溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
一條俊俏的 SQL 被一個懵懂的少年,扔向了深遠的 TCP 隧道,少年苦苦等待,卻遲遲等不來那滿載而歸。于是少年氣憤,費盡苦心從度娘那邊求來的一手好代碼,等來的卻是 timeout…
如果你也正在經歷著這些苦澀的等待,那么該了解執行計劃了;如果你自認為執行計劃已經了如指掌,那么你該讀一讀 SQL Server 2017 新特性, adaptive query processing , 我蹩腳的將其翻譯為 “自適應查詢處理”。
在講解概念之前,首先要對內存分配要有清晰的理解。一個查詢請求在執行完畢之后,會有詳細的內存分配指標和統計值附加在它的執行計劃屬性上。這些內存分配指標和統計值,分別是執行前預估的內存分配和最佳內存大小以及運行中被分配的內存大小。
如果一開始內存預估分配不準確,在執行的時候,就會分配不到合理的執行內存,導致整個查詢期間,頻繁的往 tempdb 里面去做spill(這個詞真不好翻譯,有緩存溢出的意思,即內存裝不下,暫交給 tempdb 存儲的意思), 將不能被當前內存空間容納的數據緩存到 tempdb 里面,利用硬盤IO來緩存數據,比起內存存儲效率差了很多。因此在執行前就需要保證預估的數據量大小和需要的內存比較精確。 這里需要對統計信息 (statistics)做實時更新,以便預分配內存準確。
Brentozar 有個實例可以很好的解釋和解決這個問題:
https://www.brentozar.com/blitzcache/tempdb-spills/
換句話來說,對即將執行的查詢,分配足夠多的內存,那么該查詢的執行所需的數據,就完全可以在內存中處理,而不會溢出到硬盤。從而查詢速度就快。
如果發生 spill 會有系統提示,這必須依靠執行計劃才能鋪捉到
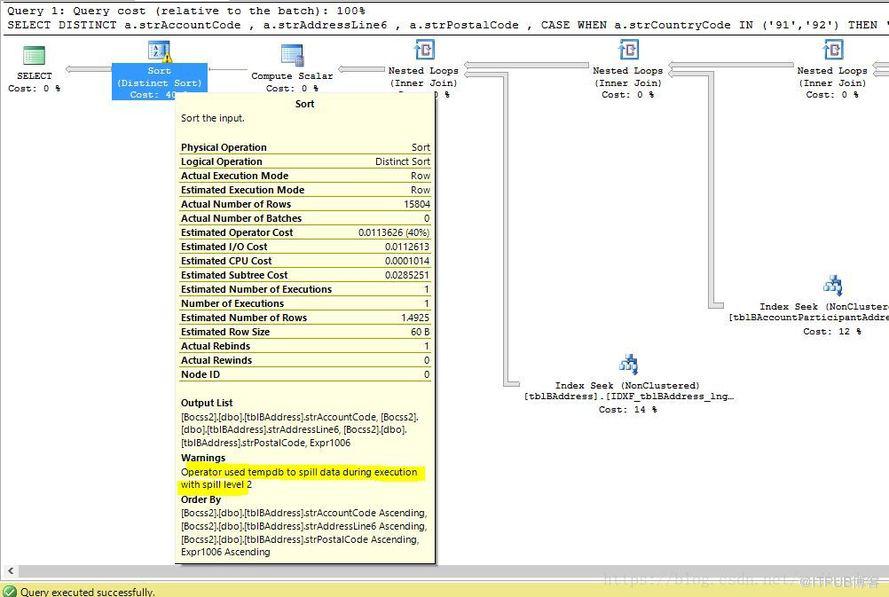
在 SQL Server 2017 出來之前,需要掌握 DBA 知識才能意識和掌握處理這類事情。但 SQL Server 2017 之后,作為普通的一名開發者,完全可以忽略這類問題,因為 adaptive query processing 已經幫我們在幕后優化這類 SQL.
如上所說,SQL 執行完畢之后,會將執行計劃與執行環境( execution context)一起緩存。Adaptive Query Processing 引入了 Batch Mode memory grant
feedback. 執行引擎通過對執行計劃緩存屬性的校驗,可以發現請求的執行過程中,是否發生了 spill,對于發生 spill 的情況,引擎會對這份執行計劃做重估,一旦發現如統計信息過期 等導致的 spill, 就會用最新的統計信息去重估執行計劃,更新執行計劃中分配內存的策略,要么降低內存分配提高并發中內存需要,要么提高內存,減少 spill 的發生概率。這些校驗都回反饋給 memory grant feedback, 由 它采用最新的策略,去更新執行計劃緩存。
上述講的是自適應查詢處理( Adaptive Query Processing)中 Batch Mode Memory Grant Feedback 的一個自動處理特性,被稱為 memory grant feedback sizing. 除此之外,SQL Server 2017 還帶來了更多的智能優化策略, 自動化完成 DBA 的部分工作。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





