溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
張瑞,阿里集團數據庫技術團隊負責人,阿里巴巴研究員,Oracle ACE。雙十一數據庫技術總負責人,曾兩次擔任雙十一技術保障總負責人。自2005年加入阿里巴巴以來,一直主導整個阿里數據庫技術的不斷革新。
近日,在京舉行的2017中國數據庫技術大會上,來自阿里巴巴集團研究員張瑞發表了題為《面向未來的數據庫體系架構的思考》的主題演講。主要介紹了阿里數據庫技術團隊正在建設阿里下一代數據庫技術體系的想法和經驗,希望能夠把阿里的成果、踩過的坑以及面向未來思考介紹給與會者,為中國數據庫技術的發展出一份力。

演講全文:
我先介紹一下我自己,我2005年加入阿里一直在做數據庫方面的工作,今天這個主題是我最近在思考阿里巴巴下一代數據庫體系方面的一些想法,在這里分享給大家,希望能夠拋磚引玉。大家如果能夠在我今天分享后,結合自己面對的實際場景,得到一些體會,有點想法的話,我今天分享的目的就達到了。
今天我會講以下幾方面內容:首先講一下我們在內核上的一點創新、數據庫怎么實現彈性調度、關于智能化的思考、最后是曾經踩過的坑和看到未來的方向。
阿里場景下數據庫所面臨的問題
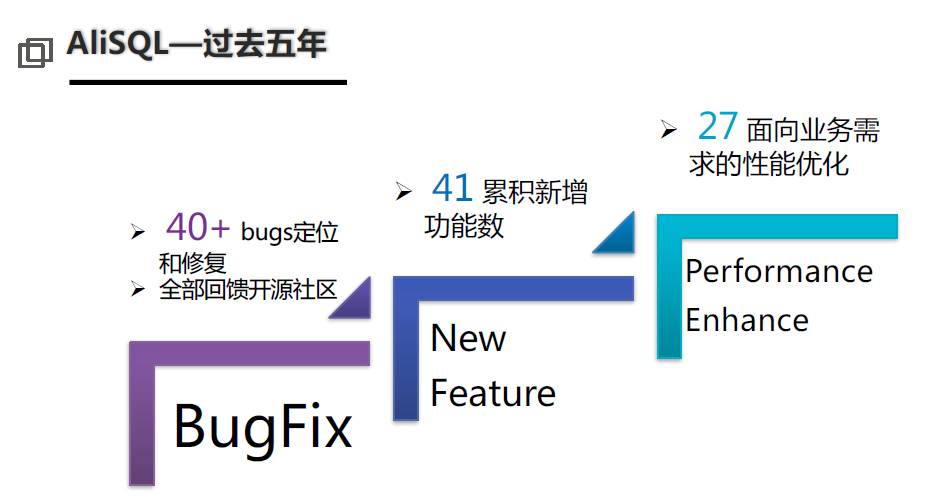
首先說一下,阿里巴巴最早一代使用的數據庫技術是Oracle,后面大家也知道一件事情就是去IOE,去IOE過程中我們邁向了使用開源數據庫的時代,這個時代今天已經過去,這個過程大概持續了五六年,整個阿里巴巴有一個大家都知道的開源MYSQL分支--AliSQL,我們在上面做了大量的改進,所以我這里列了一下在AliSQL上的一些改進,但今天我實際上并不想講這個,我想講一下面向未來的下一代數據庫技術、數據庫架構會往哪個方向走。
我覺得是這樣的,因為今天的阿里巴巴畢竟是一個技術的公司,所以很多時候我們會看比如說Google或者是一些互聯網的大的公司,他們在技術上創新點來自于哪里?來自于問題。就是說今天在座的各位和我是一樣的,你所面對場景下的問題是什么、你看問題深度如何決定了你今天創造的創新有多大。
所以今天我們重新看一下阿里面臨的問題是什么,相信在座的各位一定也有這樣的想法,阿里所面臨的問題不一定是你們的問題,但我想說今天通過阿里面臨的問題,以及我們看到這些問題后所做的事情,期待能夠給大家帶來參考,希望大家也能夠看到自己所面臨的問題是什么,你將如何思考。

可以看到其實阿里巴巴的應用和Facebook、Google的還是有很大區別的,我們也找他們做了交流,發現跟他們的業務場景真的不一樣,首先我們的主要應用是交易型的,這些應用會有些什么要求,你會看到有這些點(見圖片),下面主要講一下我們的思考。
今天數據的高可用和強一致是非常重要的,數據不一致帶來的問題是非常非常巨大的,大家也用淘寶,也是阿里巴巴一些服務的用戶,數據不一致帶來的問題,每一個用戶、甚至我的父母都會關注這些事情。
第二,今天存儲成本是非常高的,所有的數據中心已經在用SSD,但數據的存儲成本依然是一個大型企業面臨的一個非常大的問題,這都是實實在在錢的問題。
另外剛才也提到了,數據都是有生命周期的,那么數據尤其是交易數據是有非常明顯的冷和熱的狀態,大家一定很少看自己一年前在淘寶的購買記錄,但是當下的購買記錄會去看,那系統就需要經常會去讀它、更新它。
還有一個特點是今天阿里的業務還是相對簡單的,比如我們要在OLTP性能上做到極致性。還有一個阿里巴巴特有的點就是雙十一,雙十一本質上是什么,本質上就是制造了一個技術上非常大的熱點效應。這對我們提出什么樣的需求呢?需求就是一個極致彈性的能力,數據庫實際上在這個方向是非常欠缺的,數據庫怎么樣去做到彈性伸縮是非常難的事情。
最后我想說說DBA,今天在座的很多人可能都是DBA,我想說一下阿里在智能化這個方向上得到的思考是什么樣的,我們有海量的數據,我們也有很多經驗很豐富的DBA,但這些DBA怎么樣去完成下一步的轉型、怎么樣不成為業務的瓶頸?數據庫怎么樣做到自診斷、自優化。這是我們看到的問題,最后我也會來分享一下我在這方面的思考。
阿里在數據庫內核方向上的思考
我先講一下我們在數據庫內核上的思考。首先我很尊敬做國產數據庫的廠商,凡是在內核上改進的人都知道,其實每個功能都是要一行行代碼寫出來都是非常不容易的,我想表達對國產數據庫廠商包括這些技術人的尊敬。今天我要講的內容是我第一次在國內的會議上來講,首先我會講一下AliSQL X-Cluster。X-Cluster是在AliSQL上做的一個三節點集群,這是我們在引入了Paxos一致性協議,保證MySQL變成一個集群,并且這個集群具有數據強一致、面向異地部署,且能夠容忍網絡高延遲等一系列特性。
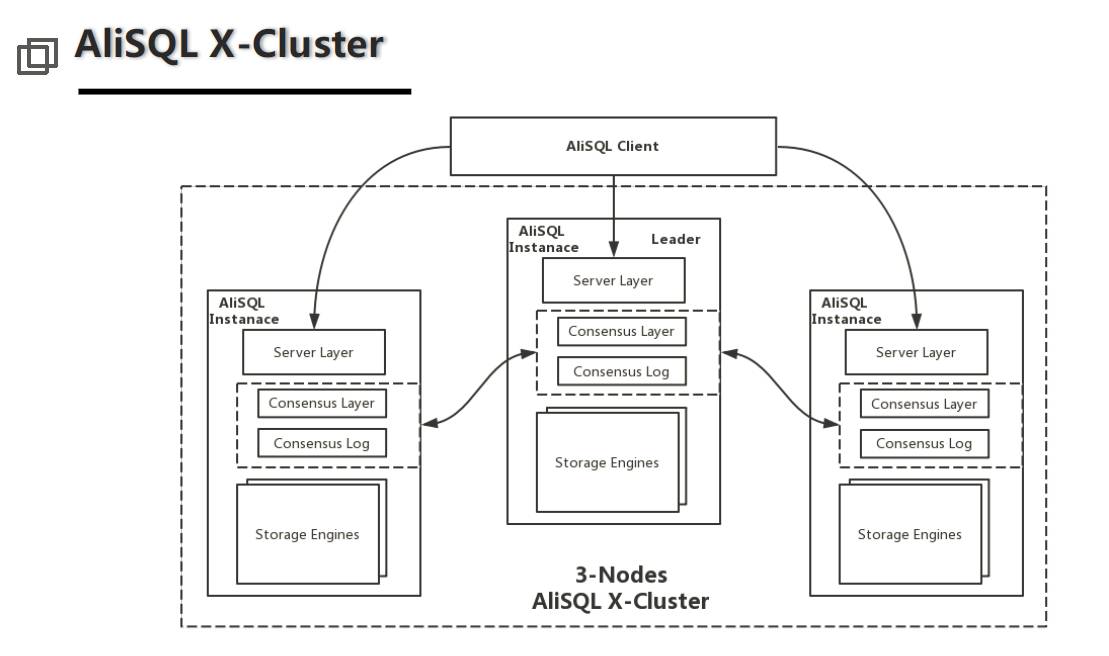
今天很多數據庫都會和Paxos聯系在一起,比如大家都知道的Google的Spanser數據庫,但是以前大家沒有特別想過數據庫和Paxos會有什么關系,其實以前確實沒有什么關系的,但是今天的數據庫在幾個地方是需要用到Paxos協議的,第一個我們需要用Paxos來選舉,尤其在高可用的場景下需要唯一地選舉出一個節點作為主節點,這就需要用到Paxos;第二是用Paxos協議來保證數據庫在沒有共享存儲的前提下數據的強一致,就是數據怎么樣在多個節點間保證是強一致,且保證高可用。
所以說現在的數據庫架構設計上Paxos的應用非常廣泛,今天外面很多展商包括Goolge Spanser也都在用Paxos協議和數據庫結合在一起來做。所以AliSQL的三節點集群也是一樣,就是利用Paxos協議變成一個數據強一致的集群。下面我大概解釋一下Paxos協議在數據庫里的作用是什么。

本質上來說Paxos也是現在通用的技術,大家都是搞數據庫的,簡單來說,Paxos協議用在我們數據庫里面,就是一個事務組的提交在一個節點并落地后,必須在多個節點同時落地,也就是說原來寫入只需要寫入一個節點上,但是現在需要跨網絡寫到另外一個節點上,這個節點可能是異地的,也可能是全球的另外一個城市,中間需要經過非常漫長的網絡時延,這時候需要有一些核心技術。
我們的目標是什么?首先沒有辦法抗拒物理時延,過去在數據庫上的操作只要提交到本地,但現在數據庫全球部署、異地部署,甚至跨網絡,這個時延特性是沒有辦法克服的,但是在這種情況下我們能做到什么?在時延增長情況下盡可能保證吞吐不下降,原來做多少QPS、TPS,這一點是可以保證的,只要工程做的好是可以保證的,但是時延一定會提升。
這也是大家經常在Goolgle Spanser論文里看到的“我的時延很高”的描述,在這種時延很高的情況下,怎么樣寫一個好的應用來保證可用、高吞吐,這是另外一個話題。大家很長一段時間里已經習慣一個概念,那就是數據庫一定是時延很低的,時延高就會導致應用出問題,實際上這個問題要花另外一個篇幅去講,那就是應用程序必須要去適應這種時延高的數據庫系統。當然用了Batching和Pipelining技術,本質上是通用的工程優化,讓跨網絡多復本同步變的高效,但是時延一定會增加。
實際上大家知道數據庫要做三副本或者三節點,本質上就是為了實現數據強一致,而且大家都在這個方向上做努力,比如Oracle前一段時間推出的Group replication,也是三節點技術,X-Cluster和它的區別是,我們一開始的目標就是跨城市,最開始設計的時候就認為這個節點一定要跨非常遠的距離來部署的,設計之初提出這個目標造成我們設計上、工程實踐上、包括最終的性能上有比較大的差異。
這里我們也做了一些X-Cluster和Oracle的Group replication的對比,同城的環境下我們要比他們好一些;在異地場景下這個差異就更大了,因為我們本來設計的時候就是面向異地的場景。可能大家也知道,阿里一直在講異地多活的概念,就是IDC之間做異地多活怎么樣能夠做到,所以最開始我們設計的就是面向異地的場景做的。
這是一個典型的X-Cluster在異地多活的場景下怎么做的架構圖,這是一個典型的3城市4份數據5份日志架構,如果要簡化且考慮數據存儲成本的話,實際上可以做到3份數據5份日志,這樣的話就可以保證城市級、機房機、包括單機任何的故障都可以避免,并且是零數據丟失的,在今天我們可以這么做,且能保證數據是零丟失、強一致的。在任何一個點上的數據至少會被寫到另一個城市的數據中心的數據庫里面,這是我們X-Cluster設計之初的目標,這也是一個典型的異地多活的架構。
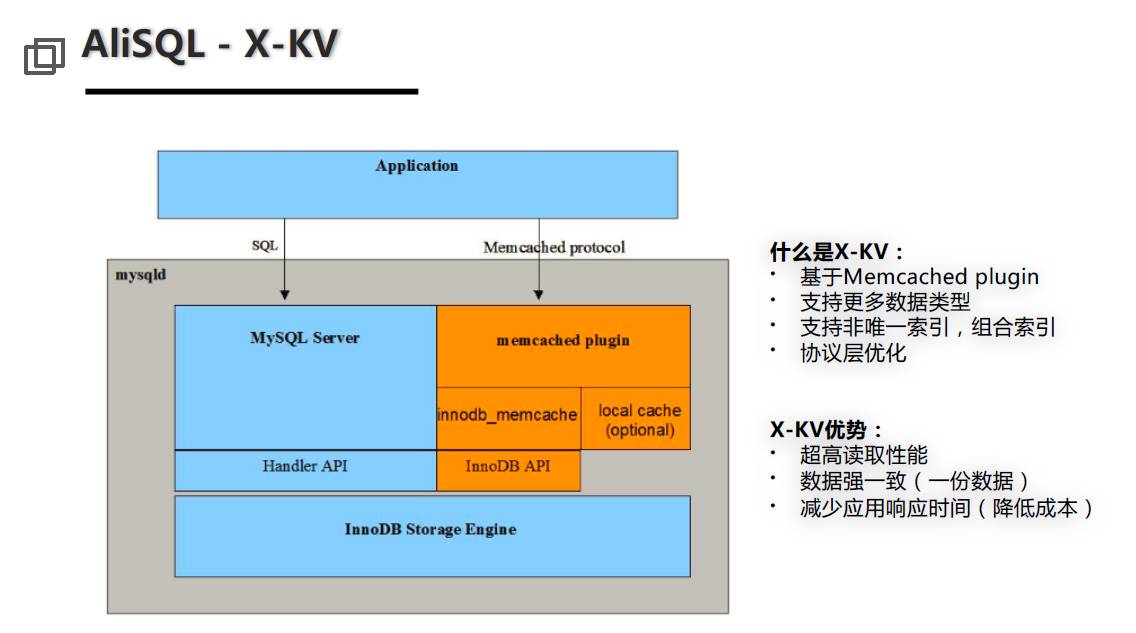
再講一個小的,但是非常實用的創新點,可能大家都比較感興趣,這就是X-KV。這里還要說一下,我們所有的下一代技術組件都是以X開頭的。這個X-KV是基于原來MYSQL的Memcached plugin做的改進,做到非常高的性能,大家可能都了解MySQL的Memcached plugin,可以通過Memcached plugin的接口直接訪問InnoDB buffer 里的數據,讀的性能可以做到非常高,這對于大家來說,或者對于所謂的架構師,或者設計的過程中意義在什么地方呢?
那就是很多場景下不需要緩存了,因為數據庫+緩存結構基本上是所有業務通用的場景,但是緩存的問題在于緩存和數據庫里的數據永遠是不一致的,需要一個同步或者失效機制來做這個事情。使用X-KV后讀的問題基本上就能解決掉。這是因為一份數據只要通過這個接口訪問就基本上做到和原來訪問緩存差不多的能力,或者說在大部分情況下其實就不需要緩存了。

第二是說它降低了應用的響應時間,原來用SQL訪問的話響應時間會比較高,我們在這上面做了一些改進,本來Memcached plugin插件有一些支持數據的類型限制,包括對一些索引類型支持不太好,所以我們做了改進,這個大家都可以用的,如果用這個方式的話基本上很多緩存系統是不需要的。
第三個事情我想講一下怎么樣解決冷熱數據分離的,我們天然地利用了MySQL的框架,這里就直接拿了MySQL的大圖來展示,大家可以看到MySQL本質上來說就是上面有個Client,中間有個Server,底下有個存儲層,在存儲層里面可以有各種各樣的引擎,所以通過不同的引擎可以實現不同的特性。大家今天最常用的就是InnoDB引擎,每個存儲引擎的特性本質上是由其結構造成的。比如InnoDB采用B+ Tree的結構,它帶來的特性就是相對來說讀和寫都比較均衡,因為發展了這么多年確實是比較成熟的。
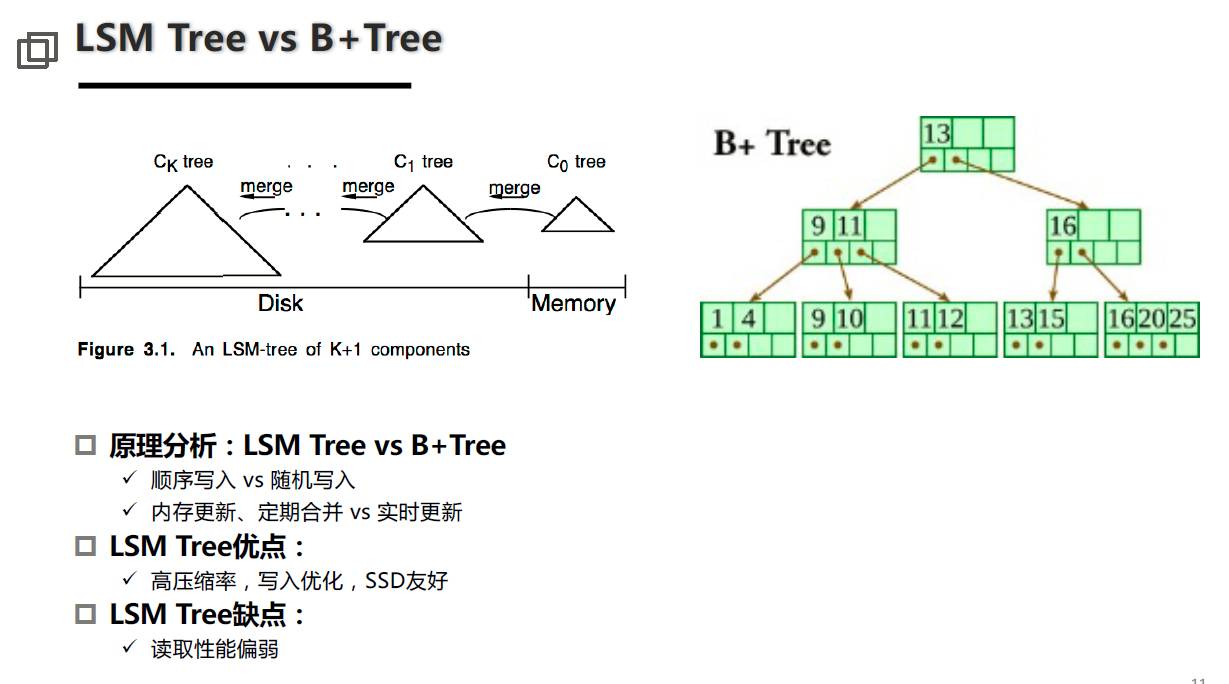
比如我們現在選擇RocksDB,這是因為我們和Facebook在RocksDB上有一些合作,就是把它引入到MySQL上面,它本質的結構是LSM Tree,這個結構就帶來的好處包括寫入比較友好、壓縮的特性好等。把它引入進來對我們的改革還不僅僅是引入了一個結構,而是今天我們用這兩種引擎解決我們今天數據分離的問題。我們也跟Facebook有過一些交流,RocksDB今天并沒有那么穩定、那么好,但是作為InnoDB存儲引擎的補充的話,是非常有效的。
尤其在穩定數據庫的背景下,用戶今天怎么樣才能對自己的數據的冷熱沒有太多的感覺,因為大家可能也知道,你們以前也有一些數據的分離,但是對應用方來說,需要把數據從某個存儲倒到某個存儲里,然后再刪掉;或者動不動DBA去找業務開發方說你的存儲空間不夠了,占用很多空間,能不能刪一些數據或者把這些數據導入到成本更低的存儲引擎里。我們經常這么干,這里說的直白一點,我相信大家都這么干過。
但是用這種雙引擎結構的話,RocksDB壓縮率高的特性,特別是OLTP行存儲的場景下,能夠給我們帶來比較大的收益。所以我們可以把這兩個引擎在MySQL特性下面把它結合起來,并且可以利用到比較廉價的架構,尤其是LSM Tree這種架構,他對廉價的存儲介質是比較友好的,因為他的寫都是順序寫的。這就是我們今天在數據庫內核上面的一些思考。
數據庫為什么要實現彈性調度
第二部分,我想說一下數據庫彈性調度這個事,大家都知道阿里雙十一,雙十一對我們來說最大的挑戰就是應用程序可能已經很容易去做彈性調度,包括上云、彈性擴容和縮容,但是數據庫確實比較難,我們也在這上面也探索了一段時間,今天會把我們的思考分享給大家。

我之前聽好多人說數據庫容器化是個偽命題,為什么要做容器化,為什么要把數據庫放到容器里呢?第二也有一些新技術,比如剛才的分享嘉賓也提到的,把存儲放在遠端通過網絡訪問是可能的。但是我們從正向來思考,先別想數據庫彈性調度可能不可能,數據庫如果要實現彈性調度,它的前提是什么?
我們先去想數據庫要像應用一樣非常簡單的彈性調度,那么數據庫要做到什么?我覺得有兩大前提是必須要做的:1、它必須要放到一個容器里;2、計算和存儲必須分離。因為如果計算和存儲本質上不分離的話,數據庫基本上沒有辦法彈性調度。大家知道計算資源是很容易被移動的,但是存儲資源基本上很難在短時間內移動它,所以做彈性是非常非常困難的。所以這是兩大基礎條件。
在我們的場景下如果你也碰到這種問題的話,那就不是偽命題,我覺得這個東西合不合理,更多時候不是技術有沒有正確性,而是在你的場景下是否需要它,所以今天我們就做了兩件事情,第一是把它放到容器里面,我們目前物理機,VM和Docker都在支持,有一層會把容器的復雜性屏蔽掉,數據庫一定要放到容器里。應用程序放到容器里很多時候是為了部署,但是我們把數據庫放容器里就是為了做調度,因為數據庫本身沒有特別多的發布,不需要像應用一樣做頻繁發布。做了容器化之后,數據庫在一個物理機上可以和其他的容器做混部。
我們做DBA的都有一些傳統的觀點,比如數據庫服務器上肯定不能跑應用,數據庫肯定是不能用容器的。不知道在座的各位,每當有人或者你的老板問你這個問題的時候,你是不是從來都是馬上回絕他說“數據庫肯定不能這么做”,但是今天你也許可以告訴你的老板可以試一試。
存儲計算分離,最早做數據庫的時候,存儲和計算其實就是分離的,用一個Oracle的數據庫,用一個SAN網絡,底下接一個存儲,存儲和計算本身就是分離的,中間用SAN網絡連起來。然后演進到用Local的盤,用SSD盤,用PC做服務器。,那未來重新要回到存儲和計算分離的結構下,今天的網絡技術的發展,不說專有網絡,就說通用的25G網絡,還有RDMA和SPDK等新技術的使用,讓我們具備了存儲計算分離的能力,讓數據庫存儲計算分離的條件已經具備。
今天在數據庫上已經看到大量優化的特性可以減少IO,可以把離散的IO變成順序的IO,可以對下層的存儲做的很友好。從存儲成本上來說,共享存儲會極大的降低成本,是因為存儲碎片會被極大地壓縮,因為原來每個機器上都空閑30%、50%的空間,其他的機器是很難利用到的,當你今天把這些碎片變成一個Pool的時候是有很大收益的。
還有數據庫未來如果采用存儲和計算分離的話,就會打破目前主流的數據庫一主一備的架構,這個架構至少有一半的計算資源是被完全浪費的,不管你的備庫是否用來做報表或者其他的應用,但是基本是浪費的。如果可以做到共享存儲,那這將是一個巨大的收益。這是我們在調度上的思考,明天分會場上也會有一個阿里同學就這個主題給大家做容器和存儲資源上的細節介紹,我今天只講了一個大概。
DBA未來的工作內容是什么?
最后講一下DBA的事情,剛才也在說,我這里說從自動化走向智能化,我們內部講從自助化走向智能化,不知道大家是不是受到一個困擾,業務發展的速度遠遠大于DBA人數的增長,如果你沒有后面的這些我可以不講了,但是如果你有,你可以聽一下我們在這方面的思考,我們也碰到同樣的問題,DBA要怎么樣的發展,自動化的下一步應該做什么,很多人說DBA是不是會被淘汰掉,至少我們想清楚了這些問題之后,阿里的DBA不糾結這個事情,所以我今天跟大家分享一下這個思考。
首先我們今天做了一個事情,我們放棄了原來的思路,原來的思路是什么呢?最早的時候我們每個上線的SQL都需要DBA看一下;第二個階段,我們做了一個系統,在每個SQL上線之前系統都要預估一下它的性能好不好,如果好才上線。所有我們今天覺得最大的變化和思考是什么?所有基于單條語句的優化都是沒有特別多意義的,因為只有基于大的數據和計算,才有可能變成一個智能化的東西,否則都是基于規則的。
基于規則的系統是很難有特別長久的生命力,因為有永遠寫不完的規則。我們也曾經做過這樣的嘗試,一些SQL進來的時候,系統要對它進行一些判斷,最后發現永遠寫不完的規則。所以后來我們就找到了另外一個方向,我相信今天在座的所有人,你所在的公司不論大小都都有一個監控系統,我們就從這個監控系統出發,怎么樣把一個監控系統變成一個智能的優化引擎,我們在這里也不說是大腦,就說是引擎好了。這個引擎會做什么?

首先來說,我們已經放棄掉基于單條SQL的優化,因為沒有意義,DBA也沒有審閱單條SQL,系統去看單條SQL的意義也不大。今天我們的第一個場景是說大量的數據,大量的數據是什么?我們就從我們的監控系統出發,提出了第一個目標,把每一條運行的SQL采集下來,不是采樣,是每一條。在規模比較大的系統來說對存儲來說是個巨大的壓力,因為這樣會產生大量的副產品。
就像Facebook在做監控產品時產生的時序數據庫一樣,今天我們產生的副產品也是在時序數據庫方面帶來壓力,這個具體的我今天先不展開。我們采集每一條SQL的運行情況,因為我們在內核里做了改進,可以把每條SQL的來源、路徑、以及它在數據庫里所有的信息全部采集下來。把監控指標壓到秒級,所有監控項的指標必須最小達到秒級,這是我們現有的技術能夠做到的。
另外,我們把應用端日志和數據庫結合在一起。原來做數據庫的時候,應用方吼一嗓子說“數據庫有沒有問題啊”DBA說沒有問題。但是從應用那端看,其實看到數據庫有很多問題,包括應用報錯,包括響應時間,把應用端報錯也要和數據庫結合在一起,尤其是應用里面報數據庫的錯誤,以及這一整條鏈路。
響應時間,只有應用端的響應時間才是真正意義上可以衡量一個數據庫是不是好的指標,而不是數據庫本身怎么樣,什么Load低啊,CPU利用率多少。當把這些數據全部采集下來之后,這些大量的時序數據我們叫做副產品,這對我們整個鏈路產生了一個巨大的壓力。我們做整個監控系統平臺的同學覺得日子要活不下去了,因為原來的存儲系統支撐不了、分析系統支撐不了、原來的平臺計算不出來。所以先從這個目標考慮,基于鏈路做了巨大的改進,包括怎么樣實現廉價存儲、怎么樣實時分析,這是存儲和計算的要求。
我們今天這個目標是在阿里內部明確提的,我們希望兩到三年內希望大部分把DBA的工作替換掉,我不知道兩到三年能不能做到,我希望能做到。其實今天DBA是這樣的,DBA的工作本質上分為兩類,第一類就是運維,但運維本質上來說是比較好解決的,不管是用云,小公司用云全搞定,大公司基本上都有一些自動化運維的系統。
但是最難解決的就是剛才我說的診斷和優化。我也了解過很多公司,比如說Google、facebook,我說你們為什么沒有DBA呢?他們說我們沒有DBA,沒有像國內這種特別傳統的針對診斷和性能優化的DBA,這種職責很少。所以這個東西希望能夠做到。
最后我們有了數據、有了計算,我們覺得未來的方向可能就是現在比較火的機器學習,這個主題明天也有一個阿里同學會來分享,機器學習這里我就不多講了,因為我覺得我們也在入門,所以沒有什么值得講的,但是我們覺得這個設計挺有戲的,你只要積累足夠的數據和計算的話這個事情還是挺有戲的。
我們對數據庫未來的其他思考
最后一頁PPT我用大白話講一下我對整個數據庫體系的一些理解。

今天在一個公司里邊沒有一個存儲或者是數據庫可以解決所有問題,今天越來越多的趨勢看到,數據存儲的多樣性是必然會存在的,因為行存有行存的優勢、列存有列存的優勢、做計算有計算的優勢、做分析有做分析的優勢、做OLTP有OLTP的優勢,不要指望,或者很難指望一個系統干所有的事情很,這個話我說了可能不太好,但是確實比較難,但是我們看到的一點是什么?就是每個技術或產品在生產中干一件事情可以干到最好,你就用它做的最好的那件事解你的問題就好了。
這就回到之前的問題,我們也走過一些彎路,數據存儲類型越來越多,今天用這個明天用那個,怎么辦?我們的運維沒法搞定,這個支持很痛苦。
所以今天我們建議建立兩個平臺:1、建立一個支撐的平臺,這個支撐的平臺盡可能把下層存儲的復雜性屏蔽掉,對上層提供統一的接口和服務;2、建立一個服務的平臺,明確面向研發的平臺,研發人員可以直接通過這個平臺來用數據庫的服務。我看到很多公司把運維平臺和DBA開發的平臺混在一起,但阿里的思路是,支撐平臺和服務平臺是兩個分層的平臺,支撐平臺在下面,上層服務平臺為所有的開發人員服務,開發人員上了這個平臺就能看到我用了什么數據庫,性能怎么樣,在上面可以做什么事情,這樣就可以大量節省DBA的人力。
我們內部有句開玩笑的話叫“不節省人力的平臺、不節省成本的技術都是耍流氓”,這句話怎么講?就是說我們的自動化系統,尤其是大公司越建越多,最后的結果就是人沒有能力了,我不知道大家有沒有這個問題,這就是我最后講的一點,自動化系統的悖論。每個公司每個人今天你們在做自動化系統的過程中有沒有發生一件事情?反正在阿里是發生了,就是人的能力弱化了。
這個自動化系統的悖論是我們無意中看到的,在講飛機的自動駕駛的時候,因為自動駕駛做的足夠好,當出現緊急問題的時候,飛機駕駛員反而沒有足夠的能力去處理緊急的情況,這就是自動化系統的悖論。
可以對比看一下,我們今天做了很多自動化系統,結果人只會點系統,系統一卡殼就完蛋,很多次生故障都是出現在系統卡殼,卡殼人搞不定,怎么辦?這是今天要去想的問題,在這個過程中今天所有帶團隊的或者今天在這個體系的人都要思考的問題,我們也在直面這個問題,讓人的能力和系統的能力能夠結合在一起,這是另外一個話題,我今天不能給出答案,但是要特別重視這些問題。
不要相信那些已經過期的神話,數據庫存儲和計算是可以分離的,數據庫也是可以放在容器里的,但你真的要去看一下,原來那些神話或者是那個背后它的問題到底是什么,其實現在可能都已經有解法了,所以在座的各位,當你的老板、CTO或者什么人來問你“能不能做到這樣?”我希望你能告訴他“我能!”
我們內部有一句話原來我們的DBA哪里看過一篇文章,說DBA的概念是什么?我印象特別深,有一個開發的同學在底下的回復是說“DBA就是一群永遠在說不的人”就是不能這樣不能那樣,我們今天我覺得未來我們變成一群永遠可以說“yes”,說“可以”的人,謝謝!
轉自:http://www.sohu.com/a/143113774_629652
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





