從順序隨機I/O原理來討論MYSQL MRR NLJ BNL BKA
從順序隨機I/O原理來討論
MYSQL MRR NLJ BNL BKA
本文只討論innodb存儲引擎,并且有部分觀點為作者觀點,如果有誤請指出。
一、機械磁盤原理
機械盤由動臂,盤片,讀寫磁頭,主軸組成,磁頭是固定不能動的,要讀取相應的扇區只能通過盤片的
旋轉。
每一個盤片為雙面,每一個面上分布有同心圓的磁道,磁道又分為扇區一般為512 BYTES,現代的磁盤
一般外邊緣磁道的扇區多,內磁道的扇區少,那么一般讀寫外邊緣磁道的速度更快,因為轉速為定值。
同時各個不同盤片上半徑下同的磁道組成了一個柱面。
下圖是一個典型的磁盤組織(摘取數據結構(C語言版))
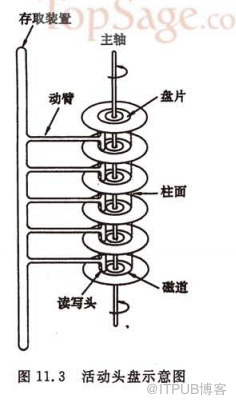
如果我們計ts(seek time)為尋道時間,tl(latency time)為尋道完成后等待盤片旋轉到特定扇區的時間
tw(transmission time)為傳輸時間,那么讀取一個扇區的時間為:
T(I/0) = ts+tl+tw
顯然在讀取數據一定的情況下,ts和tl的時間成了決定因素,而事實上ts尋道時間相對其他而言占用更長,
尋道時間在10毫秒的數量級,7200轉的tl時間為1000/7200 約為 100微秒數量級,而傳輸時間更短。
大量的隨機I/O會造成頻繁的磁道更換導致過長的時間,很可能讀完幾個扇區馬上就要跳到另外的磁道,
而順序I/O則不然一次定位可以讀取更多的扇區,從而盡量減少讀取時間。
二、隨機I/O和順序I/O模擬
模擬使用C語言調用LINUX API完成,主要方式如下:
讀取一個大文件程序中限制為900M,而程序順序和隨機讀取20000個4096大小的數據,并且CPY到其他文件中,
cpy的文件為81920000字節
為了將寫操作的影響降低,而將讀操作的影響放大,分別使用
O_CREAT | O_WRONLY |O_EXCL 打開寫文件,啟用OS BUFFER,write操作寫到OS kernel buffer則結束,同時不能開啟
O_SYNC,開始O_SYNC每一次wirte會調用fsync(),將寫的影響將會放大。
O_RDONLY | O_DIRECT 打開讀取文件,用O_DIRECT打開目的在于禁用OS CACHE當然也禁用了OS的預讀,直接讀取文件
這方面摘取一張圖便于理解,實際上我O_DIRECT后讀取這個文件是不過內核高速緩存的。
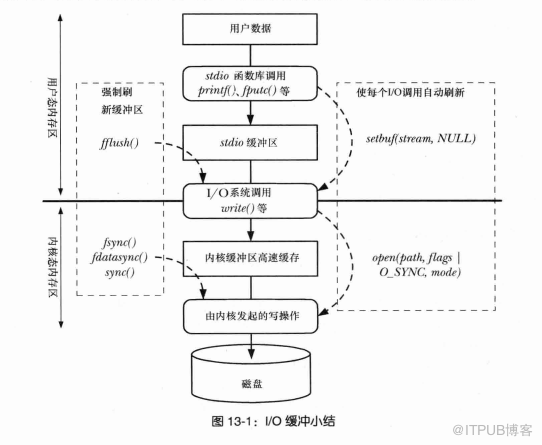
當然這個程序有一點補足,我應該使用排序算法將隨機數組中的數據排序后在進行讀取,而不是取一個連續的數組。
這樣更能說明問題,但這也不重要因為隨機讀已經慢得離譜了。下面是我程序跑出的結果。
./a.out p10404530_112030_Linux-x86-64_1of7.zip
fisrt sca array: 134709
fisrt sca array: 198155
fisrt sca array: 25305
fisrt sca array: 46515
fisrt sca array: 91550
fisrt sca array: 137262
fisrt sca array: 46134
fisrt sca array: 10208
fisrt sca array: 142115
......
sequential cpy begin Time: Fri Dec 2 01:36:55 2016
begin cpy use sequential read buffer is 4k:
per 25 % ,Time:Fri Dec 2 01:36:56 2016
per 50 % ,Time:Fri Dec 2 01:36:57 2016
per 75 % ,Time:Fri Dec 2 01:36:57 2016
per 100 % ,Time:Fri Dec 2 01:36:58 2016
scattered cpy begin Time: Fri Dec 2 01:36:58 2016
begin cpy use scattered read read buffer is 4k:
per 25 % ,Time:Fri Dec 2 01:37:51 2016
per 50 % ,Time:Fri Dec 2 01:38:40 2016
per 75 % ,Time:Fri Dec 2 01:39:29 2016
per 100 % ,Time:Fri Dec 2 01:40:20 2016
先輸出部分數組中的隨機值,可以看到讀取的位置是隨機的。從而模擬隨機讀取,
然后輸出順序讀取寫入,然后進行隨機讀取寫入。可以看到差別非常大,其實使用
iostat vmstat 都能看到讀取的速度非常慢。下面給出比較:
--順序
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 0.00 4979.38 2.06 19967.01 32.99 8.03 0.76 0.15 0.14 70.21
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 0.00 7204.12 0.00 28816.49 0.00 8.00 0.98 0.14 0.14 98.04
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 9.09 7114.14 9.09 28456.57 96.97 8.02 1.04 0.15 0.13 95.86
---隨機
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 0.00 107.14 0.00 428.57 0.00 8.00 1.01 9.49 9.42 100.92
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 0.00 104.17 1.04 416.67 0.52 7.93 1.04 9.79 9.81 103.23
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 0.00 104.12 2.06 465.98 32.99 9.40 1.17 11.02 9.68 102.78
這里明顯看出了問題,
程序放到最后給出。
三、MRR
有了上面的基礎,我們明白了順序讀取的重要性,那么我們開始看看Multi-Range Read (MRR),因為這個特性也是BKA的
重要支柱
如果了解ORACLE的朋友一定不會忘記索引集群因子,下面是集群因子的描述在索引的分析數據上clustering_factor是一
個很重要的參數,表示的是索引和表之間的關系,因為,索引是按照一定的順序排列的,但是,對于表來說是按照一種
heap的形式存放,每一行可能分布在段上任何一個塊上,所以要是通過索引來查找數據行的時候,就有可以一個索引塊
對應多個,甚至全部表的塊,所以引入了clustering_factor這個參數來表示表上數據存放和索引之間的對應關系。這樣
CBO就可以根據這個參數來判斷使用這個索引產生的cost是多少。
具體參考
(http://blog.itpub.net/7728585/viewspace-612691/)
1、描述
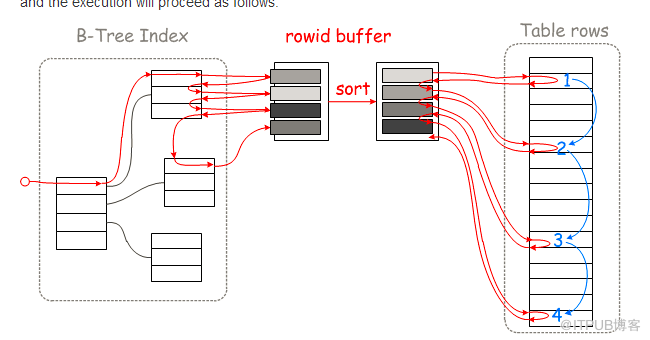
對于MYSQL的二級索引也存在如同ORACLE clustering_factor一樣的問題,過于隨機的回表會造成隨即讀取過于嚴重
范圍掃描range access中MYSQL將掃描到的數據存入read_rnd_buffer_size,然后對其按照primary key(rowid)排序,
然后使用排序好的數據進行順序回表因為我們知道INNODB中是葉節點數據是按照PRIMARY KEY(ROWID)進行排列的,那么
這樣就轉換隨機讀取為順序讀取了。
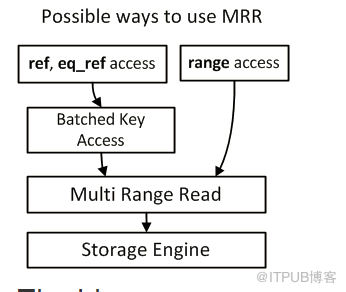
而在BKA中則將被連接表使用到ref,eq_ref索引掃描方式的時候將第一個表中掃描到的鍵值放到join_buffer_size中,
然后調用MRR接口進行排序和順序訪問并且通過join條件得到數據,這樣連接條件之間也成為了順序比對。
源碼接口handler::multi_range_read_init handler::multi_range_read_next
如圖(圖片摘取自mariadb官方文檔):
2、適用范圍:
---range access:通過一個或者多個范圍限制進行讀取數據。
比如
mysql> set optimizer_switch='mrr_cost_based=off';
Query OK, 0 rows affected (0.00 sec)
mysql> explain select * from testzh force index(id2) where id2=100 and id3<100;
+----+-------------+--------+------------+-------+---------------+------+---------+------+------+----------+----------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+------+---------+------+------+----------+----------------------------------+
| 1 | SIMPLE | testzh | NULL | range | id2 | id2 | 10 | NULL | 1 | 100.00 | Using index condition; Using MRR |
+----+-------------+--------+------------+-------+---------------+------+---------+------+------+----------+----------------------------------+
1 row in set, 1 warning (0.00 sec)
使用了ICP和MRR,因為MRR的代價評估一般較高所以這里使用mrr_cost_based=off
如圖(圖片摘取自mariadb官方文檔):
----ref and eq_ref access:當使用BKA(Batched Key Access),使用到連接索引,鍵值唯一(非主鍵)或者不唯一或者使用組合索引前綴
比如:
mysql> set optimizer_switch='mrr_cost_based=off,batched_key_access=on';
Query OK, 0 rows affected (0.00 sec)
mysql> explain select * from testzh,testzh20 where testzh.id2=testzh20.id2 ;
+----+-------------+----------+------------+------+---------------+------+---------+-----------------+--------+----------+----------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+-----------------+--------+----------+----------------------------------------+
| 1 | SIMPLE | testzh | NULL | ALL | id2,id2_2 | NULL | NULL | NULL | 100031 | 100.00 | Using where |
| 1 | SIMPLE | testzh20 | NULL | ref | id2 | id2 | 5 | test.testzh.id2 | 1 | 100.00 | Using join buffer (Batched Key Access) |
+----+-------------+----------+------------+------+---------------+------+---------+-----------------+--------+----------+----------------------------------------+
2 rows in set, 1 warning (0.00 sec)
如圖(圖片摘取自mariadb官方文檔):
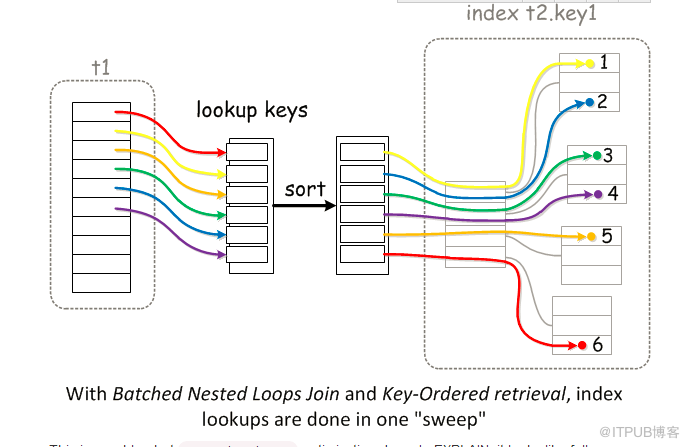
3、優勢:
順序讀取不在需要磁盤動臂不斷的移動來尋道和等待帶盤片旋轉的時間。
順序讀取有預讀的優勢。
每個塊值需要讀取一次,而不需要多次讀取,這是理所當然,因為一個塊中一般存儲了多行數據,不使用MRR可能會導致同一塊多次讀取到。
4、劣勢:
排序是額外需要時間的。如果使用order limit n,會導致更慢
四、NLJ、BNL、BKA
1、A simple nested-loop join (NLJ)
使用MYSQL文檔中偽代碼的描述:
for each row in t1 matching range {
for each row in t2 matching reference key {
for each row in t3 {
if row satisfies join conditions,
send to client
}
}
}
這種方式采用逐層調用循環的方式,很顯然這種方式適用于任何場景,不過在被連接表沒有索引的情況下,那么效率極低。
mysql> set optimizer_switch ='block_nested_loop=off';
Query OK, 0 rows affected (0.00 sec)
---ref 索引掃描
mysql> explain select * from testzh force index(id2),testzh20 where testzh.id2=testzh20.id2;
+----+-------------+----------+------------+------+---------------+------+---------+-------------------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+-------------------+-------+----------+-------------+
| 1 | SIMPLE | testzh20 | NULL | ALL | id2 | NULL | NULL | NULL | 99900 | 100.00 | Using where |
| 1 | SIMPLE | testzh | NULL | ref | id2 | id2 | 5 | test.testzh20.id2 | 1 | 100.00 | NULL |
+----+-------------+----------+------------+------+---------------+------+---------+-------------------+-------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
---ALL 全表掃描
mysql> explain select * from testzh force index(id2),testzh20 where testzh.name=testzh20.name;
+----+-------------+----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | testzh20 | NULL | ALL | NULL | NULL | NULL | NULL | 99900 | 100.00 | NULL |
| 1 | SIMPLE | testzh | NULL | ALL | NULL | NULL | NULL | NULL | 100031 | 10.00 | Using where |
+----+-------------+----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
總結:一般用于被鏈接表有索引的方式ref或者eq_ref,并且BKA代價較高,被連接表沒有索引一般使用BNL。
2、A Block Nested-Loop (BNL)
很顯然這種方式一般是用來優化被連接表沒有索引,這被連接表方式為ALL或者index,因為這種join使用NLJ實在太慢了,需要優化他對內層表
驅動的次數,那么加入一個緩存叫做join_buffer_size
我們考慮2個表連接的方式,如下:
mysql> explain select * from testzh ,testzh20 where testzh.name=testzh20.name;
+----+-------------+----------+------------+------+---------------+------+---------+------+--------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+--------+----------+----------------------------------------------------+
| 1 | SIMPLE | testzh20 | NULL | ALL | NULL | NULL | NULL | NULL | 99900 | 100.00 | NULL |
| 1 | SIMPLE | testzh | NULL | ALL | NULL | NULL | NULL | NULL | 100031 | 10.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+----------+------------+------+---------------+------+---------+------+--------+----------+----------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)
掃描testzh20表的相關字段,至少testzh20.name包含其中,存入join_buffer_size,
當join_buffer_size滿后,對
testzh進行一次掃描,并且對掃描到的值和join_buffer_size中的數據根據條件testzh.name=testzh20.name
進行比對,如果符合則放回,不符合則拋棄,比對完成后,清空buffer,繼續掃描testzh20剩下的數據,滿了
后又讀取一次testzh和join_buffer_size中的數據根據條件testzh.name=testzh20.name比對,如此反復直到
結束,我們考慮這樣的優化方式相對于BNL確實減少讀取testzh表的次數,而且是大大減少,那為什么不使用
MRR排序后在比對呢?因為testzh 壓根沒用到索引,你join_buffer_size中的數據排序了,但是testzh表中關
于testzh20.name的數據任然是無序的,沒有任何意義,使用MRR這種原理類似歸并排序,必須兩個數據集都是
排序好的,所以這里用不到MRR。
總結:一般用于被連接表方式為ALL或者index(索引覆蓋掃描)
3、Batched Key Access Joins (BKA)
這種方式在MRR中已經講了很多,其目的在于優化ref或者eq_ref使用NLJ連接的方式
mysql> explain select * from testzh ,testzh20 where testzh.id2=testzh20.id2;
+----+-------------+----------+------------+------+---------------+------+---------+-----------------+--------+----------+----------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+-----------------+--------+----------+----------------------------------------+
| 1 | SIMPLE | testzh | NULL | ALL | id2 | NULL | NULL | NULL | 100031 | 100.00 | Using where |
| 1 | SIMPLE | testzh20 | NULL | ref | id2 | id2 | 5 | test.testzh.id2 | 1 | 100.00 | Using join buffer (Batched Key Access) |
+----+-------------+----------+------------+------+---------------+------+---------+-----------------+--------+----------+----------------------------------------+
2 rows in set, 1 warning (0.00 sec)
這種方式的原理上就是通過順序的連接條件的比對,減少隨機讀取的可能。可以參考
https://mariadb.com/kb/en/mariadb/block-based-join-algorithms/
Batch Key Access Join
五、ORACLE中連接方式簡述
1、NEST LOOP JOIN:驅動表結果集較少,并且被驅動表有索引的情況下,11G后加入VECTOR I/O,其原理感覺類似MYSQL BKA,將多個單塊讀取
合并,獲得更好的NEST LOOP 性能。
2、SORT MERGE JOIN:這種連接方式類使用歸并的方式,既然是歸并一般用于連接條件之間排序好了,及都有索引的情況。
3、hash join:只使用于CBO,由于是HASH算法也就只能用于等值連接,他適用于小表和大表做連接,并且nest loop 效果不好的情況下,
對小表根據連接字段使用HASH算法,然后由于使用hash算法那么小表連接字段的不同值決定了HASH算法散列的分布均勻性,
也直接影響了HASH JOIN的性能,比如自增序列就是很好的HASH連接字段。大表的hash會占用過多的臨時表空間是需要注意
的。
參考資料:UNIX系統編程手冊
Block-Based Join Algorithms(mariadb)
Multi Range Read Optimization(mariadb)
數據結構(C語言版本)
MySQL 5.7 Reference Manual
隨機順序寫代碼
-
/*************************************************************************
-
> File Name: seqsca.c
-
> Author: gaopeng
-
> Mail: gaopp_200217@163.com
-
> Created Time: Wed 21 Dec 2016 02:24:04 PM CST
-
************************************************************************/
-
-
#include <stdio.h>
-
#include <unistd.h>
-
#include <stdlib.h>
-
#include <errno.h>
-
#include <time.h>
-
#include <sys/types.h>
-
#include <sys/stat.h>
-
#include <fcntl.h>
-
#include <string.h>
-
#define __USE_GNU 1
-
-
static int i=1;
-
-
-
-
void eprintf(const char* outp)
-
{
-
write(STDOUT_FILENO,outp,strlen(outp));
-
i++;
-
exit(i);
-
}
-
-
void ffprintf(const char* outp)
-
{
-
write(STDOUT_FILENO,outp,strlen(outp));
-
}
-
void eperror(void)
-
{
-
perror("error");
-
i++;
-
exit(i);
-
}
-
-
-
int main(int argc,char* argv[])
-
{
-
int sca[20001]; //sca[0] not used
-
char *buffer=NULL;
-
char *ct=NULL;
-
int i;
-
int openwflags = O_CREAT | O_WRONLY |O_EXCL ;//|O_SYNC no sync used os buffer max performance for wirte
-
int openrflags = O_RDONLY | O_DIRECT; //open use o_direct not use os cache disable preread
-
-
int fdr;
-
int fdwse,fdwsc;
-
off_t file_size;
-
time_t t1;
-
-
time_t t2;//time used return
-
int m;
-
-
time(&t1);
-
srand(t1);
-
-
-
if(argc !=2 || strcmp(argv[1],"--help")==0 )
-
{
-
eprintf("./tool readfile \n");
-
}
-
-
buffer=valloc(4096); //one block 4K allocate aligned memory
-
-
//init data array
-
for(i=1;i<=20000;i++)
-
{
-
sca[i] = rand()%200000;
-
}
-
-
for(i=1;i<=20;i++)
-
{
-
printf("fisrt sca array: %d\n",sca[i]);
-
}
-
-
umask(0);
-
if ((fdr = open(argv[1],openrflags)) == -1)
-
{
-
eperror();
-
}
-
-
if(file_size=lseek(fdr,0,SEEK_END) < 943718400 )
-
{
-
eprintf("testfile must > 900M \n");
-
}
-
// start sequential read
-
t2 = time(NULL);
-
-
ct = ctime(&t2);
-
if ((fdwse = open("tsq",openwflags,0755)) == -1)
-
{
-
eperror();
-
}
-
-
lseek(fdr,0,SEEK_SET);
-
printf("sequential cpy begin Time: %s",ct);
-
ffprintf("begin cpy use sequential read buffer is 4k:\n");
-
m = 0;
-
for(i=1;i<=20000;i++)
-
{
-
if(i%5000 == 0)
-
{
-
m++;
-
t2 = time(NULL);
-
ct = ctime(&t2);
-
printf("per %d % ,Time:%s",25*m,ct);
-
}
-
if(read(fdr,buffer,4096) == -1)
-
{
-
eperror();
-
}
-
if(write(fdwse,buffer,4096) == -1)
-
{
-
eperror();
-
}
-
-
}
-
ffprintf("\n");
-
close(fdwse);
-
/*
-
close(fdr);
-
-
if ((fdr = open(argv[1],openrflags)) == -1)
-
{
-
eperror();
-
}
-
*/
-
-
// start scattered read
-
if ((fdwsc = open("tsc",openwflags,0755)) == -1)
-
{
-
eperror();
-
}
-
-
t2 = time(NULL);
-
ct = ctime(&t2);
-
printf("scattered cpy begin Time: %s",ct);
-
m = 0;
-
ffprintf("begin cpy use scattered read read buffer is 4k:\n");
-
for(i=1;i<=20000;i++)
-
{
-
if(i%5000 ==0)
-
{
-
m++;
-
t2 = time(NULL);
-
ct = ctime(&t2);
-
printf("per %d % ,Time:%s",25*m,ct);
-
}
-
if (lseek(fdr,4096*sca[i],SEEK_SET) == -1)
-
{
-
ffprintf("lseek\n");
-
eperror();
-
}
-
if(read(fdr,buffer,4096) == -1)
-
{
-
ffprintf("read\n");
-
eperror();
-
}
-
if(write(fdwsc,buffer,4096) == -1)
-
{
-
ffprintf("write\n");
-
eperror();
-
}
-
}
-
ffprintf("\n");
-
close(fdwsc);
-
close(fdr);
-
free(buffer);
-
}
如果覺得不錯 您可以考慮請作者喝杯茶(微信支付): 作者微信號:







