溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
從事Oracle相關的工作,從最初的一臉懵逼到現在的略有所知,也來總結一下自己最近學習關于Oracle中SQL語句的執行計劃的相關內容。下面是文章的目錄結構:


執行計劃是一條查詢語句在Oracle中的執行過程或訪問路徑的描述
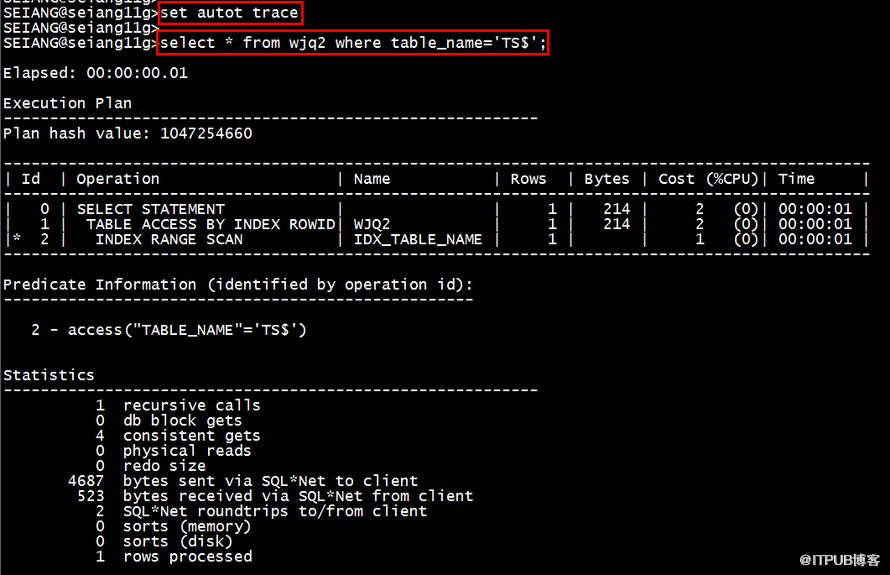
在sql*plus中,執行如下命令:
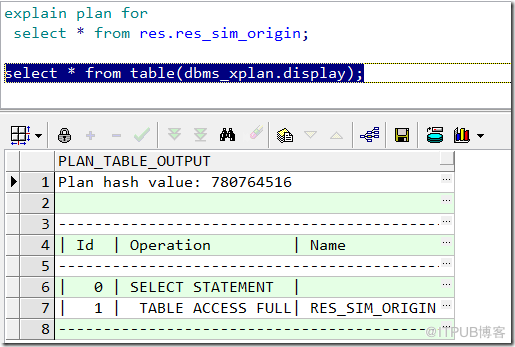
1)explain plan for select * from XXXX;
2)select * from table(dbms_xplan.display);

語法:SET AUTOT[RACE] {OFF | ON | TRACE[ONLY]} [EXP[LAIN]] [STAT[ISTICS]]
|
序號 |
命令 |
解釋 |
|
1 |
SET AUTOTRACE OFF |
此為默認值,即關閉Autotrace |
|
2 |
SET AUTOTRACE ON EXPLAIN |
只顯示執行計劃 |
|
3 |
SET AUTOTRACE ON STATISTICS |
只顯示執行的統計信息 |
|
4 |
SET AUTOTRACE ON |
包含2,3兩項內容 |
|
5 |
SET AUTOTRACE TRACEONLY |
與ON相似,但不顯示語句的執行結果 |
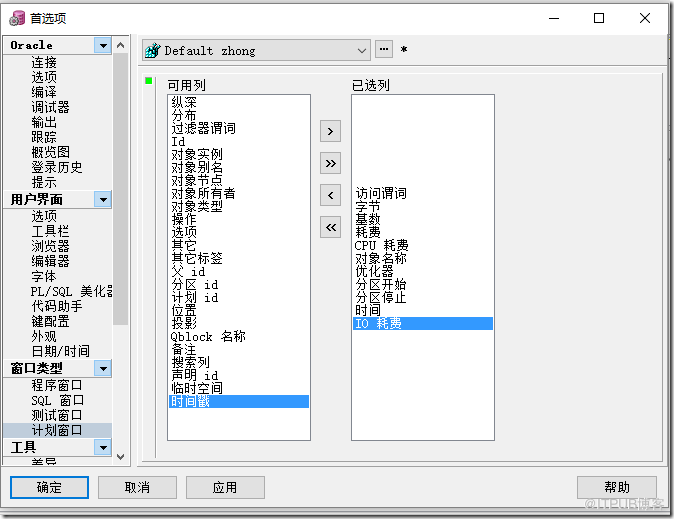
工具—>首選項 —>窗口類型—>計劃窗口—>根據需要配置要顯示在執行計劃中的列
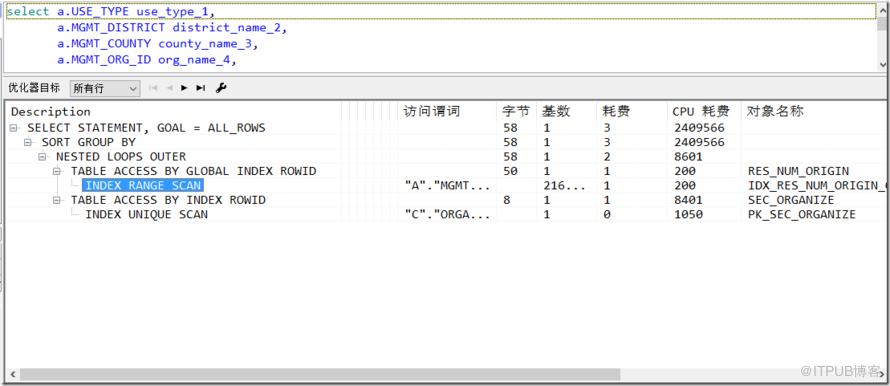
執行計劃的常用列字段解釋:
基數(Rows):Oracle估計的當前操作的返回結果集行數
字節(Bytes):執行該步驟后返回的字節數
耗費(COST)、CPU耗費:Oracle估計的該步驟的執行成本,用于說明SQL執行的代價,理論上越小越好(該值可能與實際有出入)
時間(Time):Oracle估計的當前操作所需的時間
在SQL窗口執行完一條select語句后按 F5 即可查看剛剛執行的這條查詢語句的執行計劃
注:在PLSQL中使用SQL命令查看執行計劃的話,某些SQL*PLUS命令PLSQL無法支持,比如SET AUTOTRACE ON
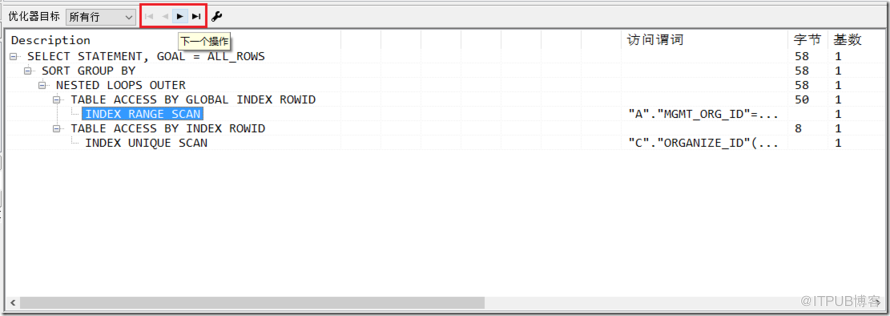
根據Operation縮進來判斷,縮進最多的最先執行;(縮進相同時,最上面的最先執行)
例:上圖中 INDEX RANGE SCAN 和 INDEX UNIQUE SCAN 兩個動作縮進最多,最上面的 INDEX RANGE SCAN 先執行;
同一級如果某個動作沒有子ID就最先執行
同一級的動作執行時遵循最上最右先執行的原則
例:上圖中 TABLE ACCESS BY GLOBAL INDEX ROWID 和 TABLE ACCESS BY INDEX ROWID 兩個動作縮進都在同一級,則位于上面的 TABLE ACCESS BY GLOBAL INDEX ROWID 這個動作先執行;這個動作又包含一個子動作 INDEX RANGE SCAN,則位于右邊的子動作 INDEX RANGE SCAN 先執行;
圖示中的SQL執行順序即為:
INDEX RANGE SCAN —> TABLE ACCESS BY GLOBAL INDEX ROWID —> INDEX UNIQUE SCAN —> TABLE ACCESS BY INDEX ROWID —> NESTED LOOPS OUTER —> SORT GROUP BY —> SELECT STATEMENT, GOAL = ALL_ROWS
(注:PLSQL提供了查看執行順序的功能按鈕(上圖中的紅框部分) )
●TABLE ACCESS FULL(全表掃描)
●TABLE ACCESS BY ROWID(通過ROWID的表存取)
●TABLE ACCESS BY INDEX SCAN(索引掃描)
(1)TABLE ACCESS FULL(全表掃描):
Oracle會讀取表中所有的行,并檢查每一行是否滿足SQL語句中的 Where 限制條件;全表掃描時可以使用多塊讀(即一次I/O讀取多塊數據塊)操作,提升吞吐量;
使用建議:數據量太大的表不建議使用全表掃描,除非本身需要取出的數據較多,占到表數據總量的 5% ~ 10% 或以上
(2)TABLE ACCESS BY ROWID(通過ROWID的表存取):
先說一下什么是ROWID?
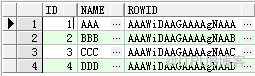
ROWID是由Oracle自動加在表中每行最后的一列偽列,既然是偽列,就說明表中并不會物理存儲ROWID的值;
你可以像使用其它列一樣使用它,只是不能對該列的值進行增、刪、改操作;一旦一行數據插入后,則其對應的ROWID在該行的生命周期內是唯一的,即使發生行遷移,該行的ROWID值也不變。
讓我們再回到 TABLE ACCESS BY ROWID 來:
行的ROWID指出了該行所在的數據文件、數據塊以及行在該塊中的位置,所以通過ROWID可以快速定位到目標數據上,這也是Oracle中存取單行數據最快的方法;
(3)TABLE ACCESS BY INDEX SCAN(索引掃描):
在索引塊中,既存儲每個索引的鍵值,也存儲具有該鍵值的行的ROWID。
一個數字列上建索引后該索引可能的概念結構如下圖:
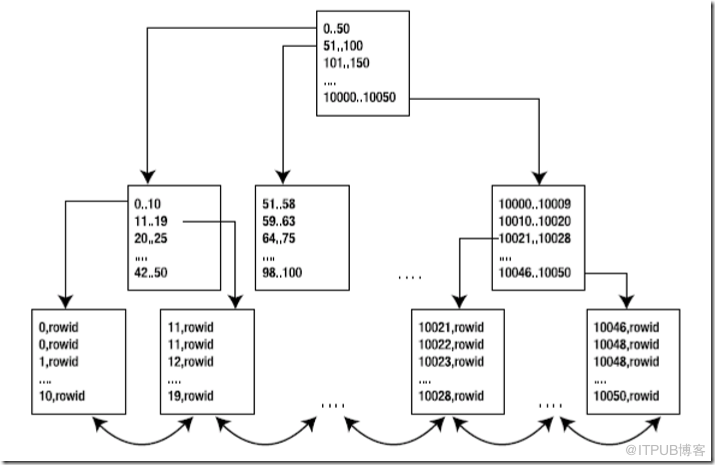
所以索引掃描其實分為兩步:
Ⅰ:掃描索引得到對應的ROWID
Ⅱ:通過ROWID定位到具體的行讀取數據
-----------------------------------索引掃描延伸--------------------------------
索引掃描又分五種:●INDEX UNIQUE SCAN(索引唯一掃描)
●INDEX RANGE SCAN(索引范圍掃描)
●INDEX FULL SCAN(索引全掃描)
●INDEX FAST FULL SCAN(索引快速掃描)
●INDEX SKIP SCAN(索引跳躍掃描)
針對唯一性索引(UNIQUE INDEX)的掃描,每次至多只返回一條記錄;
表中某字段存在 UNIQUE、PRIMARY KEY 約束時,Oracle常實現唯一性掃描;
使用一個索引存取多行數據;
發生索引范圍掃描的三種情況:
在唯一索引列上使用了范圍操作符(如:>、<、<>、>=、<=、between)
在組合索引上,只使用部分列進行查詢(查詢時必須包含前導列,否則會走全表掃描)
對非唯一索引列上進行的任何查詢
進行全索引掃描時,查詢出的數據都必須從索引中可以直接得到(注意全索引掃描只有在CBO模式下才有效)
-------------------------- 延伸閱讀:Oracle優化器簡述 -------------------------
Oracle中的優化器是SQL分析和執行的優化工具,它負責生成、制定SQL的執行計劃。
Oracle的優化器有兩種:
●RBO(Rule-Based
Optimization) 基于規則的優化器
●CBO(Cost-Based
Optimization) 基于代價的優化器
RBO:
RBO有嚴格的使用規則,只要按照這套規則去寫SQL語句,無論數據表中的內容怎樣,也不會影響到你的執行計劃;
換句話說,RBO對數據“不敏感”,它要求SQL編寫人員必須要了解各項細則;
RBO一直沿用至ORACLE 9i,從ORACLE 10g開始,RBO已經徹底被拋棄。
CBO:
CBO是一種比RBO更加合理、可靠的優化器,在ORACLE 10g中完全取代RBO;
CBO通過計算各種可能的執行計劃的“代價”,即COST,從中選用COST最低的執行方案作為實際運行方案;
它依賴數據庫對象的統計信息,統計信息的準確與否會影響CBO做出最優的選擇,也就是對數據“敏感”。
--------------------------------------------------------------------------------
掃描索引中的所有的數據塊,與 INDEX FULL SCAN 類似,但是一個顯著的區別是它不對查詢出的數據進行排序(即數據不是以排序順序被返回)
Oracle 9i后提供,有時候復合索引的前導列(索引包含的第一列)沒有在查詢語句中出現,oralce也會使用該復合索引,這時候就使用的INDEX SKIP SCAN;
什么時候會觸發 INDEX SKIP SCAN 呢?
前提條件:表有一個復合索引,且在查詢時有除了前導列(索引中第一列)外的其他列作為條件,并且優化器模式為CBO時
當Oracle發現前導列的唯一值個數很少時,會將每個唯一值都作為常規掃描的入口,在此基礎上做一次查找,最后合并這些查詢;
例如:
假設表emp有ename(雇員名稱)、job(職位名)、sex(性別)三個字段,并且建立了如create index idx_emp on emp (sex, ename, job) 的復合索引;
因為性別只有 '男' 和 '女' 兩個值,所以為了提高索引的利用率,Oracle可將這個復合索引拆成 ('男', ename, job),('女', ename, job) 這兩個復合索引;
當查詢 select * from emp where job = 'Programmer' 時,該查詢發出后:
Oracle先進入sex為'男'的入口,這時候使用到了 ('男', ename, job) 這條復合索引,查找 job = 'Programmer' 的條目;再進入sex為'女'的入口,這時候使用到了 ('女', ename, job) 這條復合索引,查找 job = 'Programmer' 的條目;
最后合并查詢到的來自兩個入口的結果集。
JOIN關鍵字用于將兩張表作連接,一次只能連接兩張表,JOIN操作的各步驟一般是串行的(在讀取做連接的兩張表的數據時可以并行讀取);
表(row source)之間的連接順序對于查詢效率有很大的影響,對首先存取的表(驅動表)先應用某些限制條件(Where過濾條件)以得到一個較小的row source,可以使得連接效率提高。
-----------延伸閱讀:驅動表(Driving Table)與匹配表(Probed Table)------------
驅動表(Driving Table):
表連接時首先存取的表,又稱外層表(Outer Table),這個概念用于NESTED LOOPS(嵌套循環)與 HASH JOIN(哈希連接)中;
如果驅動表返回較多的行數據,則對所有的后續操作有負面影響,故一般選擇小表(應用Where限制條件后返回較少行數的表)作為驅動表。
匹配表(Probed Table):
又稱為內層表(Inner Table),從驅動表獲取一行具體數據后,會到該表中尋找符合連接條件的行。故該表一般為大表(應用Where限制條件后返回較多行數的表)。
--------------------------------------------------------------------------------
●SORT MERGE JOIN(排序-合并連接)
●NESTED LOOPS(嵌套循環)
●HASH JOIN(哈希連接)
●CARTESIAN PRODUCT(笛卡爾積)
注:這里將首先存取的表稱作 row source 1,將之后參與連接的表稱作 row source 2;
(1)SORT MERGE JOIN(排序-合并連接)
假設有查詢:select a.name, b.name from table_A a join table_B b on (a.id = b.id)
內部連接過程:
a) 生成 row source 1 需要的數據,按照連接操作關聯列(如示例中的a.id)對這些數據進行排序
b) 生成 row source 2 需要的數據,按照與 a) 中對應的連接操作關聯列(b.id)對數據進行排序
c) 兩邊已排序的行放在一起執行合并操作(對兩邊的數據集進行掃描并判斷是否連接)
延伸:
如果示例中的連接操作關聯列 a.id,b.id 之前就已經被排過序了的話,連接速度便可大大提高,因為排序是很費時間和資源的操作,尤其對于有大量數據的表。
故可以考慮在 a.id,b.id 上建立索引讓其能預先排好序。不過遺憾的是,由于返回的結果集中包括所有字段,所以通常的執行計劃中,即使連接列存在索引,也不會進入到執行計劃中,除非進行一些特定列處理(如僅僅只查詢有索引的列等)。
排序-合并連接的表無驅動順序,誰在前面都可以;
排序-合并連接適用的連接條件有: <、<=、=、>、>= ,不適用的連接條件有: <>、like
(2)NESTED LOOPS(嵌套循環)
內部連接過程:
a) 取出 row source 1 的 row 1(第一行數據),遍歷 row source 2 的所有行并檢查是否有匹配的,取出匹配的行放入結果集中
b) 取出 row source 1 的 row 2(第二行數據),遍歷 row source 2 的所有行并檢查是否有匹配的,取出匹配的行放入結果集中
c) ……
若 row source 1 (即驅動表)中返回了 N 行數據,則 row source 2 也相應的會被全表遍歷 N 次。
因為 row source 1 的每一行都會去匹配 row source 2 的所有行,所以當 row source 1 返回的行數盡可能少并且能高效訪問 row source 2(如建立適當的索引)時,效率較高。
延伸:
(3)HASH JOIN(哈希連接)
哈希連接只適用于等值連接(即連接條件為 = )
HASH JOIN對兩個表做連接時并不一定是都進行全表掃描,其并不限制表訪問方式;
內部連接過程簡述:
a) 取出 row source 1(驅動表,在HASH JOIN中又稱為Build Table) 的數據集,然后將其構建成內存中的一個 Hash Table(Hash函數的Hash KEY就是連接操作關聯列),創建Hash位圖(bitmap)
b) 取出 row source 2(匹配表)的數據集,對其中的每一條數據的連接操作關聯列使用相同的Hash函數并找到對應的 a) 里的數據在 Hash Table 中的位置,在該位置上檢查能否找到匹配的數據
----------------------------延伸閱讀:Hash Table相關---------------------------
來自Wiki的解釋:
In
computing, a hash table (hash map) is a data structure used to implement an
associative array, a structure that can map keys to values. A hash table uses a
hash function to compute an index into an array
of buckets or slots, from which the desired value can be found.
散列(hash)技術:在記錄的存儲位置和記錄具有的關鍵字key之間建立一個對應關系 f ,使得輸入key后,可以得到對應的存儲位置 f(key),這個對應關系 f 就是散列(哈希)函數;
采用散列技術將記錄存儲在一塊連續的存儲空間中,這塊連續的存儲空間就是散列表(哈希表)
不同的key經同一散列函數散列后得到的散列值理論上應該不同,但是實際中有可能相同,相同時即是發生了散列(哈希)沖突,解決散列沖突的辦法有很多,比如HashMap中就是用鏈地址法來解決哈希沖突;
哈希表是一種面向查找的數據結構,在輸入給定值后查找給定值對應的記錄在表中的位置以獲取特定記錄這個過程的速度很快。
-------------------------------------------------------------------------------
HASH JOIN的三種模式:
●OPTIMAL HASH JOIN
●ONEPASS HASH JOIN
●MULTIPASS HASH JOIN
1) OPTIMAL HASH JOIN
OPTIMAL 模式是從驅動表(也稱Build Table)上獲取的結果集比較小,可以把根據結果集構建的整個Hash Table都建立在用戶可以使用的內存區域里。
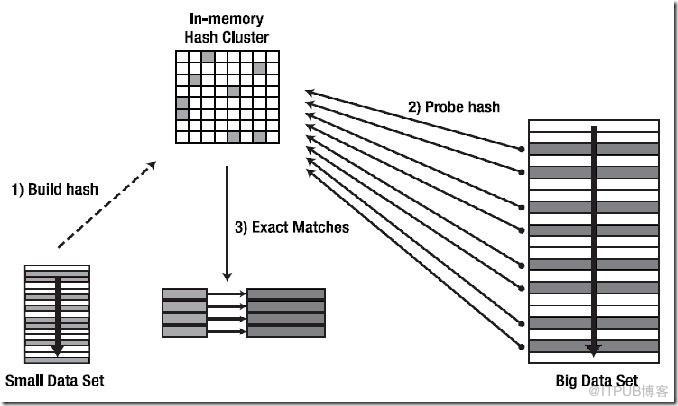
連接過程簡述:
Ⅰ:首先對Build Table內各行數據的連接操作關聯列使用Hash函數,把Build Table的結果集構建成內存中的Hash Table。如圖所示,可以把Hash Table看作內存中的一塊大的方形區域,里面有很多的小格子,Build Table里的數據就分散分布在這些小格子中,而這些小格子就是Hash Bucket(見上面Wiki的定義)。
Ⅱ:開始讀取匹配表(Probed Table)的數據,對其中每行數據的連接操作關聯列都使用同上的Hash函數,定位Build Table里使用Hash函數后具有相同值數據所在的Hash Bucket。
Ⅲ:定位到具體的Hash Bucket后,先檢查Bucket里是否有數據,沒有的話就馬上丟掉匹配表(Probed Table)的這一行。如果里面有數據,則繼續檢查里面的數據(驅動表的數據)是否和匹配表的數據相匹配。
2) ONEPASS HASH JOIN
從驅動表(也稱Build Table)上獲取的結果集較大,無法將根據結果集構建的Hash Table全部放入內存中時,會使用 ONEPASS 模式。
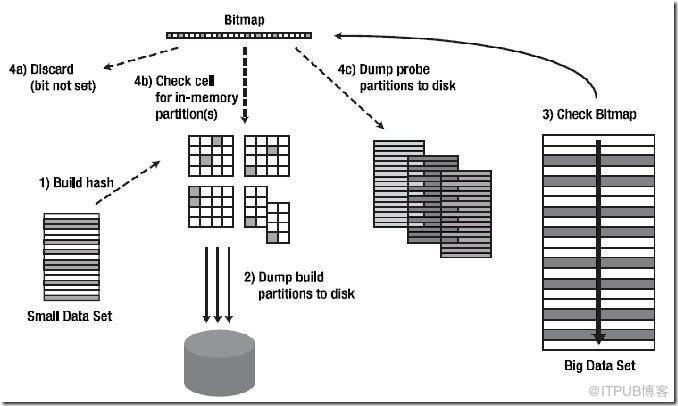
連接過程簡述:
Ⅰ:對Build Table內各行數據的連接操作關聯列使用Hash函數,根據Build Table的結果集構建Hash Table后,由于內存無法放下所有的Hash Table內容,將導致有的Hash Bucket放在內存里,有的Hash Bucket放在磁盤上,無論放在內存里還是磁盤里,Oracle都使用一個Bitmap結構來反映這些Hash Bucket的狀態(包括其位置和是否有數據)。
Ⅱ:讀取匹配表數據并對每行的連接操作關聯列使用同上的Hash函數,定位Bitmap上Build Table里使用Hash函數后具有相同值數據所在的Bucket。如果該Bucket為空,則丟棄匹配表的這條數據。如果不為空,則需要看該Bucket是在內存里還是在磁盤上。
如果在內存中,就直接訪問這個Bucket并檢查其中的數據是否匹配,有匹配的話就返回這條查詢結果。
如果在磁盤上,就先把這條待匹配數據放到一邊,將其先暫存在內存里,等以后積累了一定量的這樣的待匹配數據后,再批量的把這些數據寫入到磁盤上(上圖中的 Dump probe partitions to disk)。
Ⅲ:當把匹配表完整的掃描了一遍后,可能已經返回了一部分匹配的數據了。接下來還有Hash Table中一部分在磁盤上的Hash Bucket數據以及匹配表中部分被寫入到磁盤上的待匹配數據未處理,現在Oracle會把磁盤上的這兩部分數據重新匹配一次,然后返回最終的查詢結果。
3) MULTIPASS HASH JOIN
當內存特別小或者相對而言Hash Table的數據特別大時,會使用 MULTIPASS 模式。MULTIPASS會多次讀取磁盤數據,應盡量避免使用該模式。
●INNER JOIN(內連接)
●OUTER JOIN(外連接)
通過下面的示例進行演示:
現有test1、test2兩表,test1和test2表信息如下:
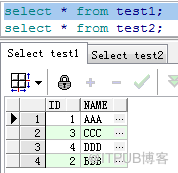
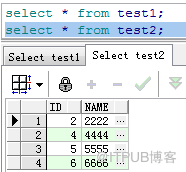
下面的例子都用test1、test2兩表來演示。
(1) INNER JOIN(內連接)只返回兩表中相匹配的記錄。
INNER JOIN 又分為兩種:
等值連接(連接條件為 = )
非等值連接(連接條件為 非 = ,如 > >= < <= 等)
等值連接用的最多,下面以等值連接舉例:
內連接的兩種寫法:
Ⅰ:select a.id ID1, a.name NAME1, b.id ID2, b.name NAME2 from test1 a inner join test2 b on (a.id = b.id);
Ⅱ:select a.id ID1, a.name NAME1, b.id ID2, b.name NAME2 from test1 a join test2 b on (a.id = b.id);
連接時只返回滿足連接條件(test1.id = test2.id)的記錄:
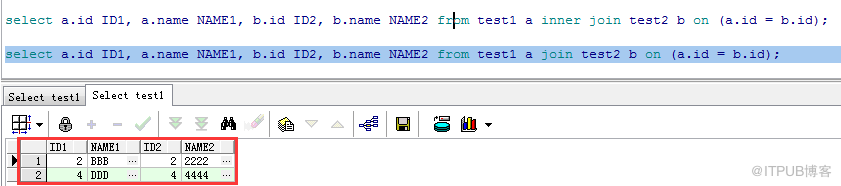
(2)OUTER JOIN(外連接):
OUTER JOIN 分為三種:
●LEFT OUTER JOIN(可簡寫為 LEFT JOIN,左外連接)
●RIGHT OUTER JOIN( RIGHT JOIN,右外連接)
●FULL OUTER JOIN( FULL JOIN,全外連接)
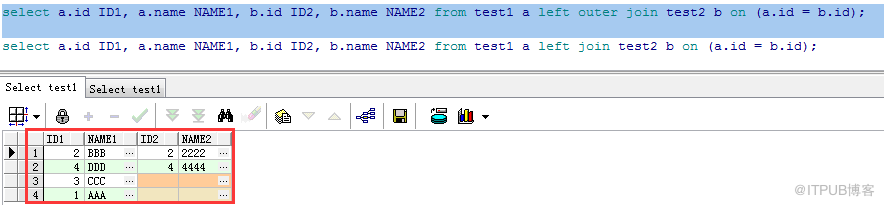
a)LEFT JOIN(左連接):
返回的結果不僅包含符合連接條件的記錄,還包含左邊表中的全部記錄。(若返回的左表中某行記錄在右表中沒有匹配項,則右表中的返回列均為空值)
兩種寫法:
Ⅰ:select a.id ID1, a.name NAME1, b.id ID2, b.name NAME2 from test1 a left outer join test2 b on (a.id = b.id);
Ⅱ:select a.id ID1, a.name NAME1, b.id ID2, b.name NAME2 from test1 a left join test2 b on (a.id = b.id);
返回結果:
b)RIGHT JOIN(右連接):
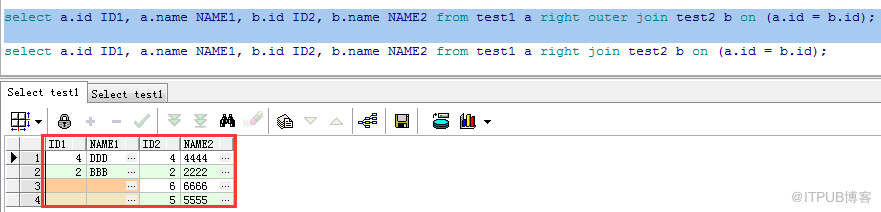
返回的結果不僅包含符合連接條件的記錄,還包含右邊表中的全部記錄。(若返回的右表中某行記錄在左表中沒有匹配項,則左表中的返回列均為空值)
兩種寫法:
Ⅰ:select a.id ID1, a.name NAME1, b.id ID2, b.name NAME2 from test1 a right outer join test2 b on (a.id = b.id);
Ⅱ:select a.id ID1, a.name NAME1, b.id ID2, b.name NAME2 from test1 a right join test2 b on (a.id = b.id);
返回結果:
c)FULL JOIN(全連接):
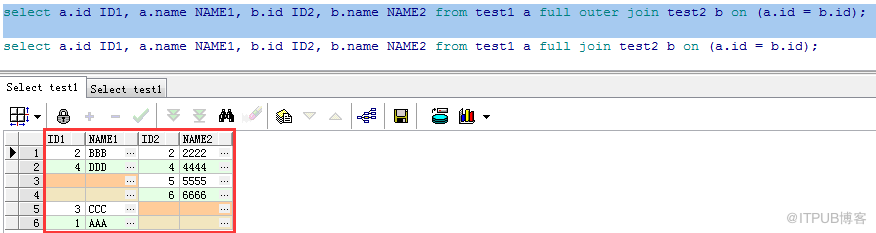
返回左右兩表的全部記錄。(左右兩邊不匹配的項都以空值代替)
兩種寫法:
Ⅰ:select a.id ID1, a.name NAME1, b.id ID2, b.name NAME2 from test1 a full outer join test2 b on (a.id = b.id);
Ⅱ:select a.id ID1, a.name NAME1, b.id ID2, b.name NAME2 from test1 a full outer join test2 b on (a.id = b.id);
返回結果:
------------------------------延伸閱讀:(+) 操作符-----------------------------
(+)
操作符是Oracle特有的表示法,用來表示外連接(只能表示
左外、右外 連接),需要配合Where語句使用。
特別注意:(+) 操作符在左表的連接條件上表示右連接,在右表的連接條件上表示左連接。
如:
Ⅰ:select a.id ID1, a.name NAME1, b.id ID2, b.name NAME2
from test1 a,test2 b where a.id = b.id(+);
查詢結果:
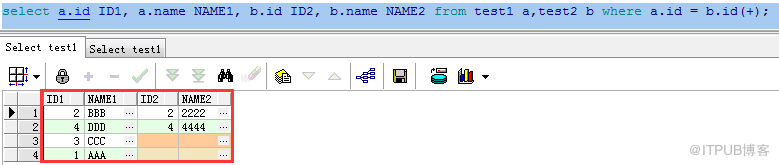
實際與左連接select a.id ID1, a.name NAME1, b.id ID2, b.name NAME2 from test1 a
left join test2 b on (a.id = b.id);效果等價
Ⅱ:select a.id ID1, a.name NAME1, b.id ID2, b.name NAME2 from test1
a,test2 b where a.id(+) = b.id;
查詢結果:

實際與右連接select a.id ID1, a.name NAME1, b.id ID2, b.name NAME2 from test1 a
right join test2 b on (a.id = b.id);效果等價
-------------------------------------------------------------------------------
補充:自連接
通過給一個表賦兩個不同的別名讓其與自身內連或外連接
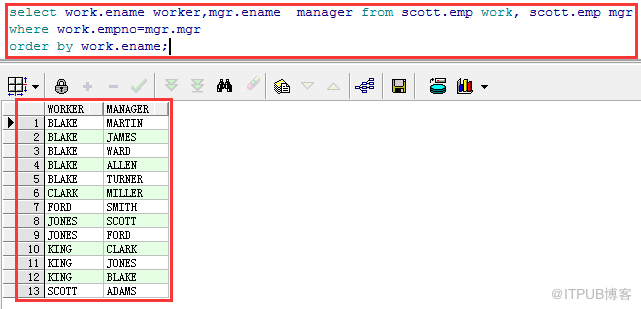
在oracle的scott的schema中有一個表是emp。在emp中的每一個員工都有自己的mgr(經理),并且每一個經理自身也是公司的員工,自身也有自己的經理。
查詢語句如下:
select work.ename worker,mgr.ename manager from scott.emp work, scott.emp mgr where work.empno=mgr.mgr order by work.ename;
1、查看總COST,獲得資源耗費的總體印象
一般而言,執行計劃第一行所對應的COST(即成本耗費)值,反應了運行這段SQL的總體估計成本,單看這個總成本沒有實際意義,但可以拿它與相同邏輯不同執行計劃的SQL的總體COST進行比較,通常COST低的執行計劃要好一些。
2、按照從左至右,從上至下的方法,了解執行計劃的執行步驟
執行計劃按照層次逐步縮進,從左至右看,縮進最多的那一步,最先執行,如果縮進量相同,則按照從上而下的方法判斷執行順序,可粗略認為上面的步驟優先執行。每一個執行步驟都有對應的COST,可從單步COST的高低,以及單步的估計結果集(對應ROWS/基數),來分析表的訪問方式,連接順序以及連接方式是否合理。
3、分析表的訪問方式
表的訪問方式主要是兩種:全表掃描(TABLE ACCESS FULL)和索引掃描(INDEX SCAN),如果表上存在選擇性很好的索引,卻走了全表掃描,而且是大表的全表掃描,就說明表的訪問方式可能存在問題;若大表上沒有合適的索引而走了全表掃描,就需要分析能否建立索引,或者是否能選擇更合適的表連接方式和連接順序以提高效率。
4、分析表的連接方式和連接順序
表的連接順序:就是以哪張表作為驅動表來連接其他表的先后訪問順序。
表的連接方式:簡單來講,就是兩個表獲得滿足條件的數據時的連接過程。主要有三種表連接方式,嵌套循環(NESTED LOOPS)、哈希連接(HASH JOIN)和排序-合并連接(SORT MERGE JOIN)。
我們常見得是嵌套循環和哈希連接。
嵌套循環:最適用也是最簡單的連接方式。類似于用兩層循環處理兩個游標,外層游標稱作驅動表,Oracle檢索驅動表的數據,一條一條的代入內層游標,查找滿足WHERE條件的所有數據,因此內層游標表中可用索引的選擇性越好,嵌套循環連接的性能就越高。
哈希連接:先將驅動表的數據按照條件字段以散列的方式放入內存,然后在內存中匹配滿足條件的行。哈希連接需要有合適的內存,而且必須在CBO優化模式下,連接兩表的WHERE條件有等號的情況下才可以使用。哈希連接在表的數據量較大,表中沒有合適的索引可用時比嵌套循環的效率要高。
1、這里看到的執行計劃,只是SQL運行前可能的執行方式,實際運行時可能因為軟硬件環境的不同,而有所改變,而且cost高的執行計劃,不一定在實際運行起來,速度就一定差,我們平時需要結合執行計劃,和實際測試的運行時間,來確定一個執行計劃的好壞。
2、對于表的連接順序,多數情況下使用的是嵌套循環,尤其是在索引可用性好的情況下,使用嵌套循環式最好的,但當ORACLE發現需要訪問的數據表較大,索引的成本較高或者沒有合適的索引可用時,會考慮使用哈希連接,以提高效率。排序合并連接的性能最差,但在存在排序需求,或者存在非等值連接無法使用哈希連接的情況下,排序合并的效率,也可能比哈希連接或嵌套循環要好。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





