溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Mydumper工作流程圖和主要步驟是什么,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
工作流程圖: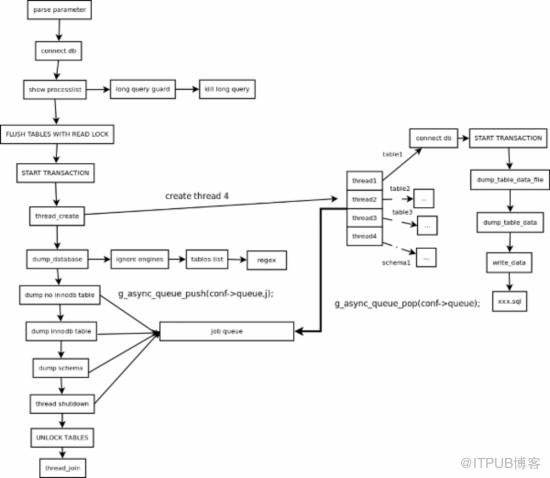
主要步驟概括:
1.主線程 FLUSH TABLES WITH READ LOCK , 施加全局只讀鎖,以阻止 DML 語句寫入,保證數據的一致性
2.讀取當前時間點的二進制日志文件名和日志寫入的位置并記錄在 metadata 文件中,以供即使點恢復使用
3.N個(線程數可以指定,默認是 4 ) dump 線程 START TRANSACTION WITH CONSISTENT SNAPSHOT ; 開啟讀一致的事物
4.dump non-InnoDB tables , 首先導出非事物引擎的表
5.主線程 UNLOCK TABLES 非事物引擎備份完后,釋放全局只讀鎖
6.dump InnoDB tables , 基于事物導出 InnoDB 表
7.事物結束
備份所生成的文件
所有的備份文件在一個目錄中,目錄可以自己指定
目錄中包含一個 metadata 文件
記錄了備份數據庫在備份時間點的二進制日志文件名,日志的寫入位置,
如果是在從庫進行備份,還會記錄備份時同步至主庫的二進制日志文件及寫入位置
每個表有兩個備份文件:
database.table-schema.sql 表結構文件
database.table.sql 表數據文件
如果對表文件分片,將生成多個備份數據文件,可以指定行數或指定大小分片
看完上述內容,你們掌握Mydumper工作流程圖和主要步驟是什么的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





