溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇“LevelDB數據文件SSTable結構是怎樣的”文章的知識點大部分人都不太理解,所以小編給大家總結了以下內容,內容詳細,步驟清晰,具有一定的借鑒價值,希望大家閱讀完這篇文章能有所收獲,下面我們一起來看看這篇“LevelDB數據文件SSTable結構是怎樣的”文章吧。
SSTable 文件的內容分為 5 個部分,Footer、IndexBlock、MetaIndexBlock、FilterBlock 和 DataBlock。其中存儲了鍵值對內容的就是 DataBlock,存儲了布隆過濾器二進制數據的是 FilterBlock,DataBlock 有多個,FilterBlock 也可以有多個,但是通常最多只有 1 個,之所以設計成多個是考慮到擴展性,也許未來會支持其它類型的過濾器。另外 3 個部分為管理塊,其中 IndexBlock 記錄了 DataBlock 相關的元信息,MetaIndexBlock 記錄了過濾器相關的元信息,而 Footer 則指出 IndexBlock 和 MetaIndexBlock 在文件中的偏移量信息,它是元信息的元信息,它位于 sstable 文件的尾部。下面我們至頂向下挨個分析每個結構
它的占用空間很小只有 48 字節,內部只存了幾個字段。下面我們用偽代碼來描述一下它的結構
// 定義了數據塊的位置和大小
struct BlockHandler {
varint offset;
varint size;
}
struct Footer {
BlockHandler metaIndexHandler; // MetaIndexBlock的文件偏移量和長度
BlockHandler indexHandler; // IndexBlock的文件偏移量和長度
byte[n] padding; // 內存墊片
int32 magicHighBits; // 魔數后32位
int32 magicLowBits; // 魔數前32位
}
Footer 結構的中間部分增加了內存墊片,其作用就是將 Footer 的空間撐到 48 字節。結構的尾部還有一個 64位的魔術數字 0xdb4775248b80fb57,如果文件尾部的 8 字節不是這個數字說明文件已經損壞。這個魔術數字的來源很有意思,它是下面返回的字符串的前64bit。
$ echo http://code.google.com/p/leveldb/ | sha1sum
db4775248b80fb57d0ce0768d85bcee39c230b61
IndexBlock 和 MetaIndexBlock 都只有唯一的一個,所以分別使用一個 BlockHandler 結構來存儲偏移量和長度。
除了 Footer 之外,其它部分都是 Block 結構,在名稱上也都是以 Block 結尾。所謂的 Block 結構是指除了內部的有效數據外,還會有額外的壓縮類型字段和校驗碼字段。
struct Block {
byte[] data;
int8 compressType;
int32 crcValue;
}
每一個 Block 尾部都會有壓縮類型和循環冗余校驗碼(crcValue),這會要占去 5 字節。如果是壓縮類型,塊內的數據 data 會被壓縮。校驗碼會針對壓縮和的數據和壓縮類型字段一起計算循環冗余校驗和。壓縮算法默認是 snappy ,校驗算法是 crc32。
crcValue = crc32(data, compressType)
在下面介紹的所有 Block 結構中,我們不再提及壓縮和校驗碼。
DataBlock 的大小默認是 4K 字節(壓縮前),里面存儲了一系列鍵值對。前面提到 sst 文件里面的 Key 是有序的,這意味著相鄰的 Key 會有很大的概率有共同的前綴部分。正是考慮到這一點,DataBlock 在結構上做了優化,這個優化可以顯著減少存儲空間。
Key = sharedKey + unsharedKey
Key 會劃分為兩個部分,一個是 sharedKey,一個是 unsharedKey。前者表示相對基準 Key 的共同前綴內容,后者表示相對基準 Key 的不同后綴部分。
比如基準 Key 是 helloworld,那么 hellouniverse 這個 Key 相對于基準 Key 來說,它的 sharedKey 就是 hello,unsharedKey 就是 universe。
DataBlock 中存儲的是連續的一系列鍵值對,它會每隔若干個 Key 設置一個基準 Key。基準 Key 的特點就是它的 sharedKey 部分是空串。基準 Key 的位置,也就是它在塊中的偏移量我們稱之為「重啟點」RestartPoint,在 DataBlock 中會記錄所有「重啟點」位置。第一個「重啟點」的位置是零,也就是 DataBlock 中的第一個 Key。
struct Entry {
varint sharedKeyLength;
varint unsharedKeyLength;
varint valueLength;
byte[] unsharedKeyContent;
byte[] valueContent;
}
struct DataBlock {
Entry[] entries;
int32 [] restartPointOffsets;
int32 restartPointCount;
}
DataBlock 中基準 Key 是默認每隔 16 個 Key 設置一個。從節省空間的角度來說,這并不是一個智能的策略。比如連續 26 個 Key 僅僅是最后一個字母不同,DataBlock 卻每隔 16 個 Key 強制「重啟」,這明顯不是最優的。這同時也意味著 sharedKey 是空串的 Key 未必就是基準 Key。
一個 DataBlock 的默認大小只有 4K 字節,所以里面包含的鍵值對數量通常只有幾十個。如果單個鍵值對的內容太大一個 DataBlock 裝不下咋整?
這里就必須糾正一下,DataBlock 的大小是 4K 字節,并不是說它的嚴格大小,而是在追加完最后一條記錄之后發現超出了 4K 字節,這時就會再開啟一個 DataBlock。這意味著一個 DataBlock 可以大于 4K 字節,如果 value 值非常大,那么相應的 DataBlock 也會非常大。DataBlock 并不會將同一個 Value 值分塊存儲。
如果沒有開啟布隆過濾器,FilterBlock 這個塊就是不存在的。FilterBlock 在一個 SSTable 文件中可以存在多個,每個塊存放一個過濾器數據。不過就目前 LevelDB 的實現來說它最多只能有一個過濾器,那就是布隆過濾器。
布隆過濾器用于加快 SSTable 磁盤文件的 Key 定位效率。如果沒有布隆過濾器,它需要對 SSTable 進行二分查找,Key 如果不在里面,就需要進行多次 IO 讀才能確定,查完了才發現原來是一場空。布隆過濾器的作用就是避免在 Key 不存在的時候浪費 IO 操作。通過查詢布隆過濾器可以一次性知道 Key 有沒有可能在里面。
單個布隆過濾器中存放的是一個定長的位圖數組,該位圖數組中存放了若干個 Key 的指紋信息。這若干個 Key 來源于 DataBlock 中連續的一個范圍。FilterBlock 塊中存在多個連續的布隆過濾器位圖數組,每個數組負責指紋化 SSTable 中的一部分數據。
struct FilterEntry {
byte[] rawbits;
}
struct FilterBlock {
FilterEntry[n] filterEntries;
int32[n] filterEntryOffsets;
int32 offsetArrayOffset;
int8 baseLg; // 分割系數
}
其中 baseLg 默認 11,表示每隔 2K 字節(2<<11)的 DataBlock 數據(壓縮后),就開啟一個布隆過濾器來容納這一段數據中 Key 值的指紋。如果某個 Value 值過大,以至于超出了 2K 字節,那么相應的布隆過濾器里面就只有 1 個 Key 值的指紋。每個 Key 對應的指紋空間在打開數據庫時指定。
// 每個 Key 占用 10bit 存放指紋信息
options.SetFilterPolicy(levigo.NewBloomFilter(10))
這里的 2K 字節的間隔是嚴格的間隔,這樣才可以通過 DataBlock 的偏移量和大小來快速定位到相應的布隆過濾器的位置 FilterOffset,再進一步獲得相應的布隆過濾器位圖數據。
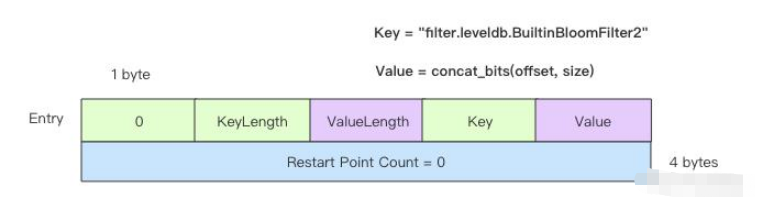
MetaIndexBlock 存儲了前面一系列 FilterBlock 的元信息,它在結構上和 DataBlock 是一樣的,只不過里面 Entry 存儲的 Key 是帶固定前綴的過濾器名稱,Value 是對應的 FilterBlock 在文件中的偏移量和長度。
key = "filter." + filterName
// value 定義了數據塊的位置和大小
struct BlockHandler {
varint offset;
varint size;
}
就目前的 LevelDB,這里面最多只有一個 Entry,那么它的結構非常簡單,如下圖所示
IndexBlock 結構
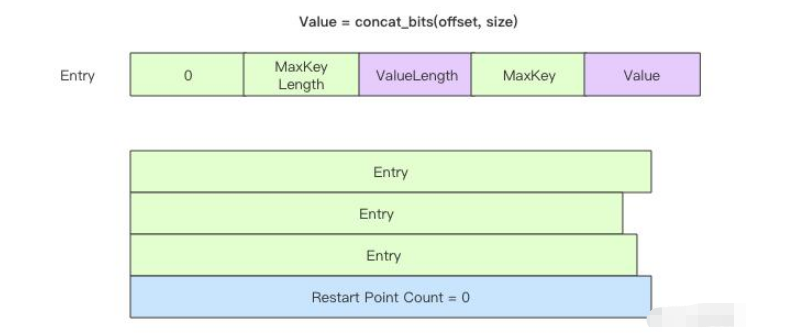
它和 MetaIndexBlock 結構一樣,也存儲了一系列鍵值對,每一個鍵值對存儲的是 DataBlock 的元信息,SSTable 中有幾個 DataBlock,IndexBlock 中就有幾個鍵值對。鍵值對的 Key 是對應 DataBlock 內部最大的 Key,Value 是 DataBlock 的偏移量和長度。不考慮 Key 之間的前綴共享,不考慮「重啟點」,它的結構如下圖所示
以上就是關于“LevelDB數據文件SSTable結構是怎樣的”這篇文章的內容,相信大家都有了一定的了解,希望小編分享的內容對大家有幫助,若想了解更多相關的知識內容,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





