溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Spark SQL外部數據源的機制以及spark-sql的使用”,在日常操作中,相信很多人在Spark SQL外部數據源的機制以及spark-sql的使用問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Spark SQL外部數據源的機制以及spark-sql的使用”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
例如你第一次讀的是 id:1,name:xxx 第二次 id:1,name:xxx,session:222 這樣代碼就要改 還有數據類型如果你是 id:"xxx" 根本不行
FileSystem:HDFS,Hbase,S3,OSS 等 HDFS 與 mysql join 你要用sqoop把 hdfs,mysql都要記載到hive中 但是用spark 一句話就可以
--packages 優點,靈活,給你都拉去過來本地有的,沒有的才下載的 缺點:生產中集群不能上網,maven沒用 解決辦法:有--jars 打成jar包傳上去
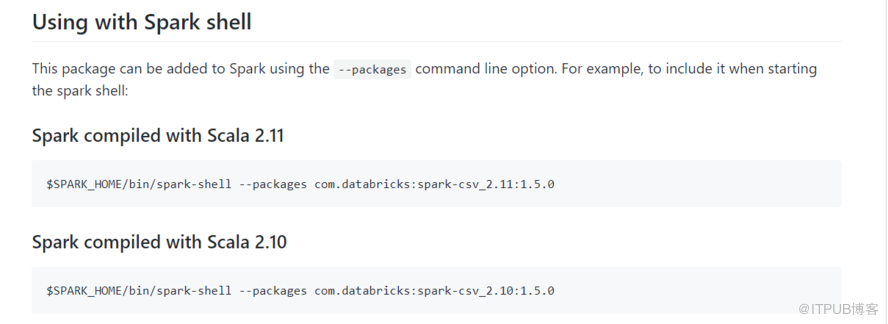
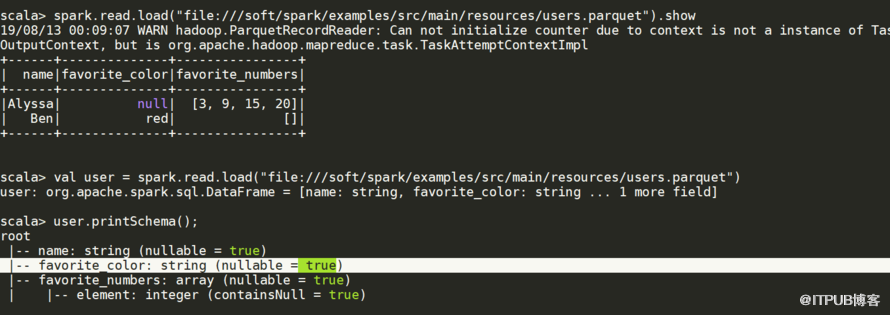
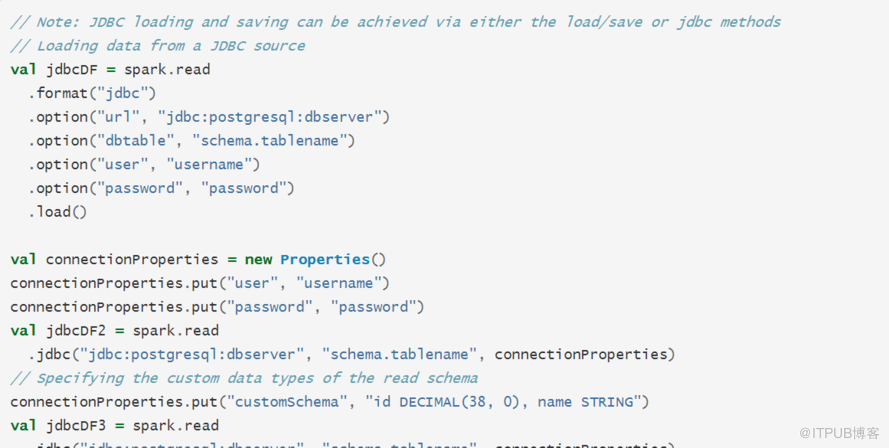
json.vsv,hdfs,hive,jdbc,s3,parquet,es,redis 等 分為兩大類 build-in (內置) , 3th-party(外部) spark.read.load() 默認讀的是parquet文件

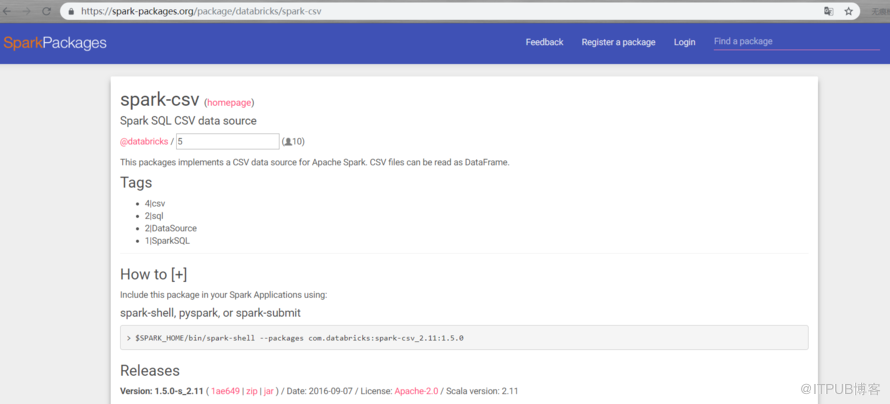
csv為例使用https://spark-packages.org 這個網址 點homepage
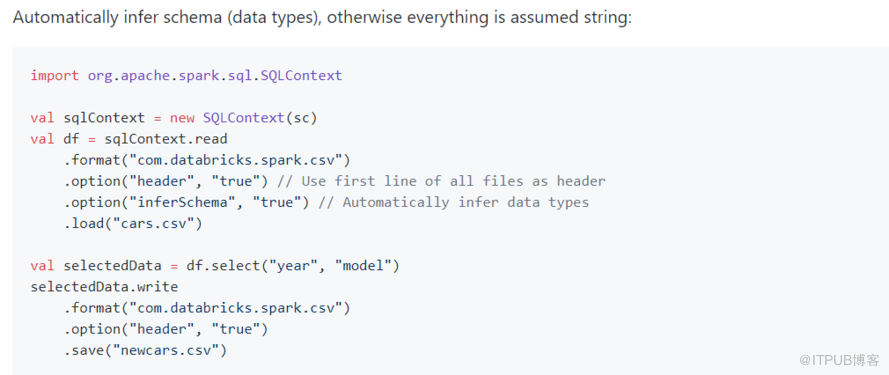
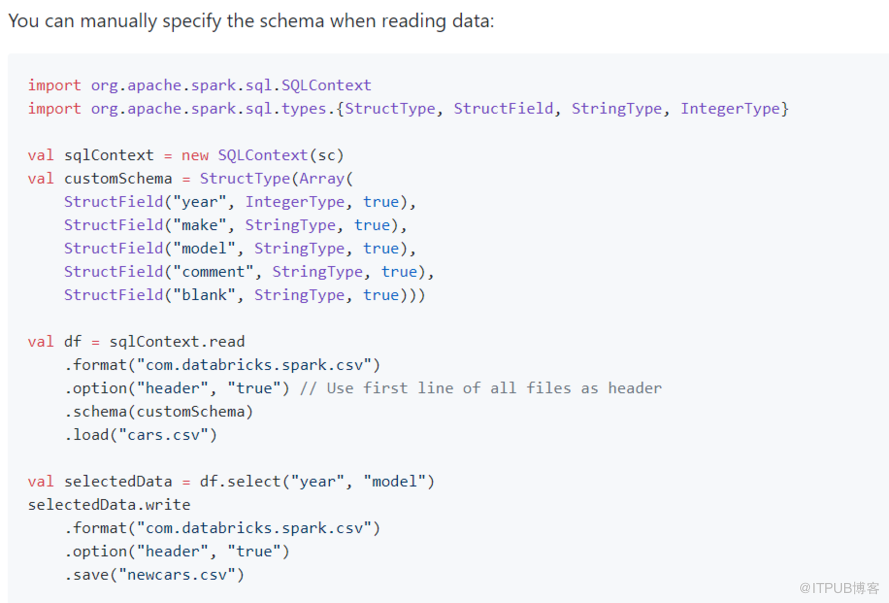
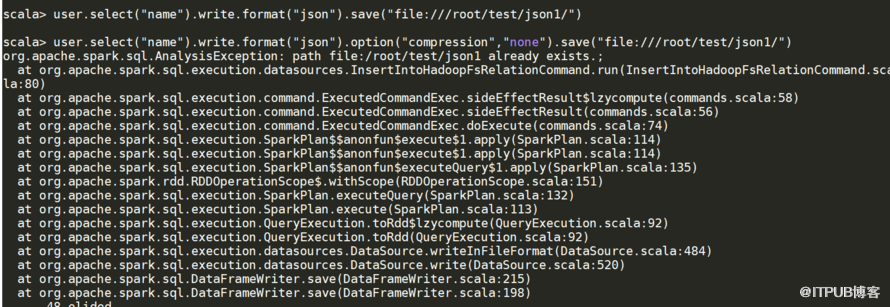
存在拋出異常 目標存在追加,但是重跑一次可能兩份,有弊端(保證不了每次處理都是一樣的) 目標表存在,已經存在的數據被清掉 忽略模式,有了就不會再往里加了

user.select("name").write.format("json").option("compression","none").save("file:///root/test/json1/")
user.select("name").write().format("json").save("/root/test/json1/")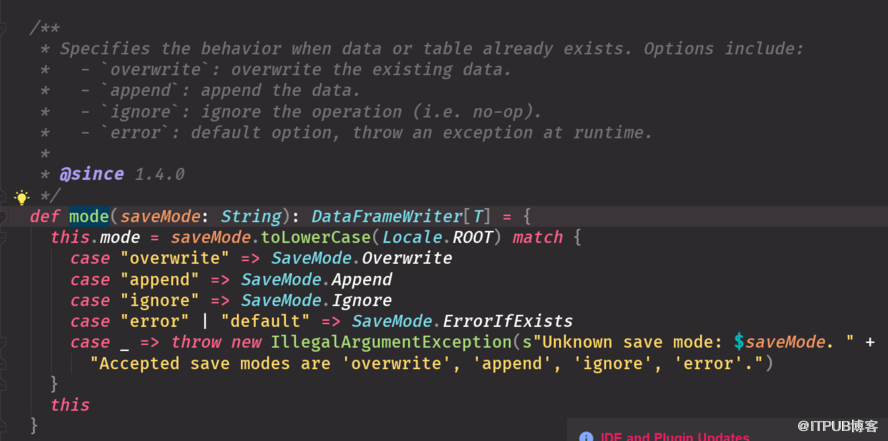
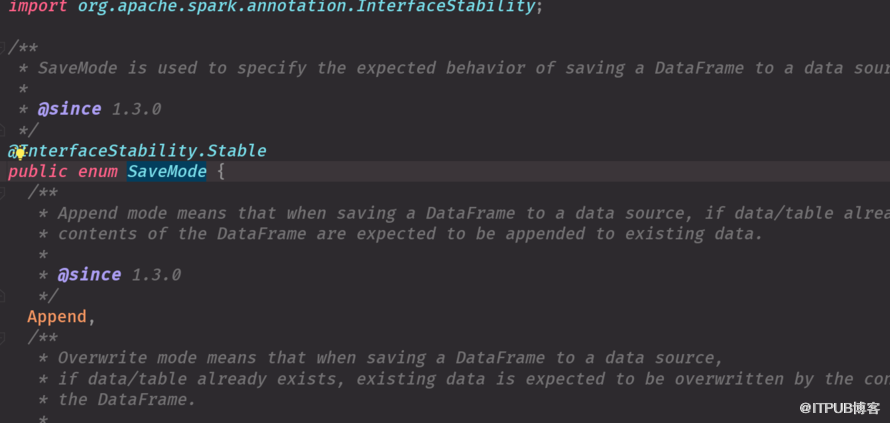
result.write.mode("default")
result.write.mode(SaveMode.ErrorIfExists)

哪個字段分區 最少,最多多少條 幾個分區 一次進去多少條


sparksession中有個table方法直接可以把表轉化為DataFrame


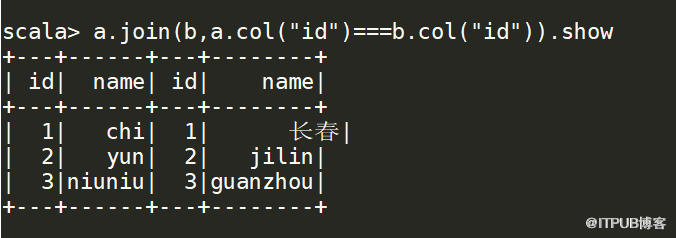
三個等號,否則報錯,注意條件
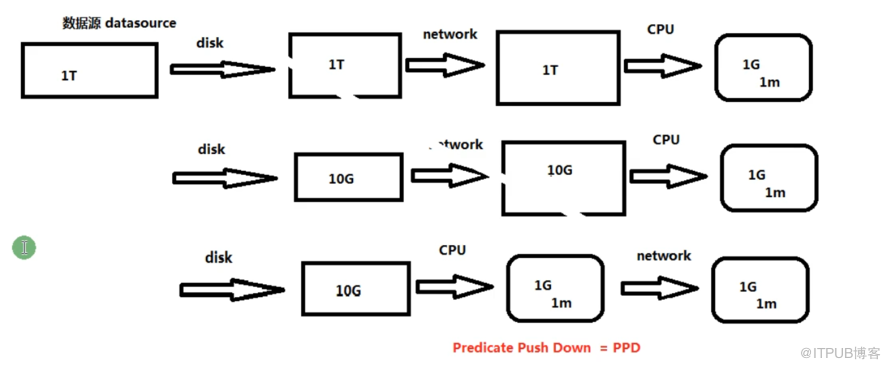
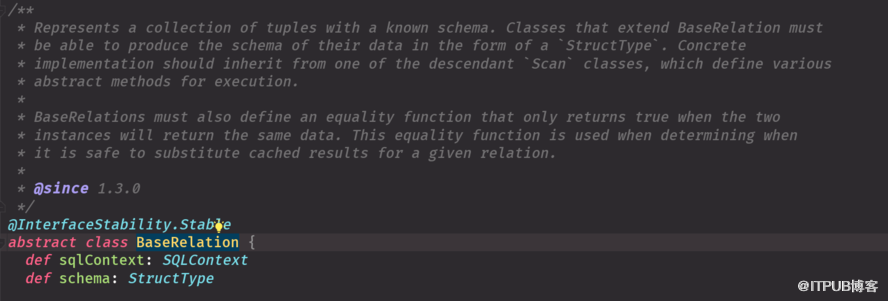
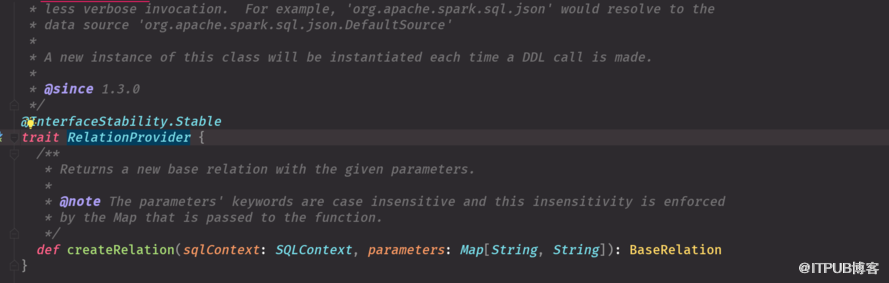
如何更有效的讀取外部數據源 Table sCAN 加載外部數據源數據,定義數據的schema信息Base(抽象類必須有子類) 寫必須實現RelationProvicer

就是上圖第一行什么都不管,讀出什么是什么
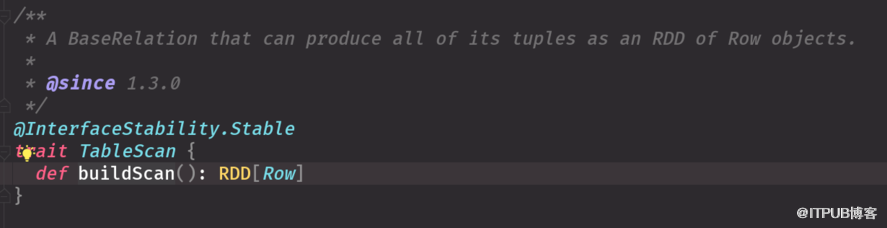
裁剪對應第二個

裁剪過濾對應第三個 兩個圖就參數不同,功能一致


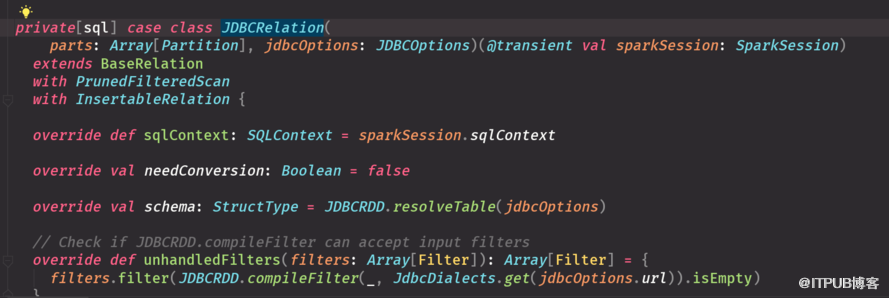
實現這三個接口 一個可以寫schema信息 一個是過濾 一個可以寫出去 帶scan是查,insert 寫, base加載數據源和schema信息
到此,關于“Spark SQL外部數據源的機制以及spark-sql的使用”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





