溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
INFORMATICA 開發規范有哪些,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
ETL研發運維責任人界定
1)資科內部業務數據流轉,采取使用方研發原則,即誰取用數據,誰負責ETL版本研發。目標系統運維人員進行運維。
2)對于業務用戶的獨立管理系統,沒有專門研發,由取數源端研發負責informatica 版本研發推送數據。源端系統對應運維人員負責對應workflow運維。
1)對于增量同步表,需要源表和目標表存在主鍵。
2)增量字段上,需要有索引
3)增量字段 (如時間條件,必須嚴格順序進入數據庫,或者增量同步完成后,嚴格保證增量同步的取數范圍后續不會有數據進入)
同步場景 | 同步要求 | |||
同步類型 | 源表和目標表是否存在主鍵或者唯一鍵 | 增量字段上是否有索引(源表和目標表) | update 同步 | delte同步 |
有標識字段增量 | 存在pk或者索引 | 需要存在索引 | 需要存在updatetime字段,并使用update字段PK 進行update 更新同步。 | 需要將刪除數據寫入臨時表,etl同時同步臨時表后將目標庫對應數據刪除,源端也需要進行定期清理臨時表 |
源表全量讀取同步 | 不存在約束或者索引 | N/A | N/A | N/A |
源表全量讀取同步 | 存在pk或者索引 | N/A | N/A | N/A |
序號 | 術語或縮略語 | 說明性定義 |
1 | ETL | Extraction-Transformation-Loading,數據加載 |
2 | Source | 源 |
3 | Target | 目標 |
4 | Transformation | 組件 |
5 | Mapping | 數據映射 |
6 | Mapplet | 數據映射集,可復用的Transformation組合 |
7 | Session | 執行任務 |
8 | Worklet | 數據工作集 |
9 | Workflow | 數據工作流 |
10 | Schedule | 調度頻率 |
11 | Parameter | 參數 |
12 | ETLUser | 用與ETL數據同步的數據庫用戶 |
13 | ProductDatabaseSID | 生產系統數據庫SID |
本文檔讀者包括:
l 項目經理;
l 系統管理員;
l DBA管理員;
l 開發人員;
l 測試人員;
l 運維人員;
本項目需要使用到的技術:
l ETL數據整合及轉換:Informatica;
l 操作系統:Linux、Windows
l 數據庫:Oracle、Mysql、DB2、MS SQLServer等
Service Variable | Description | 值 | |
1 | $PMRootDir | Infa_share根目錄 | <Installation_Directory>\server\infa_shared |
2 | $PMSessionLogDir | Session 運行日志目錄 | $PMRootDir/SessLogs. |
3 | $PMBadFileDir | Reject files拒絕文件目錄 | $PMRootDir/BadFiles. |
4 | $PMCacheDir | Temporary cache files | $PMRootDir/Cache |
5 | $PMTargetFileDir | Target files 目標文件生成目錄 | $PMRootDir/TgtFiles |
6 | $PMSourceFileDir | Source files 平面文件源文件目錄 | $PMRootDir/SrcFiles |
9 | $PMWorkflowLogDir | Workflow logs workflow執行日志目錄 | $PMRootDir/WorkflowLogs. |
10 | $PMLookupFileDir | Lookup files lookup生成的cache目錄 | $PMRootDir/LkpFiles. |
11 | $PMTempDir | 臨時文件目錄 | $PMRootDir/Temp |
12 | $PMStorageDir | HA時,記錄workflow的運行狀態 | $PMRootDir/Storage. |
以下元素,數據庫表,字段名稱,函數名稱,函數表達式,SQL語句均采用大寫字母。
數據鏈接分為源數據庫鏈接與目標數據庫鏈接,ETL的E(抽取)與L(加載)的鏈接。
數據庫鏈接方式分為Native、ODBC兩種方式:
1)Native是采用相應數據的客戶端連接來抽取、加載數據,比如oracle、DB2等;
2)ODBC是采用DataDirect ODBC的方式連接數據庫,比如mysql、MSSQL。
數據連接的命名采用:DataBaseType_ProductDatabaseSID_ETLUSER。
說明:DataBaseType為數據源類型,ProductDatabaseSID生產數據庫的SID,ETLUser為用與ETL數據同步的用戶。
例如: Ora_ASURE_BILETL,連接方式為Native方式,Ora表示數據類型為Oracle,ASURE為阿修羅生產數據庫SID,BILETL為ETL的操作用戶。
例如:ODBC_ Mysql_ASURE_BILETL,ODBC表示采用ODBC的方式連接。Mysql為數據庫類型,ASURE為阿修羅系統,BILETL為ETL操作用戶。
表5-1 數據庫類型縮寫
序號 | 數據源類型 | 縮寫 |
1 | Oracle | Ora_ |
2 | DB2 | DB2_ |
3 | Mysql | Mysql_ |
4 | Microsoft SQL Server | MSSQL_ |
5 | Sybase | Sybase_ |
6 | Greenplum | GP_ |
7 | Teradata | TD_ |
8 | ODBC | ODBC_DataType_ |
表5-2 數據庫信息表
序號 | 數據庫中文名 | 數據庫SID | 備注 |
1 | 阿修羅系統 | ASURE | |
2 | 新車輛管理系統 | VMS | |
3 | 短信系統 | SMSDB | |
4 |
表5-3 常用組件命名前綴
序號 | 組件名稱 | 圖標 | 命名規范 | 含義 |
1 | Source Qualifier | 
| sq_ | 從數據源讀取數據 |
2 | Expression | 
| exp_desc | 行級轉換 |
3 | Filter | 
| fil_ | 數據過濾 |
4 | Sorter | 
| sort_ | 數據排序 |
5 | Aggregator | 
| agg_ | 聚合 |
6 | Joiner | 
| jnr_ | 異構數據關接連接 |
7 | Lookup | 
| lkp_ | 查詢連接 |
8 | Update Strategy | 
| ust_ | 對目標編輯 insert, update, delete, reject |
9 | Router | 
| rot_ | 條件分發 |
10 | Sequence Generator | 
| sqg_ | 序列號生成器 |
11 | Normalizer | 
| nrm_ | 記錄規范化 |
12 | Rank | 
| rnk_ | 對記錄進行TOPx |
13 | Union | 
| uni_ | 數據合并 |
14 | Transaction Control | 
| tc_ | 對裝載數據按條件進行事務控制 |
15 | Stored Procedure | 
| sp_ | 存儲過程組件 |
16 | Custom | 
| cus_ | 用戶自定義組件 |
17 | HTTP | 
| http_ | WWW組件 |
18 | Java | 
| java_ | Java自編程組件 |
表5-4 Folder/mapplet/Mapping/Session/Workflow命名規范
情形 | 名稱 | 例如 | |
FOLDER | |||
公用文件夾 | 000_Shared | ||
文件夾 | ProductDatabaseSID_OWNER | SFOSS_ EXP5(sfoss是生產阿修羅數據庫sid, exp5是我們要操作的表owner) | |
MAPPLET | |||
MPL_Business Name | MPL_LRNull | ||
MAPPING | |||
單源單目標 | M_Target Table Name | M_TT_WAYBILL | |
多源單目標 | M_Target Table Name | M_TT_WAYBILL | |
單源多目標 | M_1ToN_Function description | M_1ToN__Broadcost | |
多源多目標 | M_NToN_Function description | M_NToN_Gather | |
SESSION | |||
可復用post_S_ | post_S_ mapping name | post_S_M_STGOMS_ORDERS | |
可復用pre_S_ | pre_S_ mapping name | pre_S_M_STGOMS_ORDERS | |
單mapping單session | S_mapping name | S_M_STGOMS_ORDERS | |
單mapping多session | S_mapping name_區域/子系統 | S_M_STGOMS_ORDERS_BJ S_M_STGOMS_ORDERS_GX (BJ代表北京,GX體表廣西) | |
WORKFLOW | |||
單mapping單session | WF_mapping name | WF_STGOMS_ORDERS | |
單mapping多session | WF_mapping name | WF_STGOMS_ORDERS | |
多mapping多session | WF_function description | WF_UpdateUsersAndGroups | |
Schedule | |||
SCHDL_運行間隔_(運行時間)_(截止時間) | 每5分鐘運行一次,2014年5月6號過期 | SCHDL_5MIN_Stop20140506 | |
每5分鐘運行一次,永不過期 | SCHDL_5MIN_FOREVER | ||
每天21:30運行,永不過期 | SCHDL_1Day_AT2130_FOREVER | ||
每月4號21:30運行,永不過期 | SCHDL_1MON_4THAT2130__FOREVER | ||
創建Connection由Informatica管理員完成,但在開發環境和測試中開發人員有修改Connection屬性的權限。
以創建Oracle Connection“Ora_ASURE_SFMAP”為例進行說明
登陸到Informatica 服務器,查看對應的SID“ASURE”是否已經添加到tnsname.ora文件中,否則在tnsname.ora中添加
登陸到Workflow ManageràConnection(連接)àRelationalàSelect Type = “Oracle”àNew…(按鈕)
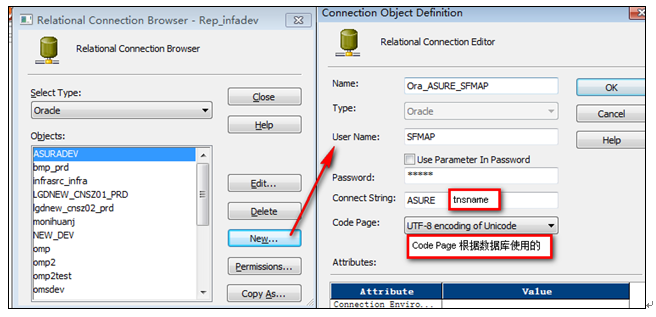
8?1 創建Connection
修改Connection連接的權限,登陸到Workflow ManageràConnection(連接)àRelationalàObjects:選擇需要修改的Connection連接àPermission…(按鈕)à修改屬主。給Others組執行的權限。
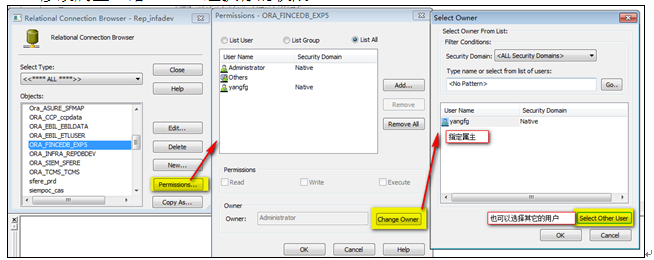
8?2 修改Connection屬主
在創建文件夾前,需要在目標數據創建用戶ETLMGR,腳本在文件夾“ETLMGR”中,請按照順序執行
登陸Repository Manager 參考第5章的命名規則創建文件夾
操作:FolderàCreateà在彈出的對話框中輸入文件夾名稱
不關閉對話框進入下一步
選擇新建文件夾的屬主
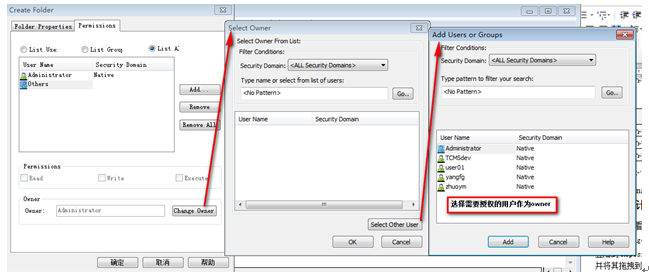
9?1 選擇文件夾屬主
此部分操作由開發從員完成
登陸Repository Manager將文件夾“000_Shared”下的Mapping“M_GetParam”、 “M_getSessionRunStatus”拖拽到新建的文件夾中,并在彈出的創建快捷鏈接對話框選擇“全部確定”。
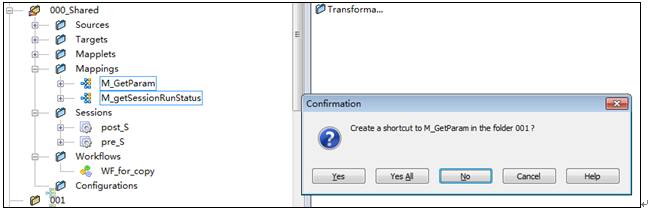
9?2 創建共享Mapping快捷鏈接
登陸Workflow Manager打開新建的文件夾,將文件夾“000_Shared”下的Session “pre_S”、“post_S”拖拽到新建的文件夾中,并在彈出的復制對話框選擇“確定”,
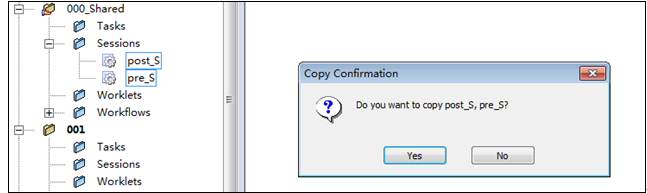
9?3 復制共享Session
然后處理Mapping沖突,為找不到的Mapping重新選擇對應的快捷方式
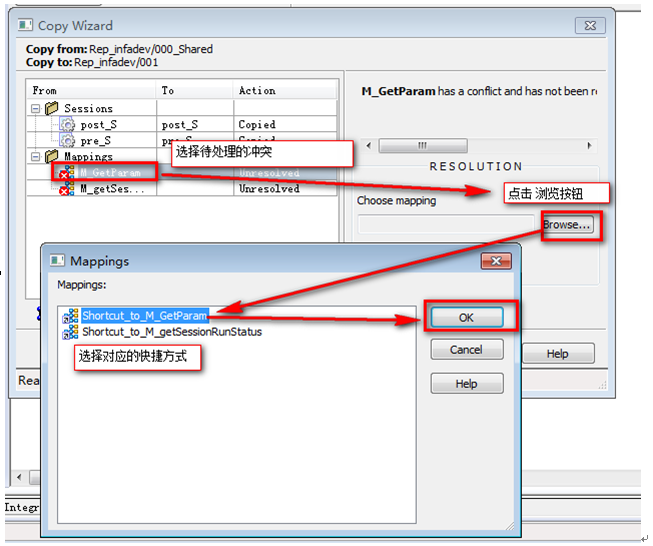
9?4 Mapping沖突處理
沖突處理完接提示選擇下一步并確認,完成這一步驟的操作
登陸到Workflow Manager打開新建的文件夾,編輯“post_S”、“pre_S”源和目標的Connection(連接)
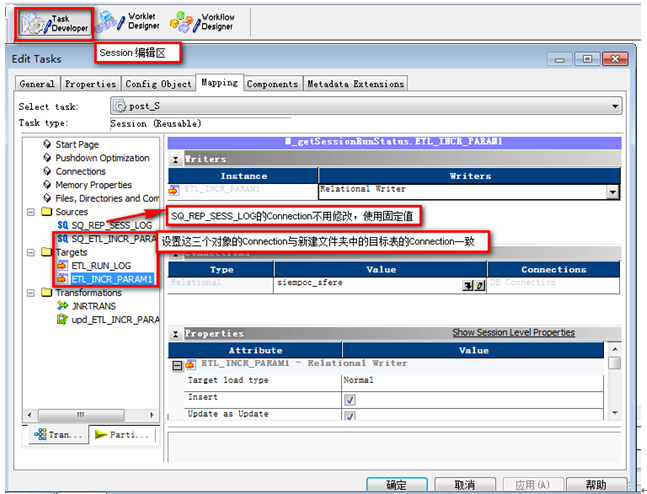
9?5編輯“post_S”
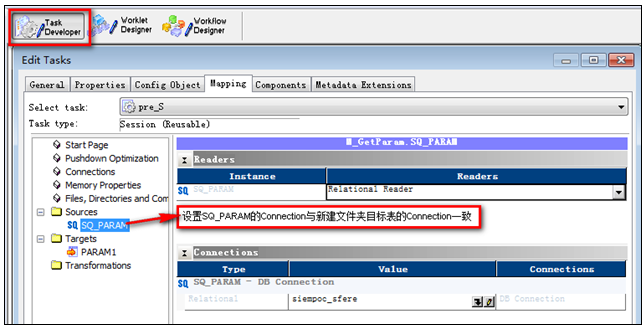
9?6 編輯“pre_S”
注意1:在進行Mapping之前,需要在目標表數據庫的ETLMGR.ETL_INCR_PARAM中插入對應目標表相關的信息,具體內容可能過查詢ETLMGR.ETL_DICT獲得幫助
注意2:ETLMGR.ETL_INCR_PARAM.TIME_BEFORE_NOW(增量結束時間與當前時間的時間差,以秒為單位)的值建議不小于300,以避免一些來不及commit的數據會丟失。
登陸到Designer,本章所述的所有操作均在Designer客戶端。
導入源表結構
創建源表的ODBC連接
EnableNcharSupport: 默認是不打勾的,不打勾的情況下導入char,varchar,varchar2會變成nchar,nvarchar,nvarchar2
ODBC連接只是作為導入源表和目標表的結構的媒介,不會進行實際數據的處理,實際數據的處理由服務端Connection完成
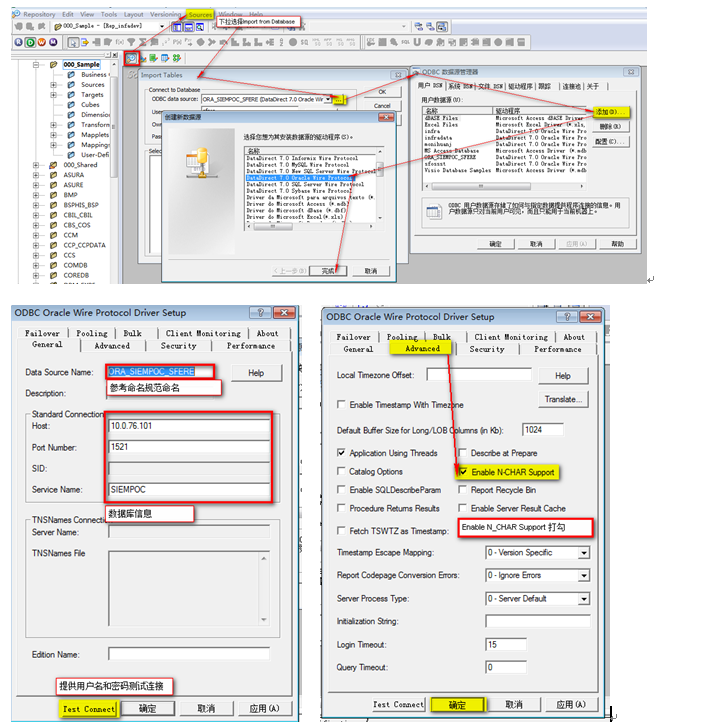
從ODBC連接中導入源表的結構
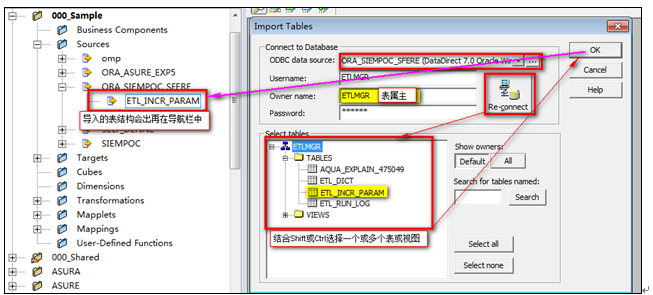
導入目標表結構
導入目標表結構與導入源表結構相似,但是要先切換到目標表的編輯窗口
開發時注意查看客戶端左上方的Folder顯示,一定要在正確的Folder里面工作。
創建Mapping
展開文件夾“000_Sample”,找到Mapping“M_for_copy”并將其拖拽到目標文件夾,在彈出的對話框中選擇“Yes”
根據第五章的命名規范重命名“M_for_copy”并添加注釋
操作:菜單MappingàEdit
Comment(注釋) 內容填寫如下:
Create date: 日期
Create by: 用戶名(現實中文名)
Desc: decription 例:用戶信息交換
[
Modify Date:
Modify by: 用戶
Desc: decription 例:過期用戶信息不再交換
]
所有的Mapping都添加四個參數(Parameter),
操作:在復制Mapping的過程中已經創建
$$INCR_START_DT STRING(20) DEFAULT: 1900-01-01 00:00:00 à增量起始時間(表示增量區間的起點)
$$INCR_END_DT STRING(20) DEFAULT: 2900-01-01 00:00:00 à增量截至時間(表示增量區間的終點)
$$INCR_START_ID DECIMAL(19,0) DEFAULT: 0 à增量起始主鍵值
$$INCR_END_ID DECIMAL(19,0) DEFAULT: 9999999999999999999 à增量截至主鍵值
Mapping具體設計參考文檔《Informatica覺見場景設計》
l 在組件中創建變量時,注意選擇數據類型,選擇長度,在給變量賦值或將變量賦值給字段時要保持數據類型一致,不一致時要使用顯式類型轉換。
l 在做字符處理時,注意NULL,空字符串和空格的區別以及不同的判讀和處理方式
l 不需要輸出的端口不勾選OutputPort。當組件中有重名的字段時,輸入的字段在原字段后加'_IN',變量的字段在原字段后加'_V',輸出字段名盡量保持和下一個組件的輸入字段名名稱一致,以便使用按名稱自動連接
l 數據加載方式:全量,增量
全量: Truncate & Insert
基于時間的增量(具體實現方案參考Informatica常見場景設計)
基于主鍵的增量(具體實現方案參考Informatica常見場景設計)
對于所有的Mapping要求盡量使用增量(增量區間可優先按時間確定,沒有時間戳時按主鍵確定)
對于數據源表確實無法提供增量時間或主鍵的則全量抽取。全量抽取只適用于只適用于數據量小的表,如果數據表的數據量特別大,則需要跟需求方重新確定需求。
l Source Qualifier 組件使用:
對于源系統使用nvarchar2,導入時確保在mapping中使用nstring與之匹配,這樣才能確保字符傳遞的正確性,否則會出現亂碼,字符被截斷等問題
如果Mapping中存儲存在兩個及以上的Source表,同時他們來自相同的源系統,盡量使用Source Qualifier 進行關聯,并在Source Qualifier中添加關聯條件,而不是用Joiner控件
在Source Qualifier中添加增量條件:
時間戳字段>= TO_DATE($$INCR_START_DT,’YYYYMMDD HH24:MI:SS’) And
時間戳字段 < TO_DATE($$INCR_END_DT,’YYYYMMDD HH24:MI:SS’) (注意這里是小于,而不是小于等于) 或
主鍵字段> TO_DATE($$INCR_START_ID,’YYYYMMDD HH24:MI:SS’) And
主鍵字段 <= TO_DATE($$INCR_END_ID,’YYYYMMDD HH24:MI:SS’) (注意這里是大于,而不是大于等于)
l Joiner 組件使用:
對于大表(大于500000行)的連接查詢一定要使用Joiner
使用Joiner控件時,要以小表為master表,同時要對兩組數據進行排序,根據Joiner的字段進行排序,排序一定要使用同一個方式:升序或降序。此時控件中的Sorted input要打勾
l Lookup 組件使用:
盡量使用有連接的Lookup,降低性能風險
Lookup中如果內部有SQL,保證SQL的字段順序和Port的字段順序一致
如果是無連接的Lookup,對于組件的命名采用LKP_返回的字段名稱;如果是有連接的Lookup,如果是返回一個值,那組件的命名采用LKP_返回的字段名稱,如果是多個值,那組件的命名采用LKP_被查詢表名稱
對于小表(小于500000行)的連接查詢使用Lookup控件
對于Lookup維表查找維度ID時,需要在輸出字段添加default value = -1,如下圖:
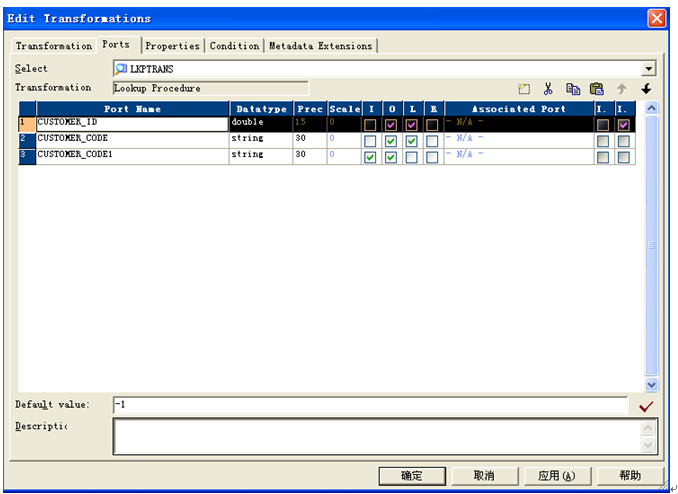
Lookup控件的使用有三種方式,同時注意幾點
1: Connect
對于mapping中對某個表只查詢一次的盡量使用Connect Lookup,在使用Connect lookup的時候對于沒有用到的Column可以刪除掉,防止浪費Cache空間,一定要使用Cache --Lookup Caching Enabled
2: Unconnect
對于mapping中對某個表查詢多次的盡量使用Unconnect Lookup,對于沒有用到的
字段可以進行刪除,防止浪費Cache空間
3: Lookup函數
對于mapping中的Expression中進行查詢的盡量使用Lookup函數
4:Lookup表最好從Targets中獲取,也可以從Sources中獲取
5:Lookup函數不能在mapplet中使用
6:Lookup 使用中的條件允許 Null = Null
l Update Strategy組件使用:
要求目標表有主鍵索引
將SESSION 的屬性設置為UPDATE ELSE INSERT。會導致SESSION 的運行速度明顯的下降,因為INFORMATICA 對每行記錄都執行兩個操作:更新(根據主鍵),如果返回的結果時更新了0 條記錄,再執行一個插入操作。
改變這種情況的辦法是,提前知道在MAPPING 中要執行的是DD_UPDATE,還是DD_INSERT,然后告訴UPDATE 控件采用什么更新策略
不能使用DD_REJECT,可以在Update Strategy組件前添加filter組件將需要做DD_REJECT的數據過濾掉
l AGGREGATOR 組件使用:
在使用Aggregator前,最好對數據進行排序,這樣會極大提高系統性能,此時Sorted Input應該打勾
一個mapping中最好只用一個Aggregator 控件。要使用多個Aggregator可以考慮使用臨時表把mapping拆開
Aggregator與Lookup控件的一起使用時,每個控件都需要索引緩沖、數據緩沖并且他們共享內核里面同樣的HEAP 段,這些內存區域是非常關鍵的,當處理的記錄數量非常巨大時會引起內存的不穩定
當包含它的Mapping速度比較慢時,可以調整Session中的參數:
Maximum Memory Allowed For Auto Memory Attributes 512M
Maximum Percentage of Total Memory Allowed For Auto Memory Attributes 5%
Worklfow運行的時候會從他們中取小的一個值
開發時注意查看客戶端左上方的Folder顯示,一定要在正確的Folder里面工作。
11?1查看工作文件夾
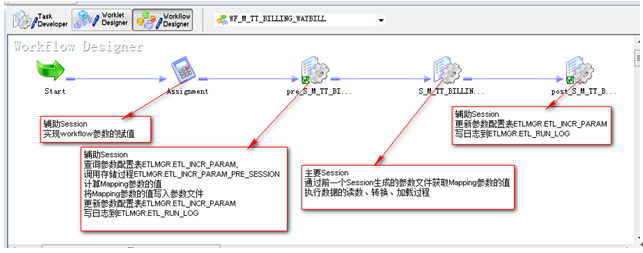
Workflow設計概覽:Workflow設計完成后的樣子及各部分功能
登陸到Repository Manager,打開目標文件夾,展開(不是打開)文件夾“000_Shared”,找到Workflow“WF_for_copy”并將其拖拽到目標文件夾,此時將會彈出一個“Copy Wizard”對話框。在沖突處置中選擇“rename”并按命名規范重命名。
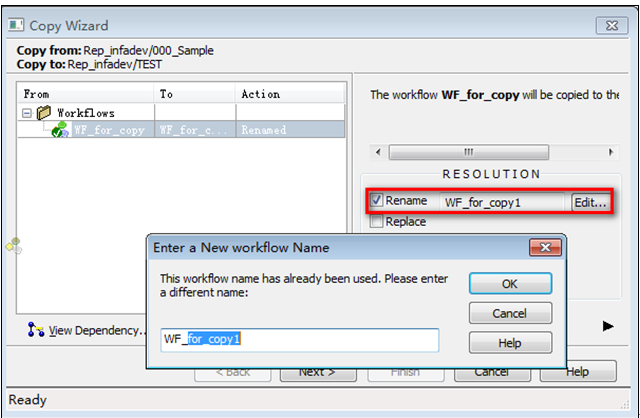
11?2按命名規范重命名
General(通用) ,添加注釋
Create date: 日期
Create by: 用戶
Source table: Source table1
Source table2
……
Target table: Target table1
Target table2
……
Desc: decription 例:將廣西用戶信息同步到集團
[
Modify Date:
Modify by: 用戶名(現實中文名)
Desc: decription 例:添加北京用戶信息同步到集團
]
Properties(屬性)
Enable HA recovery:打勾
Automatically recover terminated task:打勾
Maximum automatic recovery attemps:5
Schedule
創建可復用的計劃
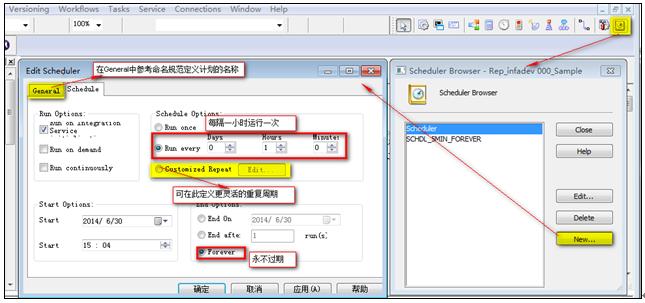
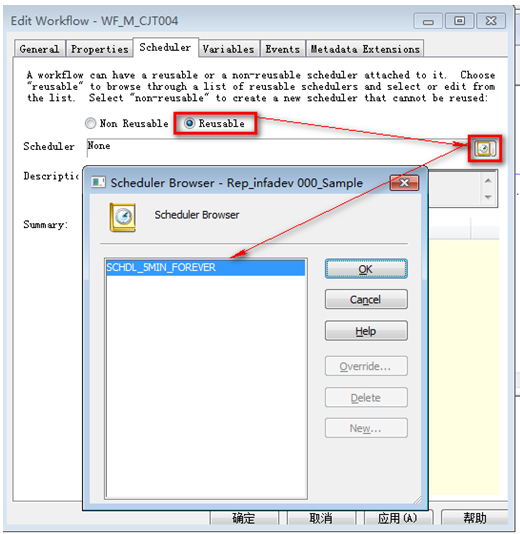
為Workflow分配計劃
如果在文件夾下找不到pre_S”、“post_S”,參考 復制共享對象
將可復用Session “pre_S”、“post_S”,添加到在Workflow中, 并按命名規范重命名,如workflow名為“WF_M_CJN001”,則Session的名稱分別為“pre_ S_M_CJN001”、“post_ S_M_CJN001”
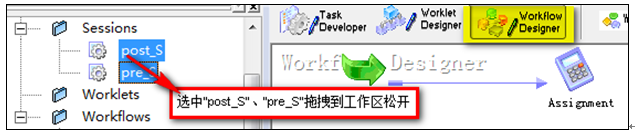
11?3 可復用Session添加到Workflow
修改Session “pre_sql”、“post_sql”的屬性
General屬性
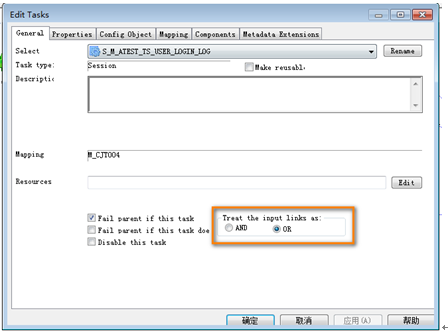
Failed Parent if this task failed:勾選
Treat the input link as: And
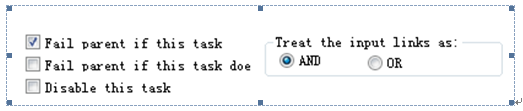
11?4 修改General屬性
Properties屬性
Session Log File Name:FolderName_SessionName.log
(如:000_Sample_pre_S_M_CJN001.log、 000_Sample_post_S_M_CJN001.log)
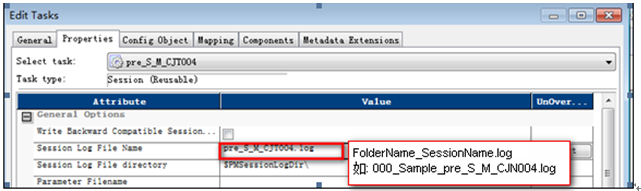
11?5 設置pre_S_*的日志文件
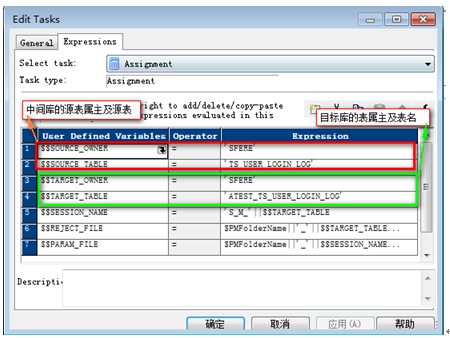
設置$$TARGET_OWNER,$$TARGER_TABLE的值
$$TARGET_OWNER = 目標表的owner
$$TARGET_TABLE = 目標表名
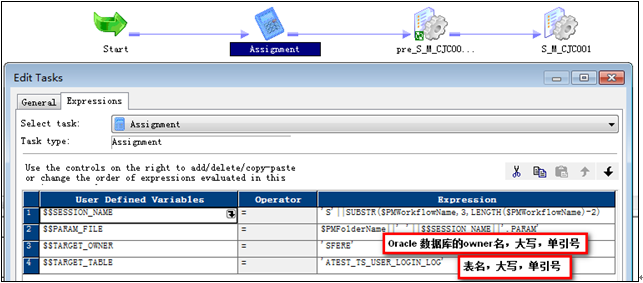
11?6 編輯Assignment
登陸到Workflow Manager,開發時注意查看客戶端左上方的Folder顯示,一定要在正確的Folder里面工作。
登陸到Workflow Manager,,打開Session放置的Workflow
在工具欄的左上角左擊session創建圖標后松開鼠標,然后在工作區任意位置左擊一下彈出Session創建對話框,選擇正確的mapping,并按照5.4規范命名
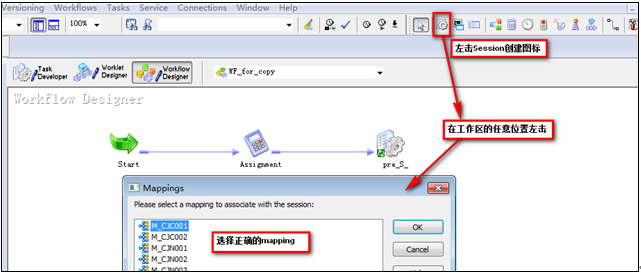
12?1 創建Session
將Assignment、Sessionpre_S_*、新建的Session、post_S_*串聯
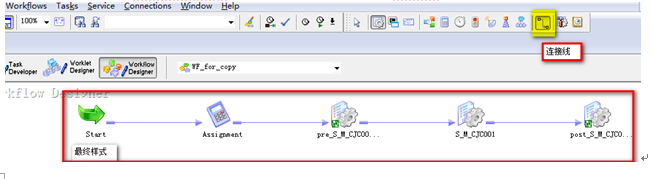
12?2 串聯Session
對于Session的修改和設置一定去到Session工作區設置,盡量不要在Worklet或者Workflow里面做特殊設置,比如指定表名或者指定用戶名等。
Failed Parent if this task failed:勾選
Treat the input link as: And

12?3 General屬性設置
Session Log File Name:FolderName_SessionName.log,(參照樣例,需要手動寫入)
Parameter Filename :
當 增量參數是由pre_S*生成的參數文件控制時:$PMRootDir/BWParam/$$PARAM_FILE (固定值)
當 增量參數不是由參數文件控制時:留空
Treat Source Rows as, 有幾種類型:1: Insert 2:Update 3:Data driven
對于目標表只有Insert的,就選擇,Insert,
對于目標表中存在更新,同時沒有使用UpdateStrategy控件的使用: Update
對于Mapping中使用UpdateStrategry控件的使用Data driven
Commit Interval:默認值10000,當單次加載超過10 0000行時將值設置為100000
Recovery Strategy:
調度增量(或者一次全量)超過500萬 并且 在加載數據之前沒有刪除冗余數據操作的調度 選擇:Resume from last checkpoint
其它:Restart task
Enable high precision:勾選
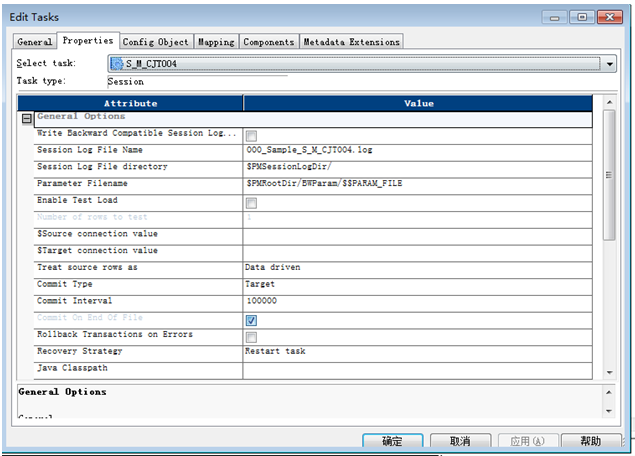
12?4 Properties屬性設置
Default buffer block size
當運行速度較慢時考慮調整
Informatica用來存儲數據的最小單位,默認值12KB。Information初始化Session時,對每個Session分配2個Block作為初始化分配。如果一行數據大于Block的大小時則每一行數據均要移動多個Block,影響執行效率。建議取一行數據最大值的整數倍作為Block的大小。如一行數據的大小是8KB,可以調整Default buffer block size為24KB或者16KB
Maximum Memory Allowed For Auto Memory Attributes
512M 單次取數介于500000行到2000000
1024M 單次取數介于2000000行到5000000
Maximum Percentage of Total Memory Allowed For Auto Memory Attributes: 10%
以上兩個參數通常情況下保留缺省值即可,對于某些占用內存較大的Mapping可以考慮增大,最大不能超過1G,同時他們之中取小的值作為最終值
Save session log for these runs:100,保存最近N次的運行日志
Tips:菜單—>TaskàSession ConfigurationàEditàPropertiesà 將Save session log for these runs 設為100
可修改整個文件夾所有session的“Save session log for these runs”的值
配置源表的連接信息,包括使用的Connection(連接),源表
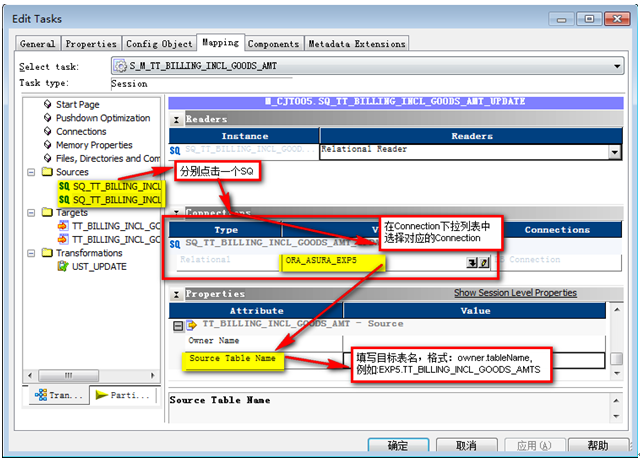
12?5 設置源表的連接信息
檢查源表的過濾條件(可選),默認是繼承mapping中Source Qualifier 中的過濾條件一致,在session里可以進行個性化設置
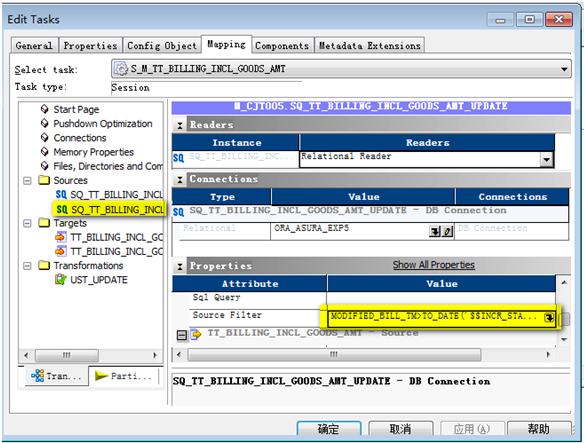
12?6 設置Source Filter
Target load type : Bulk/Normal 對于目標表中存在索引的,Target load type只能選擇l裝載方式。默認值是Bulk,本文要求統一設置成Normal
Tips:可在Workflow Manager中的Tools->Options->Miscellaneous中進行初始設置
Insert: 勾選
Update as Update :勾選,當指定的目標表中只有Update動作時,使用
Update as Insert :不勾選, à當指定的目標表中只有Insert動作時,使用
Update else Insert:不勾選 à 可用于維表或其它主數據表的數據增量操作,如果已經有US更 新策略組件則不用。
Delete :不勾選
Truncate target table option : 通常是全量抽取時,用于目標表需要先進行清除動作時,這個選項要慎重選擇因為會清空全表的數據。默認是末被勾選的。
Reject filename: $$REJECT_FILE
Pre Sql設置數據的重載機制,根據情況添加以下腳本
情況1:按時間增量基于delete-insert方式時填寫以下語句,否則留空
Delete from $$TARGET_OWNER.$$TARGET_TABLE
Where (increment column)>=to_date(‘$incr_start_dt’, ‘YYYY-MM-DD HH24:MI:SS’)
And (increment column)<to_date(‘$incr_end_dt’, ‘YYYY-MM-DD HH24:MI:SS’);
Commit;
情況2:按主鍵增量且基于delete-insert方式時填寫以下語句,否則留空
Delete from $$TARGET_OWNER.$$TARGET_TABLE
Where (increment column)> $$incr_start_ID
And (increment column)<= $$incr_end_ID
Commit;
情況3:全量
留空
Post SQL: 默認留空,如果需要在目標表加載完成在數據庫執行的任務可自行編寫
Target Table Name: $$TARGET_OWNER.$$TARGET_TABLE
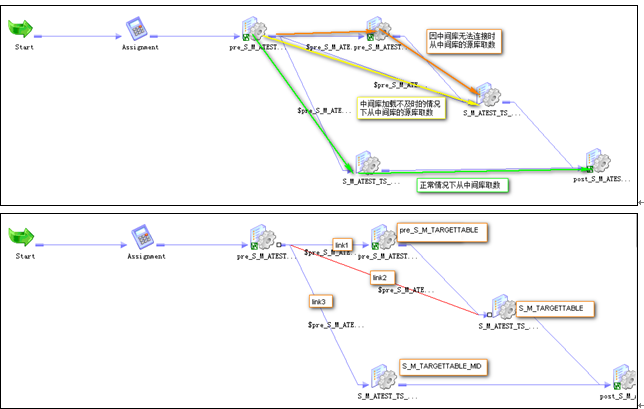
從中間庫取數據時的設計需要在中間庫數據加載不及時的情況下,從中間庫的源庫取數據來避免數據漏采,所以在Workflow中要設計兩個Session分別能從中間庫、中間庫的源庫抽取數據。可復用Session‘pre_s_MID’可以生成當批次的增量時間值,并根據中間庫取數據的及時情況讓其中一個Session空跑。
參考:文件夾000_Sample下WF_M_FOR_MID
注意:以下設計只能針對基于時間的增量。
參考復制共享對象創建‘M_GetParam_Mid’的快捷方式,復制’ re_S_MID’、’post_S_MID’
向目標庫的 ETLMGR.ETL_INCR_PARAM插入所需的數據,ETL_INCR_PARAM.SESSON_NAME = S_M_TargetTable
創建Workflow時從000_Sample 復制WF_for_copy_mid進行重命名。參考 添加可復用Session 添加‘pre_S’,‘pre_S_MID’,‘post_S_MID’
Assignment:跟直接從源庫數據不同,從中間庫取數據時需要檢查中間庫的數據是否及時,所以要指定中間庫的源表。
pre_S_M_ TargetTable:由‘pre_S’重命名而來, 屬性設置與 添加可復用Session 一致。
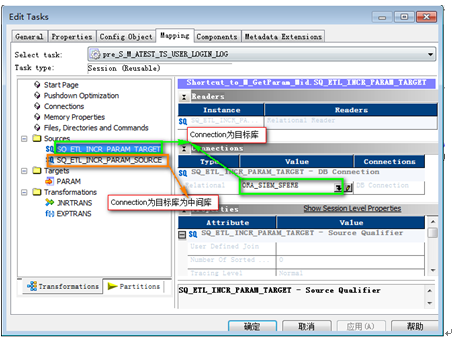
pre_S_ M_ TargetTable_MID:由‘pre_S_MID’重命名而來, 屬性設置與 添加可復用Session 一致,但是要指定兩個源表的Connection分別到中間庫和目標庫.
post_S_ M_ TargetTable:由‘post_S_MID’ 重命名而來,屬性設置與 添加可復用Session 一致.
S_M_TargetTable_MID:屬性設置參考 Session設計 ,源表的Connection指向中間庫
S_M_TargetTable:屬性設置參考 Session設計 ,源表的Connection指向中間庫的源庫,可能需要向管理員申請對應Connection的執行權限。
特殊設置:’treat the input link as ’ = ‘or’
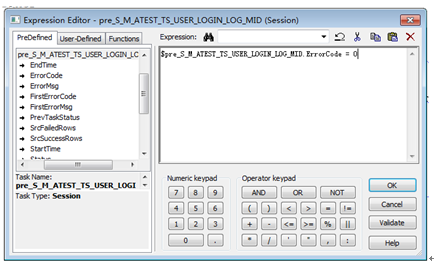
Link1: $pre_S_M_TargetTable_MID.ErrorCode <> 0
Link2: $pre_S_M_TargetTable.ErrorCode = 0
Link3: $pre_S_M_TargetTable.ErrorCode = 0
雙擊連線(link)可以編輯連線的條件
可參考文件夾000_Sample下WF_M_FOR_FTP的Workflow的設計
FTP Connection:在幫助文檔的搜索‘FTP Connection’關鍵字
寫數據到FTP文件時,由于目標不再是數據庫,所以不需要在ETLMGR.ETL_INCR_PARAM設置增量參數的值,也不能在將運行日志寫入日志表中。增量的控制一般采用sysdate(DB參數)來實現。建議每FTP文件的命名帶上時間戳并且在FTP文件順利生成后寫一個標志文件來標志FTP文件順利生成。
1) 習慣點擊Ctrl+S進行Mapping的保存,避免客戶端崩潰造成的不必要損失
2) 習慣性的經常去Refresh Mapping和Validate Session和Workflow,保持Session和Mapping的一致,保持Session的正確可用性
3) 下班前及在進行重大修改前對相關內容做備份,備份操作參考12章
登陸到Repository Manager
備份Workflow
操作:選擇需要備份的Workflow(結合Shift及Ctrl可多選)à右鍵àExport(導出)à選擇保存路徑并填寫文件名稱à點擊保存按鈕
上述操作會備份Workflow及Workflow所有子對象如:Session、Mapping、Source、Target等
備份Mapping
操作:選擇需要備份的Mapping(結合Shift及Ctrl可多選)à右鍵àExport(導出)à選擇保存路徑并填寫文件名稱à點擊保存按鈕
上述操作會備份Mapping及Mapping的所有子對象如: Mapping、Mapplet、Source、Target等
備份其它對象,參考上述兩種備份操作
登陸到Repository Manager
操作:菜單RepositoryàImportant Objectà選擇需要導入的XML文件,打開à選擇下一步à選擇需要導入的對象à選擇并確認目標文件夾àImportà (有沖突時會出現)處置沖突的解決方法à下一步
Tips:在處置沖突時可對多外對象應用相幾的處置方法
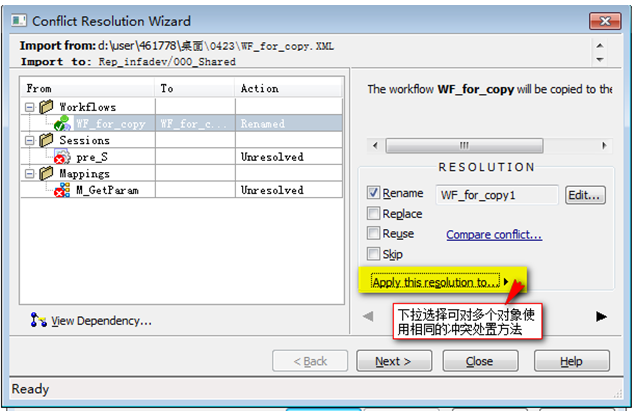
14?1 導入對象時處置沖突

解決方法:檢查Workflow、Session的命名規范,如'S_M_TCMS_TM_DEPARTMENT'寫成
's_M_TCMS_TM_DEPARTMENT'
看完上述內容,你們掌握INFORMATICA 開發規范有哪些的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





