溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
中臺,我理解是能力的下沉,數據處理能力下沉為加工平臺,數據處理結果下沉為數據資產。那么數據治理能否下沉?可以下沉出什么東西?
——宜信數據中臺負責人 盧山巍

本文來源:宜信數據中臺負責人盧山巍在億歐產業互聯網頻道“數字中臺創新”沙龍的分享實錄
原文首發:億歐
億歐產業互聯網頻道10月24日在上海InnoSpace落地“數字中臺創新”沙龍,活動匯聚了良品鋪子電商技術中心總監羅軼群、愛馳汽車科技信息總監杭瑜峰、宜信數據中臺負責人盧山巍、ThoughtWorks首席咨詢師及極客時間《說透中臺》專欄作者王健、億歐華東負責人繆國成、億歐產業互聯網頻道副主編黃志磊、億歐產業互聯網頻道作者龔晨霞參與分享,就數字中臺話題展開深度討論。
宜信是一家成立于2006年從事普惠金融和財富管理業務的金融科技企業,2018年基于四大開源平臺和中間件等技術,開始研發數據中臺,并在宜信內部推廣使用。目前,宜信的中臺部門一共分為兩大板塊:數據中臺和AI中臺。
以下是盧山巍演講觀點梳理:
1、宜信數據中臺指導思維:統一建設、敏捷開發
2、從開源到中臺,關鍵詞是自助化
3、數據治理,更依賴人治還是自治?
以下是演講速記實錄,經億歐產業互聯網頻道整理,供行業人士參考。
大家下午好,我叫盧山巍,來自宜信。剛才聽羅總高屋建瓴地介紹了中臺的概念和應用,受益匪淺。我的分享會不太一樣:第一,我有一個限定詞是“數據”。羅總的分享對業務中臺、組織中臺、技術中臺都有探討,而我本身是做數據的,所以我只介紹數據中臺。第二,我個人是從純粹技術路線走上來的,分享的內容會比較具體而微 。
我今天分享的話題是《宜信數據中臺建設三部曲》,內容將按照時間發展故事線來展開。分別是:「敏捷使者」— ABD時代(2015年-2018年) ;「自助奇兵」— ADX時代(2018年-2019年); 「自治歸來」— ADG時代(2019年-)。
2015年加入宜信之前,我在上海張江的eBay研發中心工作,當時的主要方向是大數據架構和研發,在付費廣告組做大數據相關的事情。由于我個人的關注點比較下沉,對平臺技術更感興趣,因此總想在技術領域中做出一些框架和平臺類的東西。
2015年宜信找到我,說公司內部沒有數據平臺,希望我能夠去帶領建設數據平臺,于是我加入了宜信。
其實說“公司沒有數據平臺”是不準確的,更準確地說應該是“公司沒有統一的數據平臺”,因為公司很多業務線都有自己所謂的數據平臺,有的做得好一點,有的是純粹的定制化,談不上平臺化,因為公司規模很大,很多是自下而上地建設,不像銀行是自上而下去推動做這個事情。當時也沒有數據中臺這個概念,只是說要做一個好的數據平臺,感覺有點無從下手,很有挑戰,因此著手做了很多公司內部的調研和訪談,用幾張圖來展現當時的現狀。
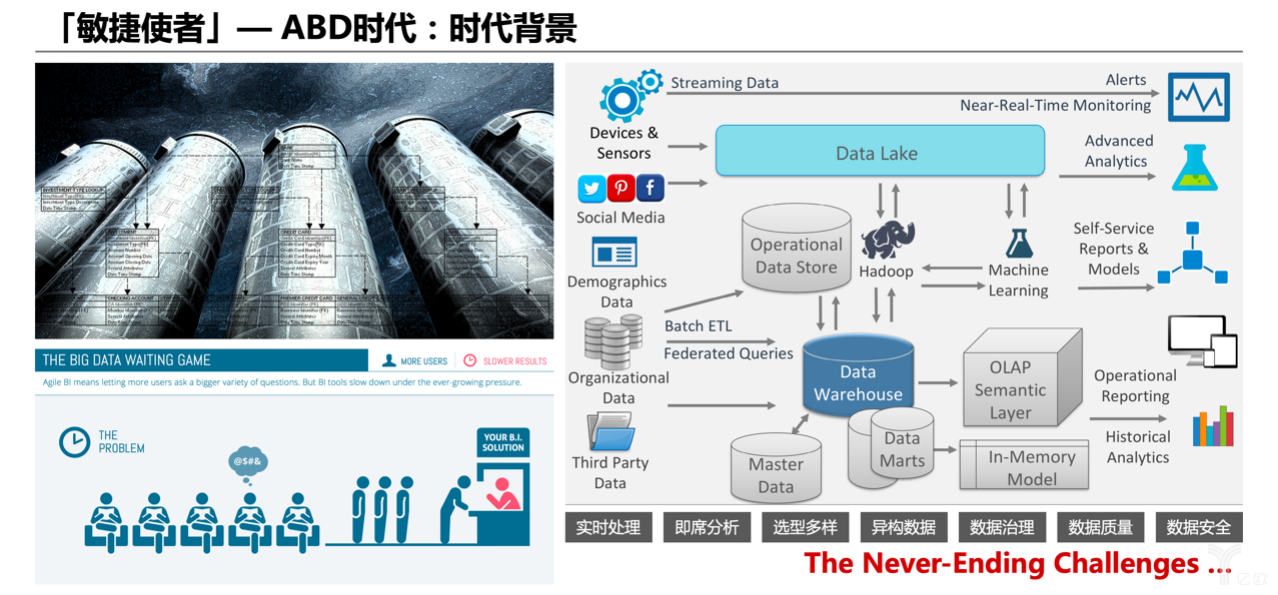
左上角的圖表達的是業務的豎井,從前臺到業務開發端,到數據端,甚至有的數據庫都沒打通。通常好的數據中臺,要有好的業務中臺配合,在業務豎井嚴重的現狀下,想在數據層融合打通是挺難的事。
左下角表達的是在2015年的時候,很多企業都面臨的兩個慢的問題,即:時效慢、實施慢。
一方面,那時比較主流的還是T+1批處理,很多企業沒有完善的流式處理平臺,不像現在有很多成熟的選擇。一般來講都是只能滿足T+1時效的數據需求。
另一方面,因為沒有很好的自助平臺給大家使用,就變成了需求提給特定的BI團隊,BI團隊接了這個需求,需求多了忙不過來,就開始排期,可能要1-2個月甚至以上的時間才能響應和處理這個需求。
有的業務部門比較有實力,擁有不少大數據工程師,使用了很多技術選型,比如MongoDB、ES、HBase、Cassandra、Phoenix、Presto、Spark、Hive、Impala等等各種技術選型都有,沒有統一的技術選型標準。而公司需求又是多樣化的,像上圖右邊的自助查詢、360全景分析、實時處理、多維分析、數據湖等等,使得大數據架構變得越來越復雜和臃腫,越來越難以建設和維護,再加上圖下方的數據治理、數據質量、數據安全等切面課題,當時面臨的就是這樣一個比較復雜的現狀。
在這樣的現狀之下思考整個問題,找尋解決方案。本身我個人是比較倡導敏捷開發思想的,敏捷開發更多是在業務開發方面的實踐經驗,大數據比較笨重,怎么才能讓大象奔跑起來?我認為要用敏捷化思想去建設數據平臺。經過調研和思考,形成了一系列大數據敏捷思想框架、實踐和方法論,更重要的是我們要落地一些中間件去驅動敏捷化實踐。
接下來我們先后自研了四個中間件平臺:DBus、Wormhole、Moonbox、Davinci。既然用了這么多的技術選型,又很難快速將它們統一到一套技術選型,還要能夠去統一收口管控關鍵節點,最好的辦法就是利用中間件思想去適配已有的選型,然后再去簡化整個架構。
下面這個圖就比較技術視角了,展示了整個數據處理的鏈路,從左到右,分為數據源層、數據集成層、數據總線層、數據處理層、數據存儲層、數據服務層和數據應用層 。其中數據源層,天然有各種各樣的選型,這是業務需要;數據存儲層,出于不同目的有了眾多技術選型,這個也沒法很快統一,而且本身也很難找到一個大數據存儲選型,能夠解決所有的存儲問題和計算問題,所以不得不面對多個存儲和計算的整合問題。
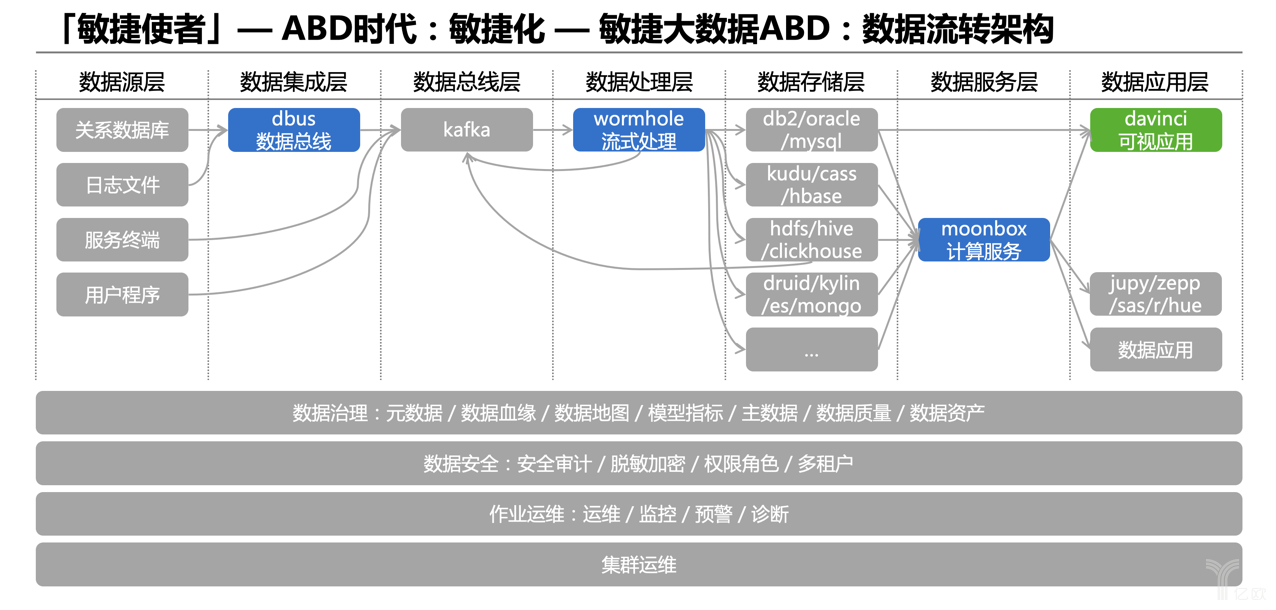
在應用端,需求場景驅動也是很難整合統一的。能夠整合收口的是數據集成層、數據總線層、數據處理層和數據服務層 。整個數據鏈路梳理完之后,是一種“開放+統一”的架構,有些層面是開放包容的,而有些層面是要統一收口管控的。
當然,上圖灰色的切面課題也是應該關注和支持的,因為我們當時的策略是做四個中間件工具DBus、Wormhole、Moonbox、Davinci,因此沒有太關注這些切面課題 。
下面分別介紹這些中間件工具:
這些中間件做出來后帶來了什么效果?比如某條業務線2-3個數據相關人員,對業務非常了解,但沒有大數據技術開發背景,經過一兩周的培訓,就可以自助地、快速地完成各種實時數倉、實時報表、實時應用的端到端項目。這在以前是不可想象的,以前要做一個實時項目,需要有大數據技術開發背景的團隊來支持,而現在哪怕不是IT背景的人,培訓一下就可以做這個事情了,這就是敏捷中間件工具帶來的效率提升和成本減低。
接下來更深入地介紹一下Wormhole。
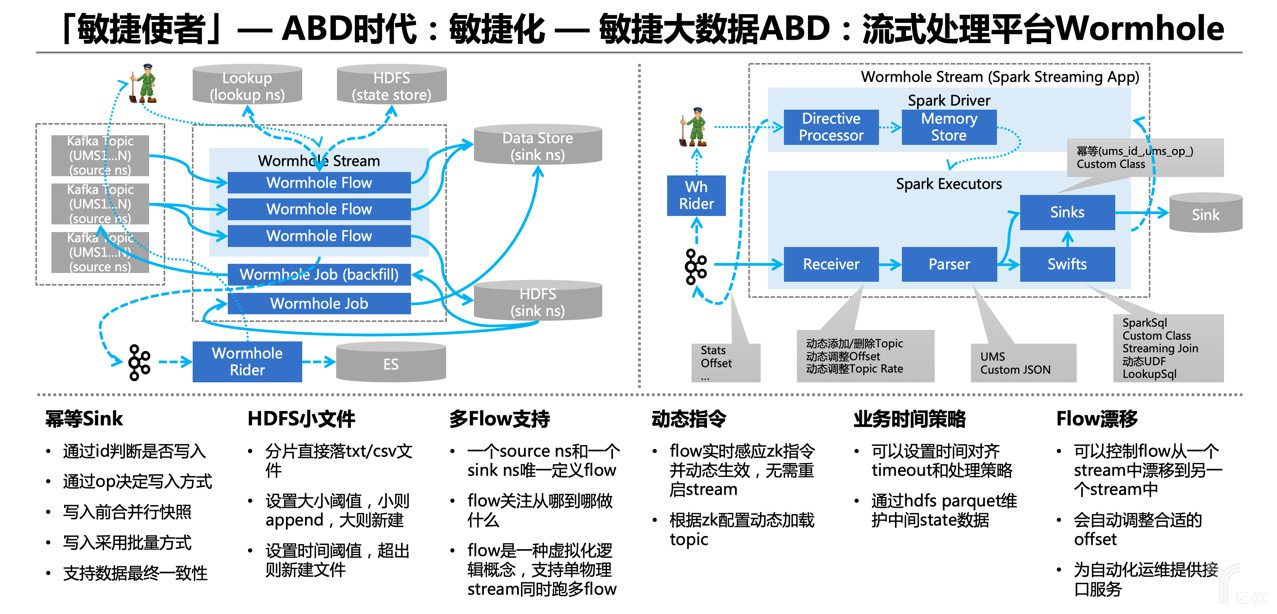
除了上面說到的配置化和SQL化開發流式應用這些好處,從內部技術實現角度來看,很多流式開發要注意的典型問題也都被中間件屏蔽了,這些對用戶來說是透明支持的。
關于開源,我以前就職于eBay,eBay出了幾個Apache頂級開源項目,對我們也是很有影響的,所以我在宜信設計做這四個工具的時候,一開始就是朝著通用化開源工具的方向進行的。不知道在座大家有沒有聽說過這幾個工具,其中Davinci在社區是很火的,很多公司都有在用。
至此,第一階段工作趨于穩定,解決了公司內部很多的問題,開源的幾個工具不光是在公司內部得到很好的應用,在技術社區也賦能了很多其他企業。
第二階段是從去年下半年開始的。2017年我參加了杭州云棲大會,聽過阿里分享的數據中臺,那時“中臺”這個詞還沒有流行起來。到了2018年初,我就在思考,認為數據中臺是當下公司需要做的東西,于是跟CTO建議,他也很支持我們,之后沒幾個月,數據中臺開始流行起來,所以我們也相當于趕上風口了。
ABD時代已經做得不錯了,為什么還要再往上做數據中臺?除了前面提到的業務線多、技術選型多、需求多等這些大家都知道的問題之外,從數據管理層面來看,如數據治理、數據資產等都還沒有涉及,還有很多切面上的課題也沒有過多考慮。之前因為開源也和一些社區、公司做過線下交流,都表示“你們的開源工具做得很好,但是離我們業務需求想要的中間感覺還差一塊”,其實差的就是一個類似數據中臺的東西。
不管數據中臺如何定義,企業需要一個能夠更加直接賦能業務的平臺,因此我們可以在業務需求和中間件工具之間再提升一個層次,構建一個一體化、標準化、一站式的自助平臺。
進入第二個時代,敏捷數據中臺ADX。下圖大三角中的藍色三角,數據平臺引擎,從技術層面來講,我們首先要基于之前的開源工具建設一個好用的自助平臺。但是單單一個好的自助數據平臺,不等同于數據中臺。參考了很多數據中臺文章和定義后,我們總結出數據中臺還應該包括其他三塊。
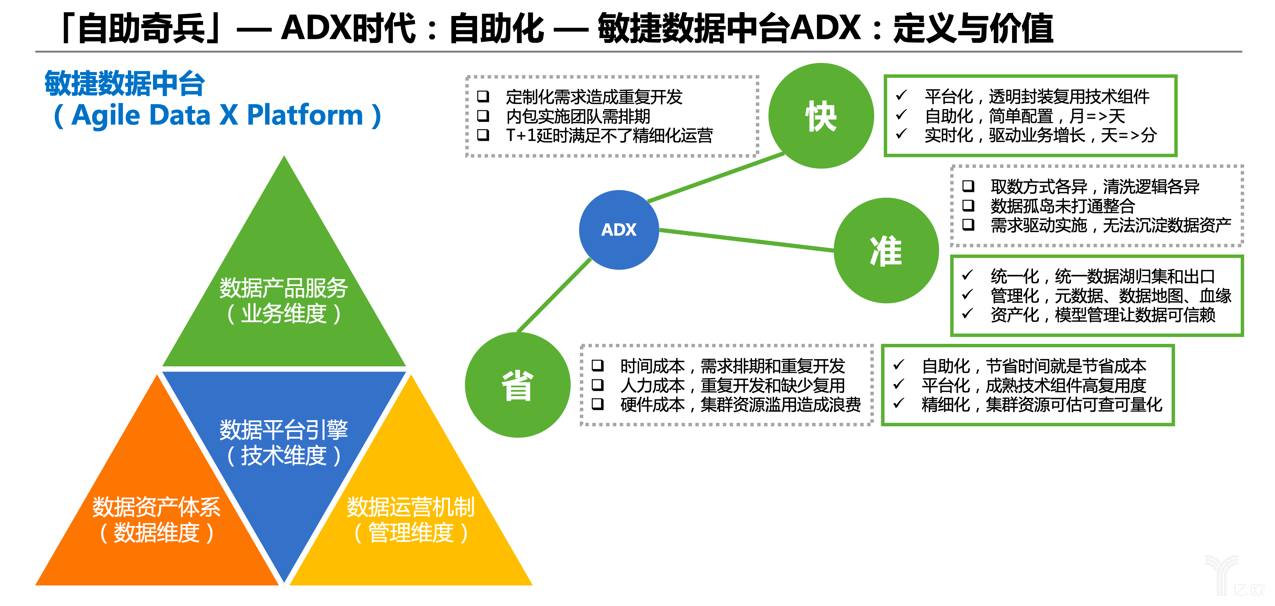
數據中臺的價值體現,在上圖右側也有展示,簡單來說就是“更省更快更準”,或者換個說法是“降本增效提質”,這就是數據中臺的價值本質。
下面這張圖是ADX上一個大致的使用體驗,在自助化數據中臺上,整個數據中臺研發團隊就成為在其背后的IT團隊了。用戶不必和我們直接打交道,在平臺上可以自助地申請資源、申請庫表,自助開發、自助運維、查看監控 、設置報警、診斷問題、上線下線等,我們只要做好平臺設計、研發和運維,這是我們想達到的效果,更加全面徹底的自助化、平民化。
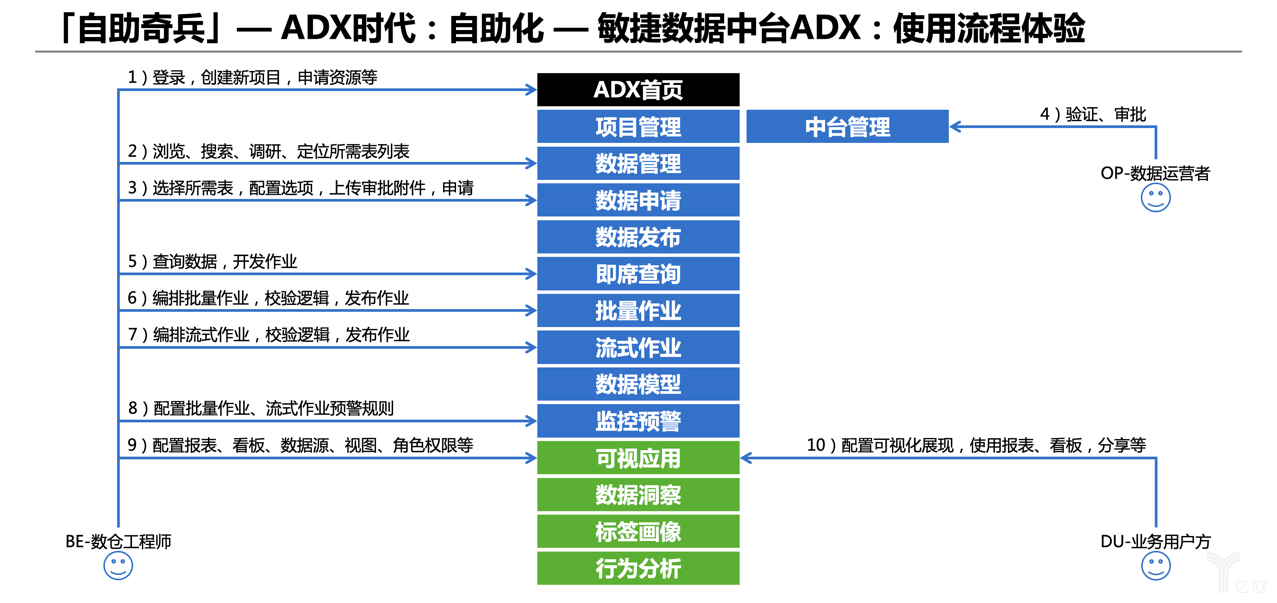
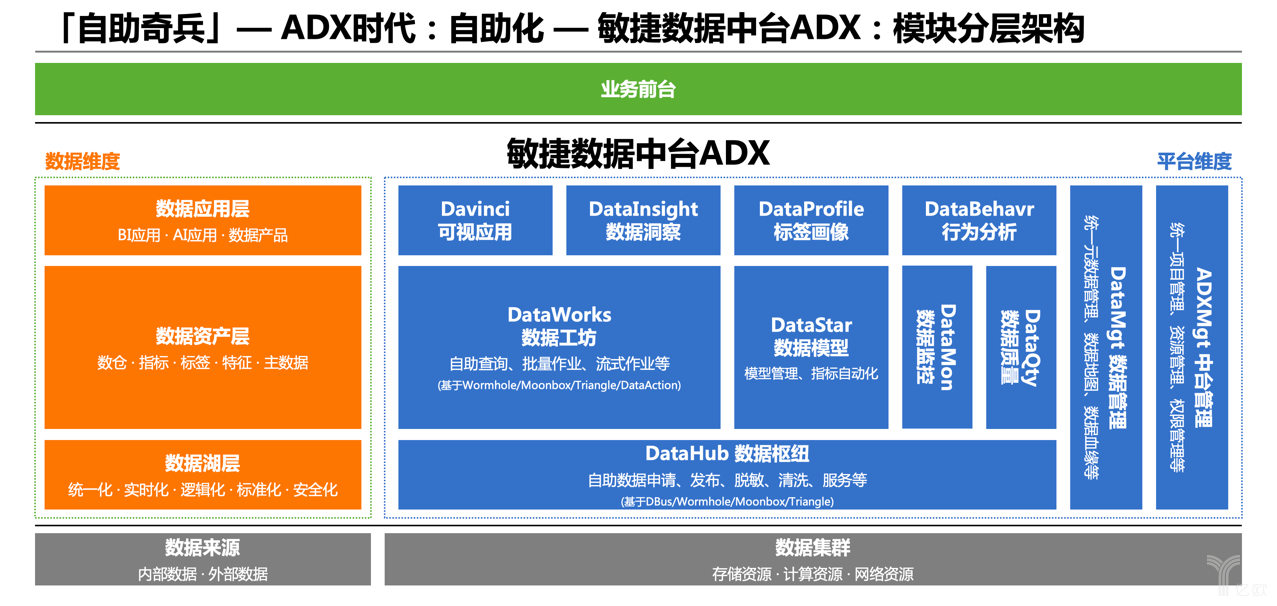
數據中臺是基于模塊化思想建設的,拆分為眾多子模塊,之間關系是分層和聯合的。比如統一的數據歸集、數據加工、數據模型、監控預警等,這些和其他公司思路都差不多;右側的數據管理、中臺管理,都是在解決切面的課題;上面部分是貼近業務使用的模塊。模塊很多這里不一一展開介紹。
值得一提的是,主要核心模塊都不是從零開發,而是基于ABD開源工具整合打通構建的,所以ADX不是推翻了以前的ABD,而是基于ABD更加抽象、更模式化、更面向業務去做上層建筑。
現在處于ADX時代,下圖就有所變化了。DataHub整合了數據集成和數據總線層,以前DBus只支持流式歸集和分發,而DataHub不管是流式還是批量都可以支持。DataWorks之于Wormhole也是如此,相當于ABD功能的擴展外延。
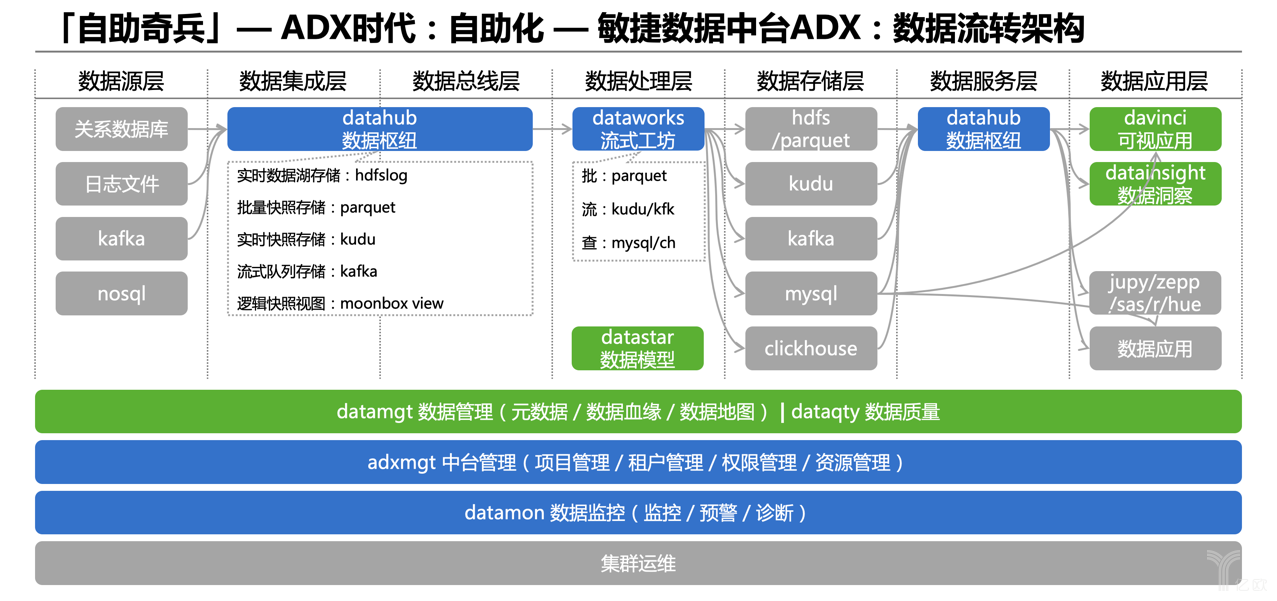
下層的切面課題,也都有相應的模塊對應解決。所以說ADX更加平臺化,不像以前我們做了幾個比較好的開源工具,然后大家自己DIY組合去解決各種場景項目,現在是基于一站式自助平臺,用戶可以在其上完成各種各樣的日常數據處理工作。
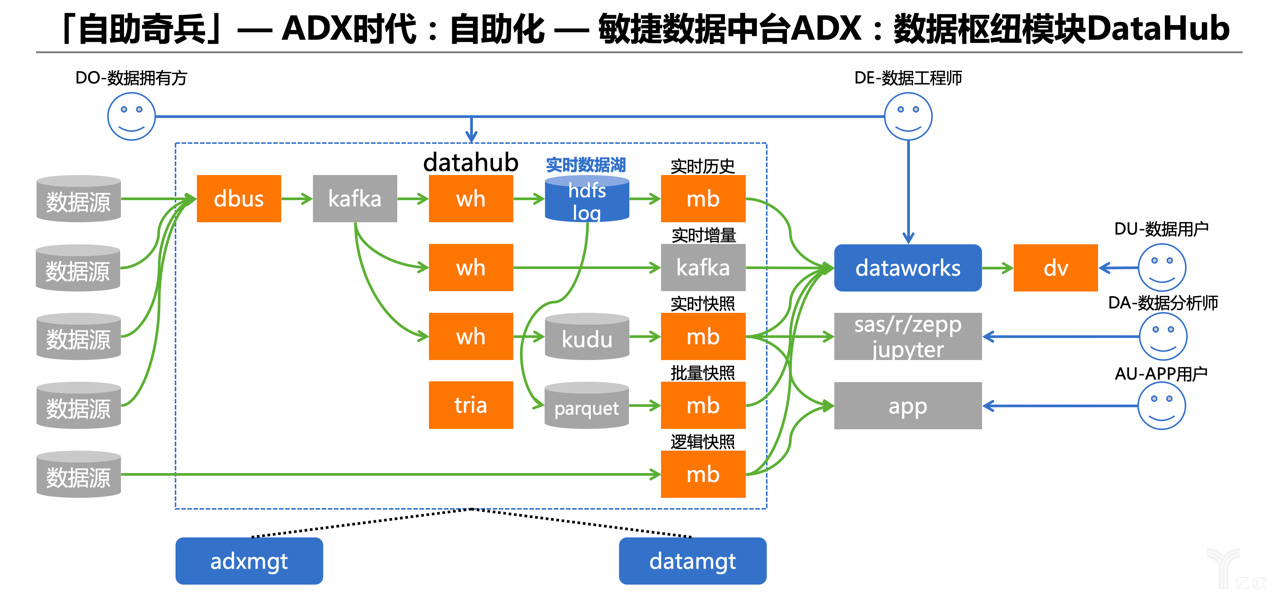
再提一下DataHub,這個模塊當時做的時候沒覺得怎樣,做出來以后大家都覺得真的很方便,很強大。
下圖從DataHub這個模塊外面站在黑盒的角度去看,可以想要什么數據就能得到什么數據:比如我想要某張表的每天T+1快照,它會返給我;我想要這張表的任何一個歷史時刻的精確快照,它也能返給我;我想要這張表的實時流數據,它還能返給我。之所以能做到這點,因為我們把所有表的全量+增量數據都實時落入數據湖,并基于ABD開源工具的整合模式提供各種各樣的所需數據形態,因此從數據層面來看,理論上你想要什么,DataHub都可以提供。我們也了解了社區一些類似的數據整合方案,大部分都是提供單純工具層面的功能,而沒有內置實時數據湖。DataHub包含了一個數據湖,全公司所有的數據都可以實時地統一地歸集和維護進來,所有的數據使用方,想要什么就可以返回什么,這是非常方便和徹底的使用體驗。
第二個時代ADX時代,從開發到上線到現在大規模應用,有一年多的時間,基本能力都已具備。到了第三個時代,我們更關注數據資產能力和數據治理能力建設,沒有數據資產就談不上數據中臺,而數據治理是確保數據資產有效沉淀和賦能業務的重要保障。
數據治理這個課題,在數據鏈路每一層都有對應可能存在的問題,這些問題有些可以在系統層面解決,但更多的是依賴于人去治、依賴于組織去治,且依然不容易得到完美的解決。在這個課題上我們也在思考和摸索中,以下僅限于探討。
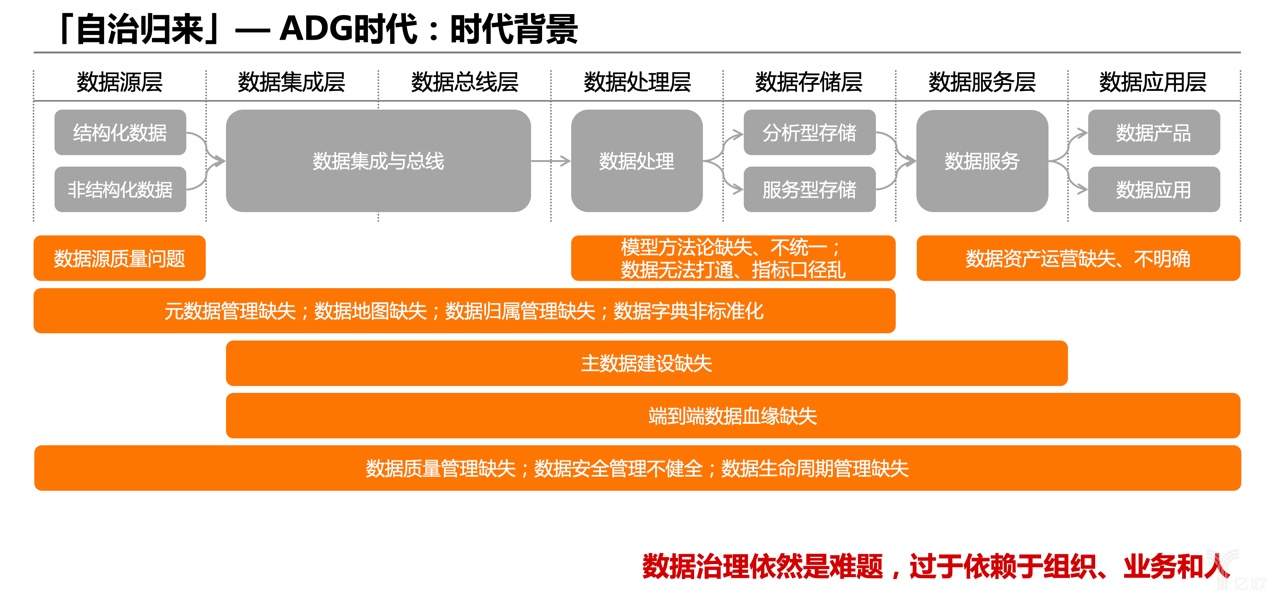
下面是我們的一些思考。“自治”包含兩層含義:自動化治理和自助化治理。
中臺,我理解是能力的下沉,數據處理能力下沉為加工平臺,數據處理結果下沉為數據資產。那么數據治理能否下沉?可以下沉出什么東西?
一類是下沉出一些平臺工具,比如元數據管理、數據質量管理,這些可以做得很通用化、工具化;一類是下沉出一些方法論的系統化,比如阿里的OneData,是一套內部打磨出來的本地化的方法論,落地為一套系統體系,這套體系和方法論不一定適合于每家公司,但我覺得這個思路每家公司都可以借鑒,打磨適合本企業業務體系的方法論,然后將之系統化,更好地約束和規范化企業內的數據治理管理和數據資產建設。

對于“自動化”數據治理,以上兩類依然不能覆蓋所有問題,比如企業有很多遺留系統、遺留流程,無法在短時間內進行大規模的、統一的改造和遷移,那么怎樣去管控它、治理它?這依然是一個難題。RPA是一個比較新興的思路,可以很好地處理遺留系統的問題,這一點和數據治理也許可以找到很好的交叉點,比如可以利用流程編排、自動執行的思想,應對一些遺留系統、遺留環境的數據治理問題。
關于“自助化”數據治理,數據治理和數據處理不太一樣,比如流式處理,這是一個業務能夠直觀感受到的剛需,不管什么業務都會有很強的需求。而數據治理不同,從業務角度來看,數據治理雖然就長期而言可以為整個企業和業務發展帶來堅實的正面影響,但短期內可能會限制業務快速發展的速度,所以業務方可能不會有特別大的動力去主動支持和配合數據治理。
有些企業會自上而下強制推行數據治理的管理和實踐,這是需要管理層有這個意識和決心的。我們公司不太一樣,數據治理需要向業務快速迭代和需求快速變更妥協,無法做到自上而下強推,但又不能不治,因此我們考慮能不能自助化地做數據治理。比如業務線可以建立自己的私有數據資產,如果希望升級成公有數據資產,可以進行申請審核,當然這要可以為業務線帶來好處,要和KPI綁定,這樣一來,數據資產的運營能力可以下放,讓大家主動共同參與到數據治理中來,這種柔性數據治理推廣方式可能會更有效,這也是我們在嘗試的工作。
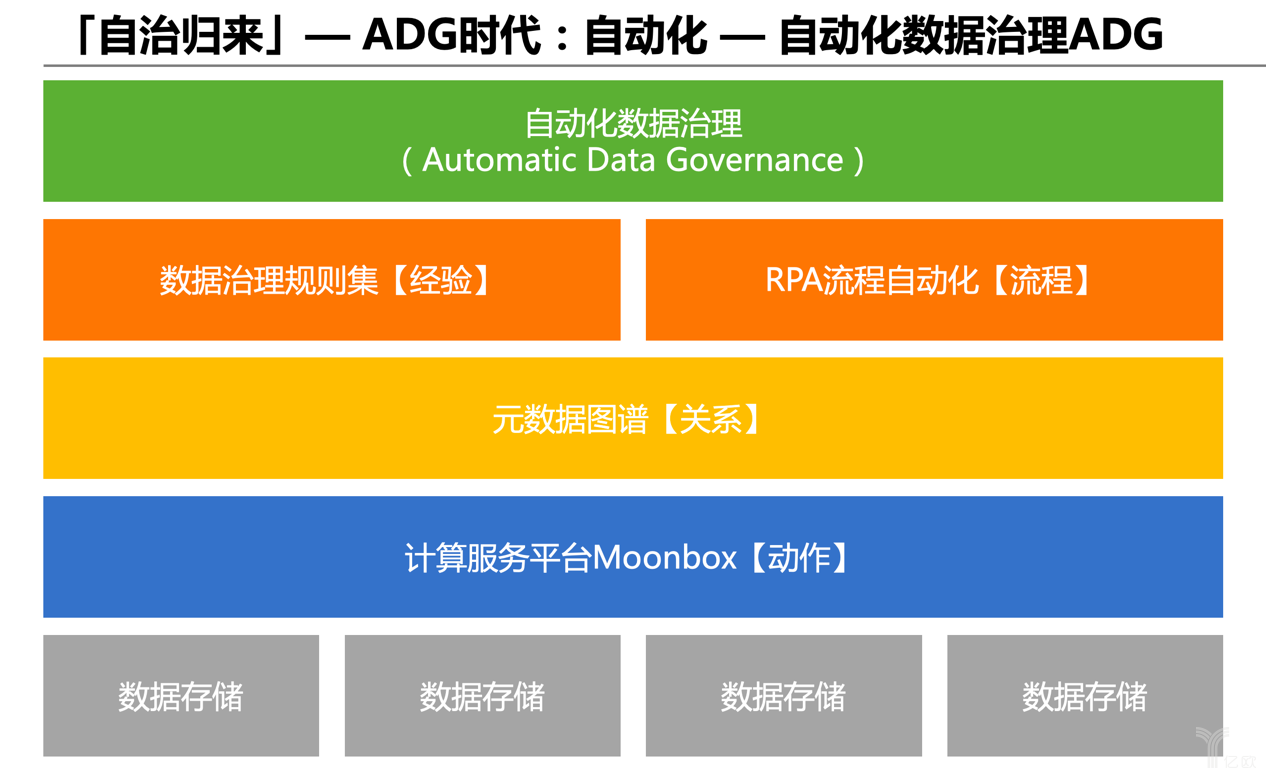
上圖只是一個粗略的概念架構圖,還不是特別成熟,這也是我們現在在思考的一些思路。如果可以把公司所有的元數據歸集起來,形成一個企業級元數據全景圖譜的話,我們就具備了數據知識;因為我們有Moonbox,我們就具備了各種數據操作能力;基于數據知識能力和數據操作能力,就可以根據數據治理的經驗、規則和現狀的流程梳理,進行數據治理動作的可視化編排,最終形成一個自動化數據治理的體系和框架。
數據治理純靠人的話,不確定性因素太大,相對來說我更相信工具,相信通過不斷的抽象、下沉和驗證,可以找到一套更系統化的流程方式和配套工具去做得更好。
以上就是我們四年來數據中臺建設的三個時代走過的歷程,前路依然任重道遠,還需繼續摸索沉淀,希望可以和大家多多交流探討,感謝大家的聆聽!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





