溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
我們的 目標 是
理解Oracle數據庫管理系統,并由此串聯梳理一下核心關鍵詞。
數據庫管理系統就像是一 張 網 ,關鍵詞就是網上的交叉點。我們并不會詳細解釋具體每個關鍵詞的意思,百度或者官方文檔會有詳細說明,點到為止,有個全貌,混個臉熟。
不知者,有個印象,知之者,了然一笑。如是而已。
先說 Oracle, 但說Oracle之前,又得先提一下 IBM
IBM( 國際商業機器公司 )或萬國商業機器公司,簡稱IBM(International Business Machines Corporation)
名字就那么大氣磅礴,至今也是如雷貫耳。
關鍵是里面牛人輩出。
首先是這一位 :

他叫 E.F.CODDE 。 對了,他的名字就是一個很重要的關鍵詞。因為他是關系數據庫的達摩祖師。
1970年,E.F.CODDE 發表 《 大型共享數據庫數據的關系模型》,首次明確而清晰地為數據庫系統提出了一種嶄新的模型, 即 關系模型 。
一聲霹靂,石破天驚。

緊接著,同樣是IBM牛人的 唐.錢柏林( Don Chamberlin )登場了。他就是 SQL 之父。E.F.CODD只是在數學層面解決了關系代數的研究,而Don Chamberlin 將關系代數 翻譯成能夠在計算機中簡單實現的語言,也就是SQL。

所謂 關系代數 包括
并、差、交、笛卡爾積等集合運算
和
選擇、投影、連接、自然連接、外連接、除法等關系運算。
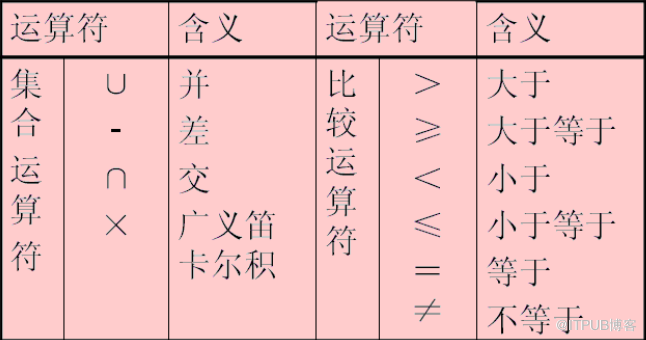
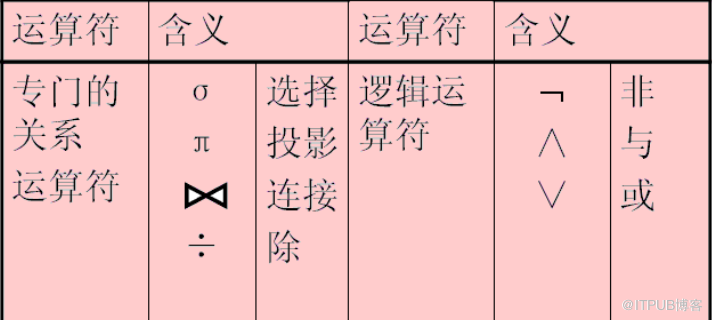
而SQL語言,我們再熟悉不過了。沒有它,關系數據庫,就是一潭死水。
SQL和關系數據庫同樣重要!
理論具備,接下來就是怎么用的問題了。當然像SQL標準化之類的問題,是一個逐步角逐的問題,需要時間的沉淀。所有計算機協議和標準都可作如是觀。最后,書同文,車同軌都是大勢所趨,也勢在必然,不然,雜亂無序,只能是一盤散沙,談何萬物互聯。
一個具有敏銳商業嗅覺的人,聞風而動。
他就是 拉里·埃里森(Larry Ellison)。 他組建了一個四人團隊,如下圖:

最右邊的就是 拉里·埃里森(Larry Ellison),而手捧蛋糕的就是 Bruce Scott。
Scotte,Oracle數據庫里的一個保留測試賬號,密碼tigger,就是他的貓的名字。
創業維艱,但也可以說順風順水。
Oracle迎合潮流而上,站在浪潮之巔。
下圖就是如今Oracle在加州的總部。可以看出,氣勢恢宏,財大氣粗。盡管Oracle經過兼收并購,多維發展,不僅僅是一個數據庫廠商了,但數據庫造型的大樓,也標示著它是依靠數據庫起家的。

再說 數據庫 不需要過多解釋,顧名思義而已,存儲數據的倉庫。只是隨著互聯網的發展,如今,數據庫又分 關系數據庫 和 非關系數據庫 ,Oracle數據庫,就是關系數據庫,當然也包括Mysql,MS-SQL Server,PostgreDB。 非關系數據庫,就有點魚龍混雜,百家爭鳴的特色了。如MangoDB,HBASE,Redis, Cassandra. 盡管解釋他們的時候,吹噓 NoSQL 是一項全新的數據庫革命性運動,什么“Not only SQL”,但我認為,非關系數據庫相比關系數據庫來說,沒那么偉大,沒那個劃時代。它只是對關系數據庫的變革和改良。因為關系數據庫,嚴謹周密,也就會負重而行。對于有些 應用場景 ,不需要那么嚴謹,只需要輕裝上陣,實現需要的功能即可,什么 ACID , 數據一致性 , 范式 等都將成為累贅。所以非關系數據庫,簡單一點說,有如下特點:
1.針對特定應用場景,功能單一化。
2.不支持ACID機制,這也是關系數據庫的一個基石。
3. 使用相對簡單,沒有入Mysql,Oracle這樣龐大的體系結構。
4. 大部分都是開源的。
記得我十幾年前,MySQL還是一個定位中小型的數據庫,簡陋,不支持事務,讀寫還是阻塞的等等,作為一個MySQL DBA 是很low的,而如下,Mysql DBA招聘信息琳瑯滿目,而且報酬豐厚,嫣然已經力壓Oracle DBA。因為現在Mysql,InnoDB都是Oracle公司旗下,二者親密結合,能量級倍增。關系型數據庫產品趨于雷同。而且很多問題,都變成了一個架構問題,而Mysql很多欠缺,都可以通過架構來解決。 當然,免費也是一個問題,但對于很多沒有那么復雜業務的公司,他們用不了成千上百臺數據庫服務器(像亞馬遜,他們購買數據庫產品的費用就不容小覷),數據庫產品的費用對于他們的來說,是九牛一毛。而穩定和快捷有效的服務支持才是他們更應該關注的,穩定壓倒一切。所以Oracle依舊是他們的首選。
所以,隨著開源的關系數據庫產品的壯大完善,以及NoSQL數據庫的百家爭鳴,Oracle隨不能說 風光不再,但也不能再說 如日中天。
作為一個DBA,應該懂得更多。
如履薄冰,戰戰兢兢!
憂心忡忡,兢兢業業!
憂患意識,是每個DBA必需的,尤其是技術快速發展的今天。
再說 數據庫管理系統
官方文檔如是說:
A database management system (DBMS) is software that controls the storage, organization, and retrieval of data.
Stroage( 存儲 ),Organization( 組織 ) ,Retrieval( 檢索 )
它 首先是一套 軟件 ,只不過它龐大、復雜,是一個系統層面的軟件。但終歸還是一個軟件,有著軟件的一般特性。
軟件也就是一系列程序的集合。 程序 是死的,是靜態的文件,需要讓它動起來才能工作。程序被加載進內存中,在內存中活動起來,就表現為 進程 。所以,它依賴于CPU,內存等資源。進程不是尸位素餐,然后死去萬事空。計算機不養閑人,占了地方不干活或者不干正事的,那就是病毒。有用的進程是要干活的,是要開花結果的,這些結果是大部分時候要存儲下來,需要做持久化保存。這就是外存的作用。 畢竟是數據庫,既是數據,還是庫,怎能飄然無蹤,不做持久存儲。
所以,我應該關注:
內存,CPU , 存儲,進程狀態,這操作系統和硬件層面的因素,在日常的監控和優化時,需要經常關注。
當然,搭建環境(包括軟硬件環境)的時候,更應該關注這些因素。特別是 存儲架構, I/O吞吐量 ,必須得到保證,I/O分流均衡也是重重之重。畢竟數據庫是I/O密集型的應用。好的開始,就是成功的一半,架構好,后面垂拱而治有望,架構差,后面疲于應付難免。
“” 時時勤拂拭,勿使惹塵埃 “”
貼一張《鳥哥的Linux私房菜》的圖片,基礎,但卻不容忽視。
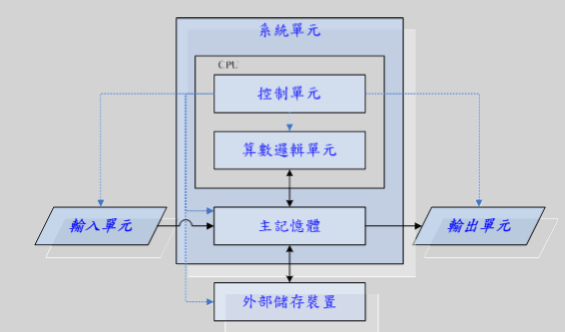
進入數據庫內部,我們就應該關注:
內存結構 , 進程狀態和功能,以及存儲結構
這些都是學習任何一套軟件的基本套路,因為計算機的底層都一樣,內存,CPU,I/O,外部存儲。
下面的幾張圖中,基本上都是關鍵詞,可以細細品味哦。對于初學者,想了解里面的原理,最好是看圖默想和通過一些視頻學習,快速學懂,通過官方文檔或者是二手說明文字,可能云里霧里
內存結構和進程:
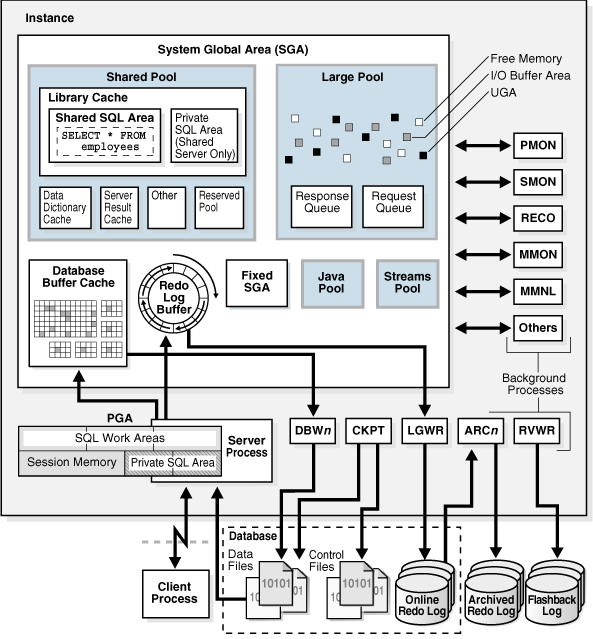
存儲結構(物理結構):主要就是一系列文件:
關鍵文件: 控制文件,數據文件,和在線重做日志文件。
控制文件是中樞,數據文件是基本,在線重做日志文件是保障
三大文件,缺一不可。
非關鍵文件: 參數文件,密碼文件,歸檔日志文件,告警文件,跟蹤文件,備份文件
存儲結構(邏輯存儲):
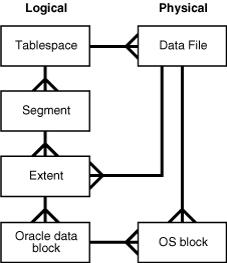
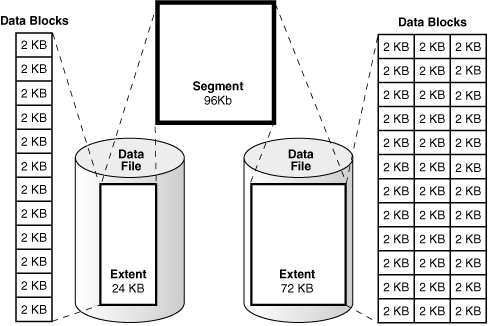
這里需要特別說明一下的是 數據塊。
官方如是說:
A data block is the smallest logical unit of data storage in Oracle Database.
One logical data block corresponds to a specific number of bytes of physical disk space, for example, 2 KB. Data blocks are the smallest units of storage that Oracle Database can use or allocate.
數據塊
是數據存儲在Oracle數據庫的最小邏輯單元。
一個邏輯數據塊對應于物理磁盤空間的特定字節數,例如,2KB。數據塊是Oracle數據庫可以使用或分配的最小存儲單元。
就像一個盒子,里面放著我們的存儲的數據,也就是表中一行一行的數據。每次從磁盤中抽取數據的時候,都是去拿盒子,然后放入內存中。內存中對應的就是 buffer,也就是內存中的一個盒子。計算機中存儲的都是0和1,所以盒子,也就塊,只是一個邏輯概念上的封裝。塊是一個邏輯概念,但是存儲中中一切概念的基礎。
I/O吞吐量是以塊為單位的,
性能指標本質上就是 獲得多少塊 和 用了多少時間 的權衡。
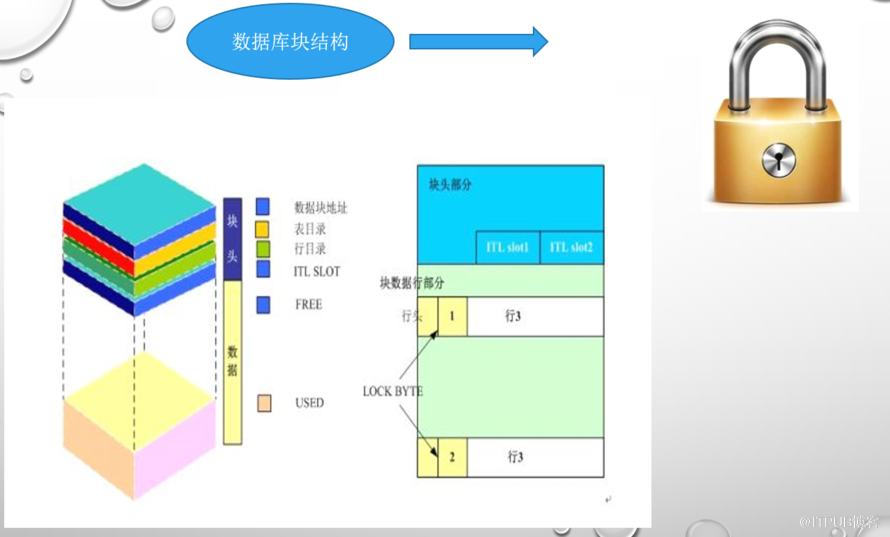
封裝,因為要傳輸。就像郵寄包裹要打包一樣。包裹上要寫上地址信息,這在TCP/IP中,我們再熟悉不過了,層層打包,層層封裝。包郵包頭,塊有塊頭。
塊頭 ,至關重要。因為它存在了事務信息,鎖信息等,這可是關系數據的基礎哦。
凡事都有頭,塊有塊頭,區有區頭,段有段頭,此種套路,在計算機中,由來已久,甚至與生俱來,所以不容忽視。
最后再說 數據庫 ,這里說的是關系數據庫。那么我們就必須知道什么是 關系 。
E.F.CODD提出的關系模型。數學家的論文,我們看不懂,但有人幫我們看懂就行。
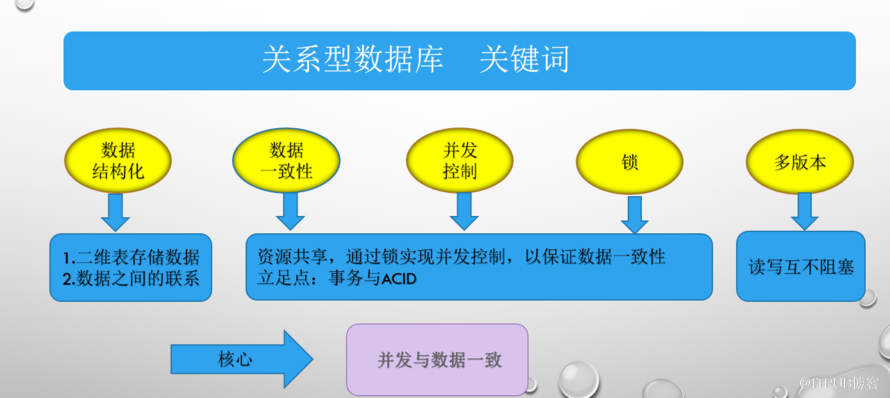
關系,就是 二維表 。
在定義關系的時候,科學家做了一系列的工作,我們也沒有必要跟走一遍,有興趣當然可以嘗試。
科學家為了定義關系,以及為了解決 數據庫設計的時候 冗余 和 一致性 問題而設計出一系列的規范。
所謂規范,遵守即可,因為科學家已經論證過,這是對的。
規范也就是范式,大部分情況,我們設計數據庫都應該遵守規范,符合范式要求。但也只是大部分情況,有些情況,為了迎合一些特例,就需要 做 反范式設計 。
所謂反范式設計,也就是故意冗余,將一致性問題交給應用和業務邏輯。以空間換取時間。
說到數據一致性,可以說是結構化數據,也就是關系數據庫的一個基石。一個人去修改一個數據,沒有不一致的,但數據庫管理系統不可能是單一操作的,要不怎么能說它龐大,繁雜呢。 很多人一起訪問修改是必然的,也就是 并發 。
并發,是 數據一致性的天敵。道理不言自明。
要兩者和諧相處,談何容易? 于是 鎖 就閃亮登場。 它是 并發 和 數據一致性 調節者。
但 鎖 是為調節而生的。調節,其實很粗暴。
哲學上說,時間的絕對和空間的相對。 在同一個時間點,一個數據結構,只能是一個人修改。鎖,就是讓其他人等待,等待就會產生 阻塞 。于是性能問題就出來了。。。
如果沒有鎖,就沒有等待(當然,一些空閑等待,不在這個考慮范圍內),也就沒有阻塞,數據庫會運行的暢通無阻,但這在關系數據庫系統中是不可能的。
但是,在非關系數據庫中,這是可能的,因為它們可能放棄了鎖,為什么能夠放棄? 因為它們剔除了對同一資源爭議的情況,也就是不要并發了。因為業務不需要。 符合業務需要,又能健步如飛。
end
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





