溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“怎么編寫Python腳本”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
Streamlit是第一個專門針對機器學習和數據科學團隊的應用開發框架,它是開發自定義機器學習工具的最快的方法,你可以認為它的目標是取代Flask在機器學習項目中的地位,可以幫助機器學習工程師快速開發用戶交互工具。
1、Hello world
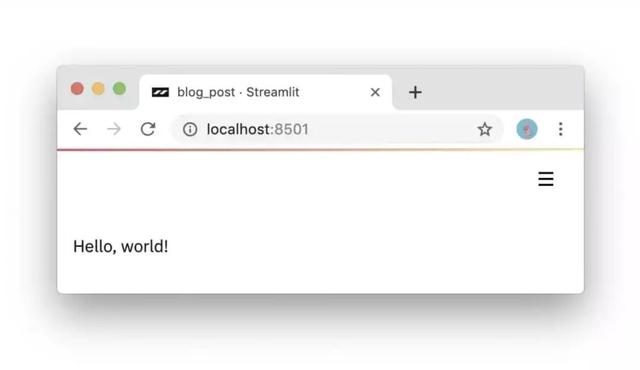
Streamlit應用就是Python腳本,沒有隱含的狀態,你可以使用函數調用重構。只要你會寫Python腳本,你就會開發Streamlit應用。例如,下面的代碼在網頁中輸出 Hello,world!:
import streamlit as st
st.write('Hello, world!')結果如下:
2、使用UI組件
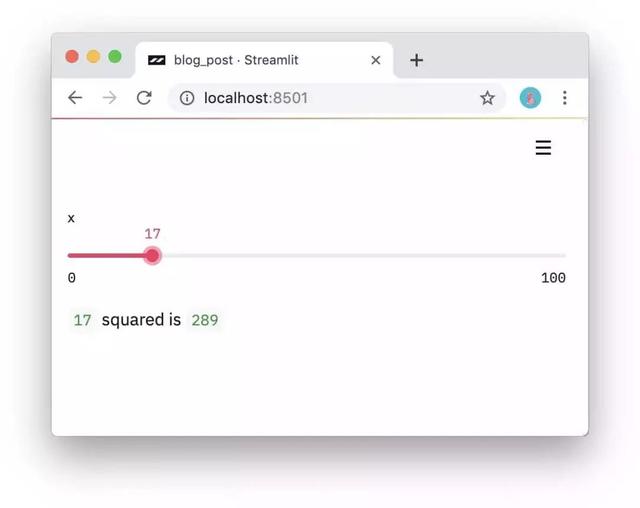
Streamlit將組件視為變量,在Streamlit中沒有回調,每一個交互都是 簡單地返回,從而確保代碼干凈:
import streamlit as st
x = st.slider('x')
st.write(x, 'squared is', x * x)結果如下:
3、數據重用和計算
如果你要下載大量數據或者運行復雜的計算該怎么實現?關鍵在于安全地重用數據。Streamlit引入了緩存原語可以讓Steamlit應用 安全、輕松的重用信息。例如,下面的代碼只需要從Udacity的自動 駕駛車項目下載一次數據,從而得到一個簡單、快速的應用:
import streamlit as st
import pandas as pd
# Reuse this data across runs!
read_and_cache_csv = st.cache(pd.read_csv)
BUCKET = "https://streamlit-self-driving.s3-us-west-2.amazonaws.com/"
data = read_and_cache_csv(BUCKET + "labels.csv.gz", nrows=1000)
desired_label = st.selectbox('Filter to:', ['car', 'truck'])
st.write(data[data.label == desired_label])結果如下:

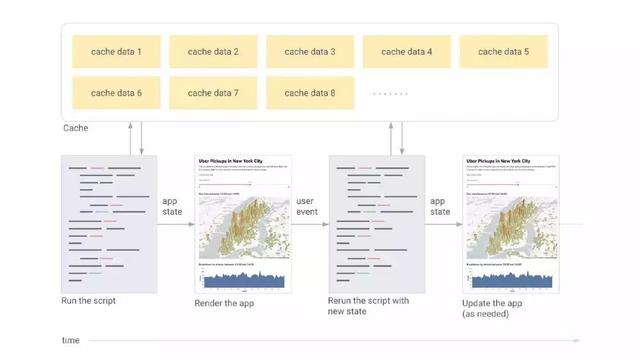
簡而言之,Streamlit的工作方式如下:
對于用戶的每一次交互,整個腳本從頭到尾執行一遍
Streamlit基于UI組件的狀態給變量賦值
緩存讓Streamlit可以避免重復請求數據或重復計算
或者參考下圖:
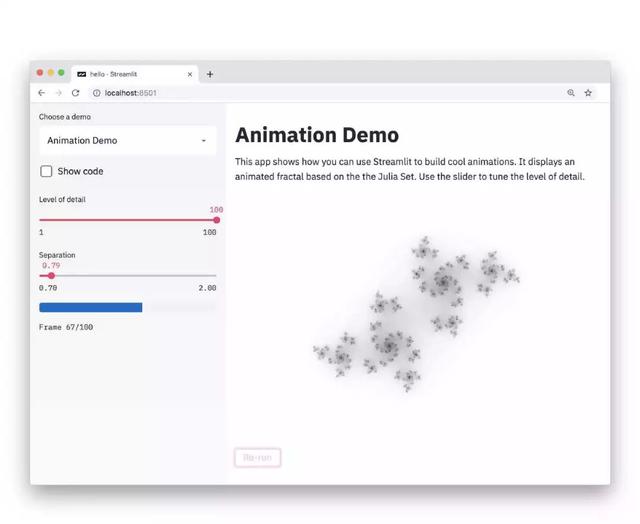
如果上面的內容還沒有說清楚,你可以直接上手嘗試Streamlit!
$ pip install --upgrade streamlit
$ streamlit hello
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://10.0.1.29:8501
這會自動打開本地的web瀏覽器并訪問Streamlit應用:
4、實例:自動駕駛數據集工具
下面的Streamlit應用讓你可以在整個Udacity自動駕駛車輛照片數據集中進行語義化搜索,可視化人工標注,并且可以實時運行一個YOLO 目標檢測器:
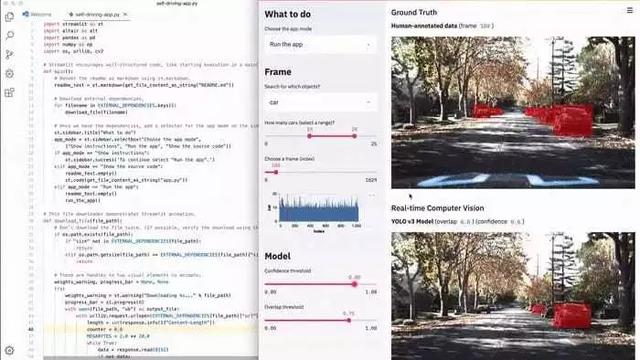
、整個應用只有300行Python代碼,絕大多數是機器學習代碼。實際上 其中只有23個Streamlit調用。你可以嘗試自己運行:
$ pip install --upgrade streamlit opencv-python $ streamlit run https://raw.githubusercontent.com/streamlit/demo-self-driving/master/app.py
“怎么編寫Python腳本”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





