溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
??本來以為一篇就能搞定,還是低估了自己的廢話,好吧,只能通過兩篇文章向大家介紹K8s核心原理。
??kubernetes API server的和核心功能是提供了kubernetes各類資源對象(pod、RC 、service等)的增、刪、改、查以及watch等HTTP Rest接口,是整個系統的數據總線和數據中心。有時候我們使用kubectl創建或者查看pod等資源的時候,發現沒有反應,可能就是你的kube-apiservice服務異常退出導致的。
??Kubernetes API server通過一個名為kube-apiservice的進程提供服務,該進程運行與master節點上。默認情況下該進程的端口是本機的8080提供restful服務。(注意如果是HTTPS,則是6443端口)。
??接下來的一些操作,介紹一些如何通過rest 與kubernetes API server交互,這有便于后各k8s各個組件之間通信的理解:
[root@zy ~]# kubectl cluster-info #查看主節點信息
[root@zy ~]# curl localhost:8080/api #查看kubernetes API的版本信息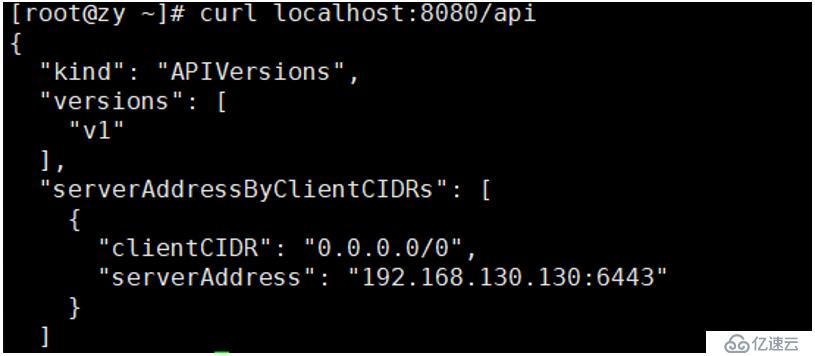
[root@zy ~]# curl localhost:8080/api #查看kubernetes API支持的所有的資源對象
當然我們也可以訪問具體的資源
[root@zy ~]# curl localhost:8080/api/v1/pods
[root@zy ~]# curl localhost:8080/api/v1/services
[root@zy ~]# curl localhost:8080/api/v1/replicationcontrollers當我們在運行kubectl get svc時會發現:
??有一個以上話紅框的服務,這個是什么呢,原來為了讓pod中的進程能夠知道kubernetes API server的訪問地址,kubernetes API server本身也是一個service,名字就叫“kubernetes”,并且他的cluster IP 就是cluster IP地址池例的第一個地址,另外它服務的端口就是443。
??kubernetes API server還提供了一類很特殊的rest接口—proxy接口,這個結構就是代理REST請求,即kubernetes API server把收到的rest請求轉發到某個node上的kubelet守護進程的rest端口上,由該kubelet進程負責相應。
舉例:
masterIP:8080/api/v1/proxy/nodes/{node_name}/pods #某個節點下所有pod信息
masterIP:8080/api/v1/proxy/nodes/{node_name}/stats #某個節點內物理資源的統計信息
masterIP:8080/api/v1/proxy/nodes/{node_name}/spec #某個節點的概要信息#接下來說一下比較重要的pod的相關接口
masterIP:8080/api/v1/proxy/namespaces/{namespace}/pods/{pod_name}/{path:*} #訪問pod的某個服務接口
masterIP:8080/api/v1/proxy/namespaces/{namespace}/pods/{pod_name} #訪問pod假如這里有一個名為myweb的Tomcat的pod
我們在瀏覽器中輸入masterIP:8080/api/v1/proxy/namespaces/{namespace}/pods/myweb就能訪問到該pod的http服務了。
如果這里是一個幾個web的pod組成的service的話:
masterIP:8080/api/v1/proxy/namespaces/{namespace}/services/{service_name} 就能訪問到其下面的服務,當然最終會通過kube-proxy被定位到相應的pod下。
??Kubernetes API Server作為集群的和核心,負責集群各功能模塊之間的通信。集群內的各個功能模塊通過API server將信息存入etcd,同樣的想要獲取和操作這些數據時,也是通過API Server的REST接口(GET、LIST、WATCH)來實現,從而實現各個模塊之間的交互。
接下來小編通過一張圖,簡單介紹一下幾種典型的交互場景: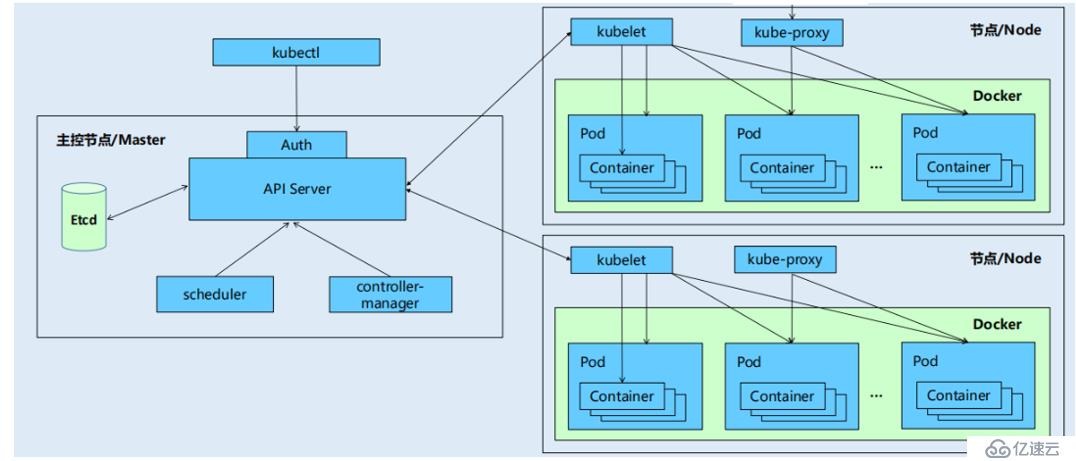
??介紹:Controller Manager作為集群內部管理控制中心,負責集群內的Node、Pod副本、EndPoint、命名空間、服務賬號、資源定額等管理。當某個Node意外宕機了,Controller Manager會及時發現此故障并執行自動修復流程,確保集群始終處于預期的工作狀態。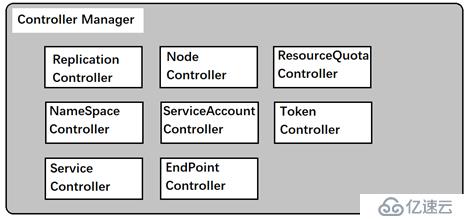
??由上圖所示,Controller Manager中包含很多個controller,每一種controller都負責一種具體的控制流程,而Controller Manager正是這些controller的核心管理者。一般來說,智能系統和自動系統都被稱為一個“操縱系統”的機構來不斷修正系統的工作狀態。在kubernetes集群中,每個controller都有這樣一個“操縱系統”,他們通過API Server提供的接口實時監控整個集群里的每一個資源對象的當前狀態,當發生各種故障導致系統狀態發生變化,這些controller會嘗試將系統從“現有裝態”修正到“期望狀態”。
接下來小編會介紹一些比較重要的Controller。
??在介紹replication controller時小編要強調一點的是,千萬不要把資源對象的那個RC和這個replication controller弄混淆了,我們這里介紹的replication controller是副本的控制器,RC只是一個資源對象,上層是replication controlle管理各個RC。(這里我們統一的將replication controller叫副本的控制器,資源對象RC叫RC)。
??副本的控制器的核心作用是確保任何使用集群中的一個RC所關聯的Pod副本數量保持預設的值。如果發現Pod副本數超過預設的值,則副本的控制器會銷毀一些Pod的副本,反之則創建一些新的Pod的副本以達到目標值。值得注意的是只有當Pod的重啟策略是always時,副本的控制器才會管理該pod的操作。通常情況下,pod對象被成功的創建之后不會消失,唯一例外的是當pod處于success或者failed狀態的時間過長(超時時間可以設定),該pod會被系統自動回收,管理該pod的副本的控制器將在其他的工作節點上重新創建、啟動該pod。
??RC中的Pod模板就像一個模具,模具制作出來的東西一旦離開模具,二者將毫無關系,一旦pod創建,無論模板如何變化都不會影響到已經創建的pod,并且刪除一個RC 不會影響它所創建出來的Pod,當然如果想在RC控制下,刪除所有的Pod,需要將RC中設置的pod的副本數該為0,這樣才會自動刪除所有的Pod。
replication controller(副本的控制器)的職責:
?? - 確保當前管理的Pod的數量為預設值
?? - 通過調用RC的spec.replicas屬性實現系統擴容和縮容
?? - 通過改變RC中的Pod的模板中的image,來實現系統的滾動升級
replication controller(副本的控制器)的使用場景 :
?? - 重新調度:無論是否有節點宕機,還是pod意外死亡,RC都可以保證自己所管理的正在運行Pod的數量為預設值
?? - 彈性伸縮:實現集群的擴容和縮容(根據集群的可用資源和負載壓力)
?? - 滾動升級:應用服務升級新的版本,并且保證整個升級過程,應用服務仍可對外提供服務。
??Kubelet進程在啟動時會通過API Server注冊自身的節點信息,并定時的向API Server匯報狀態信息,API Server在接受到這些信息后,將這些信息更新到etcd中。Etcd中存儲的節點信息包括:節點的健康狀態、節點資源、節點名稱、節點地址信息、操作系統版本、docker版本、kubelet版本等。而節點的健康狀態有三種:就緒(True)、未就緒(False)、未知(Unknown)。
接下來小編通過圖來介紹Node Controller的核心工作流程: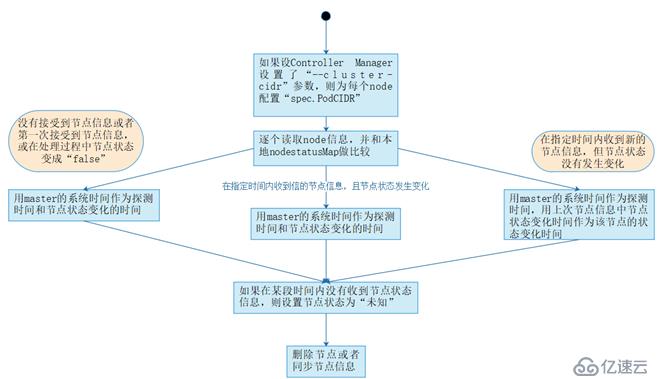
具體步驟
?- 如果controller manager在啟動時設置了--cluster-cidr,那么為每一個沒有設置spec.PodCIDR的節點生成一個CIDR地址,并用該地址設置節點的spec.PodCIDR屬性。
?- 逐個讀取節點信息,此時node controller中有一個nodestatusMap,里面存儲了信息,與新發送過來的節點信息做比較,并更新nodestatusMap中的節點信息。Kubelet發送過來的節點信息,有三種情況:未發送、發送但節點信息未變化、發送并且節點信息變化。此時node controller根據發送的節點信息,更新nodestatusMap,如果判斷出在某段時間內沒有接受到某個節點的信息,則設置節點狀態為“未知”。
?- 最后,將未就緒狀態的節點加入到待刪除隊列中,待刪除后,通過API Server將etcd中該節點的信息刪除。如果節點為就緒狀態,那么就向etcd中同步該節點信息。
??Kubernetes提供了資源配額管理(resourceQuota controller)這里高級功能,資源配置管理確保了指定的資源對象在任何時候都不會超量占用系統物理資源,避免了由于某些業務進程的設計或者實現的缺陷導致整個系統運行紊亂設置意外宕機,對整個集群的穩定性有著至關重要的作用。
目前kubernetes支持如下三個層次的資源配額管理:
? - 容器級別:對CPU 和 memory的限制
? - Pod級別:可以對一個pod內所有容器的可用資源進行限制
? - Namespace級別:為namespace(多租戶)級別的資源限制,其中限制的資源包括:
? ? ? △ Pod數量
? ? ? △ RC數量
? ? ? △ Service數量
? ? ? △ ResourceQuota數量
? ? ? △ Secret數量
? ? ? △ 可持有的PV數量
? ? Kubernetes的配額管理是通過admission control(準入控制)來控制的。admission control當前提供了兩種方式的配額約束,分別是limitRanger和resourceQuota。其中limitRanger作用于pod和容器上。ResourceQuota作用于namespace上,用于限定一個namespace里的各類資源的使用總額。
Kubernetes的配額管理是通過admission control(準入控制)來控制的。admission control當前提供了兩種方式的配額約束,分別是limitRanger和resourceQuota。其中limitRanger作用于pod和容器上。ResourceQuota作用于namespace上,用于限定一個namespace里的各類資源的使用總額。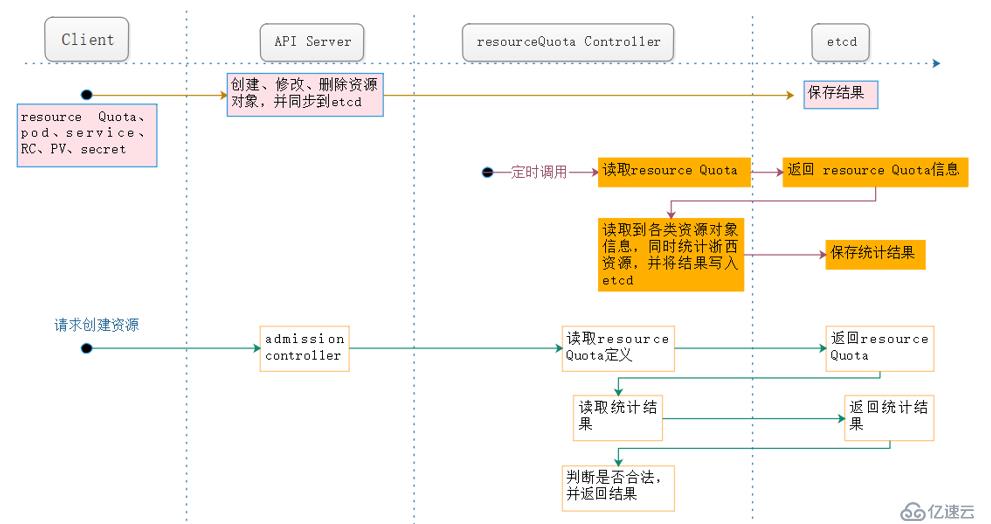
從上圖中,我們可以看出,大概有三條路線,resourceQuota controller在這三條路線中都起著重要的作用:
? ? 用戶通過API Server可以創建新的namespace并保存在etcd中,namespace controller定時通過API Server讀取這些namespace信息。如果namespace被API標記為優雅刪除(通過設置刪除周期),則將該namespace的狀態設置為“terminating”并保存到etcd中。同時namespace controller刪除該namespace下的serviceAccount,RC,pod,secret,PV,listRange,resourceQuota和event等資源對象。
? ? 當namespace的狀態為“terminating”后,由admission controller的namespaceLifecycle插件來阻止為該namespace創建新的資源。同時在namespace controller刪除完該namespace中的所有資源對象后,namespace controller對該namespace 執行finalize操作,刪除namespace的spec.finallizers域中的信息。
? ?當然這里有一種特殊情況,當個namespace controller發現namespace設置了刪除周期,并且該namespace 的spec.finalizers域值為空,那么namespace controller將通過API Server刪除該namespace 的資源。
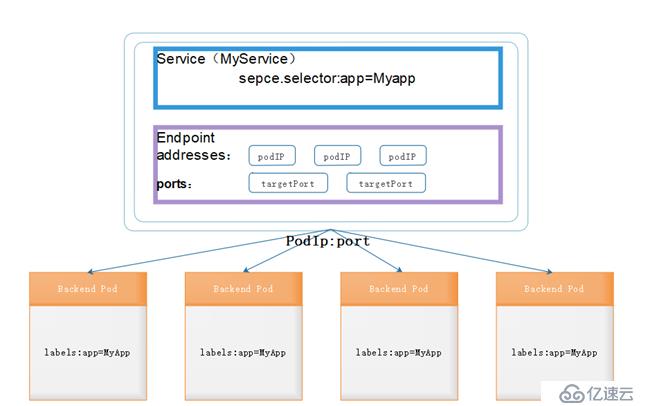
? ?上圖所示了service和endpoint與pod的關系,endpoints表示一個service對應的所有的pod副本的訪問地址,而endpoints controller就是負責生成和維護所有endpoints對象的控制器。
? ?它負責監聽service和對應的pod副本的變化,如果檢測到service被刪除,則刪除和該service同名的endpoints對象。如果檢測到新的service被創建或者修改,則根據該service的信息獲取到相關的pod列表,然后創建或者更新service對應的endpoints對象。如果檢測到pod的事件,則更新它對應service的endpoints對象(增加或者刪除或者修改對應的endpoint條目)。
? ?kubernetes scheduler 在整個系統中承擔了“承上啟下”的作用,“承上”是指它負責接收controller manager創建的新的pod,為其安排一個落腳的“家”,“啟下”是指安置工作完成以后,目標node上的kubelet服務進程接管后繼工作,負責pod生命周期中的“下半生”。
我們都知道將service和pod通過label關聯之后,我們訪問service的clusterIP對應的服務,就能通過kube-proxy將路由轉發到對應的后端的endpoint(pod IP +port)上,最終訪問到容器中的服務,實現了service的負載均衡功能。
? ?那么接下來說一說service controller的作用,它其實是屬于kubernetes與外部的云平臺之間的一個接口控制器。Service controller監聽service的變化,如果是一個loadBalancer類型的service,則service controller確保外部的云平臺上該service對應的loadbalance實例被相應的創建、刪除以及更新路由轉發表(根據endpoint的條目)。
? ?kubernetes scheduler 在整個系統中承擔了“承上啟下”的作用,“承上”是指它負責接收controller manager創建的新的pod,為其安排一個落腳的“家”,“啟下”是指安置工作完成以后,目標node上的kubelet服務進程接管后繼工作,負責pod生命周期中的“下半生”。
? ?具體的來說,kubernetes scheduler的作用就是將待調度的pod(新建的、補足副本而創建的)按照特定的調度算法和調度策略綁定到集群中某個合適的node上,并將綁定信息寫入到etcd中。整個調度過程分為三個對象,分別是:待調度的pod列表、可有的合適的node列表、調度算法和策略。一句話就是通過合適的調度算法和策略,將待調度的pod列表中的pod在合適的node上創建并啟動。
接下來小編通過一幅圖簡單介紹一下scheduler的工作流程: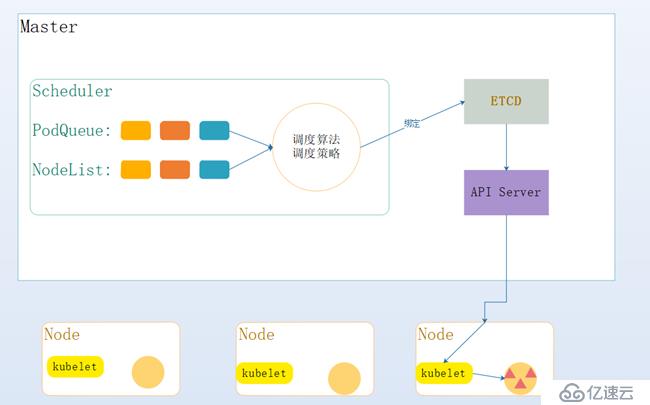
有圖可知:
? 遍歷所有目標node,篩選出符合要求的候選節點。為此,kubernetes內置了多種預選策略
? 確定優先節點,在第1步的基礎上,采用優選策略,計算出每一個節點候選的積分,積分最高者勝出
? 最后通過API Server將待調度的Pod,通知給最優node上的kubelet,將其創建并運行
? ?在scheduler中可用的預選算有很多:NoDiskconflict、PodFitsResources、PodSelectorMatches、PodFitsHost、CheckNodeLabelPresence、CheckServiceAffinity、PodFitsPorts等策略。其中的5個默認的預選策略:PodFitsPorts、PodFitsResources、NoDiskconflict、PodSelectorMatches、PodFitsHost每個節點只有通過這5個預選策略后,才能初步被選中,進入下一個流程。
下面小編介紹幾個常用的預選策略:
? ?判斷備選pod的gcePersistentDisk或者AWSElasticBlockStore和備選的節點中已存在的pod是否存在沖突具體檢測過程如下:
? ?? - 首先,讀取備選pod的所有的volume信息,對每一個volume執行一下步驟的沖突檢測
? ?? - 如果該volume是gcePersistentDisk,則將volume和備選節點上的所有pod的每個volume進行比較,如果發現相同的gcePersistentDisk,則返回false,表明磁盤沖突,檢測結束,反饋給調度器該備選節點不合適作為備選的pod,如果volume是AWSElasticBlockStore,則將volume和備選節點上的所有pod的每個volume進行比較,如果發現相同的AWSElasticBlockStore,則返回false,表明磁盤沖突,檢測結束,反饋給調度器該備選節點不合適作為備選的pod
? ?? - 最終,檢查備選pod的所有的volume均為發現沖突,則返回true,表明不存在磁盤沖突,反饋給調度器該備選節點合適備選pod
? ?判斷備選節點資源是否滿足備選pod的需求,檢測過程如下:
? ?? - 計算備選pod和節點中已存在的pod的所有容器的需求資源(CPU 和內存)的總和
? ?? - 獲得備選節點的狀態信息,其中包括節點的資源信息
? ?? - 如果備選pod和節點中已存在pod的所有容器的需求資源(CPU和內存)的總和超出了備選節點擁有的資源,則返回false,表明備選節點不適合備選pod,否則返回true,表明備選節點適合備選pod
? ?判斷備選節點是否包含備選pod的標簽選擇器指定的標簽:
? ?? - 如果pod沒有指定spec.nodeSelector標簽選擇器,則返回true
? ?? - 如果獲得備選節點的標簽信息,判斷節點是否包含備選pod的標簽選擇器所指的標簽,如果包含返回true,不包含返回false
??判斷備選pod的spec.nodeName域所指定的節點名稱和備選節點的名稱是否一致,如果一致返回true,否則返回false。
??判斷備選pod所用的端口列表匯中的端口是否在備選節點中被占用,如果被占用,則返回false,否則返回true。
??Scheduler中的優選策略有:leastRequestedPriority、CalculateNodeLabelPriority和BalancedResourceAllocation等。每個節點通過優先策略時都會算出一個得分,計算各項得分,最終選出得分值最大的節點作為優選結果。
小編接下來就給大家介紹一下一些常用的優選策略:
??該策略用于從備選節點列表中選出資源消耗最小的節點:
? ?? - 計算出所有備選節點上運行的pod和備選pod的CPU占用量
? ?? - 計算出所有備選節點上運行的pod和備選pod的memory占用量
? ?? - 根據特定的算法,計算每個節點的得分
? ?如果用戶在配置中指定了該策略,則scheduler會通過registerCustomPriorityFunction方法注冊該策略。該策略用于判斷策略列出的標簽在備選節點中存在時,是否選擇該備選節點。如果備選節點的標簽在優選策略的標簽列表中且優選策略的presence值為true,或者備選節點的標簽不在優選策略的標簽列表中且優選策略的presence值為false,則備選節點score=10,否則等于0。
? ?該優選策略用于從備選節點列表中選出各項資源使用率最均衡的節點:
? ?? - 計算出所有備選節點上運行的pod和備選pod的CPU占用量
? ?? - 計算出所有備選節點上運行的pod和備選pod的memory占用量
? ?? - 根據特定的算法,計算每個節點的得分
? ?在kubernetes集群中,每個node上都會啟動一個kubelet服務進程。該進程用于處理master節點下發到本節點的任務,管理Pod以及Pod中的容器。每個kubelet進程會在API Server上注冊節點信息,定期向master節點匯報節點資源的使用情況,并通過cAdvisor監控容器和節點的資源。
? ?節點通過設置kubelet的啟動參數“--register-node”來決定是否向API Server注冊自己。如果該參數為true,那么kubelet將試著通過API Server注冊自己。在自注冊時,kubelet啟動時還包括以下參數:
? ? -api-servers:API Server的位置
? ? --kubeconfing:kubeconfig文件,用于訪問API Server的安全配置文件
? ? --cloud-provider:云服務商地址,僅用于共有云環境
? ?如果沒有選擇自注冊模式,用戶需要手動去配置node的資源信息,同時告知ndoe上的kubelet API Server的位置。Kubelet在啟動時通過API Server注冊節點信息,并定時向API Server發送節點新消息,API Server在接受到這些消息之后,將這些信息寫入etcd中。通過kubelet的啟動參數“--node-status-update-frequency”設置kubelet每個多長時間向API Server報告節點狀態,默認為10s。
? ? kubelet通過以下幾種方式獲取自身node上所要運行的pod清單:
? ?? 文件:kubelet啟動參數“--config”指定的配置文件目錄下的文件(默認為“/etc/Kubernetes/manifests”)通過--file-check-frequency設置檢查該文件的時間間隔,默認為20s
? ?? HTTP端點:通過“--manifest-url”參數設置。通過“--http-check-frequency”設置檢查該HTTP端點數據的時間間隔,默認為20s。
? ?? API Server:kubelet通過API server監聽etcd目錄,同步pod列表
注意:這里static pod,不是被API Server創建的,而是被kubelet創建,之前文章中提到了靜態的pod是在kubelet的配置文件中編寫,并且總在kubelet所在node上運行。
? ?Kubelet監聽etcd,所有針對pod的操作將會被kubelet監聽到。如果是新的綁定到本節點的pod,則按照pod清單的要求創建pod,如果是刪除pod,則kubelet通過docker client去刪除pod中的容器,并刪除該pod。
? ?具體的針對創建和修改pod任務,流程為:
? ?? - 為該pod創建一個目錄
? ?? - 從API Server讀取該pod清單
? ?? - 為該pod掛載外部volume
? ?? - 下載pod用到的secret
? ?? - 檢查已經運行在節點中的pod,如果該pod沒有容器或者Pause容器沒有啟動,則先停止pod里的所有容器的進程。如果pod中有需要刪除的容器,則刪除這些容器
? ?? - 檢查已經運行在節點中的pod,如果該pod沒有容器或者Pause容器沒有啟動,則先停止pod里的所有容器的進程。如果pod中有需要刪除的容器,則刪除這些容器
? ?? - 為pod中的每個容器做如下操作
? ?? ? ?△ 為容器計算一個hash值,然后用容器的名字去查詢docker容器的hash值。若查找到容器,且兩者得到hash不同,則停止docker中的容器的進程,并且停止與之關聯pause容器的進程;若兩個相同,則不做任何處理
? ?? ? ?△ 如果容器被停止了,且容器沒有指定restartPolicy(重啟策略),則不做任何處理
? ?? ? ?△調用docker client 下載容器鏡像,調用docker client 運行容器
? ?Pod通過兩類探針來檢查容器的健康狀態。一個是livenessProbe探針,用于判斷容器是否健康,告訴kubelet一個容器什么時候處于不健康狀態,如果livenessProbe探針探測到容器不健康,則kubelet將刪除該容器,并根據容器的重啟策略做相應的處理;如果一個容器不包含livenessProbe探針,那么kubelet認為livenessProbe探針的返回值永遠為“success”。另一個探針為ReadinessProbe,用于判斷容器是否啟動完成,且準備接受請求。如果ReadinessProbe探針檢測到失敗,則pod的狀態將被修改,endpoint controller將從service的endpoints中刪除包含該容器所在pod的IP地址的endpoint條目。
? ?Kubelet定期調用容器中的livenessProbe探針來診斷容器的健康狀態。livenessProbe包括以下三種實現方式:
? ? - Execaction:在容器內執行一個命令,如果該命令的退出狀態碼為0,表示容器健康
? ? - TCPSocketAction:通過容器的IP地址和端口執行一個TCP檢查,如果端口能被訪問,則表明該容器正常
? ? - TCPSocketAction:通過容器的IP地址和端口執行一個TCP檢查,如果端口能被訪問,則表明該容器正常
具體的配置小編之前的文章中有詳細說明:https://blog.51cto.com/14048416/2396640
? ? 介紹kube-proxy,不得不說service,這里小編先帶大家回顧一下service,由于pod每次創建時它的IP地址是不固定的,為了訪問方便以及負載均衡,這里引入了service的概念,service在創建后有一個clusterIP,這個IP是固定的,通過labelselector與后端的pod關聯,這樣我們如果想訪問后端的應用服務,只需要通過service的clusterIP,然后就會將請求轉發到后端的pod上,即使一個反向代理,又是一個負載均衡。
? ? 但是在很多情況下service只是一個概念,而真正將service的作用落實的這是背后的kube-proxy服務進程。那么接下來就具體的介紹kube-proxy。
? ? 在kubernetes集群中的每一個node上都有一個kube-proxy進程,這個進程可以看做service的透明代理兼負載均衡,其核心功能就是將到某個service的訪問請求轉發到后端的多個pod實例上。對每一個TCP類型的kubernetes service,kube-proxy都會在本地node上建立一個socketserver來負責接收請求,然后均勻發送到后端的某個pod的端口上,這個過程默認采用round robin負載均衡算法。另外,kubernetes也提供通過修改service的service.spec.sessionAffinity參數的值來實現會話保持特性的定向發送,如果設置的值為“clientIP”,那么則將來來自同一個clientIP的請求都轉發到同一個后端的pod上。
? ? 此外,service的clusterIP和nodePort等概念是kube-proxy服務通過Iptables的NAT轉換實現的,kube-proxy在運行過程中動態創建于service相關的Iptable規則,這些規則實現了clusterIP以及nodePort的請求流量重定向到kube-proxy進程上對應的服務的代理端口的功能。由于Iptable機制針對的是本地的kube-proxy端口,所有每一個node上都要運行kube-proxy組件,這樣一來,在kubernetes集群內部,我們可以在任意node上發起對service的訪問。由此看來,由于kube-proxy的作用,在service的調用過程中客戶端無序關心后端有幾個pod,中間過程的通信,負載均衡以及故障恢復都是透明。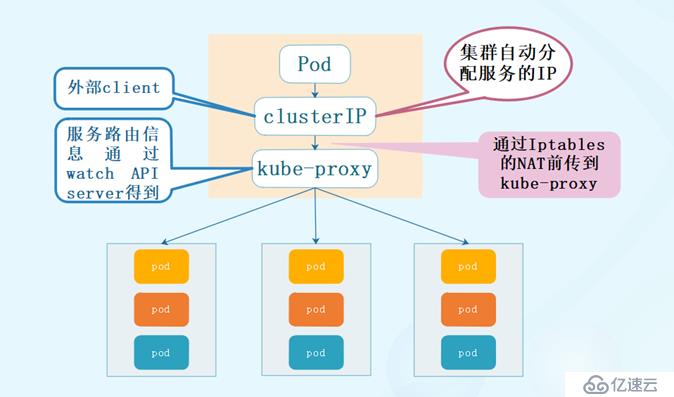
? ? 目前kube-proxy的負載均衡只支持round robin算法。round robin算法按照成員列表逐個選取成員,如果一輪循環結束,便從頭開始下一輪循環,如此循環往復。Kube-proxy的負載均衡器在round robin算法得到基礎上還支持session保持。如果service在定義中指定了session保持,則kube-proxy接受請求時會從本地內存中查找是否存在來自該請求IP的affinitystate對象,如果存在該對象,且session沒有超時,則kube-proxy將請求轉向該affinitystate所指向的后端的pod。如果本地存在沒有來自該請求IP的affinitystate對象,則按照round robin算法算法為該請求挑選一個endpoint,并創建一個affinitystate對象,記錄請求的IP和指向的endpoint。后面請求就會“黏連”到這個創建好的affinitystate對象上,這就實現了客戶端IP會話保持的功能。
? ?kube-proxy通過查詢和監聽API Server中service與endpoint的變換,為每一個service都建立一個“服務代理對象“,并自動同步。服務代理對相關是kube-proxy程序內部的一種數據結構,它包括一個用于監聽此務請求的socketServer, socketServer的端口是隨機指定的是本地一個空閑端口。此外,kube-proxy內部也創建了一個負載均衡器—loadBalancer, loadBalancer上保存了service到對應的后端endpoint列表的動態路由轉發表,而具體的路由選擇則取決于round robin算法和service的session會話保持。
? ?針對發生變化的service列表,kube-proxy會逐個處理,下面是具體的處理流程:
? ?- 如果service沒有設置集群IP,這不做任何處理,否則,獲取該service的所有端口定義列表
? ?- 逐個讀取服務端口定義列表中的端口信息,根據端口名稱、service名稱和namespace判斷本地是否已經存在對應的服務代理對象,如果不存在則創建,如果存在并且service端口被修改過,則先刪除Iptables中和該service端口相關的規則,關閉服務代理對象,然后走新建流程并為該service創建相關的Iptables規則
? ?- 更新負載均衡組件中對應service的轉發地址列表,對于新建的service,確定轉發時的會話保持策略
? ?- 對于已刪除的service則進行清理
接下來小編通過一個具體的案例,實際的給大家介紹一下kube-proxy的原理:
#首先創建一個service:
apiVersion: v1
kind: Service
metadata:
labels:
name: mysql
role: service
name: mysql-service
spec:
ports:
- port: 3306
targetPort: 3306
nodePort: 30964
type: NodePort
selector:
mysql-service: "true"? ?mysql-service對應的nodePort暴露出來的端口為30964,對應的cluster IP(10.254.162.44)的端口為3306,進一步對應于后端的pod的端口為3306。這里的暴露出來的30964也就是為mysql-service服務創建的代理對象在本地的端口,在ndoe上訪問該端口,則會將路由轉發到service上。
? ?mysql-service后端代理了兩個pod,ip分別是192.168.125.129和192.168.125.131。先來看一下iptables。
[root@localhost ~]# iptables -S -t nat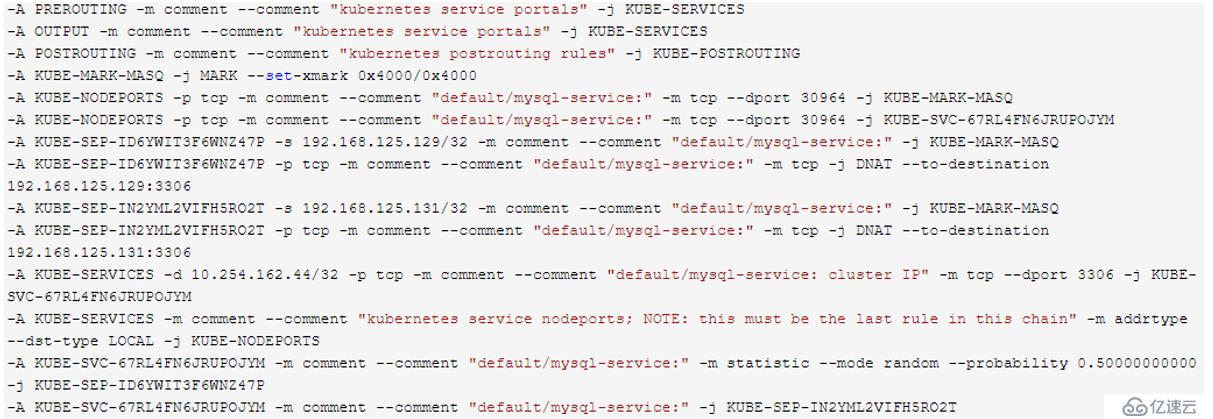
首先如果是通過node的30964端口訪問,則會進入到以下鏈:
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/mysql-service:" -m tcp --dport 30964 -j KUBE-MARK-MASQ
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/mysql-service:" -m tcp --dport 30964 -j KUBE-SVC-67RL4FN6JRUPOJYM然后進一步跳轉到KUBE-SVC-67RL4FN6JRUPOJYM的鏈
-A KUBE-SVC-67RL4FN6JRUPOJYM -m comment --comment "default/mysql-service:" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-ID6YWIT3F6WNZ47P
-A KUBE-SVC-67RL4FN6JRUPOJYM -m comment --comment "default/mysql-service:" -j KUBE-SEP-IN2YML2VIFH5RO2T這里利用了iptables的--probability的特性,使連接有50%的概率進入到KUBE-SEP-ID6YWIT3F6WNZ47P鏈,50%的概率進入到KUBE-SEP-IN2YML2VIFH5RO2T鏈。
KUBE-SEP-ID6YWIT3F6WNZ47P的鏈的具體作用就是將請求通過DNAT發送到192.168.125.129的3306端口。
-A KUBE-SEP-ID6YWIT3F6WNZ47P -s 192.168.125.129/32 -m comment --comment "default/mysql-service:" -j KUBE-MARK-MASQ
-A KUBE-SEP-ID6YWIT3F6WNZ47P -p tcp -m comment --comment "default/mysql-service:" -m tcp -j DNAT --to-destination 192.168.125.129:3306同理KUBE-SEP-IN2YML2VIFH5RO2T的作用是通過DNAT發送到192.168.125.131的3306端口。
-A KUBE-SEP-IN2YML2VIFH5RO2T -s 192.168.125.131/32 -m comment --comment "default/mysql-service:" -j KUBE-MARK-MASQ
-A KUBE-SEP-IN2YML2VIFH5RO2T -p tcp -m comment --comment "default/mysql-service:" -m tcp -j DNAT --to-destination 192.168.125.131:3306? ?總的來說就是:在創建service時,如果不指定nodePort則為其創建代理對象時代理對象再本地監聽一個隨機的空閑端口,如果設置了nodePort則以nodePort為本地代理對象的端口。客戶端在訪問本地代理對象的端口后此時會根據iptables轉發規則,將請求轉發到service的clusterIP+port上,然后根據負載均衡策略指定的轉發規則,將請求再次轉發到后端的endpoint的target Port上,最終訪問到具體pod中容器的應用服務,然后將響應返回。
文章內容參考至《kubernetes權威指南》
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





