溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“怎么診斷SQL中library cache: mutex X等待”,在日常操作中,相信很多人在怎么診斷SQL中library cache: mutex X等待問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”怎么診斷SQL中library cache: mutex X等待”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
該機制是用于保護內存結構,在 library cache 中有許多內存結構需要 library cache: mutex X 的保護。
library cache 用來保存解析過的 cursor 相關的內存結構。
等待 library cache: mutex X 與之前版本的 latch:library cache 等待相同。library cache: mutex X 可以被很多因素引起,例如:(包括應用問題,執行計劃不能共享導致的高版本的游標等),本質上都是某個進程持有 library cache: mutex X 太長時間,導致后續的進程必須等待該資源。如果在 library cache 的 latch 或者 mutex 上有等待,說明解析時有很大的壓力,解析 SQL 的時間變長(由于 library cache 的 latch 或者 mutex 的等待)會使整個數據庫的性能下降。
由于引起 library cache: mutex X 的原因多種多樣,因此找到引起問題的根本原因很重要,才能使用正確的解決方案。
*大量的硬解析:過于頻繁的硬解析,會導致該等待。
*高版本的游標:當發生 High version count 時,大量的子游標需要檢索,從而會引起該等待。
*游標失效:游標失效是指,保存在 library cache 中的游標由于不可用,而從 library cache 中刪除。游標失效是指某些改變導致內存中的游標不再有效。例如:游標相關對象的統計信息搜集;游標關聯表,視圖等對象的修改等。發生游標失效會導致接下來的進程需要重新載入該游標。當游標失效過多時,會導致 ‘library cache: mutex X’ 等待。
*游標重新載入:游標重新載入是指本來已經存在于 library cache 中,但是當再次查找時已經被移出 library cache(例如:由于內存壓力),這時就需要重新解析并且載入該游標。游標重新載入操作不是一件好事,它表明您正在做一件本來不需要做的事情,如果您設置的 library cache 大小適當,是可以避免游標重新載入的。游標重新載入的時候是不可以被進程使用的,這種情況會導致 library cache: mutex X 等待。
*已知的 Bug。
library cache: mutex X – 用于保護 handle。
library cache: bucket mutex X – 用于保護 library cache 中的 hash buckets。
library cache: dependency mutex X – 用于保護依賴。
確認是否存在一些改變:
a. 負載是否增長?
b. 是否有應用、操作系統、中間件的改變?
該等待的出現的趨勢:
a. 確認該等待是否在每天的固定時刻產生?
b. 是否做了一些操作觸發該等待?
生成問題發生時刻的 AWR 和 ADDM 報告,與基線或者正常時間段的 AWR 和 ADDM 報告比較,是否有負載,參數等的改變和不同。
有時使用systemstate dump 可以用來匹配已知的問題,例如:在 AWR 中沒有發現明顯的 SQL 時、通過 systemstate dump 捕獲阻塞進程和被阻塞進程的信息,可幫助發現潛在的問題。
當systemstate dump 不適合收集時(因為它消耗資源較多)。這時定期執行如下 SQL,來確定哪些進程和 SQL 在等待 library cache: mutex X。
select s.sid, t.sql_text
from vvsql t
where s.event like ‘%mutex%’
and t.sql_id = s.sql_id
正常情況下,我們可以從 AWR 中看到 library cache: mutex X 是 TOP 事件: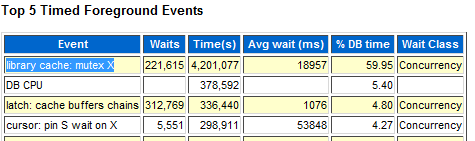
定位出硬解析和高版本的 SQL,點擊“Main Report”下的“SQL Statistics”鏈接
定位解析比較高的 SQL: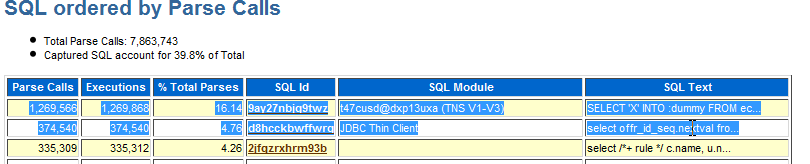
注意比較高的解析比例的 SQL,理想情況下解析和執行的比例應該很低,如果該比例很高說明應用中沒有很好的使用游標,游標解析并且打開之后應該保持打開狀態,與開發人員確認如何保持游標打開,避免下次執行該 SQL 時重復解析。
下一步檢查 SQL 高版本: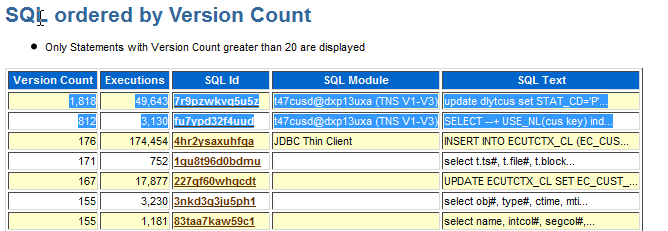
檢查是否存在較高的硬解析,因為硬解析會引起 SQL AREA 的重新裝載,通過 load profile 確定硬解析的數量。
2.對于 SQL AREA 的重新加載也要進行檢查: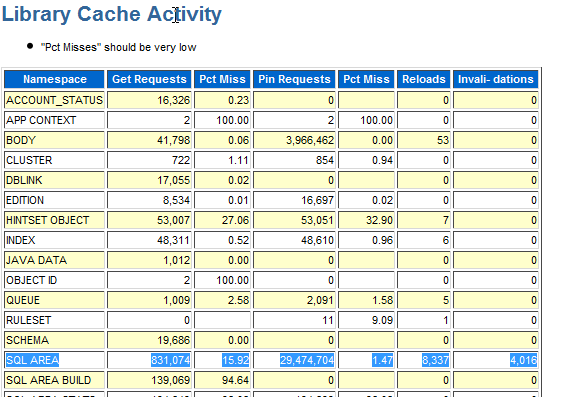
如果在 SQL AREA 上的重新加載次數很高,那么需要檢查游標是否被有效共享(重新加載的次數是指被緩存在 shared pool 中,但是使用時已經不在 shared pool 中)。如果游標已經有效共享,那么需要確認 shared pool 和 sga_target 是否足夠大,如果 shared pool 有壓力而沒有足夠的空間,那么有些緩存的游標會被從 shared pool 中清除。如果游標共享不充分,shared pool 會被這些不能被重用的游標占滿,從而把那些可以重用的游標擠出 shared pool,進而引起在這些 SQL 重新執行時需要重新加載。游標共享充分,但由于 shared pool 空間過小也會引起可重用的游標被清除從而引發硬解析。
在“Library Cache Activity”下檢查 invalidations,如果 invalidations 過高,需要確認是否有大量的 DDL 操作,例如: truncate, drop, grants, dbms_stats 等
4.對于 11G,確認 cursor_sharing 不是 similar,因為該值已經不建議使用,并且會引起 mutex X 等待
到此,關于“怎么診斷SQL中library cache: mutex X等待”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





