溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關Mysql主從復制,讀寫分離,分表分庫策略與實踐的示例分析,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
一、MySQL擴展具體的實現方式
隨著業務規模的不斷擴大,需要選擇合適的方案去應對數據規模的增長,以應對逐漸增長的訪問壓力和數據量。
關于數據庫的擴展主要包括:業務拆分、主從復制、讀寫分離、數據庫分庫與分表等。這篇文章主要講述數據庫分庫與分表
(1)業務拆分
在 大型網站應用之海量數據和高并發解決方案總結一二 一篇文章中也具體講述了為什么要對業務進行拆分。
業務起步初始,為了加快應用上線和快速迭代,很多應用都采用集中式的架構。隨著業務系統的擴大,系統變得越來越復雜,越來越難以維護,開發效率變得越來越低,并且對資源的消耗也變得越來越大,通過硬件提高系統性能的方式帶來的成本也越來越高。
因此,在選型初期,一個優良的架構設計是后期系統進行擴展的重要保障。
例如:電商平臺,包含了用戶、商品、評價、訂單等幾大模塊,最簡單的做法就是在一個數據庫中分別創建users、shops、comment、order四張表。
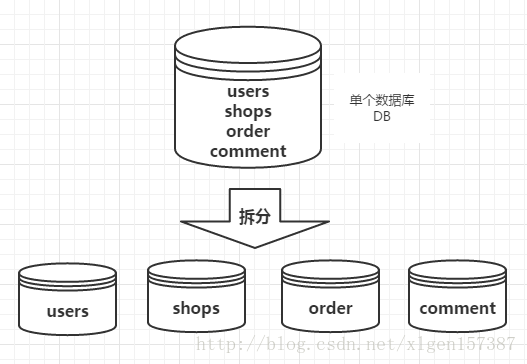
但是,隨著業務規模的增大,訪問量的增大,我們不得不對業務進行拆分。每一個模塊都使用單獨的數據庫來進行存儲,不同的業務訪問不同的數據庫,將原本對一個數據庫的依賴拆分為對4個數據庫的依賴,這樣的話就變成了4個數據庫同時承擔壓力,系統的吞吐量自然就提高了。
(2)主從復制
一般是主寫從讀,一主多從
1、 MySQL5.6 數據庫主從(Master/Slave)同步安裝與配置詳解
2、 MySQL主從復制的常見拓撲、原理分析以及如何提高主從復制的效率總結
3、 使用mysqlreplicate命令快速搭建 Mysql 主從復制
上述三篇文章中,講述了如何配置主從數據庫,以及如何實現數據庫的讀寫分離,這里不再贅述,有需要的選擇性點擊查看。
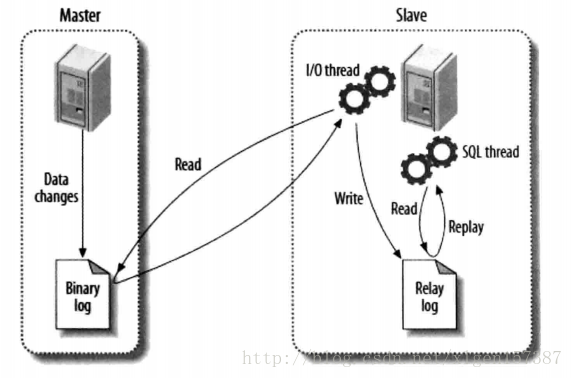
上圖是網上的一張關于MySQL的Master和Slave之間數據同步的過程圖。
主要講述了MySQL主從復制的原理:數據復制的實際就是Slave從Master獲取Binary log文件,然后再本地鏡像的執行日志中記錄的操作。由于主從復制的過程是異步的,因此Slave和Master之間的數據有可能存在延遲的現象,此時只能保證數據最終的一致性。
(3)數據庫分庫與分表
我們知道每臺機器無論配置多么好它都有自身的物理上限,所以當我們應用已經能觸及或遠遠超出單臺機器的某個上限的時候,我們惟有尋找別的機器的幫助或者繼續升級的我們的硬件,但常見的方案還是通過添加更多的機器來共同承擔壓力。
我們還得考慮當我們的業務邏輯不斷增長,我們的機器能不能通過線性增長就能滿足需求?因此,使用數據庫的分庫分表,能夠立竿見影的提升系統的性能,關于為什么要使用數據庫的分庫分表的其他原因這里不再贅述,主要講具體的實現策略。請看下邊章節。
關鍵字:用戶ID、表容量
對于大部分數據庫的設計和業務的操作基本都與用戶的ID相關,因此使用用戶ID是最常用的分庫的路由策略。用戶的ID可以作為貫穿整個系統用的重要字段。因此,使用用戶的ID我們不僅可以方便我們的查詢,還可以將數據平均的分配到不同的數據庫中。(當然,還可以根據類別等進行分表操作,分表的路由策略還有很多方式)
接著上述電商平臺假設,訂單表order存放用戶的訂單數據,sql腳本如下(只是為了演示,省略部分細節):
CREATE TABLE `order` ( `order_id` bigint(32) primary key auto_increment, `user_id` bigint(32), ... )
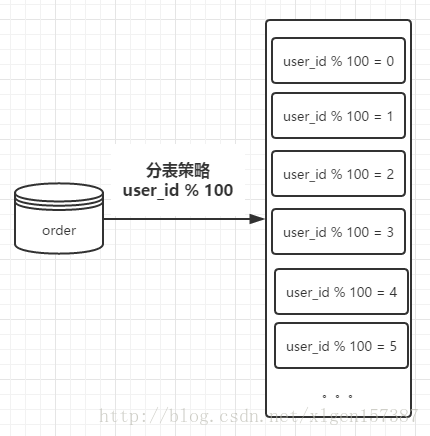
當數據比較大的時候,對數據進行分表操作,首先要確定需要將數據平均分配到多少張表中,也就是:表容量。
這里假設有100張表進行存儲,則我們在進行存儲數據的時候,首先對用戶ID進行取模操作,根據
user_id%100 獲取對應的表進行存儲查詢操作,示意圖如下:
例如,user_id = 101 那么,我們在獲取值的時候的操作,可以通過下邊的sql語句:
select * from order_1 where user_id= 101
其中,order_1是根據
101%100 計算所得,表示分表之后的第一章order表。
注意:
在實際的開發中,如果你使用MyBatis做持久層的話,MyBatis已經提供了很好得支持數據庫分表的功能,例如上述sql用MyBatis實現的話應該是:
接口定義:
/**
* 獲取用戶相關的訂單詳細信息
* @param tableNum 具體某一個表的編號
* @param userId 用戶ID
* @return 訂單列表
*/
public List<Order> getOrder(@Param("tableNum") int tableNum,@Param("userId") int userId);xml配置映射文件:
<select id="getOrder" resultMap="BaseResultMap">
select * from order_${tableNum}
where user_id = #{userId}
</select>其中${tableNum} 含義是直接讓參數加入到sql中,這是MyBatis支持的特性。
注意:
另外,在實際的開發中,我們的用戶ID更多的可能是通過UUID生成的,這樣的話,我們可以首先將UUID進行hash獲取到整數值,然后在進行取模操作。
數據庫分表能夠解決單表數據量很大的時候數據查詢的效率問題,但是無法給數據庫的并發操作帶來效率上的提高,因為分表的實質還是在一個數據庫上進行的操作,很容易受數據庫IO性能的限制。
因此,如何將數據庫IO性能的問題平均分配出來,很顯然將數據進行分庫操作可以很好地解決單臺數據庫的性能問題。
分庫策略與分表策略的實現很相似,最簡單的都是可以通過取模的方式進行路由。
還是上例,將用戶ID進行取模操作,這樣的話獲取到具體的某一個數據庫,同樣關鍵字有:
用戶ID、庫容量
路由的示意圖如下:
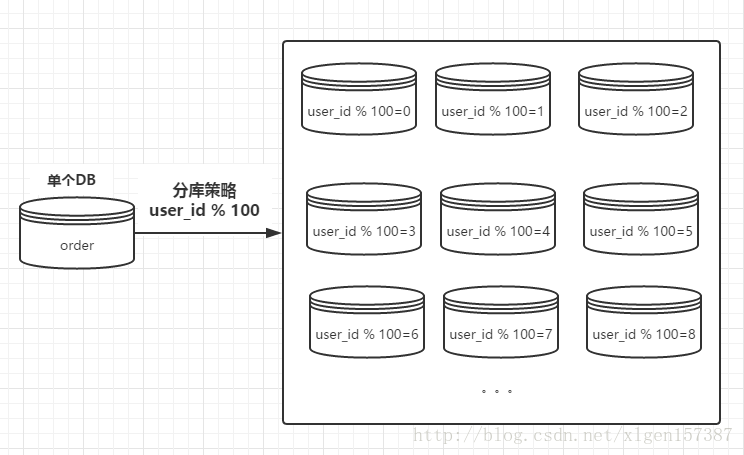
上圖中庫容量為100。
同樣,如果用戶ID為UUID請先hash然后在進行取模。
上述的配置中,數據庫分表可以解決單表海量數據的查詢性能問題,分庫可以解決單臺數據庫的并發訪問壓力問題。
有時候,我們需要同時考慮這兩個問題,因此,我們既需要對單表進行分表操作,還需要進行分庫操作,以便同時擴展系統的并發處理能力和提升單表的查詢性能,就是我們使用到的分庫分表。
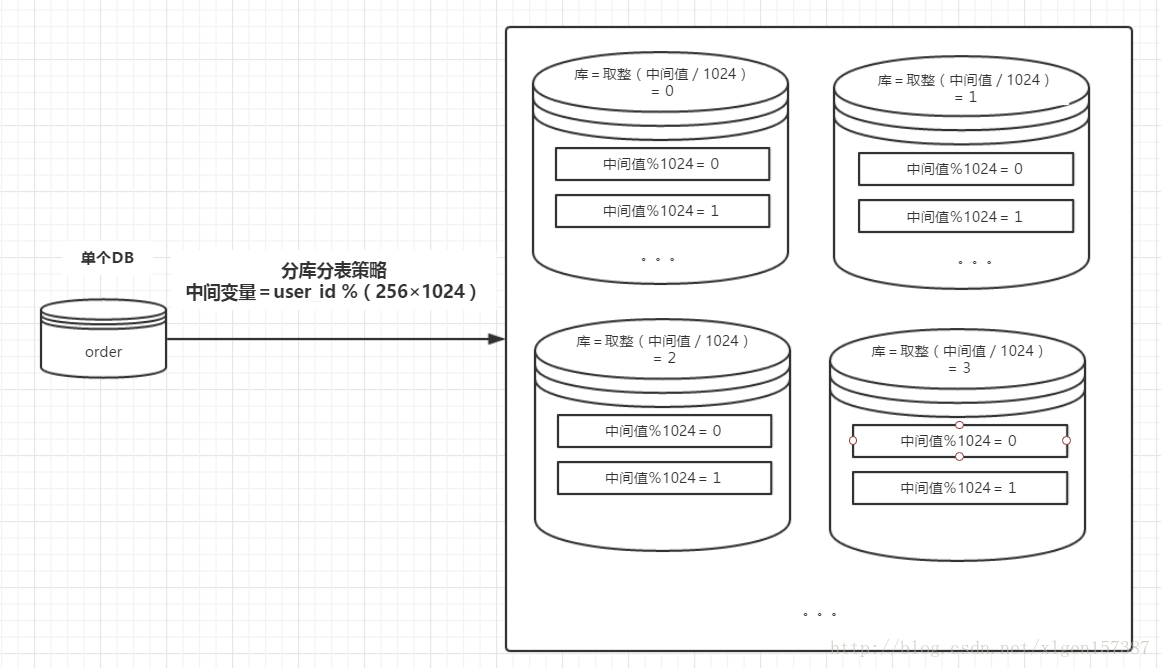
分庫分表的策略相對于前邊兩種復雜一些,一種常見的路由策略如下:
1、中間變量 = user_id%(庫數量*每個庫的表數量); 2、庫序號 = 取整(中間變量/每個庫的表數量); 3、表序號 = 中間變量%每個庫的表數量;
例如:數據庫有256 個,每一個庫中有1024個數據表,用戶的user_id=262145,按照上述的路由策略,可得:
1、中間變量 = 262145%(256*1024)= 1; 2、庫序號 = 取整(1/1024)= 0; 3、表序號 = 1%1024 = 1;
這樣的話,對于user_id=262145,將被路由到第0個數據庫的第1個表中。
示意圖如下:
關于分庫分表策略的選擇有很多種,上文中根據用戶ID應該是比較簡單的一種。其他方式比如使用號段進行分區或者直接使用hash進行路由等。有興趣的可以自行查找學習。
關于上文中提到的,如果用戶的ID是通過UUID的方式生成的話,我們需要單獨的進行一次hash操作,然后在進行取模操作等,其實hash本身就是一種分庫分表的策略,使用hash進行路由策略的時候,我們需要知道的是,也就是hash路由策略的優缺點,優點是:數據分布均勻;缺點是:數據遷移的時候麻煩,不能按照機器性能分攤數據。
上述的分庫和分表操作,查詢性能和并發能力都得到了提高,但是還有一些需要注意的就是,例如:原本跨表的事物變成了分布式事物;由于記錄被切分到不同的數據庫和不同的數據表中,難以進行多表關聯查詢,并且不能不指定路由字段對數據進行查詢。分庫分表之后,如果我們需要對系統進行進一步的擴陣容(路由策略變更),將變得非常不方便,需要我們重新進行數據遷移。
最后需要指出的是,分庫分表目前有很多的中間件可供選擇,最常見的是使用淘寶的中間件Cobar。
GitHub地址: https://github.com/alibaba/cobara
文檔地址為: https://github.com/alibaba/cobar/wiki
關于淘寶的中間件Cobar本篇內容不具體介紹,會在后邊的學習中在做介紹。
另外Spring也可以實現數據庫的讀寫分離操作,后邊的文章,會進一步學習。
上述中,我們學到了如何進行數據庫的讀寫分離和分庫分表,那么,是不是可以實現一個可擴展、高性能、高并發的網站那?很顯然還不可以!一個大型的網站使用到的技術遠不止這些,可以說,這些都是其中的最基礎的一個環節,因為還有很多具體的細節我們沒有掌握到,比如:數據庫的集群控制,集群的負載均衡,災難恢復,故障自動切換,事務管理等等技術。因此,還有很多需要去學習去研究的地方。
總之:
路漫漫其修遠兮,吾將上下而求索。
前方道路美好而光明,2017年新征程,不泄步!
一個徹底開源的,面向企業應用開發的大數據庫集群
支持事務、ACID、可以替代MySQL的加強版數據庫
一個可以視為MySQL集群的企業級數據庫,用來替代昂貴的Oracle集群
一個融合內存緩存技術、NoSQL技術、HDFS大數據的新型SQL Server
結合傳統數據庫和新型分布式數據倉庫的新一代企業級數據庫產品
一個新穎的數據庫中間件產品
以上內容來自 Mycat官網,簡單來說,Mycat就是一個數據庫中間件,對于我們開發來說,就像是一個代理,當我們需要使用到多個數據庫和需要進行分庫分表的時候,我們只需要在mycat里面配置好相關規則,程序無需做任何修改,只是需要將原本的數據源鏈接到mycat而已,當然如果以前有多個數據源,需要將數據源切換為單個數據源,這樣有個好處就是當我們的數據量已經很大的時候,需要開始分庫分表或者做讀寫分離的時候,不用修改代碼(只需要改一下數據源的鏈接地址)
使用Mycat分表分庫實踐
haha,首先這不是一篇入門Mycat的博客但小編感覺又很入門的博客!這篇博客主要講解Mycat中數據分片的相關知識,同時小編將會在本機數據庫上進行測試驗證,圖文并茂展示出來。
數據庫分區分表,咋一聽非常地高大上,總有一種高高在上,望塵莫及的感覺,但小編想說的是,其實,作為一個開發人員,該來的總是會來,該學的東西你還是得學,區別只是時間先后順序的問題。
分區就是把一個數據表的文件和索引分散存儲在不同的物理文件中。
mysql支持的分區類型包括Range、List、Hash、Key,其中Range比較常用:
RANGE分區:基于屬于一個給定連續區間的列值,把多行分配給分區。
LIST分區:類似于按RANGE分區,區別在于LIST分區是基于列值匹配一個離散值集合中的某個值來進行選擇。
HASH分區:基于用戶定義的表達式的返回值來進行選擇的分區,該表達式使用將要插入到表中的這些行的列值進行計算。這個函數可以包含MySQL 中有效的、產生非負整數值的任何表達式。
KEY分區:類似于按HASH分區,區別在于KEY分區只支持計算一列或多列,且MySQL服務器提供其自身的哈希函數。必須有一列或多列包含整數值。
分表是指在邏輯上將一個表拆分成多個邏輯表,在整體上看是一張表,分表有水平拆分和垂直拆分兩種,舉個例子,將一張大的存儲商戶信息的表按照商戶號的范圍進行分表,將不同范圍的記錄分布到不同的表中。
Mycat 的分片其實和分表差不多意思,就是當數據庫過于龐大,尤其是寫入過于頻繁且很難由一臺主機支撐是,這時數據庫就會面臨瓶頸。我們將存放在同一個數據庫實例中的數據分散存放到多個數據庫實例(主機)上,進行多臺設備存取以提高性能,在切分數據的同時可以提高系統的整體性。
數據分片是指將數據全局地劃分為相關的邏輯片段,有水平切分、垂直切分、混合切分三種類型,下面主要講下Mycat的水平和垂直切分。有一點很重要,那就是Mycat是分布式的,因此分出來的數據片分布到不同的物理機上是正常的,靠網絡通信進行協作。
水平切分
就是按照某個字段的某種規則分散到多個節點庫中,每個節點中包含一部分數據。可以將數據水平切分簡單理解為按照數據行進行切分,就是將表中的某些行切分到一個節點,將另外某些行切分到其他節點,從分布式的整體來看它們是一個整體的表。
垂直切分
一個數據庫由很多表構成,每個表對應不同的業務,垂直切分是指按照業務將表進行分類并分不到不同的節點上。垂直拆分簡單明了,拆分規則明確,應用程序模塊清晰、明確、容易整合,但是某個表的數據量達到一定程度后擴展起來比較困難。
混合切分
為水平切分和垂直切分的結合。
上面說到,垂直切分主要是根據具體業務來進行拆分的,那么,我們可以想象這么一個場景,假設我們有一個非常大的電商系統,那么我們需要將訂單表、流水表、用戶表、用戶評論表等分別分不到不同的數據庫中來提高吞吐量,架構圖大概如下:
由于小編是在一臺機器上測試,因此就只有host1這個節點,但不同的表還是依舊對應不同的數據庫,只不過是所有數據庫屬于同一個數據庫實例(主機)而已,后期不同主機只需增加<dataHost>節點即可。
mycat配置文件如下:
server.xml
<user name="root"> <property name="password">root</property> // 對應四個邏輯庫 <property name="schemas">order,trade,user,comment</property> </user>
schema.xml
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <!-- 4個邏輯庫,對應4個不同的分片節點 --> <schema name="order" checkSQLschema="false" sqlMaxLimit="100" dataNode="database1" /> <schema name="trade" checkSQLschema="false" sqlMaxLimit="100" dataNode="database2" /> <schema name="user" checkSQLschema="false" sqlMaxLimit="100" dataNode="database3" /> <schema name="comment" checkSQLschema="false" sqlMaxLimit="100" dataNode="database4" /> <!-- 四個分片,對應四個不同的數據庫 --> <dataNode name="database1" dataHost="localhost1" database="database1" /> <dataNode name="database2" dataHost="localhost1" database="database2" /> <dataNode name="database3" dataHost="localhost1" database="database3" /> <dataNode name="database4" dataHost="localhost1" database="database4" /> <!-- 實際物理主機,只有這一臺 --> <dataHost name="localhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1" url="localhost:3306" user="root" password="root"> </writeHost> </dataHost> </mycat:schema>
登陸本機mysql,創建order,trade,user,comment4個數據庫:
create database database1 character set utf8; create database database2 character set utf8; create database database3 character set utf8; create database database4 character set utf8;
執行bin目錄下的startup_nowrap.bat文件,如果輸出下面內容,則說明已經啟動mycat成功,如果沒有,請檢查order,trade,user,comment4個數據庫是否已經創建。
采用下面語句登陸Mycat服務器:
mysql -uroot -proot -P8066 -h227.0.0.1
在comment數據庫中創建Comment表,并插入一條數據
上圖1處新建一個Comment表,2處插入一條記錄,3處查看記錄插入到哪個數據節點中,即database4。
server.xml
<user name="root"> <property name="password">root</property> <property name="schemas">TESTDB</property> </user>
schema.xml
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100"> <table name="travelrecord" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" /> </schema> <dataNode name="dn1" dataHost="localhost1" database="db1" /> <dataNode name="dn2" dataHost="localhost1" database="db2" /> <dataNode name="dn3" dataHost="localhost1" database="db3" /> <dataHost name="localhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <!-- can have multi write hosts --> <writeHost host="hostM1" url="localhost:3306" user="root" password="root"> </writeHost> </dataHost> </mycat:schema>
rule.xml
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mycat:rule SYSTEM "rule.dtd"> <mycat:rule xmlns:mycat="http://io.mycat/"> <tableRule name="auto-sharding-long"> <rule> <columns>id</columns> rang-long </rule> </tableRule> <function name="rang-long" class="io.mycat.route.function.AutoPartitionByLong"> <property name="mapFile">autopartition-long.txt</property> </function> </mycat:rule>
conf目錄下的autopartition-long.txt
# range start-end ,data node index # K=1000,M=10000. 0-500M=0 500M-1000M=1 1000M-1500M=2
上面的配置創建了一個名為TESTDB的邏輯庫,并指定了需要切分的表<table>標簽,表名為travelrecord,分區的策略采用rang-long算法,即根據id數據列值的范圍進行切分,具體的規則在autopartition-long.txt文件中定義,即id在0-500*10000范圍內的記錄存放在db1的travelrecord表中,id在500*10000 - 1000*10000范圍內的記錄存放在db2數據庫的travelrecord表中,下面我們插入兩條數據,驗證是否和分片規則一致。
創建db1,db2,db3數據庫
create database db1 character set utf8; create database db2 character set utf8; create database db3 character set utf8;
確實是這樣的,到此我們就完成了mycat數據庫的水平切分,這個例子只是演示按照id列值得范圍進行切分,mycat還支持很多的分片算法,如取模、一致性哈希算法、按日期分片算法等等,大家可以看《分布式數據庫架構及企業實戰——基于Mycat中間件》這本書深入學習。
至于為什么需要讀寫分離,在我之前的文章有介紹過了,相信看到這篇文章的人也知道為什么需要讀寫分離了,當然如果你也需要了解一下,那么歡迎查看我之前的文章 SpringBoot Mybatis 讀寫分離配置,順便也可以了解一下怎么通過代碼進行讀寫分離的
主從復制是讀寫分離的關鍵,不管通過什么方式進行讀寫分離,前提就是MySQL有主從復制,當前雙機主從也行,但是關鍵的關鍵,是要能保證2個庫的數據能一致(出掉剛寫入主庫從庫還未能及時反應過來的情況),如果2個庫的數據不一致,那么讀寫分離也有沒有任何意義了,具體MySQL怎么做主從復制可以查看我之前的文章 MySQL主從復制搭建,基于日志(binlog)
Mycat的用戶就跟MySQL用戶是同一個意思,主要配置鏈接到Mycat的用戶名以及密碼,以及能使用的邏輯庫,用戶信息主要在server.xml中配置的,具體如下
<?xml version="1.0" encoding="UTF-8"?> <!-- - - Licensed under the Apache License, Version 2.0 (the "License"); - you may not use this file except in compliance with the License. - You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - - Unless required by applicable law or agreed to in writing, software - distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the License for the specific language governing permissions and - limitations under the License. --> <!DOCTYPE mycat:server SYSTEM "server.dtd"> <mycat:server xmlns:mycat="http://io.mycat/"> <system> <property name="defaultSqlParser">druidparser</property> <!-- <property name="useCompression">1</property>--> <!--1為開啟mysql壓縮協議--> <!-- <property name="processorBufferChunk">40960</property> --> <!-- <property name="processors">1</property> <property name="processorExecutor">32</property> --> <!--默認是65535 64K 用于sql解析時最大文本長度 --> <!--<property name="maxStringLiteralLength">65535</property>--> <!--<property name="sequnceHandlerType">0</property>--> <!--<property name="backSocketNoDelay">1</property>--> <!--<property name="frontSocketNoDelay">1</property>--> <!--<property name="processorExecutor">16</property>--> <!-- <property name="mutiNodeLimitType">1</property> 0:開啟小數量級(默認) ;1:開啟億級數據排序 <property name="mutiNodePatchSize">100</property> 億級數量排序批量 <property name="processors">32</property> <property name="processorExecutor">32</property> <property name="serverPort">8066</property> <property name="managerPort">9066</property> <property name="idleTimeout">300000</property> <property name="bindIp">0.0.0.0</property> <property name="frontWriteQueueSize">4096</property> <property name="processors">32</property> --> </system> <user name="raye"> <property name="password">rayewang</property> <property name="schemas">separate</property> </user> </host> </mycat:server>
其中<user name="raye">定義了一個名為raye的用戶,標簽user中的<property name="password">rayewang</property>定義了用戶的密碼,<property name="schemas">separate</property>定義了用戶可以使用的邏輯庫
Mycat的配置有很多,不過因為我們只是使用Mycat的讀寫分類的功能,所以用到的配置并不多,只需要配置一些基本的,當然本文也只是會介紹到讀寫分離相關的配置,其他配置建議讀者自己查看一下文檔,或者通過其他方式了解,邏輯庫是在schema.xml中配置的
首先介紹Mycat邏輯庫中的一些配置標簽
schema 標簽是用來定義邏輯庫的,schema有四個屬性dataNode,checkSQLschema,sqlMaxLimit,name
dataNode 標簽屬性用于綁定邏輯庫到某個具體的 database 上,1.3 版本如果配置了 dataNode,則不可以配置分片表,1.4 可以配置默認分片,只需要配置需要分片的表即可
name是定義當前邏輯庫的名字的,方便server.xml中定義用戶時的引用
checkSQLschema當該值設置為 true 時,如果我們執行語句select
from separate.users;則 MyCat 會把語句修改 為select from users;。即把表示 schema 的字符去掉,避免發送到后端數據庫執行時報(ERROR 1146 (42S02): Table ‘separate.users’ doesn’t exist)。 不過,即使設置該值為 true ,如果語句所帶的是并非是 schema 指定的名字,例如:select * from db1.users; 那么 MyCat 并不會刪除 db1 這個字段,如果沒有定義該庫的話則會報錯,所以在提供 SQL語句的最好是不帶這個字段。
sqlMaxLimit當該值設置為某個數值時。每條執行的 SQL 語句,如果沒有加上 limit 語句,MyCat 也會自動的加上所對應的值。例如設置值為 100,執行select
from users;的效果為和執行select from users limit 100;相同。設置該值的話,MyCat 默認會把查詢到的信息全部都展示出來,造成過多的輸出。所以,在正常使用中,還是建議加上一個值,用于減少過多的數據返回。當然 SQL 語句中也顯式的指定 limit 的大小,不受該屬性的約束。需要注意的是,如果運行的 schema 為非拆分庫的,那么該屬性不會生效。需要手動添加 limit 語句。
schema標簽中有標簽table用于定義不同的表分片信息,不過我們只是做讀寫分離,并不會用到,所以這里就不多介紹了
dataNodedataNode 標簽定義了 MyCat 中的數據節點,也就是我們通常說所的數據分片。一個 dataNode 標簽就是一個獨立的數據分片,dataNode有3個屬性:name,dataHost,database。
name定義數據節點的名字,這個名字需要是唯一的,此名字是用于table標簽和schema標簽中引用的
dataHost該屬性用于定義該分片屬于哪個數據庫實例的,屬性值是引用 dataHost 標簽上定義的 name 屬性
database該屬性用于定義該分片屬性哪個具體數據庫實例上的具體庫,因為這里使用兩個緯度來定義分片,就是:實例+具體的庫。因為每個庫上建立的表和表結構是一樣的。所以這樣做就可以輕松的對表進行水平拆分
dataHost是定義真實的數據庫連接的標簽,該標簽在 mycat 邏輯庫中也是作為最底層的標簽存在,直接定義了具體的數據庫實例、讀寫分離配置和心跳語句,dataHost有7個屬性:name,maxCon,minCon,balance,writeType,dbType,dbDriver,有2個標簽heartbeat,writeHost,其中writeHost標簽中又包含一個readHost標簽
name唯一標識 dataHost 標簽,供dataNode標簽使用
maxCon指定每個讀寫實例連接池的最大連接。也就是說,標簽內嵌套的 writeHost、readHost 標簽都會使用這個屬性的值來實例化出連接池的最大連接數
minCon指定每個讀寫實例連接池的最小連接,初始化連接池的大小
balance 讀取負載均衡類型
balance=”0”, 不開啟讀寫分離機制,所有讀操作都發送到當前可用的 writeHost 上。
balance=”1”,全部的 readHost 與 stand by writeHost 參與 select 語句的負載均衡,簡單的說,當雙主雙從模式(M1->S1,M2->S2,并且 M1 與 M2 互為主備),正常情況下,M2,S1,S2 都參與 select 語句的負載均衡。
balance=”2”,所有讀操作都隨機的在 writeHost、readhost 上分發。
balance=”3”,所有讀請求隨機的分發到 wiriterHost 對應的 readhost 執行,writerHost 不負擔讀壓力
writeType寫入負載均衡類型,目前的取值有 3 種:
writeType=”0”, 所有寫操作發送到配置的第一個 writeHost,第一個掛了切到還生存的第二個writeHost,重新啟動后已切換后的為準,切換記錄在配置文件中:dnindex.properties .
writeType=”1”,所有寫操作都隨機的發送到配置的 writeHost
dbType 指定后端連接的數據庫類型,目前支持二進制的 mysql 協議,還有其他使用 JDBC 連接的數據庫。例如:mongodb、oracle、spark 等
dbDriver指定連接后端數據庫使用的 Driver,目前可選的值有 native 和 JDBC。使用 native 的話,因為這個值執行的 是二進制的 mysql 協議,所以可以使用 mysql 和 maridb。其他類型的數據庫則需要使用 JDBC 驅動來支持。從 1.6 版本開始支持 postgresql 的 native 原始協議。 如果使用 JDBC 的話需要將符合 JDBC 4 標準的驅動 JAR 包放到 MYCAT\lib 目錄下,并檢查驅動 JAR 包中包括如下目錄結構的文件:META-INF\services\java.sql.Driver。在這個文件內寫上具體的 Driver 類名,例如: com.mysql.jdbc.Driver。
heartbeat這個標簽內指明用于和后端數據庫進行心跳檢查的語句。例如,MYSQL 可以使用 select user(),Oracle 可以使用 select 1 from dual 等。 這個標簽還有一個 connectionInitSql 屬性,主要是當使用 Oracla 數據庫時,需要執行的初始化 SQL 語句就這個放到這里面來。例如:alter session set nlsdateformat=’yyyy-mm-dd hh34:mi:ss’
writeHost,readHost這兩個標簽都指定后端數據庫的相關配置給 mycat,用于實例化后端連接池。唯一不同的是,writeHost 指定寫實例、readHost 指定讀實例,組著這些讀寫實例來滿足系統的要求。 在一個 dataHost 內可以定義多個 writeHost 和 readHost。但是,如果 writeHost 指定的后端數據庫宕機,那么這個 writeHost 綁定的所有 readHost 都將不可用。另一方面,由于這個 writeHost 宕機系統會自動的檢測到,并切換到備用的 writeHost 上去,這2個標簽屬性都一致,擁有host,url,password,user,weight,usingDecrypt等屬性
host用于標識不同實例,一般 writeHost 我們使用M1,readHost 我們用S1
url真實數據庫的實例的鏈接地址,如果是使用 native 的 dbDriver,則一般為 address:port 這種形式。用 JDBC 或其他的dbDriver,則需要特殊指定。當使用 JDBC 時則可以這么寫:jdbc:mysql://localhost:3306/
user真實數據庫實例的鏈接用戶名
password真實數據庫實例的鏈接密碼
weight權重 配置在 readhost 中作為讀節點的權重,主要用于多臺讀取的數據庫實例機器配置不同的情況,可以根據權重調整訪問量
usingDecrypt是否對密碼加密默認 0 否 如需要開啟配置 1,同時使用加密程序對密碼加密
注意,readHost是在writeHost標簽內的,不是單獨的
以下是我的讀寫分離配置文件
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="separate" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"/> <dataNode name="dn1" dataHost="localhost1" database="test" /> <dataHost name="localhost1" maxCon="1000" minCon="10" balance="3" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <!-- can have multi write hosts --> <writeHost host="hostM1" url="192.168.1.126:3307" user="root" password="123456"> <!-- can have multi read hosts --> <readHost host="hostS2" url="192.168.1.126:3308" user="root" password="123456" /> </writeHost> </dataHost> </mycat:schema>
前面已經差不多都解釋清楚了,因為我只是用的基本的主從復制,所以我的將dataHost的balance設置成了3
啟動mycat,然后用數據庫連接工具連接到mycat,可以測試是否配置成功,最簡單的就是通過修改從庫的數據,這樣方便查看到底是運行到哪個庫上面了,另外由于我是基于docker啟動的mycat,所以如果是直接在系統中運行的mycat的,可以去看官方文檔,看看到底怎么啟動mycat
以上就是Mysql主從復制,讀寫分離,分表分庫策略與實踐的示例分析,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





