溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Java IO模型與Java網絡編程模型的對比”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Java IO模型與Java網絡編程模型的對比”吧!
作者:cooffeelis
鏈接:
https://www.jianshu.com/p/511b9cffbdac
來源:簡書
著作權歸作者所有。商業轉載請聯系作者獲得授權,非商業轉載請注明出處。
常用的5種IO模型:
blocking IO
nonblocking IO
IO multiplexing
signal driven IO
asynchronous IO
再說一下IO發生時涉及的對象和步驟:
對于一個network IO (這里我們以read舉例),它會涉及到兩個系統對象:
一個是調用這個IO的process (or thread)
一個就是系統內核(kernel)
當一個read操作發生時,它會經歷兩個階段:
等待數據準備,比如accept(), recv()等待數據
(Waiting for the data to be ready)
將數據從內核拷貝到進程中, 比如 accept()接受到請求,recv()接收連接發送的數據后需要復制到內核,再從內核復制到進程用戶空間(Copying the data from the kernel to the process)
對于socket流而言,數據的流向經歷兩個階段:
第一步通常涉及等待網絡上的數據分組到達,然后被復制到內核的某個緩沖區。
第二步把數據從內核緩沖區復制到應用進程緩沖區。
記住這兩點很重要,因為這些IO Model的區別就是在兩個階段上各有不同的情況。
在linux中,默認情況下所有的socket都是blocking,一個典型的讀操作流程大概是這樣:

阻塞IO流程
當用戶進程調用了recvfrom這個系統調用,kernel就開始了IO的第一個階段:準備數據(對于網絡IO來說,很多時候數據在一開始還沒有到達。比如,還沒有收到一個完整的UDP包。這個時候kernel就要等待足夠的數據到來)。這個過程需要等待,也就是說數據被拷貝到操作系統內核的緩沖區中是需要一個過程的。而在用戶進程這邊,整個進程會被阻塞(當然,是進程自己選擇的阻塞)。當kernel一直等到數據準備好了,它就會將數據從kernel中拷貝到用戶內存,然后kernel返回結果,用戶進程才解除block的狀態,重新運行起來。
所以,blocking IO的特點就是在IO執行的兩個階段都被block了。
linux下,可以通過設置socket使其變為non-blocking。當對一個non-blocking socket執行讀操作時,流程是這個樣子:

非阻塞 I/O 流程
當用戶進程發出read操作時,如果kernel中的數據還沒有準備好,那么它并不會block用戶進程,而是立刻返回一個error。從用戶進程角度講 ,它發起一個read操作后,并不需要等待,而是馬上就得到了一個結果。用戶進程判斷結果是一個error時,它就知道數據還沒有準備好,于是它可以再次發送read操作。一旦kernel中的數據準備好了,并且又再次收到了用戶進程的system call,那么它馬上就將數據拷貝到了用戶內存,然后返回。
所以,nonblocking IO的特點是用戶進程需要不斷的主動詢問kernel數據好了沒有。
值得注意的是,此時的非阻塞IO只是應用到等待數據上,當真正有數據到達執行recvfrom的時候,還是同步阻塞IO來的, 從圖中的copy data from kernel to user可以看出
IO multiplexing就是我們說的select,poll,epoll,有些地方也稱這種IO方式為event driven IO。select/epoll的好處就在于單個process就可以同時處理多個網絡連接的IO。它的基本原理就是select,poll,epoll這個function會不斷的輪詢所負責的所有socket,當某個socket有數據到達了,就通知用戶進程。

I/O 多路復用流程
這個圖和blocking IO的圖其實并沒有太大的不同,事實上,還更差一些。因為這里需要使用兩個system call (select 和 recvfrom),而blocking IO只調用了一個system call (recvfrom)。但是,用select的優勢在于它可以同時處理多個connection。
所以,如果處理的連接數不是很高的話,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延遲還更大。select/epoll的優勢并不是對于單個連接能處理得更快,而是在于能處理更多的連接。)
IO復用的實現方式目前主要有select、poll和epoll。
select和poll的原理基本相同:
注冊待偵聽的fd(這里的fd創建時最好使用非阻塞)
每次調用都去檢查這些fd的狀態,當有一個或者多個fd就緒的時候返回
返回結果中包括已就緒和未就緒的fd
相比select,poll解決了單個進程能夠打開的文件描述符數量有限制這個問題:select受限于FD_SIZE的限制,如果修改則需要修改這個宏重新編譯內核;而poll通過一個pollfd數組向內核傳遞需要關注的事件,避開了文件描述符數量限制。
此外,select和poll共同具有的一個很大的缺點就是包含大量fd的數組被整體復制于用戶態和內核態地址空間之間,開銷會隨著fd數量增多而線性增大。
select和poll就類似于上面說的就餐方式。但當你每次都去詢問時,老板會把所有你點的飯菜都輪詢一遍再告訴你情況,當大量飯菜很長時間都不能準備好的情況下是很低效的。于是,老板有些不耐煩了,就讓廚師每做好一個菜就通知他。這樣每次你再去問的時候,他會直接把已經準備好的菜告訴你,你再去端。這就是事件驅動IO就緒通知的方式-epoll。
epoll的出現,解決了select、poll的缺點:
基于事件驅動的方式,避免了每次都要把所有fd都掃描一遍。
epoll_wait只返回就緒的fd。
epoll使用nmap內存映射技術避免了內存復制的開銷。
epoll的fd數量上限是操作系統的最大文件句柄數目,這個數目一般和內存有關,通常遠大于1024。
目前,epoll是Linux2.6下最高效的IO復用方式,也是Nginx、Node的IO實現方式。而在freeBSD下,kqueue是另一種類似于epoll的IO復用方式。
此外,對于IO復用還有一個水平觸發和邊緣觸發的概念:
水平觸發:當就緒的fd未被用戶進程處理后,下一次查詢依舊會返回,這是select和poll的觸發方式。
邊緣觸發:無論就緒的fd是否被處理,下一次不再返回。理論上性能更高,但是實現相當復雜,并且任何意外的丟失事件都會造成請求處理錯誤。epoll默認使用水平觸發,通過相應選項可以使用邊緣觸發。
點評:
I/O 多路復用的特點是通過一種機制一個進程能同時等待多個文件描述符,而這些文件描述符(套接字描述符)其中的任意一個進入讀就緒狀態,select()函數就可以返回。
所以, IO多路復用,本質上不會有并發的功能,因為任何時候還是只有一個進程或線程進行工作,它之所以能提高效率是因為select\epoll 把進來的socket放到他們的 ‘監視’ 列表里面,當任何socket有可讀可寫數據立馬處理,那如果select\epoll 手里同時檢測著很多socket, 一有動靜馬上返回給進程處理,總比一個一個socket過來,阻塞等待,處理高效率。
當然也可以多線程/多進程方式,一個連接過來開一個進程/線程處理,這樣消耗的內存和進程切換頁會耗掉更多的系統資源。
所以我們可以結合IO多路復用和多進程/多線程 來高性能并發,IO復用負責提高接受socket的通知效率,收到請求后,交給進程池/線程池來處理邏輯。信號驅動
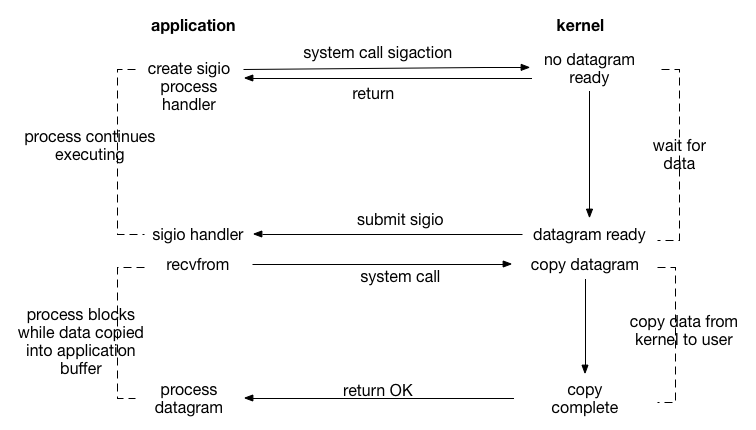
上文的就餐方式還是需要你每次都去問一下飯菜狀況。于是,你再次不耐煩了,就跟老板說,哪個飯菜好了就通知我一聲吧。然后就自己坐在桌子那里干自己的事情。更甚者,你可以把手機號留給老板,自己出門,等飯菜好了直接發條短信給你。這就類似信號驅動的IO模型。
流程如下:
開啟套接字信號驅動IO功能
系統調用sigaction執行信號處理函數(非阻塞,立刻返回)
數據就緒,生成sigio信號,通過信號回調通知應用來讀取數據。
此種io方式存在的一個很大的問題:Linux中信號隊列是有限制的,如果超過這個數字問題就無法讀取數據。
異步非阻塞
linux下的asynchronous IO其實用得很少。先看一下它的流程:

異步IO 流程
用戶進程發起read操作之后,立刻就可以開始去做其它的事。而另一方面,從kernel的角度,當它受到一個asynchronous read之后,首先它會立刻返回,所以不會對用戶進程產生任何block。然后,kernel會等待數據準備完成,然后將數據拷貝到用戶內存,當這一切都完成之后,kernel會給用戶進程發送一個signal,告訴它read操作完成了。
阻塞IO VS 非阻塞IO:
概念:
阻塞和非阻塞關注的是程序在等待調用結果(消息,返回值)時的狀態.
阻塞調用是指調用結果返回之前,當前線程會被掛起。調用線程只有在得到結果之后才會返回。非阻塞調用指在不能立刻得到結果之前,該調用不會阻塞當前線程。
例子:你打電話問書店老板有沒有《分布式系統》這本書,你如果是阻塞式調用,你會一直把自己“掛起”,直到得到這本書有沒有的結果,如果是非阻塞式調用,你不管老板有沒有告訴你,你自己先一邊去玩了, 當然你也要偶爾過幾分鐘check一下老板有沒有返回結果。在這里阻塞與非阻塞與是否同步異步無關。跟老板通過什么方式回答你結果無關。
分析:
阻塞IO會一直block住對應的進程直到操作完成,而非阻塞IO在kernel還準備數據的情況下會立刻返回。
同步IO VS 異步IO:
概念:
同步與異步同步和異步關注的是消息通信機制 (synchronous communication/ asynchronous communication)所謂同步,就是在發出一個調用時,在沒有得到結果之前,該調用就不返回。但是一旦調用返回,就得到返回值了。換句話說,就是由調用者主動等待這個調用的結果。而異步則是相反,調用在發出之后,這個調用就直接返回了,所以沒有返回結果。換句話說,當一個異步過程調用發出后,調用者不會立刻得到結果。而是在調用發出后,被調用者通過狀態、通知來通知調用者,或通過回調函數處理這個調用。
典型的異步編程模型比如Node.js舉個通俗的例子:你打電話問書店老板有沒有《分布式系統》這本書,如果是同步通信機制,書店老板會說,你稍等,”我查一下”,然后開始查啊查,等查好了(可能是5秒,也可能是一天)告訴你結果(返回結果)。而異步通信機制,書店老板直接告訴你我查一下啊,查好了打電話給你,然后直接掛電話了(不返回結果)。然后查好了,他會主動打電話給你。在這里老板通過“回電”這種方式來回調。
分析:
在說明同步IO和異步IO的區別之前,需要先給出兩者的定義。Stevens給出的定義(其實是POSIX的定義)是這樣子的:
A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes;
An asynchronous I/O operation does not cause the requesting process to be blocked;
兩者的區別就在于同步IO做”IO operation”的時候會將process阻塞。按照這個定義,之前所述的阻塞IO,非阻塞IO ,IO復用都屬于同步IO。
有人可能會說,非阻塞IO 并沒有被block啊。這里有個非常“狡猾”的地方,定義中所指的”IO operation”是指真實的IO操作,就是例子中的recvfrom這個system call。非阻塞IO在執行recvfrom這個system call的時候,如果kernel的數據沒有準備好,這時候不會block進程。但是,當kernel中數據準備好的時候,recvfrom會將數據從kernel拷貝到用戶內存中,這個時候進程是被block了,在這段時間內,進程是被block的。
而異步IO則不一樣,當進程發起IO 操作之后,就直接返回再也不理睬了,直到kernel發送一個信號,告訴進程說IO完成。在這整個過程中,進程完全沒有被block。
最后,再舉幾個不是很恰當的例子來說明這四個IO Model:
有A,B,C,D四個人在釣魚:
A用的是最老式的魚竿,所以呢,得一直守著,等到魚上鉤了再拉桿;
B的魚竿有個功能,能夠顯示是否有魚上鉤,所以呢,B就和旁邊的MM聊天,隔會再看看有沒有魚上鉤,有的話就迅速拉桿;
C用的魚竿和B差不多,但他想了一個好辦法,就是同時放好幾根魚竿,然后守在旁邊,一旦有顯示說魚上鉤了,它就將對應的魚竿拉起來;
D是個有錢人,干脆雇了一個人幫他釣魚,一旦那個人把魚釣上來了,就給D發個短信。
select,poll,epoll本質上都是同步I/O,因為他們都需要在讀寫事件就緒后自己負責進行讀寫,也就是說這個讀寫過程是阻塞的
Select/Poll/Epoll 都是IO復用的實現方式, 上面說了使用IO復用,會把socket設置成non-blocking,然后放進Select/Poll/Epoll 各自的監視列表里面,那么,他們的對socket是否有數據到達的監視機制分別是怎樣的?效率又如何?我們應該使用哪種方式實現IO復用比較好?下面列出他們各自的實現方式,效率,優缺點:
(1)select,poll實現需要自己不斷輪詢所有fd集合,直到設備就緒,期間可能要睡眠和喚醒多次交替。而epoll其實也需要調用epoll_wait不斷輪詢就緒鏈表,期間也可能多次睡眠和喚醒交替,但是它是設備就緒時,調用回調函數,把就緒fd放入就緒鏈表中,并喚醒在epoll_wait中進入睡眠的進程。雖然都要睡眠和交替,但是select和poll在“醒著”的時候要遍歷整個fd集合,而epoll在“醒著”的時候只要判斷一下就緒鏈表是否為空就行了,這節省了大量的CPU時間。這就是回調機制帶來的性能提升。
(2)select,poll每次調用都要把fd集合從用戶態往內核態拷貝一次,并且要把current往設備等待隊列中掛一次,而epoll只要一次拷貝,而且把current往等待隊列上掛也只掛一次(在epoll_wait的開始,注意這里的等待隊列并不是設備等待隊列,只是一個epoll內部定義的等待隊列)。這也能節省不少的開銷。
上文講述了UNIX環境的五種IO模型。基于這五種模型,在Java中,隨著NIO和NIO2.0(AIO)的引入,一般具有以下幾種網絡編程模型:
BIO
NIO
AIO
BIO是一個典型的網絡編程模型,是通常我們實現一個服務端程序的過程,步驟如下:
主線程accept請求阻塞
請求到達,創建新的線程來處理這個套接字,完成對客戶端的響應。
主線程繼續accept下一個請求
這種模型有一個很大的問題是:當客戶端連接增多時,服務端創建的線程也會暴漲,系統性能會急劇下降。因此,在此模型的基礎上,類似于 tomcat的bio connector,采用的是線程池來避免對于每一個客戶端都創建一個線程。有些地方把這種方式叫做偽異步IO(把請求拋到線程池中異步等待處理)。
JDK1.4開始引入了NIO類庫,這里的NIO指的是New IO,主要是使用Selector多路復用器來實現。Selector在Linux等主流操作系統上是通過epoll實現的。
NIO的實現流程,類似于select:
創建ServerSocketChannel監聽客戶端連接并綁定監聽端口,設置為非阻塞模式。
創建Reactor線程,創建多路復用器(Selector)并啟動線程。
將ServerSocketChannel注冊到Reactor線程的Selector上。監聽accept事件。
Selector在線程run方法中無線循環輪詢準備就緒的Key。
Selector監聽到新的客戶端接入,處理新的請求,完成tcp三次握手,建立物理連接。
將新的客戶端連接注冊到Selector上,監聽讀操作。讀取客戶端發送的網絡消息。
客戶端發送的數據就緒則讀取客戶端請求,進行處理。
相比BIO,NIO的編程非常復雜。
JDK1.7引入NIO2.0,提供了異步文件通道和異步套接字通道的實現。其底層在windows上是通過IOCP,在Linux上是通過epoll來實現的(LinuxAsynchronousChannelProvider.java,UnixAsynchronousServerSocketChannelImpl.java)。
創建AsynchronousServerSocketChannel,綁定監聽端口
調用AsynchronousServerSocketChannel的accpet方法,傳入自己實現的CompletionHandler。包括上一步,都是非阻塞的
連接傳入,回調CompletionHandler的completed方法,在里面,調用AsynchronousSocketChannel的read方法,傳入負責處理數據的CompletionHandler。
數據就緒,觸發負責處理數據的CompletionHandler的completed方法。繼續做下一步處理即可。
寫入操作類似,也需要傳入CompletionHandler。
其編程模型相比NIO有了不少的簡化。
| . | 同步阻塞IO | 偽異步IO | NIO | AIO |
|---|---|---|---|---|
| 客戶端數目 :IO線程 | 1 : 1 | m : n | m : 1 | m : 0 |
| IO模型 | 同步阻塞IO | 同步阻塞IO | 同步非阻塞IO | 異步非阻塞IO |
| 吞吐量 | 低 | 中 | 高 | 高 |
| 編程復雜度 | 簡單 | 簡單 | 非常復雜 | 復雜 |
到此,相信大家對“Java IO模型與Java網絡編程模型的對比”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。