類型是 Node 還是 TreeNode 來判斷該位置下是鏈表還是紅黑樹的。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
// 第三個參數 onlyIfAbsent 如果是 true,那么只有在不存在該 key 時才會進行 put 操作
// 第四個參數 evict 我們這里不關心
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 第一次 put 值的時候,會觸發下面的 resize(),類似 java7 的第一次 put 也要初始化數組長度
// 第一次 resize 和后續的擴容有些不一樣,因為這次是數組從 null 初始化到默認的 16 或自定義的初始容量
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 找到具體的數組下標,如果此位置沒有值,那么直接初始化一下 Node 并放置在這個位置就可以了
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {// 數組該位置有數據
Node<K,V> e; K k;
// 首先,判斷該位置的第一個數據和我們要插入的數據,key 是不是"相等",如果是,取出這個節點
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 如果該節點是代表紅黑樹的節點,調用紅黑樹的插值方法,本文不展開說紅黑樹
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 到這里,說明數組該位置上是一個鏈表
for (int binCount = 0; ; ++binCount) {
// 插入到鏈表的最后面(Java7 是插入到鏈表的最前面)
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// TREEIFY_THRESHOLD 為 8,所以,如果新插入的值是鏈表中的第 8 個
// 會觸發下面的 treeifyBin,也就是將鏈表轉換為紅黑樹
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 如果在該鏈表中找到了"相等"的 key(== 或 equals)
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// 此時 break,那么 e 為鏈表中[與要插入的新值的 key "相等"]的 node
break;
p = e;
}
}
// e!=null 說明存在舊值的key與要插入的key"相等"
// 對于我們分析的put操作,下面這個 if 其實就是進行 "值覆蓋",然后返回舊值
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 如果 HashMap 由于新插入這個值導致 size 已經超過了閾值,需要進行擴容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
和 Java7 稍微有點不一樣的地方就是,Java7 是先擴容后插入新值的,Java8 先插值再擴容,不過這個不重要。
resize() 方法用于 初始化數組或 數組擴容,每次擴容后,容量為原來的 2 倍,并進行數據遷移。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) { // 對應數組擴容
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 將數組大小擴大一倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 將閾值擴大一倍
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // 對應使用 new HashMap(int initialCapacity) 初始化后,第一次 put 的時候
newCap = oldThr;
else {// 對應使用 new HashMap() 初始化后,第一次 put 的時候
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
// 用新的數組大小初始化新的數組
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab; // 如果是初始化數組,到這里就結束了,返回 newTab 即可
if (oldTab != null) {
// 開始遍歷原數組,進行數據遷移。
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// 如果該數組位置上只有單個元素,那就簡單了,簡單遷移這個元素就可以了
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
// 如果是紅黑樹,具體我們就不展開了
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
// 這塊是處理鏈表的情況,
// 需要將此鏈表拆成兩個鏈表,放到新的數組中,并且保留原來的先后順序
// loHead、loTail 對應一條鏈表,hiHead、hiTail 對應另一條鏈表,代碼還是比較簡單的
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
// 第一條鏈表
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
// 第二條鏈表的新的位置是 j + oldCap,這個很好理解
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
相對于 put 來說,get 真的太簡單了。
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 判斷第一個節點是不是就是需要的
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
// 判斷是否是紅黑樹
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 鏈表遍歷
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
Java7 中實現的 ConcurrentHashMap 說實話還是比較復雜的,Java8 對 ConcurrentHashMap 進行了比較大的改動。建議讀者可以參考 Java8 中 HashMap 相對于 Java7 HashMap 的改動,對于 ConcurrentHashMap,Java8 也引入了紅黑樹。
說實話,Java8 ConcurrentHashMap 源碼真心不簡單,最難的在于擴容,數據遷移操作不容易看懂。
我們先用一個示意圖來描述下其結構:
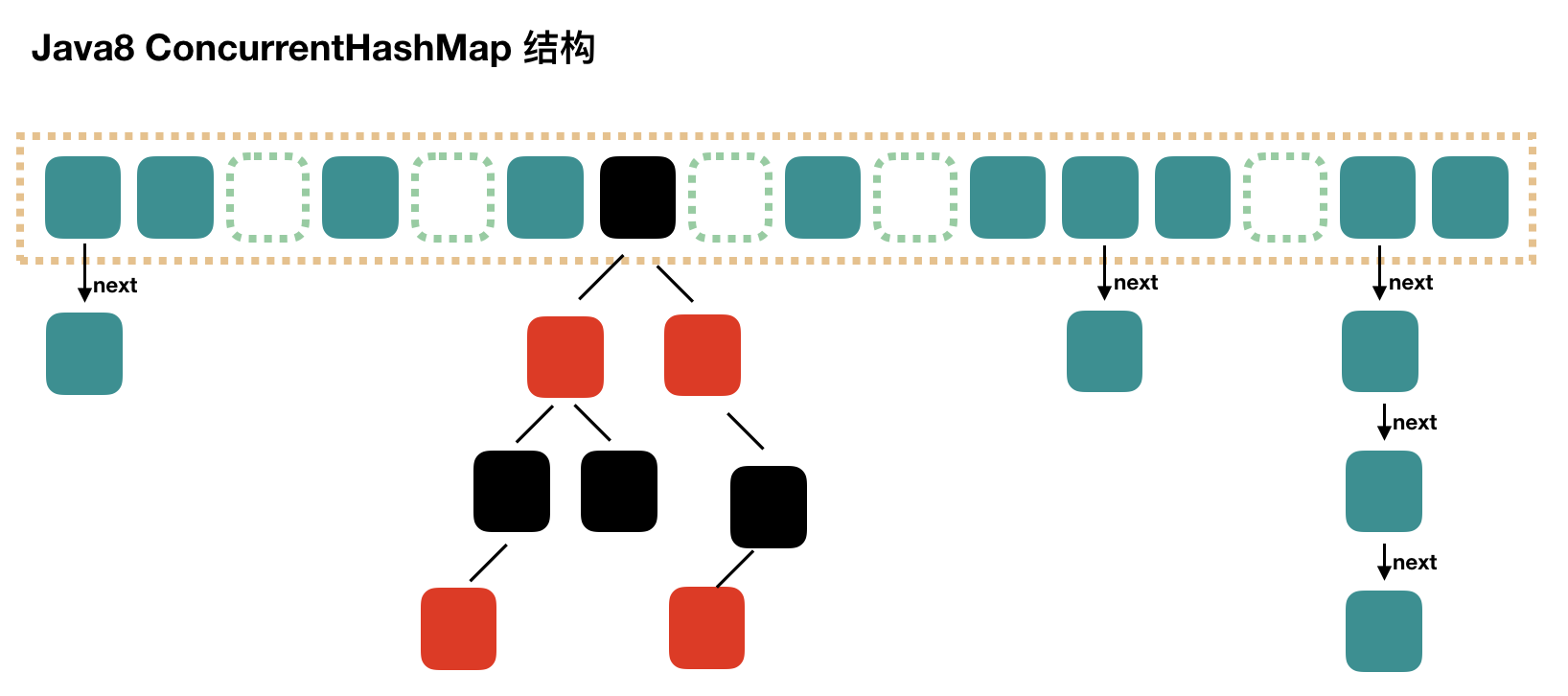
結構上和 Java8 的 HashMap 基本上一樣,不過它要保證線程安全性,所以在源碼上確實要復雜一些。
// 這構造函數里,什么都不干
public ConcurrentHashMap() {
}
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
這個初始化方法有點意思,通過提供初始容量,計算了 sizeCtl,sizeCtl = 【 (1.5 * initialCapacity + 1),然后向上取最近的 2 的 n 次方】。如 initialCapacity 為 10,那么得到 sizeCtl 為 16,如果 initialCapacity 為 11,得到 sizeCtl 為 32。
sizeCtl 這個屬性使用的場景很多,不過只要跟著文章的思路來,就不會被它搞暈了。
如果你愛折騰,也可以看下另一個有三個參數的構造方法,這里我就不說了,大部分時候,我們會使用無參構造函數進行實例化,我們也按照這個思路來進行源碼分析吧。
仔細地一行一行代碼看下去:
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
// 得到 hash 值
int hash = spread(key.hashCode());
// 用于記錄相應鏈表的長度
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 如果數組"空",進行數組初始化
if (tab == null || (n = tab.length) == 0)
// 初始化數組,后面會詳細介紹
tab = initTable();
// 找該 hash 值對應的數組下標,得到第一個節點 f
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 如果數組該位置為空,
// 用一次 CAS 操作將這個新值放入其中即可,這個 put 操作差不多就結束了,可以拉到最后面了
// 如果 CAS 失敗,那就是有并發操作,進到下一個循環就好了
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// hash 居然可以等于 MOVED,這個需要到后面才能看明白,不過從名字上也能猜到,肯定是因為在擴容
else if ((fh = f.hash) == MOVED)
// 幫助數據遷移,這個等到看完數據遷移部分的介紹后,再理解這個就很簡單了
tab = helpTransfer(tab, f);
else { // 到這里就是說,f 是該位置的頭結點,而且不為空
V oldVal = null;
// 獲取數組該位置的頭結點的監視器鎖
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) { // 頭結點的 hash 值大于 0,說明是鏈表
// 用于累加,記錄鏈表的長度
binCount = 1;
// 遍歷鏈表
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 如果發現了"相等"的 key,判斷是否要進行值覆蓋,然后也就可以 break 了
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
// 到了鏈表的最末端,將這個新值放到鏈表的最后面
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) { // 紅黑樹
Node<K,V> p;
binCount = 2;
// 調用紅黑樹的插值方法插入新節點
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 判斷是否要將鏈表轉換為紅黑樹,臨界值和 HashMap 一樣,也是 8
if (binCount >= TREEIFY_THRESHOLD)
// 這個方法和 HashMap 中稍微有一點點不同,那就是它不是一定會進行紅黑樹轉換,
// 如果當前數組的長度小于 64,那么會選擇進行數組擴容,而不是轉換為紅黑樹
// 具體源碼我們就不看了,擴容部分后面說
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//
addCount(1L, binCount);
return null;
}
put 的主流程看完了,但是至少留下了幾個問題,第一個是初始化,第二個是擴容,第三個是幫助數據遷移,這些我們都會在后面進行一一介紹。
這個比較簡單,主要就是初始化一個 合適大小的數組,然后會設置 sizeCtl。
初始化方法中的并發問題是通過對 sizeCtl 進行一個 CAS 操作來控制的。
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
// 初始化的"功勞"被其他線程"搶去"了
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
// CAS 一下,將 sizeCtl 設置為 -1,代表搶到了鎖
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
// DEFAULT_CAPACITY 默認初始容量是 16
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
// 初始化數組,長度為 16 或初始化時提供的長度
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
// 將這個數組賦值給 table,table 是 volatile 的
table = tab = nt;
// 如果 n 為 16 的話,那么這里 sc = 12
// 其實就是 0.75 * n
sc = n - (n >>> 2);
}
} finally {
// 設置 sizeCtl 為 sc,我們就當是 12 吧
sizeCtl = sc;
}
break;
}
}
return tab;
}
前面我們在 put 源碼分析也說過,treeifyBin 不一定就會進行紅黑樹轉換,也可能是僅僅做數組擴容。我們還是進行源碼分析吧。
private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
if (tab != null) {
// MIN_TREEIFY_CAPACITY 為 64
// 所以,如果數組長度小于 64 的時候,其實也就是 32 或者 16 或者更小的時候,會進行數組擴容
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
// 后面我們再詳細分析這個方法
tryPresize(n << 1);
// b 是頭結點
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
// 加鎖
synchronized (b) {
if (tabAt(tab, index) == b) {
// 下面就是遍歷鏈表,建立一顆紅黑樹
TreeNode<K,V> hd = null, tl = null;
for (Node<K,V> e = b; e != null; e = e.next) {
TreeNode<K,V> p =
new TreeNode<K,V>(e.hash, e.key, e.val,
null, null);
if ((p.prev = tl) == null)
hd = p;
else
tl.next = p;
tl = p;
}
// 將紅黑樹設置到數組相應位置中
setTabAt(tab, index, new TreeBin<K,V>(hd));
}
}
}
}
}
如果說 Java8 ConcurrentHashMap 的源碼不簡單,那么說的就是擴容操作和遷移操作。
這個方法要完完全全看懂還需要看之后的 transfer 方法,讀者應該提前知道這點。
這里的擴容也是做翻倍擴容的,擴容后數組容量為原來的 2 倍。
// 首先要說明的是,方法參數 size 傳進來的時候就已經翻了倍了
private final void tryPresize(int size) {
// c:size 的 1.5 倍,再加 1,再往上取最近的 2 的 n 次方。
int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :
tableSizeFor(size + (size >>> 1) + 1);
int sc;
while ((sc = sizeCtl) >= 0) {
Node<K,V>[] tab = table; int n;
// 這個 if 分支和之前說的初始化數組的代碼基本上是一樣的,在這里,我們可以不用管這塊代碼
if (tab == null || (n = tab.length) == 0) {
n = (sc > c) ? sc : c;
if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if (table == tab) {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = nt;
sc = n - (n >>> 2); // 0.75 * n
}
} finally {
sizeCtl = sc;
}
}
}
else if (c <= sc || n >= MAXIMUM_CAPACITY)
break;
else if (tab == table) {
// 我沒看懂 rs 的真正含義是什么,不過也關系不大
int rs = resizeStamp(n);
if (sc < 0) {
Node<K,V>[] nt;
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
// 2\. 用 CAS 將 sizeCtl 加 1,然后執行 transfer 方法
// 此時 nextTab 不為 null
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
// 1\. 將 sizeCtl 設置為 (rs << RESIZE_STAMP_SHIFT) + 2)
// 我是沒看懂這個值真正的意義是什么?不過可以計算出來的是,結果是一個比較大的負數
// 調用 transfer 方法,此時 nextTab 參數為 null
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
}
}
}
這個方法的核心在于 sizeCtl 值的操作,首先將其設置為一個負數,然后執行 transfer(tab, null),再下一個循環將 sizeCtl 加 1,并執行 transfer(tab, nt),之后可能是繼續 sizeCtl 加 1,并執行 transfer(tab, nt)。
所以,可能的操作就是執行 1 次 transfer(tab, null) + 多次 transfer(tab, nt),這里怎么結束循環的需要看完 transfer 源碼才清楚。
下面這個方法有點長,將原來的 tab 數組的元素遷移到新的 nextTab 數組中。
雖然我們之前說的 tryPresize 方法中多次調用 transfer 不涉及多線程,但是這個 transfer 方法可以在其他地方被調用,典型地,我們之前在說 put 方法的時候就說過了,請往上看 put 方法,是不是有個地方調用了 helpTransfer 方法,helpTransfer 方法會調用 transfer 方法的。
此方法支持多線程執行,外圍調用此方法的時候,會保證第一個發起數據遷移的線程,nextTab 參數為 null,之后再調用此方法的時候,nextTab 不會為 null。
閱讀源碼之前,先要理解并發操作的機制。原數組長度為 n,所以我們有 n 個遷移任務,讓每個線程每次負責一個小任務是最簡單的,每做完一個任務再檢測是否有其他沒做完的任務,幫助遷移就可以了,而 Doug Lea 使用了一個 stride,簡單理解就是 步長,每個線程每次負責遷移其中的一部分,如每次遷移 16 個小任務。所以,我們就需要一個全局的調度者來安排哪個線程執行哪幾個任務,這個就是屬性 transferIndex 的作用。
第一個發起數據遷移的線程會將 transferIndex 指向原數組最后的位置,然后 從后往前的 stride 個任務屬于第一個線程,然后將 transferIndex 指向新的位置,再往前的 stride 個任務屬于第二個線程,依此類推。當然,這里說的第二個線程不是真的一定指代了第二個線程,也可以是同一個線程,這個讀者應該能理解吧。其實就是將一個大的遷移任務分為了一個個任務包。
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
// stride 在單核下直接等于 n,多核模式下為 (n>>>3)/NCPU,最小值是 16
// stride 可以理解為”步長“,有 n 個位置是需要進行遷移的,
// 將這 n 個任務分為多個任務包,每個任務包有 stride 個任務
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
// 如果 nextTab 為 null,先進行一次初始化
// 前面我們說了,外圍會保證第一個發起遷移的線程調用此方法時,參數 nextTab 為 null
// 之后參與遷移的線程調用此方法時,nextTab 不會為 null
if (nextTab == null) {
try {
// 容量翻倍
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
// nextTable 是 ConcurrentHashMap 中的屬性
nextTable = nextTab;
// transferIndex 也是 ConcurrentHashMap 的屬性,用于控制遷移的位置
transferIndex = n;
}
int nextn = nextTab.length;
// ForwardingNode 翻譯過來就是正在被遷移的 Node
// 這個構造方法會生成一個Node,key、value 和 next 都為 null,關鍵是 hash 為 MOVED
// 后面我們會看到,原數組中位置 i 處的節點完成遷移工作后,
// 就會將位置 i 處設置為這個 ForwardingNode,用來告訴其他線程該位置已經處理過了
// 所以它其實相當于是一個標志。
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
// advance 指的是做完了一個位置的遷移工作,可以準備做下一個位置的了
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
/*
* 下面這個 for 循環,最難理解的在前面,而要看懂它們,應該先看懂后面的,然后再倒回來看
*
*/
// i 是位置索引,bound 是邊界,注意是從后往前
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
// 下面這個 while 真的是不好理解
// advance 為 true 表示可以進行下一個位置的遷移了
// 簡單理解結局:i 指向了 transferIndex,bound 指向了 transferIndex-stride
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
// 將 transferIndex 值賦給 nextIndex
// 這里 transferIndex 一旦小于等于 0,說明原數組的所有位置都有相應的線程去處理了
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
// 看括號中的代碼,nextBound 是這次遷移任務的邊界,注意,是從后往前
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) {
// 所有的遷移操作已經完成
nextTable = null;
// 將新的 nextTab 賦值給 table 屬性,完成遷移
table = nextTab;
// 重新計算 sizeCtl:n 是原數組長度,所以 sizeCtl 得出的值將是新數組長度的 0.75 倍
sizeCtl = (n << 1) - (n >>> 1);
return;
}
// 之前我們說過,sizeCtl 在遷移前會設置為 (rs << RESIZE_STAMP_SHIFT) + 2
// 然后,每有一個線程參與遷移就會將 sizeCtl 加 1,
// 這里使用 CAS 操作對 sizeCtl 進行減 1,代表做完了屬于自己的任務
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
// 任務結束,方法退出
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
// 到這里,說明 (sc - 2) == resizeStamp(n) << RESIZE_STAMP_SHIFT,
// 也就是說,所有的遷移任務都做完了,也就會進入到上面的 if(finishing){} 分支了
finishing = advance = true;
i = n; // recheck before commit
}
}
// 如果位置 i 處是空的,沒有任何節點,那么放入剛剛初始化的 ForwardingNode ”空節點“
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
// 該位置處是一個 ForwardingNode,代表該位置已經遷移過了
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
// 對數組該位置處的結點加鎖,開始處理數組該位置處的遷移工作
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
// 頭結點的 hash 大于 0,說明是鏈表的 Node 節點
if (fh >= 0) {
// 下面這一塊和 Java7 中的 ConcurrentHashMap 遷移是差不多的,
// 需要將鏈表一分為二,
// 找到原鏈表中的 lastRun,然后 lastRun 及其之后的節點是一起進行遷移的
// lastRun 之前的節點需要進行克隆,然后分到兩個鏈表中
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
// 其中的一個鏈表放在新數組的位置 i
setTabAt(nextTab, i, ln);
// 另一個鏈表放在新數組的位置 i+n
setTabAt(nextTab, i + n, hn);
// 將原數組該位置處設置為 fwd,代表該位置已經處理完畢,
// 其他線程一旦看到該位置的 hash 值為 MOVED,就不會進行遷移了
setTabAt(tab, i, fwd);
// advance 設置為 true,代表該位置已經遷移完畢
advance = true;
}
else if (f instanceof TreeBin) {
// 紅黑樹的遷移
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
// 如果一分為二后,節點數少于 8,那么將紅黑樹轉換回鏈表
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
// 將 ln 放置在新數組的位置 i
setTabAt(nextTab, i, ln);
// 將 hn 放置在新數組的位置 i+n
setTabAt(nextTab, i + n, hn);
// 將原數組該位置處設置為 fwd,代表該位置已經處理完畢,
// 其他線程一旦看到該位置的 hash 值為 MOVED,就不會進行遷移了
setTabAt(tab, i, fwd);
// advance 設置為 true,代表該位置已經遷移完畢
advance = true;
}
}
}
}
}
}
說到底,transfer 這個方法并沒有實現所有的遷移任務,每次調用這個方法只實現了 transferIndex 往前 stride 個位置的遷移工作,其他的需要由外圍來控制。
這個時候,再回去仔細看 tryPresize 方法可能就會更加清晰一些了。
get 方法從來都是最簡單的,這里也不例外:
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
// 判斷頭結點是否就是我們需要的節點
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// 如果頭結點的 hash 小于 0,說明 正在擴容,或者該位置是紅黑樹
else if (eh < 0)
// 參考 ForwardingNode.find(int h, Object k) 和 TreeBin.find(int h, Object k)
return (p = e.find(h, key)) != null ? p.val : null;
// 遍歷鏈表
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
簡單說一句,此方法的大部分內容都很簡單,只有正好碰到擴容的情況,ForwardingNode.find(int h, Object k) 稍微復雜一些,不過在了解了數據遷移的過程后,這個也就不難了,所以限于篇幅這里也不展開說了。
其實也不是很難嘛,雖然沒有像之前的 AQS 和線程池一樣一行一行源碼進行分析,但還是把所有初學者可能會糊涂的地方都進行了深入的介紹,只要是稍微有點基礎的讀者,應該是很容易就能看懂 HashMap 和 ConcurrentHashMap 源碼了。
看源碼不算是目的吧,深入地了解 Doug Lea 的設計思路,我覺得還挺有趣的,大師就是大師,代碼寫得真的是好啊。
我發現很多人都以為我寫博客主要是源碼分析,說真的,我對于源碼分析沒有那么大熱情,主要都是為了用源碼說事罷了,可能之后的文章還是會有比較多的源碼分析成分。
不要臉地自以為本文的質量還是挺高的,信息量比較大,如果你覺得有寫得不好的地方,或者說看完本文你還是沒看懂它們,那么請提出來
~
(全文完)
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





