溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
過去的一年多的時間中,大部分的工作都圍繞著Zeppelin這個項目展開,經歷了Zeppelin的從無到有,再到逐步完善穩定。見證了Zeppelin的成長的同時,Zeppelin也見證了我的積累進步。對我而言,Zeppelin就像是孩提時代一同長大的朋友,在無數次的游戲和談話中,交換對未知世界的感知,碰撞對未來的憧憬,然后刻畫出更好的彼此。這篇博客中就向大家介紹下我的這位老朋友。
定位
Zeppelin是一個分布式的KV存儲平臺,在設計之初,我們對他有如下幾個主要期許:
高性能;
大集群,因此需要有更好的可擴展性和必要的業務隔離及配額;
作為支撐平臺,向上支撐更豐富的協議;
Zeppelin的整個設計和實現都圍繞這三個目標努力,本文將從API、數據分布、元信息管理、一致性、副本策略、數據存儲、故障檢測幾個方面來分別介紹。
為了讓讀者對Zeppelin有個整體印象,先介紹下其提供的接口:
基本的KV存儲相關接口:Set、Get、Delete;
支持TTL;
HashTag及針對同一HashTag的Batch操作,Batch保證原子,這一支持主要是為了支撐上層更豐富的協議。
最為一個分布式存儲,首要需要解決的就是數據分布的問題。另一篇博客淺談分布式存儲系統數據分布方法中介紹了可能的數據分布方案,Zeppelin選擇了比較靈活的分片的方式,如下圖所示:
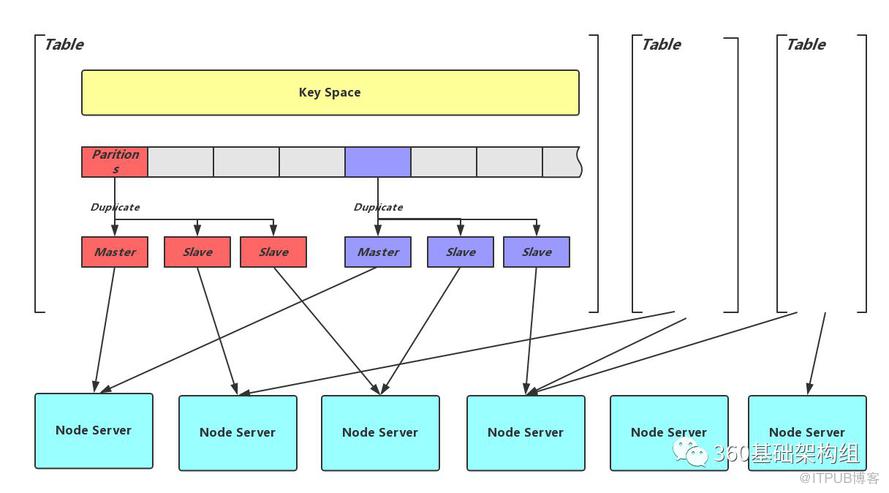
用邏輯概念Table區分業務,并將Table的整個Key Space劃分為相同大小的分片(Partition),每個分片的多副本分別存儲在不同的存儲節點(Node Server)上,因而,每個Node Server都會承載多個Partition的不同副本。Partition個數在Table創建時確定,更多的Partition數會帶來更好的數據均衡效果,提供擴展到更大集群的可能,但也會帶來元信息膨脹的壓力。實現上,Partition又是數據備份、數據遷移、數據同步的最小單位,因此更多的Partition可能帶來更多的資源壓力。Zeppelin的設計實現上也會盡量降低這種影響。
可以看出,分片的方式將數據分布問題拆分為兩層隱射:從Key到Partition的映射可以簡單的用Hash實現。而Partition副本到存儲節點的映射相對比較復雜,需要考慮穩定性、均衡性、節點異構及故障域隔離(更多討論見淺談分布式存儲系統數據分布方法)。關于這一層映射,Zeppelin的實現參考了CRUSH對副本故障域的層級維護方式,但擯棄了CRUSH對降低元信息量稍顯偏執的追求。
在進行創建Table、擴容、縮容等集群變化的操作時,用戶需要提供整個:
集群分層部署的拓撲信息(包含節點的機架、機器等部署信息);
存儲節點權重;
各個故障層級的分布規則;
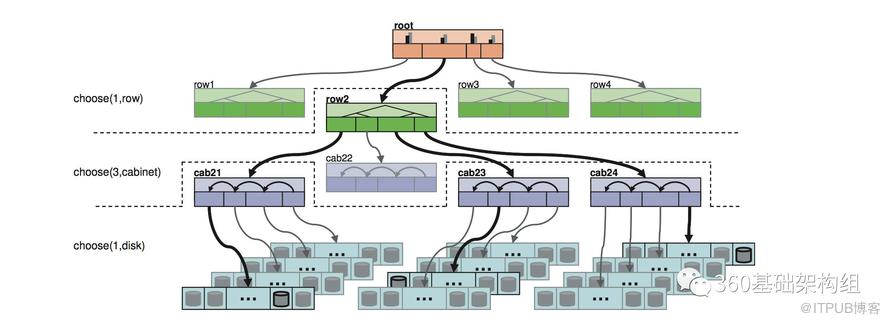
Zeppelin根據這些信息及當前的數據分布直接計算出完整的目標數據分布,這個過程會盡量保證數據均衡及需要的副本故障域。下圖舉例展示了,副本在機架(cabinet)級別隔離的規則及分布方式。更詳細的介紹見Decentralized Placement of Replicated Data
上面確定了分片的數據分布方式,可以看出,包括各個分片副本的分布情況在內的元信息需要在整個集群間共享,并且在變化時及時擴散,這就涉及到了元信息管理的問題,通常有兩種方式:
有中心的元信息管理:由中心節點來負責整個集群元信息的檢測、更新和維護,這種方式的優點是設計簡潔清晰,容易實現,且元信息傳播總量相對較小并且及時。最大的缺點就是中心節點的單點故障。以BigTable和Ceph為代表。
對等的元信息管理:將集群元信息的處理負擔分散到集群的所有節點上去,節點間地位一致。元信息變動時需要采用Gossip等協議來傳播,限制了集群規模。而無單點故障和較好的水平擴展能力是它的主要優點。Dynamo和Redis Cluster采用的是這種方式。
考慮到對大集群目標的需求,Zeppelin采用了有中心節點的元信息管理方式。其整體結構如下圖所示:
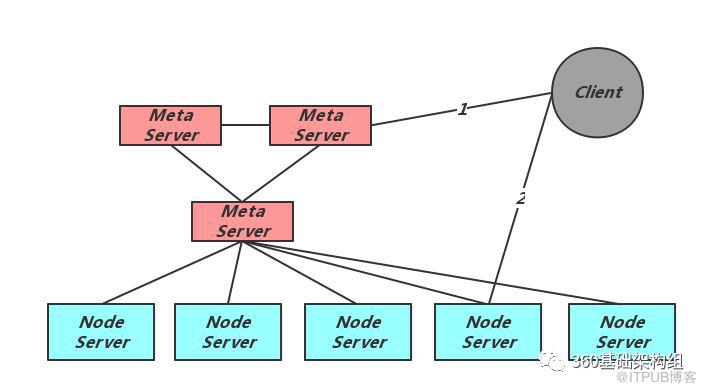
可以看出Zeppelin有三個主要的角色,元信息節點Meta Server、存儲節點Node Server及Client。Meta負責元信息的維護、Node的存活檢測及元信息分發;Node負責實際的數據存儲;Client的首次訪問需要先從Meta獲得當前集群的完整數據分布信息,對每個用戶請求計算正確的Node位置,并發起直接請求。
為了減輕上面提到的中心節點的單點問題。我們采取了如下策略:
Meta Server以集群的方式提供服務,之間以一致性算法來保證數據正確。
良好的Meta設計:包括一致性數據的延遲提交;通過Lease讓Follower分擔讀請求;粗粒度的分布式鎖實現;合理的持久化及臨時數據劃分等。更詳細的介紹見:Zeppelin不是飛艇之元信息節點
智能Client:Client承擔更多的責任,比如緩存元信息;維護到Node Server的鏈接;計算數據分布的初始及變化。
Node Server分擔更多責任:如元信息更新由存儲節點發起;通過MOVE,WAIT等信息,實現元信息變化時的客戶端請求重定向,減輕Meta壓力。更詳細的介紹見:Zeppelin不是飛艇之存儲節點
通過上面幾個方面的策略設計,盡量的降低對中心節點的依賴。即使Meta集群整個異常時,已有的客戶端請求依然能正常進行。
上面已經提到,中心元信息Meta節點以集群的方式進行服務。這就需要一致性算法來保證:
即使發生網絡分區或節點異常,整個集群依然能夠像單機一樣提供一致的服務,即下一次的成功操作可以看到之前的所有成功操作按順序完成。
Zeppelin中采用了我們的一致性庫Floyd來完成這一目標,Floyd是Raft的C++實現。更多內容可以參考:Raft和它的三個子問題。
利用一致性協議,Meta集群需要完成Node節點的存活檢測、元信息更新及元信息擴散等任務。這里需要注意的是,由于一致性算法的性能相對較低,我們需要控制寫入一致性庫的數據,只寫入重要、不易恢復且修改頻度較低的數據。
為了容錯,通常采用數據三副本的方式,又由于對高性能的定位,我們選擇了Master,Slave的副本策略。每個Partition包含至少三個副本,其中一個為Master,其余為Slave。所有的用戶請求由Master副本負責,讀寫分離的場景允許Slave也提供讀服務。Master處理的寫請求會在修改DB后寫Binlog,并異步的將Binlog同步給Slave。

上圖所示的是Master,Slave之間建立主從關系的過程,右邊為Slave。當元信息變化時,Node從Meta拉取最新的元信息,發現自己是某個Partition新的Slave時,將TrySync任務通過Buffer交給TrySync Moudle;TrySync Moudle向Master的Command Module發起Trysync;Master生成Binlog Send任務到Send Task Pool;Binlog Send Module向Slave發送Binlog,完成數據異步復制。更詳細內容見:Zeppelin不是飛艇之存儲節點。未來也考慮支持Quorum及EC的副本方式來滿足不同的使用場景。
Node Server最終需要完成數據的存儲及查詢等操作。Zeppelin目前采用了Rocksdb作為存儲引擎,每個Partition副本都會占有獨立的Rocksdb實例。采用LSM方案也是為了對高性能的追求,相對于B+Tree,LSM通過將隨機寫轉換為順序寫大幅提升了寫性能,同時,通過內存緩存保證了相對不錯的讀性能。庖丁解LevelDB之概覽中以LevelDB為例介紹了LSM的設計和實現。
然而,在數據Value較大的場景下,LSM寫放大問題嚴重。為了高性能,Zeppelin大多采用SSD盤,SSD的隨機寫和順序寫之間的差距并不像機械盤那么大,同時SSD又有擦除壽命的問題,因此LSM通過多次重復寫換來的高性能優勢不太劃算。而Zeppelin需要對上層不同協議的支撐,又不可避免的會出現大Value,LSM upon SSD針對這方面做了更多的討論,包括這種改進在內的其他針對不同場景的存儲引擎及可插拔的設計也是Zeppelin未來的發展方向。
一個好的故障檢測的機制應該能做到如下幾點:
及時:節點發生異常如宕機或網絡中斷時,集群可以在可接受的時間范圍內感知;
適當的壓力:包括對節點的壓力,和對網絡的壓力;
容忍網絡抖動
擴散機制:節點存活狀態改變導致的元信息變化需要通過某種機制擴散到整個集群;
Zeppelin 中的故障可能發生在元信息節點集群或存儲節點集群,元信息節點集群的故障檢測依賴下層的Floyd的Raft實現,并且在上層通過Jeopardy階段來容忍抖動。更詳細內容見:Zeppelin不是飛艇之元信息節點。
而存儲節點的故障檢測由元信息節點負責, 感知到異常后,元信息節點集群修改元信息、更新元信息版本號,并通過心跳通知所有存儲節點,存儲節點發現元信息變化后,主動拉去最新元信息并作出相應改變。
最后,Zeppelin還提供了豐富的運維、監控數據,以及相關工具。方便通過Prometheus等工具監控展示。
[Zeppelin](https://github.com/Qihoo360/zeppelin)
[Floyd](https://github.com/Qihoo360/floyd)
[Raft](https://raft.github.io/)
[淺談分布式存儲系統數據分布方法](http://catkang.github.io/2017/12/17/data-placement.html)
[Decentralized Placement of Replicated Data](https://whoiami.github.io/DPRD)
[Zeppelin不是飛艇之元信息節點](http://catkang.github.io/2018/01/19/zeppelin-meta.html)
[Zeppelin不是飛艇之存儲節點](http://catkang.github.io/2018/01/07/zeppelin-overview.html)
[Raft和它的三個子問題](http://catkang.github.io/2017/06/30/raft-subproblem.html)
[庖丁解LevelDB之概覽](http://catkang.github.io/2017/01/07/leveldb-summary.html)
[LSM upon SSD](http://catkang.github.io/2017/04/30/lsm-upon-ssd.html)
原文鏈接:https://mp.weixin.qq.com/s/cfMtQ1YAZiCId3OM7bxXrg
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





