溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
一般K線數據,主要是記錄HLOC(High,Low,Open,Close)四個值,再加上Volume交易量。在做基于K線分析時候,變動百分比也是一個經常考慮數值。這里說下增加變動百分比的屬性。
其實還是很簡單,如果不考慮跳空的話,就是(Close - Open)* 100.0 / Open; 考慮到跳空的話,就是當前K線結束值前取上個K線結束值,再處于上個K線結束值即可。
如果有個close的值隊列的,示例代碼如下
closelist = [100,99,101,103,105,109] def getPrecentlist(inputlist): precentlist = [] for i in range(1,len(inputlist)): precent = (inputlist[i] - inputlist[i-1])*100.0/inputlist[i-1] precentlist.append(precent) return precentlist getPrecentlist(closelist)
返回就是如下百分比隊列。
[-1.0,2.0202020202020203,1.9801980198019802,1.941747572815534,3.8095238095238093]
同理, 在VNPY的K線序列管理工具ArrayManager,可以加入下面代碼。按照屬性返回百分比序列
@property def percent(self): """獲取百分比序列""" arrayold = self.closeArray[0:self.size - 1] arraynew = self.closeArray[1:self.size] return map(lambda (closenew, closeold): (closenew - closeold)*100.0/closeold,zip(arraynew, arrayold))
這里稍微有點玄機,就是利用了lambda把原來function簡化,同時用zip生成一個當前close和前一個close的元祖,來調來計算。
下面使用之前做的DataFrame anaylzer做的一些分析。對于豆粕m1905,從2018年09月1日到現在,10分鐘K的變動百分比。
首先不出所料,precent以0為中軸的高斯分布。
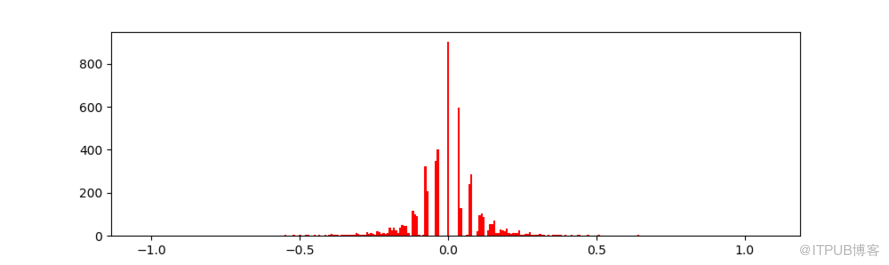
比較出乎意料的是,對于最大和最小的百分之一到百分之五的K線,之后的2,4,6個K線結束時候,過半數是反轉掉頭的。我原來以為如果有個大的K線向上,之后回順著向上,但是看起來,反轉更能多出現。
Precent 大于 0.4312038575295748, 99時候,k線數量為 54,第二根K線結束價格上漲概率為 31.48148148148148%;
Precent 小于于 -0.4345589035350628, 1時候,k線數量為 54, 第二根K線結束價格下跌概率為 38.888888888888886%
Precent 大于 0.4312038575295748, 99時候,第四根K線結束價格上漲概率為 33.333333333333336%
Precent 小于于 -0.4345589035350628, 1時候,第四根K線結束價格下跌概率為 48.148148148148145%
Precent 大于 0.4312038575295748, 99時候,第六根K線結束價格上漲概率為 35.18518518518518%
Precent 小于于 -0.4345589035350628, 1時候,第六根K線結束價格下跌概率為 46.2962962962963%
Precent 大于 0.31567899447202463, 98時候,k線數量為 107,第二根K線結束價格上漲概率為 38.3177570093458%;
Precent 小于于 -0.3369829012686155, 2時候,k線數量為 107, 第二根K線結束價格下跌概率為 36.44859813084112%
Precent 大于 0.31567899447202463, 98時候,第四根K線結束價格上漲概率為 37.38317757009346%
Precent 小于于 -0.3369829012686155, 2時候,第四根K線結束價格下跌概率為 41.12149532710281%
Precent 大于 0.31567899447202463, 98時候,第六根K線結束價格上漲概率為 33.64485981308411%
Precent 小于于 -0.3369829012686155, 2時候,第六根K線結束價格下跌概率為 40.18691588785047%
Precent 大于 0.27096928404930803, 97時候,k線數量為 160,第二根K線結束價格上漲概率為 39.375%;
Precent 小于于 -0.2776041810690485, 3時候,k線數量為 160, 第二根K線結束價格下跌概率為 36.25%
Precent 大于 0.27096928404930803, 97時候,第四根K線結束價格上漲概率為 40.625%
Precent 小于于 -0.2776041810690485, 3時候,第四根K線結束價格下跌概率為 41.875%
Precent 大于 0.27096928404930803, 97時候,第六根K線結束價格上漲概率為 40.0%
Precent 小于于 -0.2776041810690485, 3時候,第六根K線結束價格下跌概率為 42.5%
Precent 大于 0.23543815932988155, 96時候,k線數量為 213,第二根K線結束價格上漲概率為 37.55868544600939%;
Precent 小于于 -0.24673951357067325, 4時候,k線數量為 214, 第二根K線結束價格下跌概率為 38.78504672897196%
Precent 大于 0.23543815932988155, 96時候,第四根K線結束價格上漲概率為 40.375586854460096%
Precent 小于于 -0.24673951357067325, 4時候,第四根K線結束價格下跌概率為 43.925233644859816%
Precent 大于 0.23543815932988155, 96時候,第六根K線結束價格上漲概率為 39.436619718309856%
Precent 小于于 -0.24673951357067325, 4時候,第六根K線結束價格下跌概率為 43.925233644859816%
但是,我嘗試用這個規律做繼續分析收益的時候,發現雖然繼續向上或者向下次數不多,但是往往是巨量的,這樣如果下一個反轉的單子意味著巨虧。這個就是雖然小于50%出現,但是來一次都是高風險呀。
DataFrame 分析代碼如下:
# encoding: UTF-8 from pymongo import MongoClient, ASCENDING import pandas as pd import numpy as np from datetime import datetime import talib import matplotlib.pyplot as plt import scipy.stats as scs class DataAnalyzer(object): def __init__(self, exportpath="C:\Project\\", datformat=['datetime', 'high', 'low', 'open', 'close','volume']): self.mongohost = None self.mongoport = None self.db = None self.collection = None self.df = pd.DataFrame() self.exportpath = exportpath self.datformat = datformat def db2df(self, db, collection, start, end, mongohost="localhost", mongoport=27017, export2csv=False): """讀取MongoDB數據庫行情記錄,輸出到Dataframe中""" self.mongohost = mongohost self.mongoport = mongoport self.db = db self.collection = collection dbClient = MongoClient(self.mongohost, self.mongoport, connectTimeoutMS=500) db = dbClient[self.db] cursor = db[self.collection].find({'datetime':{'$gte':start, '$lt':end}}).sort("datetime",ASCENDING) self.df = pd.DataFrame(list(cursor)) self.df = self.df[self.datformat] self.df = self.df.reset_index(drop=True) path = self.exportpath + self.collection + ".csv" if export2csv == True: self.df.to_csv(path, index=True, header=True) return self.df def csv2df(self, csvpath, dataname="csv_data", export2csv=False): """讀取csv行情數據,輸入到Dataframe中""" csv_df = pd.read_csv(csvpath) self.df = csv_df[self.datformat] self.df["datetime"] = pd.to_datetime(self.df['datetime']) self.df = self.df.reset_index(drop=True) path = self.exportpath + dataname + ".csv" if export2csv == True: self.df.to_csv(path, index=True, header=True) return self.df def df2Barmin(self, inputdf, barmins, crossmin=1, export2csv=False): """輸入分鐘k線dataframe數據,合并多多種數據,例如三分鐘/5分鐘等,如果開始時間是9點1分,crossmin = 0;如果是9點0分,crossmin為1""" dfbarmin = pd.DataFrame() highBarMin = 0 lowBarMin = 0 openBarMin = 0 volumeBarmin = 0 datetime = 0 for i in range(0, len(inputdf) - 1): bar = inputdf.iloc[i, :].to_dict() if openBarMin == 0: openBarmin = bar["open"] if highBarMin == 0: highBarMin = bar["high"] else: highBarMin = max(bar["high"], highBarMin) if lowBarMin == 0: lowBarMin = bar["low"] else: lowBarMin = min(bar["low"], lowBarMin) closeBarMin = bar["close"] datetime = bar["datetime"] volumeBarmin += int(bar["volume"]) # X分鐘已經走完 if not (bar["datetime"].minute + crossmin) % barmins: # 可以用X整除 # 生成上一X分鐘K線的時間戳 barMin = {'datetime': datetime, 'high': highBarMin, 'low': lowBarMin, 'open': openBarmin, 'close': closeBarMin, 'volume' : volumeBarmin} dfbarmin = dfbarmin.append(barMin, ignore_index=True) highBarMin = 0 lowBarMin = 0 openBarMin = 0 volumeBarmin = 0 if export2csv == True: dfbarmin.to_csv(self.exportpath + "bar" + str(barmins)+ str(self.collection) + ".csv", index=True, header=True) return dfbarmin #-------------------------------------------------------------- def Percentage(self, inputdf, export2csv=True): """ 計算 Percentage """ dfPercentage = inputdf for i in range(1, len(inputdf)): if dfPercentage.loc[ i - 1, "close"] == 0.0: percentage = 0 else: percentage = ((dfPercentage.loc[i, "close"] - dfPercentage.loc[i - 1, "close"]) / dfPercentage.loc[ i - 1, "close"]) * 100.0 dfPercentage.loc[i, "Perentage"] = percentage dfPercentage = dfPercentage.fillna(0) dfPercentage = dfPercentage.replace(np.inf, 0) if export2csv == True: dfPercentage.to_csv(self.exportpath + "Percentage_" + str(self.collection) + ".csv", index=True, header=True) return dfPercentage def resultValuate(self,inputdf, nextBar, export2csv=True): summayKey = ["Percentage","TestValues"] dft = pd.DataFrame(columns=summayKey) def addResultBar(self, inputdf, export2csv = False): dfaddResultBar = inputdf ######cci在(100 - 200),(200 -300)后的第2根,第4根,第6根的價格走勢###################### dfaddResultBar["next2BarClose"] = None dfaddResultBar["next4BarClose"] = None dfaddResultBar["next6BarClose"] = None dfaddResultBar["next5BarCloseMakrup"] = None for i in range(1, len(dfaddResultBar) - 6): dfaddResultBar.loc[i, "next2BarPercentage"] = dfaddResultBar.loc[i + 2, "close"] - dfaddResultBar.loc[i, "close"] dfaddResultBar.loc[i, "next4BarPercentage"] = dfaddResultBar.loc[i + 4, "close"] - dfaddResultBar.loc[i, "close"] dfaddResultBar.loc[i, "next6BarPercentage"] = dfaddResultBar.loc[i + 6, "close"] - dfaddResultBar.loc[i, "close"] if dfaddResultBar.loc[i, "close"] > dfaddResultBar.loc[i + 2, "close"]: dfaddResultBar.loc[i, "next2BarClose"] = -1 elif dfaddResultBar.loc[i, "close"] < dfaddResultBar.loc[i + 2, "close"]: dfaddResultBar.loc[i, "next2BarClose"] = 1 if dfaddResultBar.loc[i, "close"] > dfaddResultBar.loc[i + 4, "close"]: dfaddResultBar.loc[i, "next4BarClose"] = -1 elif dfaddResultBar.loc[i, "close"] < dfaddResultBar.loc[i + 4, "close"]: dfaddResultBar.loc[i, "next4BarClose"] = 1 if dfaddResultBar.loc[i, "close"] > dfaddResultBar.loc[i + 6, "close"]: dfaddResultBar.loc[i, "next6BarClose"] = -1 elif dfaddResultBar.loc[i, "close"] < dfaddResultBar.loc[i + 6, "close"]: dfaddResultBar.loc[i, "next6BarClose"] = 1 dfaddResultBar = dfaddResultBar.fillna(0) if export2csv == True: dfaddResultBar.to_csv(self.exportpath + "addResultBar" + str(self.collection) + ".csv", index=True, header=True) return dfaddResultBar def PrecentAnalysis(inputdf): dfPercentage = inputdf #######################################分析分布######################################## plt.figure(figsize=(10,3)) plt.hist(dfPercentage['Perentage'],bins=300,histtype='bar',align='mid',orientation='vertical',color='r') plt.show() for Perentagekey in range(1,5): lpHigh = np.percentile(dfPercentage['Perentage'], 100-Perentagekey) lpLow = np.percentile(dfPercentage['Perentage'], Perentagekey) de_anaylsisH = dfPercentage.loc[(dfPercentage["Perentage"]>= lpHigh)] HCount = de_anaylsisH['Perentage'].count() de_anaylsisL = dfPercentage.loc[(dfPercentage["Perentage"] <= lpLow)] LCount = de_anaylsisL['Perentage'].count() percebtage = de_anaylsisH[de_anaylsisH["next2BarClose"]>0]["next2BarClose"].count()*100.000/HCount de_anaylsisHsum = de_anaylsisH["next2BarPercentage"].sum() de_anaylsisLsum = de_anaylsisL["next2BarPercentage"].sum() print('Precent 大于 %s, %s時候,k線數量為 %s,第二根K線結束價格上漲概率為 %s%%;' %(lpHigh,100-Perentagekey,HCount , percebtage)) print('和值 %s' %(de_anaylsisHsum)) de_anaylsisL = dfPercentage.loc[(dfPercentage["Perentage"]<= lpLow)] percebtage = de_anaylsisL[de_anaylsisL["next2BarClose"]<0]["next2BarClose"].count()*100.000/LCount print('Precent 小于于 %s, %s時候,k線數量為 %s, 第二根K線結束價格下跌概率為 %s%%' %(lpLow,Perentagekey,LCount, percebtage)) print('和值 %s' %(de_anaylsisLsum)) de_anaylsisHsum = de_anaylsisH["next4BarPercentage"].sum() de_anaylsisLsum = de_anaylsisL["next4BarPercentage"].sum() percebtage = de_anaylsisH[de_anaylsisH["next4BarClose"] > 0]["next2BarClose"].count() * 100.000 / HCount print('Precent 大于 %s, %s時候,第四根K線結束價格上漲概率為 %s%%' % (lpHigh, 100 - Perentagekey, percebtage)) # print('和值 %s' % (de_anaylsisHsum)) percebtage = de_anaylsisL[de_anaylsisL["next4BarClose"] < 0]["next2BarClose"].count() * 100.000 / LCount print('Precent 小于于 %s, %s時候,第四根K線結束價格下跌概率為 %s%%' % (lpLow, Perentagekey, percebtage)) print('和值 %s' % (de_anaylsisLsum)) de_anaylsisHsum = de_anaylsisH["next6BarPercentage"].sum() de_anaylsisLsum = de_anaylsisL["next6BarPercentage"].sum() percebtage = de_anaylsisH[de_anaylsisH["next6BarClose"] > 0]["next2BarClose"].count() * 100.000 / HCount print('Precent 大于 %s, %s時候,第六根K線結束價格上漲概率為 %s%%' % (lpHigh, 100 - Perentagekey, percebtage)) print('和值 %s' % (de_anaylsisHsum)) percebtage = de_anaylsisL[de_anaylsisL["next6BarClose"] < 0]["next2BarClose"].count() * 100.000 /LCount print('Precent 小于于 %s, %s時候,第六根K線結束價格下跌概率為 %s%%' % (lpLow, Perentagekey, percebtage)) print('和值 %s' % (de_anaylsisLsum)) if __name__ == '__main__': DA = DataAnalyzer() #數據庫導入 start = datetime.strptime("20180901", '%Y%m%d') end = datetime.today() df = DA.db2df(db="VnTrader_1Min_Db", collection="m1905", start = start, end = end) #csv導入 # df = DA.csv2df("rb1905.csv") df10min = DA.df2Barmin(df,10) dfPercentage = DA.Percentage(df10min) dfPercentage = DA.addResultBar(dfPercentage) PrecentAnalysis(dfPercentage)
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





