溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Python爬蟲用到的工具有哪些”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Python爬蟲用到的工具有哪些”吧!
有必要學爬蟲嗎?
我想,這已經是一個不需要討論的問題了。
爬蟲,“有用”也“有趣”!
這個數據為王的時代,我們要從這個龐大的互聯網中來獲取到我們所需要的數據, 爬蟲是不二之選。無論是過去的“搜索引擎”,還是時下熱門的“數據分析”,它都是獲取數據必不可少的手段。掌握爬蟲后,你看到很多“有趣”的東西!不管你是什么技術方向,掌握了這門技術能讓你在繁榮的互聯網中探索,方便快捷的收集各種各樣的數據或者文件。除了好玩有趣之外,爬蟲是實實在在有非常多的用武之地的,事實上,很多公司在招聘時,對爬蟲也是有要求的。
那么想要學好網絡爬蟲,你需要初步掌握一些基礎知識:
網絡爬蟲中常用的Python基礎知識
HTTP協議通信原理(我們在瀏覽網頁的時候是怎樣的一個過程,他是如何構成的?)
HTML、CSS、JS入門基礎(掌握網頁結構以及從網頁中定位具體的元素)
具備了這些基礎,你就可以開始學習爬蟲了。現在學爬蟲,當然是Python爬蟲,這是當下絕對的主流。
不過很多伙伴還是會有疑惑!
學Python是不是應該先學學爬蟲?
學完基礎知識后我該如何去進階?
學完爬蟲之后有什么用?
在最新的編程語言排行榜上,Pyhton超越Java,成為了榜一,越來越多的程序員選擇Python,甚至有人說,使用Python是“面向未來編程”。關于Python與“爬蟲”的關系,當然是需要先掌握一些Python基礎知識,再學習爬蟲。
但是如果你剛開始學習Python,并想深入下去,那掌握Python基礎后,我推薦你先學習爬蟲,而不是其它的方向,為什么呢?
首先,通過學習爬蟲的確可以很容易的掌握Python基礎學習教程中的不少知識。當然,這可能也是因為Python世界誕生了眾多出色的爬蟲項目,使得Python給大家留下了這種印象,但是爬蟲能鍛煉并提升你的Python技術是毋庸置疑的。
其次,掌握爬蟲技術后,你會看到很多不同風景。在你使用爬蟲爬取數據的過程中,你會感到非常好玩兒,相信我,這種趣味性和好奇心,會讓你對Python有一種天生的喜愛感,為讓你有深入學習Python的動力。
我們使用Python開發爬蟲,Python最強大的地方不在于語言本身而是其龐大而活躍的開發者社區和上億量級的第三方工具包。通過這些工具包我們可以快速的實現一個又一個的功能而不用我們自己去造輪子,掌握的工具包越多,我們在編寫爬蟲程序的時候也就越方便。另外,爬蟲的工作目標是“互聯網”,所以HTTP通信和HTML、CSS、JS這些技能在編寫爬蟲程序的時候都會用的到。
作為開發人員,代碼是最好的老師,在實踐中學習,直接靠代碼說話,是我們程序員的學習方式。只要具備Python基礎,這次專欄足以讓你從完全不懂爬蟲,到有能力在工作中實際開發爬蟲、使用爬蟲。
實際生產中,我們所需要的數據一般也逃不過這樣的頁面結構:
新聞供稿專用爬蟲——爬取RSS訂閱數據
網易新聞爬蟲——泛爬網技術
網易爬蟲優化——大規模數據處理技術
豆瓣讀書爬蟲——測試驅動設計與高級反爬技術實踐
蘑菇街采集——處理深度繼承javascript網站
慢速爬蟲的應用舉例——知乎爬蟲
后續我會帶著大家一一實現這些頁面結構,實現技術各不相同的頁面爬蟲,讓大家通過具體的代碼實踐了解在什么樣的情況下可以采用什么樣的技術來處理,遇到了反爬措施我們該如何去解決,通過具體應用建立起對爬蟲的具體認知在了解背后的技術理論。
說到這 可能有的伙伴要問了:編寫完爬蟲程序之后呢?不要著急,在編寫完爬蟲程序之后我還會帶著大家將我們的爬蟲程序部署,真正的讓我們的爬蟲“大展宏圖”。
掌握Scrapy框架開發
學會泛爬技術應對海量數據
優化你的增量式爬蟲
通過分布式爬蟲解決大規模并發的爬蟲項目
運用Docker容器技術進行爬蟲部署
互聯網上到底藏著多少數據信息呢?它又能為我們的生活和工作帶來什么不同的感受呢?保持著你的好奇心,從現在開始,讓我們一起學爬蟲,一起玩爬蟲,一起用爬蟲吧!
下面先跟大家講一下Python爬蟲我們要用到的爬蟲工具!這也是學爬蟲的第一步!
爬蟲第一步做什么?
沒錯,一定是目標站點分析!
1.Chrome
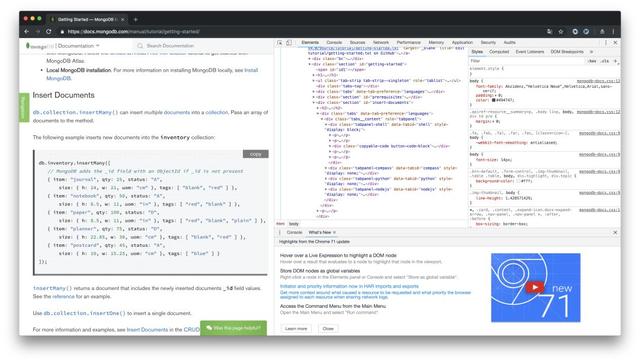
Chrome是爬蟲最基礎的工具,一般我們用它做初始的爬取分析,頁面邏輯跳轉、簡單的js調試、網絡請求的步驟等。我們初期的大部分工作都在它上面完成,打個不恰當的比喻,不用Chrome,我們就要從現代倒退到幾百年前的古代!
同類工具: Firefox、Safari、Opera
2.Charles

Charles與Chrome對應,只不過它是用來做App端的網絡分析,相較于網頁端,App端的網絡分析較為簡單,重點放在分析各個網絡請求的參數。當然,如果對方在服務端做了參數加密,那就涉及逆向工程方面的知識,那一塊又是一大籮筐的工具,這里暫且不談
同類工具:Fiddler、Wireshark、Anyproxy
接下來,分析站點的反爬蟲
3.cUrl
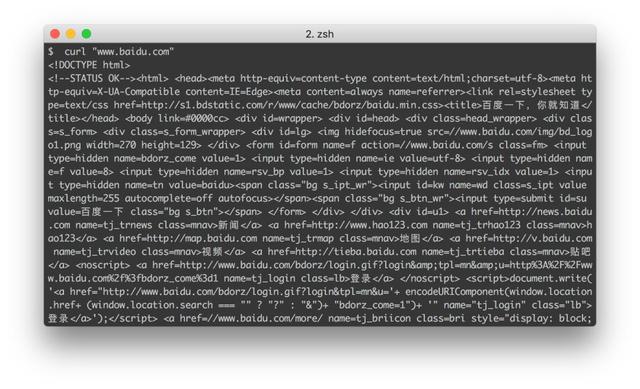
維基百科這樣介紹它
cURL是一個利用URL語法在命令行下工作的文件傳輸工具,1997年首次發行。它支持文件上傳和下載,所以是綜合傳輸工具,但按傳統,習慣稱cURL為下載工具。cURL還包含了用于程序開發的libcurl。
在做爬蟲分析時,我們經常要模擬一下其中的請求,這個時候如果去寫一段代碼,未免太小題大做了,直接通過Chrome拷貝一個cURL,在命令行中跑一下看看結果即可,步驟如下
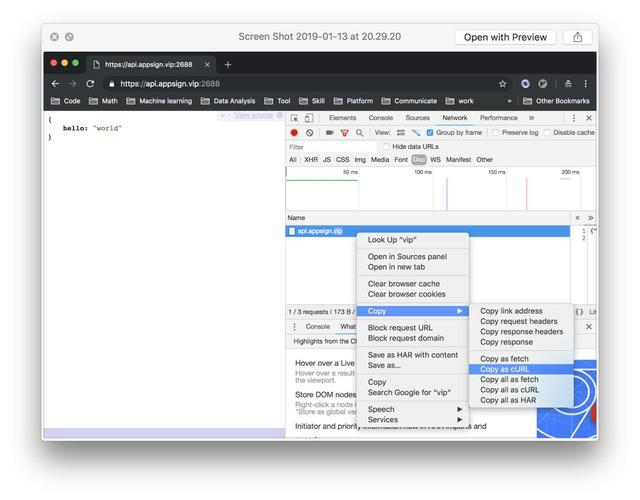

4.Postman

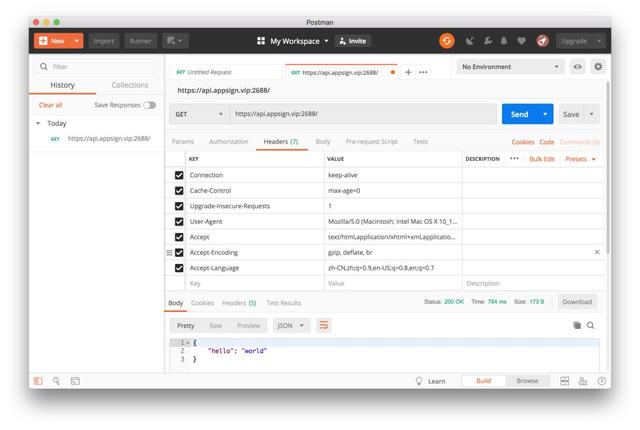
當然,大部分網站不是你拷貝一下cURL鏈接,改改其中參數就可以拿到數據的,接下來我們做更深層次的分析,就需要用到Postman“大殺器”了。為什么是“大殺器”呢?因為它著實強大。配合cURL,我們可以將請求的內容直接移植過來,然后對其中的請求進行改造,勾選即可選擇我們想要的內容參數,非常優雅
5.Online JavaScript Beautifier
用了以上的工具,你基本可以解決大部分網站了,算是一個合格的初級爬蟲工程師了。這個時候,我們想要進階就需要面對更復雜的網站爬蟲了,這個階段,你不僅要會后端的知識,還需要了解一些前端的知識,因為很多網站的反爬措施是放在前端的。你需要提取對方站點的js信息,并需要理解和逆向回去,原生的js代碼一般不易于閱讀,這時,就要它來幫你格式化吧
6.EditThisCookie
爬蟲和反爬蟲就是一場沒有硝煙的拉鋸戰,你永遠不知道對方會給你埋哪些坑,比如對Cookies動手腳。這個時候你就需要它來輔助你分析,通過Chrome安裝EditThisCookie插件后,我們可以通過點擊右上角小圖標,再對Cookies里的信息進行增刪改查操作,大大提高對Cookies信息的模擬
接著,設計爬蟲的架構
7.Sketch
當我們已經確定能爬取之后,我們不應該著急動手寫爬蟲。而是應該著手設計爬蟲的結構。按照業務的需求,我們可以做一下簡單的爬取分析,這有助于我們之后開發的效率,所謂磨刀不誤砍柴工就是這個道理。比如可以考慮下,是搜索爬取還是遍歷爬取?采用BFS還是DFS?并發的請求數大概多少?考慮一下這些問題后,我們可以通過Sketch來畫一下簡單的架構圖
同類工具:Illustrator、 Photoshop
終于開始了愉快的爬蟲開發之旅
終于要進行開發了,經過上面的這些步驟,我們到這一步,已經是萬事俱備只欠東風了。這個時候,我們僅僅只需要做code和數據提取即可
8.XPath Helper
在提取網頁數據時,我們一般需要使用xpath語法進行頁面數據信息提取,一般地,但我們只能寫完語法,發送請求給對方網頁,然后打印出來,才知道我們提取的數據是否正確,這樣一方面會發起很多不必要的請求,另外一方面,也浪費了我們的時間。這個就可以用到XPath Helper了,通過Chrome安裝插件后,我們只需要點擊它在對應的xpath中寫入語法,然后便可以很直觀地在右邊看到我們的結果,效率up+10086
9.JSONView

我們有時候提取的數據是Json格式的,因為它簡單易用,越來越多的網站傾向于用Json格式進行數據傳輸。這個時候,我們安裝這個插件后,就可以很方便的來查看Json數據啦
10.JSON Editor Online

JSONView是直接在網頁端返回的數據結果是Json,但多數時候我們請求的結果,都是前端渲染后的HTML網頁數據,我們發起請求后得到的json數據,在終端(即terminal)中無法很好的展現怎么辦?借助JSON Editor Online就可以幫你很好的格式化數據啦,一秒格式化,并且實現了貼心得折疊Json數據功能
既然看到這里了,相信你們也是很好學的小伙伴了,這里跟你們一個彩蛋工具。
0.ScreenFloat
它是干嘛的呢?其實是一個屏幕懸浮工具,其實別小看了它,它特別重要,當我們需要分析參數時,經常需要在幾個界面來回切換,這個時候有一些參數,我們需要比較他們的差異,這個時候,你就可以通過它先懸浮著,不用在幾個界面中來切換。非常方便。再送你一個隱藏玩法,比如上圖這樣。
到此,相信大家對“Python爬蟲用到的工具有哪些”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





