溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關Scrapy爬蟲項目運行和調試的小技巧是怎樣的,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
關于Scrapy爬蟲項目運行和調試的小技巧
設置網站robots.txt規則為False
一般的,我們在運用Scrapy框架抓取數據之前,需要提前到settings.py文件中,將“ROBOTSTXT_OBEY = True”改為ROBOTSTXT_OBEY = False。
在未改動之后settings.py文件中默認爬蟲是遵守網站的robots.txt規則的,如下圖所示。
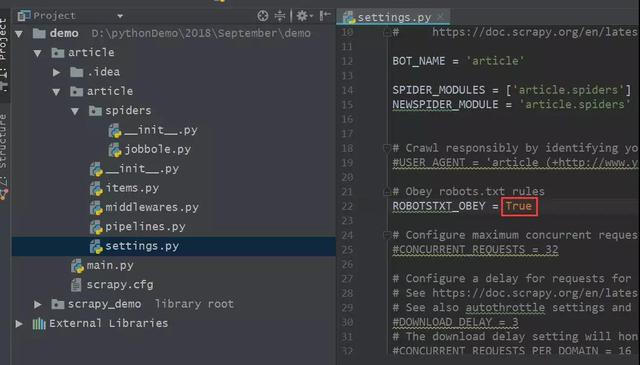
如果遵守robots.txt規則的話,那么爬取的結果會自動過濾掉很多我們想要的目標信息,因此有必要將該參數設置為False,如下圖所示。
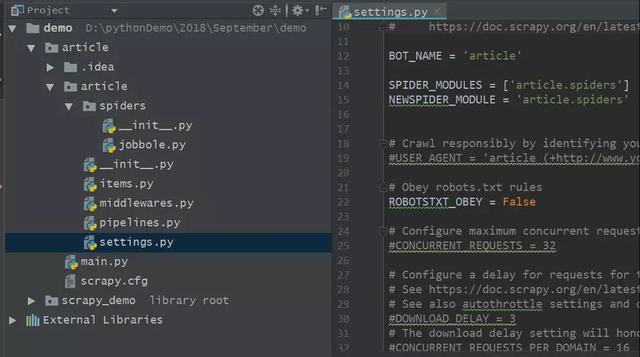
設置好robots.txt規則之后,我們便可以抓到更多網頁的信息。
利用Scrapy shell進行調試
通常我們要運行Scrapy爬蟲程序的時候會在命令行中輸入“scrapy crawl crawler_name”,細心的小伙伴應該知道上篇文章中創建的main.py文件也是可以提高調試效率的,不過這兩種方法都是需要從頭到尾運行Scrapy爬蟲項目,每次都需要請求一次URL,效率十分低。運行過Scrapy爬蟲項目的小伙伴都知道Scrapy運行的時候相對較慢,有時候因為網速不穩定,根部就無法動彈。針對每次都需要運行Scrapy爬蟲的問題,這里介紹Scrapy shell調試方法給大家,可以事半功倍噢。
Scrapy給我們提供了一種shell模式,讓我們可以在shell腳本之下獲取整個URL對應的網頁源碼。在命令行中進行運行,其語法命令是“scrapy shell URL”,URL是指你需要抓取的網頁網址或者鏈接,如下圖所示。
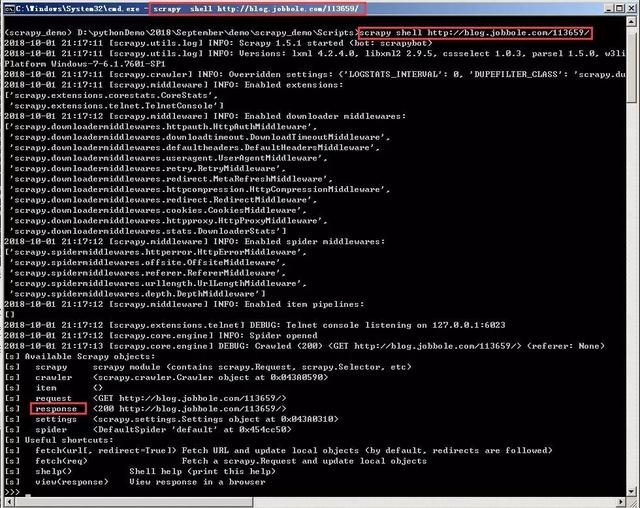
該命令代表的意思是對該URL進行調試,當命令執行之后,我們就已經獲取到了該URL所對應的網頁內容,之后我們就可以在該shell下進行調試,再也不用每次都執行Scrapy爬蟲程序,發起URL請求了。
通過shell腳本這種方式可以極大的提高調試的效率,具體的調試方法同爬蟲主體文件中的表達式語法一致。舉個栗子,如下圖所示。
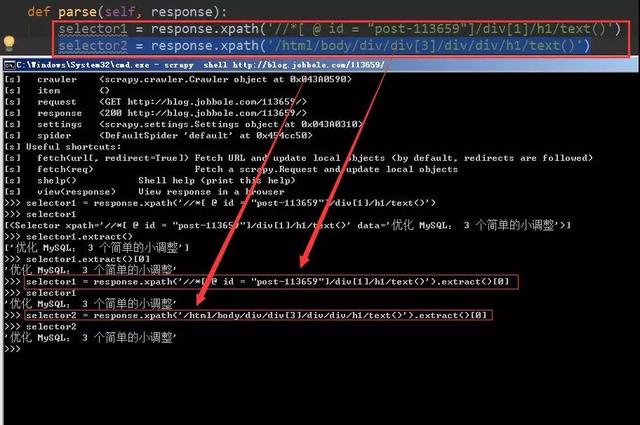
將兩個Xpath表達式所對應的選擇器放到scrapy shell調試的腳本下,我們可以很清楚的看到提取的目標信息,而且省去了每次運行Scrapy爬蟲程序的重復步驟,提高了開發效率。這種方式在Scrapy爬蟲過程中十分常用,而且也十分的實用,希望小伙伴們都可以掌握,并且積極主動的為自己所用。
看完上述內容,你們對Scrapy爬蟲項目運行和調試的小技巧是怎樣的有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





