溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Oracle中的AWR,全稱為Automatic Workload Repository,自動負載信息庫。它收集關于特定數據庫的操作統計信息和其他統計信息,Oracle以固定的時間間隔(默認為1個小時)為其所有重要的統計信息和負載信息執行一次快照,并將快照存放入AWR中。這些信息在AWR中保留指定的時間(默認為1周),然后執行刪除。執行快照的頻率和保持時間都是可以自定義的。
AWR的引入,為我們分析數據庫提供了非常好的便利條件(這方面MySQL就相差了太多)。曾經有這樣的一個比喻——“一個系統,就像是一個黑暗的大房間,系統收集的統計信息,就如同放置在房間不同位置的蠟燭,用于照亮這個黑暗大房間。Oracle,恰到好處地放置了足夠的蠟燭(AWR),房間中只有極少的燭光未覆蓋之處,性能瓶頸就容易定位。而對于蠟燭較少或是沒有蠟燭的系統,性能優化就如同黑暗中的舞者。”
那如何解讀AWR的數據呢?Oracle本身提供了一些報告,方便進行查看、分析。下面就針對最為常見的一種報告——《AWR數據庫報告》進行說明。希望通過這篇文章,能方便大家更好地利用AWR,方便進行分析工作。

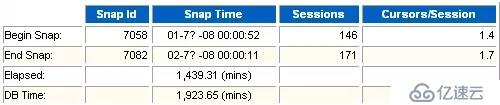
(1)Sessions
表示采集實例連接的會話數。這個數可以幫助我們了解數據庫的并發用戶數大概的情況。這個數值對于我們判斷數據庫的類型有幫助。
(2)Cursors/session
每個會話平均打開的游標數。
(3)Elapsed
通過Elapsed/DB Time比較,反映出數據庫的繁忙程度。如果DB Time>>Elapsed,則說明數據庫很忙。
(4)DB Time
表示用戶操作花費的時間,包括CPU時間和等待事件。通常同時這個數值判讀數據庫的負載情況。
db time = cpu time + wait time(不包含空閑等待)(非后臺進程)
*db time就是記錄的服務器花在數據庫運算(非后臺進程)和等待(非空閑等待)上的時間。對應于V$SESSION的elapsed_time字段累積。
需要注意的是AWR是一個數據合集。比如在1分鐘之內,1個用戶等待了30秒鐘,那么10個用戶等待事件就是300秒。CPU時間也是一樣,在1分鐘之內,1個CPU處理30秒鐘,那么4個CPU就是120秒。這些時間都是以累積的方式記錄在AWR當中的。
DB CPU——這是一個用于衡量CPU的使用率的重要指標。假設系統有N個CPU,那么如果CPU全忙的話,一秒鐘內的DB CPU就是N秒。除了利用CPU進行計算外,數據庫還會利用其它計算資源,如網絡、硬盤、內存等等,這些對資源的利用同樣可以利用時間進行度量。假設系統有M個session在運行,同一時刻有的session可能在利用CPU,有的session可能在訪問硬盤,那么在一秒鐘內,所有session的時間加起來就可以表征系統在這一秒內的繁忙程度。一般的,這個和的最大值應該為M。這其實就是Oracle提供的另一個重要指標:DB time,它用以衡量前端進程所消耗的總時間。
對除CPU以后的計算資源的訪問,Oracle用等待事件進行描述。同樣地,和CPU可分為前臺消耗CPU和后臺消耗CPU一樣,等待事件也可以分為前臺等待事件和后臺等待事件。DB Time一般的應該等于"DB CPU + 前臺等待事件所消耗時間"的總和。等待時間通過v$system_event視圖進行統計,DB Time和DB CPU則是通過同一個視圖,即v$sys_time_model進行統計。
--"Load Profile"中關于DB Time的描述
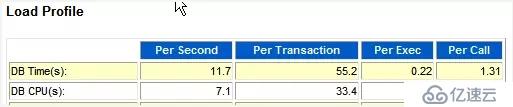
*這個系統的CPU個數是8,因此我們可以知道前臺進程用了系統CPU的7.1/8=88.75%。DB Time/s為11.7,可以看出這個系統是CPU非常繁忙的。里面CPU占了7.1,則其它前臺等待事件占了11.7 – 7.1 = 4.6 Wait Time/s。DB Time 占 DB CPU的比重: 7.1/11.7= 60.68%
--"Top 5 Timed Events"中關于DB CPU的描述
按照CPU/等待事件占DB Time的比例大小,這里列出了Top 5。如果一個工作負載是CPU繁忙型的話,那么在這里應該可以看到 DB CPU的影子。
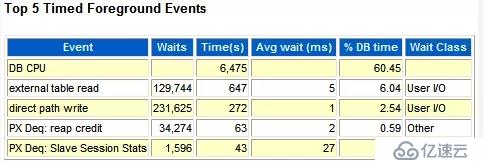
*注意到,我們剛剛已經算出了DB CPU 的%DB time,60%。其它的external table read、direct path write、PX Deq: read credit、PX Deq: Slave Session Stats這些就是占比重40的等待事件里的Top 4了。
--"Top 5 Timed Foreground Events"的局限性
再研究下這個Top 5 Timed Foreground Events,如果先不看Load Profile,是不能計算出一個CPU-Bound的工作負載。要知道系統CPU的繁忙程序,還要知道這個AWR所基于兩個snapshot的時間間隔,還要知道系統CPU的個數。要不系統可以是一個很IDLE的系統呢。記住CPU利用率 = DB CPU/(CPU_COUNT*Elapsed TIME)。這個Top 5 給我們的信息只是這個工作負載應該是并行查詢,從外部表讀取數據,并用insert append的方式寫入磁盤,同時,主要時間耗費在CPU的運算上。
--解讀"DB Time" > "DB CPU" + "前臺等待事件所消耗時間" ——進程排隊時間
上面提到,DB Time一般的應該等于DB CPU + 前臺等待事件所消耗時間的總和。在下面有對這三個值的統計:
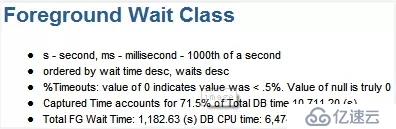
DB CPU = 6474.65
DB TIME = 10711.2
FG Wait Time = 1182.63
明顯的,DB CPU + FG Wait Time < DB Time,只占了71.5%
*其它的28.5%被消耗到哪里去了呢?這里其實又隱含著一個Oracle如何計算DB CPU和DB Time的問題。當CPU很忙時,如果系統里存在著很多進程,就會發生進程排隊等待CPU的現象。在這樣,DB TIME是把進程排隊等待CPU的時間算在內的,而DB CPU是不包括這一部分時間。這是造成 DB CPU + FG Wait Time < DB Time的一個重要原因。如果一個系統CPU不忙,這這兩者應該就比較接近了。不要忘了在這個例子中,這是一個CPU非常繁忙的系統,而71.5%就是一個信號,它提示著這個系統可能是一個CPU-Bound的系統。

這部分列出AWR在性能采集開始和結束的時候,數據緩沖池(buffer cache)和共享池(shared pool)的大小。通過對比前后的變化,可以了解系統內存消耗的變化。
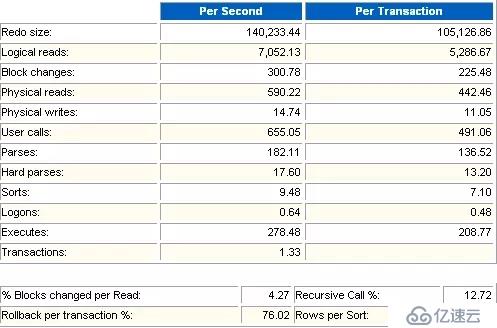
這兩部分是數據庫資源負載的一個明細列表,分隔成每秒鐘的資源負載和每個事務的資源負載。
每秒(每個事務)產生的日志大小(單位字節)
每秒(每個事務)產生的邏輯讀(單位是block)。在很多系統里select執行次數要遠遠大于transaction次數。這種情況下,可以參考Logical reads/Executes。在良好的oltp環境下,這個應該不會超過50,一般只有10左右。如果這個值很大,說明有些語句需要優化。
每秒(每個事務)改變的數據塊數。
每秒(每個事務)產生的物理讀(單位是block)。一般物理讀都會伴隨邏輯讀,除非直接讀取這種方式,不經過cache。
每秒(每個事務)產生的物理寫(單位是block)。
每秒(每個事務)用戶調用次數。User calls/Executes基本上代表了每個語句的請求次數,Executes越接近User calls越好。
每秒(每個事務)產生的解析(或分析)的次數,包括軟解析和硬解析,但是不包括快速軟解析。軟解析每秒超過300次意味著你的"應用程序"效率不高,沒有使用soft soft parse,調整session_cursor_cache。
每秒(每個事務)產生的硬解析次數。每秒超過100次,就可能說明你綁定使用的不好。
每秒(每個事務)排序次數。
每秒(每個事務)登錄數據庫次數。
每秒(每個事務)SQL語句執行次數。包括了用戶執行的SQL語句與系統執行的SQL語句,表示一個系統SQL語句的繁忙程度。
每秒的事務數。表示一個系統的事務繁忙程度。目前已知的最繁忙的系統為淘寶的在線交易系統,這個值達到了1000。
表示邏輯讀用于只讀而不是修改的塊的比例。如果有很多PLSQL,那么就會比較高。
看回滾率是不是很高,因為回滾很耗資源。
遞歸調用SQL的比例,在PL/SQL上執行的SQL稱為遞歸的SQL。
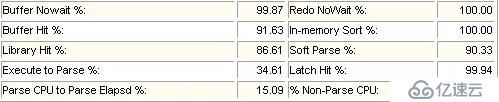
這個部分是內存效率的統計信息。對于OLTP系統而言,這些值都應該盡可能地接近100%。對于OLAP系統而言,意義不太大。因為在OLAP系統中,大查詢的速度才是對性能影響的最大因素。
非等待方式獲取數據塊的百分比。
這個值偏小,說明發生SQL訪問數據塊時數據塊正在被別的會話讀入內存,需要等待這個操作完成。發生這樣的事情通常就是某些數據塊變成了熱塊。
Buffer Nowait<99%說明,有可能是有熱塊(查找x$bh的 tch和v$latch_children的cache buffers chains)。
非等待方式獲取redo數據百分比。
數據緩沖命中率,表示了數據塊在數據緩沖區中的命中率。
Buffer Hit<95%,可能是要加db_cache_size,但是大量的非選擇的索引也會造成該值很高(大量的db file sequential read)。
數據塊在內存中排序的百分比。總排序中包括內存排序和磁盤排序。當內存中排序空間不足時,使用臨時表空間進行排序,這個是內存排序對總排序的百分比。
過低說明有大量排序在臨時表空間進行。在oltp環境下,最好是100%。如果太小,可以調整PGA參數。
共享池中SQL解析的命中率。
Library Hit<95%,要考慮加大共享池,綁定變量,修改cursor_sharing等。
軟解析占總解析數的百分比。可以近似當作sql在共享區的命中率。
這個數值偏低,說明系統中有些SQL沒有重用,最優可能的原因就是沒有使用綁定變量。
<95%:需要考慮到綁定
<80%:那么就可能sql基本沒有被重用
執行次數對分析次數的百分比。
如果該值偏小,說明解析(硬解析和軟解析)的比例過大,快速軟解析比例小。根據實際情況,可以適當調整參數session_cursor_cache,以提高會話中sql執行的命中率。
round(100*(1-:prse/:exe),2) 即(Execute次數 - Parse次數)/Execute次數 x 100%
prse = select value from v$sysstat where name = 'parse count (total)';
exe = select value from v$sysstat where name = 'execute count';沒綁定的話導致不能重用也是一個原因,當然sharedpool太小也有可能,單純的加session_cached_cursors也不是根治的辦法,不同的sql還是不能重用,還要解析。即使是soft parse 也會被統計入 parse count,所以這個指標并不能反應出fast soft(pga 中)/soft (shared pool中)/hard (shared pool 中新解析) 幾種解析的比例。只有在pl/sql的類似循環這種程序中使用使用變量才能避免大量parse,所以這個指標跟是否使用bind并沒有必然聯系增加session_cached_cursors 是為了在大量parse的情況下把soft轉化為fast soft而節約資源。
latch的命中率。
其值低是因為shared_pool_size過大或沒有使用綁定變量導致硬解析過多。要確保>99%,否則存在嚴重的性能問題,比如綁定等會影響該參數。
解析總時間中消耗CPU的時間百分比。即:100*(parse time cpu / parse time elapsed)
解析實際運行事件/(解析實際運行時間+解析中等待資源時間),越高越好。
CPU非分析時間在整個CPU時間的百分比。
100*(parse time cpu / parse time elapsed)= Parse CPU to Parse Elapsd %
查詢實際運行時間/(查詢實際運行時間+sql解析時間),太低表示解析消耗時間過多。

共享池內存使用率。
應該穩定在70%-90%間,太小浪費內存,太大則內存不足。
執行次數大于1的SQL比率。
若太小可能是沒有使用綁定變量。
執行次數大于1的SQL消耗內存/所有SQL消耗的內存(即memory for sql with execution > 1)。
這一部分只在有RAC環境下才會出現,是一些全局內存中數據發送、接收方面的性能指標,還有一些全局鎖的信息。除非這個數據庫在運行正常是設定了一個基線作為參照,否則很難從這部分數據中直接看出性能問題。
Oracle公司經驗,下面GCS和GES各項指標中,凡是與時間相關的指標,只要GCS指標低于10ms,GES指標低于15ms,則一般表示節點間通訊效率正常。但是,即便時間指標正常,也不表示應用本身或應用在RAC部署中沒有問題。
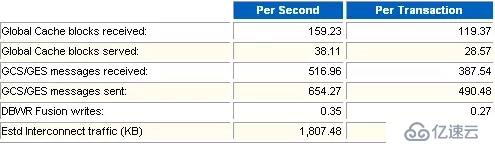

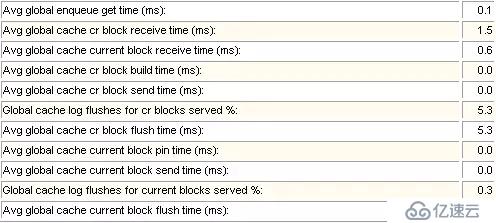


*如果CR的%Busy很大,說明節點間存在大量的塊爭用。
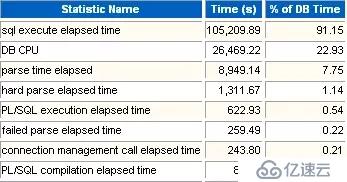
這部分信息列出了各種操作占用的數據庫時間比例。
通過這兩個指標的對比,可以看出硬解析占整個的比例。如果很高,就說明存在大量硬解析。
花費在非解析上CPU消耗占整個CPU消耗的比例。反之,則可以看出解析占用情況。如果很高,也可以反映出解析過多(進一步可以看看是否是硬解析過多)。
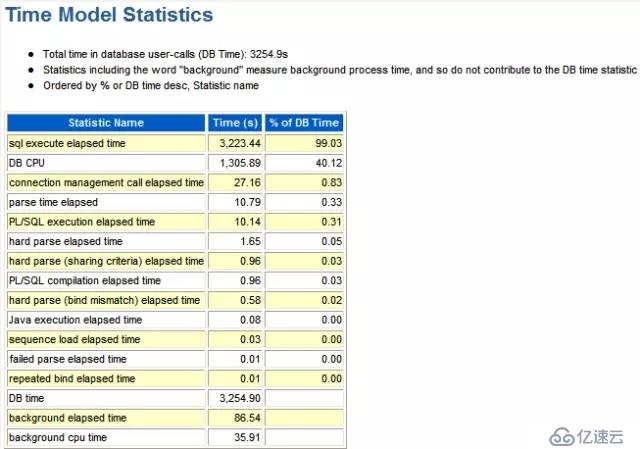
Total DB CPU = DB CPU + background cpu time = 1305.89 + 35.91 = 1341.8 seconds
再除以總的 BUSY_TIME + IDLE_TIME
% Total CPU = 1341.8/1941.76 = 69.1%,這剛好與上面Report的值相吻合。
其實,在Load Profile部分,我們也可以看出DB對系統CPU的資源利用情況。
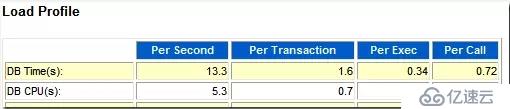
用DB CPU per Second除以CPU Count就可以得到DB在前臺所消耗的CPU%了。
這里 5.3/8 = 66.25 %
比69.1%稍小,說明DB在后臺也消耗了大約3%的CPU。
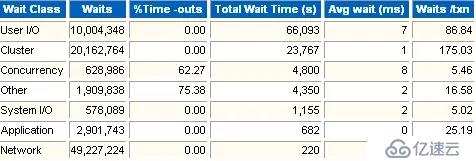
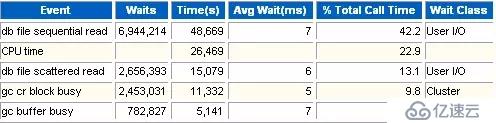
這一部分是等待的類型。可以看出那類等待占用的時間最長。
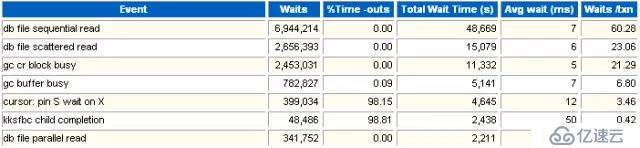
這一部分是整個實例等待事件的明細,它包含了TOP 5等待事件的信息。
%Time-outs: 超時百分比(超時依據不太清楚?)
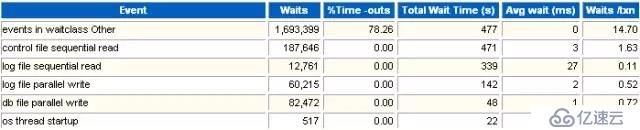
這一部分是實例后臺進程的等待事件。如果我們懷疑那個后臺進程(比如DBWR)無法及時響應,可以在這里確認一下是否有后臺進程等待時間過長的事件存在。
如果關注數據庫的性能,那么當拿到一份AWR報告的時候,最想知道的第一件事情可能就是系統資源的利用情況了,而首當其沖的,就是CPU。而細分起來,CPU可能指的是:
OS級的User%, Sys%, Idle%
DB所占OS CPU資源的Busy%
如果數據庫的版本是11g,那么很幸運的,這些信息在AWR報告中一目了然:
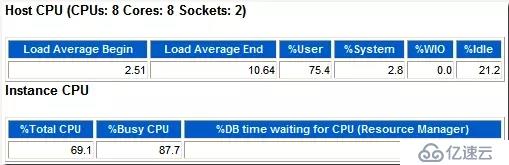
OS級的%User為75.4,%Sys為2.8,%Idle為21.2,所以%Busy應該是78.8。
DB占了OS CPU資源的69.1,%Busy CPU則可以通過上面的數據得到:%Busy CPU = %Total CPU/(%Busy) 100 = 69.1/78.8 100 = 87.69,和報告的87.7相吻合。
如果是10g,則需要手工對Report里的一些數據進行計算了。Host CPU的結果來源于DBA_HIST_OSSTAT,AWR報告里已經幫忙整出了這段時間內的絕對數據(這里的時間單位是厘秒-也就是1/100秒)。
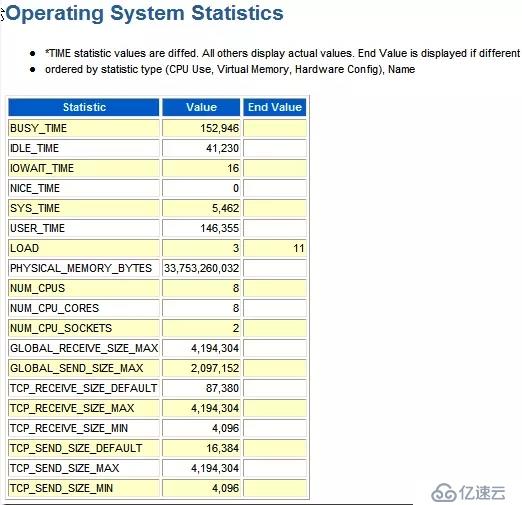
%User = USER_TIME/(BUSY_TIME+IDLE_TIME)*100 = 146355/(152946+41230)*100 = 75.37
%Sys = SYS_TIME/(BUSY_TIME+IDLE_TIME)*100
%Idle = IDLE_TIME/(BUSY_TIME+IDLE_TIME)*100這里已經隱含著這個AWR報告所捕捉的兩個snapshot之間的時間長短了。有下面的公式。正確的理解這個公式可以對系統CPU資源的使用及其度量的方式有更深一步的理解。
BUSY_TIME + IDLE_TIME = ELAPSED_TIME * CPU_COUNT推算出:ELAPSED_TIME = (152946+41230)/8/100 = 242.72 seconds //這是正確的。
至于DB對CPU的利用情況,這就涉及到10g新引入的一個關于時間統計的視圖 - v$sys_time_model。簡單而言,Oracle采用了一個統一的時間模型對一些重要的時間指標進行了記錄,具體而言,這些指標包括:
1) background elapsed time
2) background cpu time
3) RMAN cpu time (backup/restore)
1) DB time
2) DB CPU
2) connection management call elapsed time
2) sequence load elapsed time
2) sql execute elapsed time
2) parse time elapsed
3) hard parse elapsed time
4) hard parse (sharing criteria) elapsed time
5) hard parse (bind mismatch) elapsed time
3) failed parse elapsed time
4) failed parse (out of shared memory) elapsed time
2) PL/SQL execution elapsed time
2) inbound PL/SQL rpc elapsed time
2) PL/SQL compilation elapsed time
2) Java execution elapsed time
2) repeated bind elapsed time我們這里關注的只有和CPU相關的兩個: background cpu time 和 DB CPU。這兩個值在AWR里面也有記錄。

這一部分是按照SQL執行時間從長到短的排序。
SQL語句執行用總時長,此排序就是按照這個字段進行的。注意該時間不是單個SQL跑的時間,而是監控范圍內SQL執行次數的總和時間。單位時間為秒。Elapsed Time = CPU Time + Wait Time
為SQL語句執行時CPU占用時間總時長,此時間會小于等于Elapsed Time時間。單位時間為秒。
SQL語句在監控范圍內的執行次數總計。如果Executions=0,則說明語句沒有正常完成,被中間停止,需要關注。
執行一次SQL的平均時間。單位時間為秒。
為SQL的Elapsed Time時間占數據庫總時間的百分比。
SQL語句的ID編號,點擊之后就能導航到下邊的SQL詳細列表中,點擊IE的返回可以回到當前SQL ID的地方。
顯示該SQL是用什么方式連接到數據庫執行的,如果是用SQL*Plus或者PL/SQL鏈接上來的那基本上都是有人在調試程序。一般用前臺應用鏈接過來執行的sql該位置為空。
簡單的SQL提示,詳細的需要點擊SQL ID。
如果看到SQL語句執行時間很長,而CPU時間很少,則說明SQL在I/O操作時(包括邏輯I/O和物理I/O)消耗較多。可以結合前面I/O方面的報告以及相關等待事件,進一步分析是否是I/O存在問題。當然SQL的等待時間主要發生在I/O操作方面,不能說明系統就存在I/O瓶頸,只能說SQL有大量的I/O操作。
如果SQL語句執行次數很多,需要關注一些對應表的記錄變化。如果變化不大,需要從前面考慮是否大多數操作都進行了Rollback,導致大量的無用功。

記錄了執行占CPU時間總和時間最長的TOP SQL(請注意是監控范圍內該SQL的執行占CPU時間總和,而不是單次SQL執行時間)。這部分是SQL消耗的CPU時間從高到底的排序。
SQL消耗的CPU時間。
SQL執行時間。
SQL執行次數。
每次執行消耗CPU時間。
SQL執行時間占總共DB time的百分比。

這部分列出SQL獲取的內存數據塊的數量,按照由大到小的順序排序。buffer get其實就是邏輯讀或一致性讀。在sql 10046里面,也叫query read。表示一個語句在執行期間的邏輯IO,單位是塊。在報告中,該數值是一個累計值。Buffer Get=執行次數 * 每次的buffer get。記錄了執行占總buffer gets(邏輯IO)的TOP SQL(請注意是監控范圍內該SQL的執行占Gets總和,而不是單次SQL執行所占的Gets)。
SQL執行獲得的內存數據塊數量。
SQL執行次數。
每次執行獲得的內存數據塊數量。
占總數的百分比。
消耗的CPU時間。
SQL執行時間。
因為statspack/awr列出的是總體的top buffer,它們關心的是總體的性能指標,而不是把重心放在只執行一次的語句上。為了防止過大,采用了以下原則。如果有sql沒有使用綁定變量,執行非常差但是由于沒有綁定,因此系統人為是不同的sql。有可能不會被列入到這個列表中。
大于閥值buffer_gets_th的數值,這是sql執行緩沖區獲取的數量(默認10000)。
小于define top_n_sql=65的數值。

這部分列出了SQL執行物理讀的信息,按照從高到低的順序排序。記錄了執行占總磁盤物理讀(物理IO)的TOP SQL(請注意是監控范圍內該SQL的執行占磁盤物理讀總和,而不是單次SQL執行所占的磁盤物理讀)。
SQL物理讀的次數。
SQL執行次數。
SQL每次執行產生的物理讀。
占整個物理讀的百分比。
SQL執行消耗的CPU時間。
SQL的執行時間。

這部分列出了SQL執行次數的信息,按照從大到小的順序排列。如果是OLTP系統的話,這部分比較有用。因此SQL執行頻率非常大,SQL的執行次數會對性能有比較大的影響。OLAP系統因為SQL重復執行的頻率很低,因此意義不大。
SQL的執行次數。
SQL處理的記錄數。
SQL每次執行處理的記錄數。
每次執行消耗的CPU時間。
每次執行的時長。

這部分列出了SQL按分析次(軟解析)數的信息,按照從高到底的順序排列。這部分對OLTP系統比較重要,這里列出的總分析次數并沒有區分是硬分析還是軟分析。但是即使是軟分析,次數多了,也是需要關注的。這樣會消耗很多內存資源,引起latch的等待,降低系統的性能。軟分析過多需要檢查應用上是否有頻繁的游標打開、關閉操作。
SQL分析的次數。
SQL執行的次數。
占整個分析次數的百分比。
記錄了SQL占用library cache的大小的TOP SQL。
占用library cache的大小。單位是byte。

這部分列出了SQL多版本的信息。記錄了SQL的打開子游標的TOP SQL。一個SQL產生多版本的原因有很多,可以查詢視圖v$sql_sahred_cursor視圖了解具體原因。對于OLTP系統,這部分值得關注,了解SQL被重用的情況。
SQL的版本數。
SQL的執行次數。
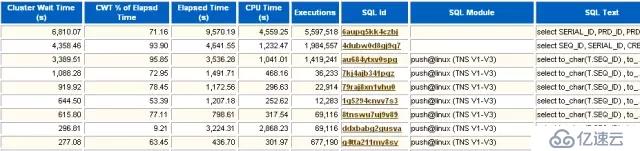
記錄了集群的等待時間的TOP SQL。這部分只在RAC環境中存在,列出了實例之間共享內存數據時發生的等待。在RAC環境下,幾個實例之間需要有一種鎖的機制來保證數據塊版本的一致性,這就出現了一類新的等待事件,發生在RAC實例之間的數據訪問等待。對于RAC結構,還是采用業務分隔方式較好。這樣某個業務固定使用某個實例,它訪問的內存塊就會固定地存在某個實例的內存中,這樣降低了實例之間的GC等待事件。此外,如果RAC結構采用負載均衡模式,這樣每個實例都會被各種應用的會話連接,大量的數據塊需要在各個實例的內存中被拷貝和鎖定,會加劇GC等待事件。
集群等待時長。
集群操作等待時長占總時長的百分比。
SQL執行總時長。

這部分是上面各部分涉及的SQL的完整文本。
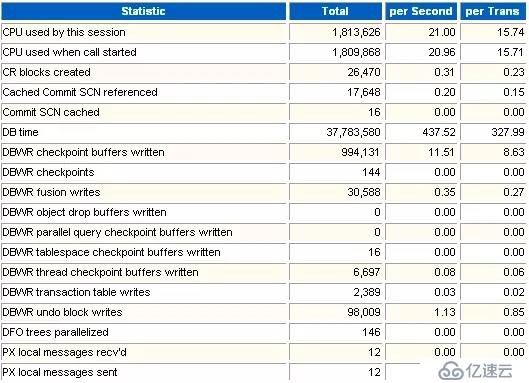
這部分是實例的信息統計,項目非常多。對于RAC架構的數據庫,需要分析每個實例的AWR報告,才能對整體性能做出客觀的評價。
這個指標用來上面在當前的性能采集區間里面,Oracle消耗的CPU單位。一個CPU單位是1/100秒。從這個指標可以看出CPU的負載情況。

在TOP5等待事件里,找到"CPU time",可以看到系統消耗CPU的時間為26469秒。

在實例統計部分,可以看到整個過程消耗了1813626個CPU單位。每秒鐘消耗21個CPU單位,對應實際的時間就是0.21秒。也就是每秒鐘CPU的處理時間為0.21秒。
系統內CPU個數為8。每秒鐘每個CPU消耗是21/8=2.6(個CPU單位)。在一秒鐘內,每個CPU處理時間就是2.6/100=0.026秒。

*總體來看,當前數據庫每秒鐘每個CPU處理時間才0.026秒,遠遠算不上高負荷。數據庫CPU資源很豐富,遠沒有出現瓶頸。
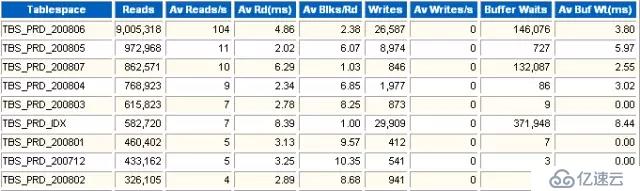
表空間的I/O性能統計。
發生了多少次物理讀。
每秒鐘物理讀的次數。
平均一次物理讀的時間(毫秒)。一個高相應的磁盤的響應時間應當在10ms以內,最好不要超過20ms;如果達到了100ms,應用基本就開始出現嚴重問題甚至不能正常運行。
每次讀多少個數據塊。
發生了多少次寫。
每秒鐘寫的次數。
獲取內存數據塊等待的次數。
獲取內存數據塊平均等待時間。
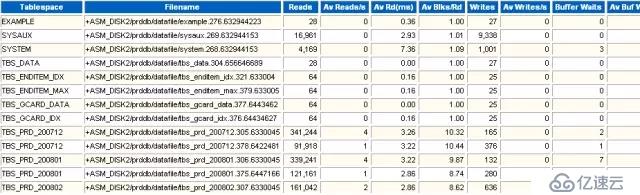
文件級別的I/O統計。
顧問信息。這塊提供了多種顧問程序,提出在不同情況下的模擬情況。包括databuffer、pga、shared pool、sga、stream pool、java pool等的情況。
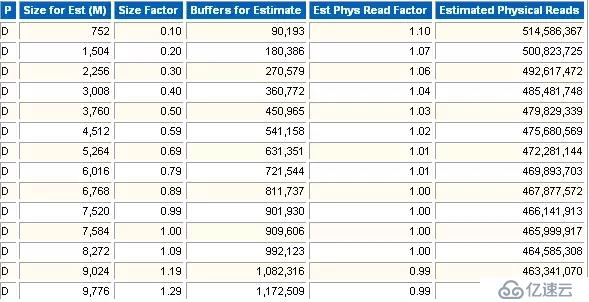
Buffer pool的大小建議。
Oracle估算Buffer pool的大小。
估算值與實際值的比例。如果0.9就表示估算值是實際值的0.9倍。1.0表示buffer pool的實際大小。
估算的Buffer的大小(數量)。
估算的物理讀的影響因子,是估算物理讀和實際物理讀的一個比例。1.0表示實際的物理讀。
估計的物理讀次數。
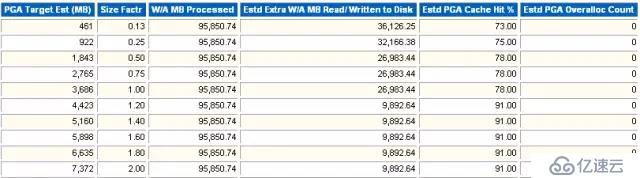
PGA的大小建議。
PGA的估算大小。
影響因子,作用和buffer pool advisory中相同。
Oracle為了產生影響估算處理的數據量。
處理數據中需要物理讀寫的數據量。
估算的PGA命中率。
需要在估算的PGA大小下額外分配內存的個數。

建議器通過設置不同的共享池大小,來獲取相應的性能指標值。
估算的共享池大小。
共享池大小的影響因子。
估算的庫高速緩存占用的大小。
高速緩存中的對象數。
需要額外將對象讀入共享池的時間。
對象讀入共享池時間的影響因子。
表示每一個模擬的shared pool大小對重新將對象讀入共享池的影響情況。當這個值的變化很小或不變的時候,增加shared pool的大小就意義不大。
分析所花費的時間。
分析花費時間的影響因子。
內存中對象被發現的次數。
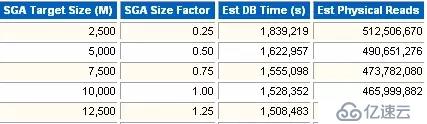
建議器對SGA整體的性能的一個建議。
估算的SGA大小。
SGA大小的影響因子。
估算的SGA大小計算出的DB Time。
物理讀的次數。

表示愿意等待類型的latch的統計信息。
表示不愿意等待類型的latch的統計信息。
比例最好接近0。

段的邏輯讀情況。
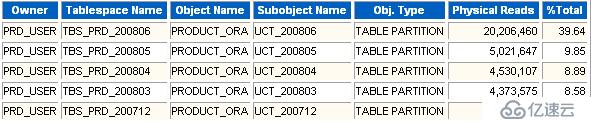
段的物理讀情況。

從這部分可以發現那些對象訪問頻繁。Buffer Busy Waits事件通常由于某些數據塊太過頻繁的訪問,導致熱點塊的產生。
AWR報告Segment Statistics部分的Segments by Row Lock Waits,非常容易引起誤解,它包含的不僅僅是事務的行級鎖等待,還包括了索引分裂的等待。之前我一直抱怨為什么v$segment_statistics中沒有統計段級別的索引分裂計數,原來ORACLE已經實現了。但是統計進這個指標中,你覺得合適嗎?
對SQL語句來講,只有當它執行完畢之后,它的相關信息才會被Oracle所記錄(比如:CPU時間、SQL執行時長等)。當時當某個SQL終止于做AWR報告選取的2個快照間隔時間之后,那么它的信息就不能被這個AWR報告反映出來。盡管它在采樣周期里面的運行,也消耗了很多資源。
也就是說某個區間的性能報告并不能精確地反映出在這個采樣周期中資源的消耗情況。因為有些在這個區間運行的SQL可能結束于這個時間周期之后,也可能有一些SQL在這個周期開始之前就已經運行了很久,恰好結束于這個采樣周期。這些因素都導致了采樣周期里面的數據并不絕對是這個時間段發生的所有數據庫操作的資源使用的數據。
作者:韓鋒
來源:宜信技術學院
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





