溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
據報告顯示到 2025 年,全球將產生 180ZB 的數據。這些海量的數據正是企業進行數字化轉型的核心生產因素,然而真正被有效存儲、使用和分析的數據不到百分之十。如何從 ZB 級的數據中尋找分析有價值的信息并回饋到業務發展才是關鍵。11 月 30 日 UCan 技術沙龍大數據專場(北京站)邀請了 5 位資深大數據技術專家分享他們對大數據的探索和應用實踐。
大數據業務常態化的處理手段與架構衍變
很多開發人員在解決實際的業務問題時,經常會面臨如何選擇大數據框架的困惑。比如有十億條數據需要進行聚合操作,是把數據放在 HBase+Phoenix 還是 Kudu+Impala 或是 Spark 上進行呢?到底哪種方案才能夠達到降低開發運營成本且性能足夠高的效果呢? UCloud 大數據工程師劉景澤分享了他的思考。
要想對數據進行分析決策,首先要有數據來源,其次要將采集到的數據進行存儲,然后把這些數據進行匯總、聚合、計算,最后反饋到數據應用層。目前市面上主流的大數據框架有幾百種,總結下來主要分為數據采集層、數據存儲層、數據計算層和數據應用層。除此之外,一套完整的大數據技術棧還包括了任務調度、集群監控、權限管理和元數據管理。

面對數量眾多、種類繁雜的技術棧,選擇的自由度很高,但前提是不能把強依賴的框架給拆分開。這里劉景澤給出了一個通用型架構如下圖所示:
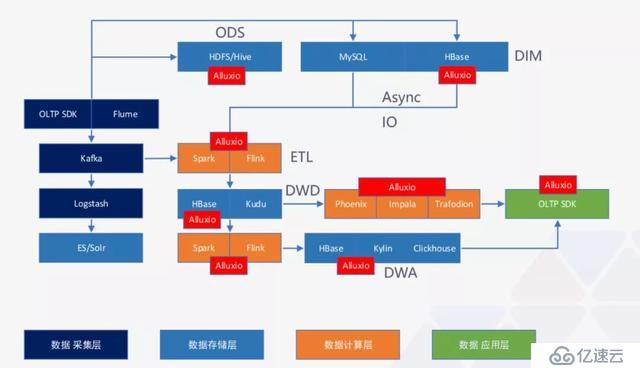
圖中左邊 OLTP SDK 指的是后臺接口,可以調用很多大數據的服務。從接口或者從 Flume 采集到的數據,直接送到 Kafka,然后送到 ES,再通過 ES 進行建模。整個過程相當于只使用了 ELK 這套系統,雖然很簡單,但這也是一個大數據框架。對于數據量比較大、業務范圍比較廣的公司,往往要求原始數據要做冷備留存,這時 HDFS 就可以作為一個數據冷備的集群,HDFS + Hive 作為冷備也是非常常見的方案。
當業務規模發展到足夠大的時候,需要進行一些聚合操作,如果從單獨的一個框架拉出來的數據是不完整的,可能需要多個框架同時操作然后進行 join,這樣操作的效率非常低。要解決這個問題,可以用大寬表的思路:第一步先把業務數據存放在 MySQL 或者 HBase 里面。然后通過 Spark 或 Flink,從 MySQL 或 HBase 里面通過異步 IO 的方式把所需要的維度數據拿出來進行 join,join 好的數據可以存在 HBase 中。到這一層的時候,所有的數據維度已經非常完整了。當進行一個重要指標分析的時候,我們只需要從 HBase 里面拿數據就可以了。對于業務不是非常重的指標可以直接通過 Phoenix 或者 HBase、Impala 和 Trafodion 對接業務需求,把想要的結果輸出。
再往后發展,如果業務還是異常繁重,數據處理不過來,我們就可以把明細數據層 HBase 里面的數據拿出來,放到 Spark 和 Flink 這兩個流計算框架中進行預聚合,然后對接到 OLTP 系統,提供后臺服務。
可見,大數據技術棧的選擇并沒有統一的標準,不同業務場景需要不同的處理方式。正如劉景澤所說:“在很多場景里面,我們面對框架的時候要一以貫之,發現它真正的自由度在哪里?而不要被它們所局限了。”
存儲計算分離與數據抽象實踐
大數據誕生的初期,很多公司的大數據集群是由一個龐大的 Cluster 陣列組成,里面包括很多臺服務器,也就是集群的計算能力和存儲能力分布在一個數據中心。這是由于當時的網絡條件較差,導致任務處理中的數據傳輸開銷非常大,而本地磁盤比網絡傳輸更快,因此當時的主要理念就是要以數據為中心做計算,為的是減少數據的遷移,提高計算效率,這里最典型的代表就是 MapReduce。
實際上,這種” 資源池” 方案不能同時充分利用存儲和計算資源,造成了大量浪費,還面臨著各種組件升級困難、無法區別對待不同數據、定位問題困難、臨時調配資源困難等一系列問題。隨著網絡速度的大幅提升、內存和磁盤的大規模擴容、大數據軟件的迭代更新,之前的存儲 + 計算集群的方案該如何改進呢?BLUECITY 大數據總監劉寶亮提出了存儲計算分離架構,如下圖所示:
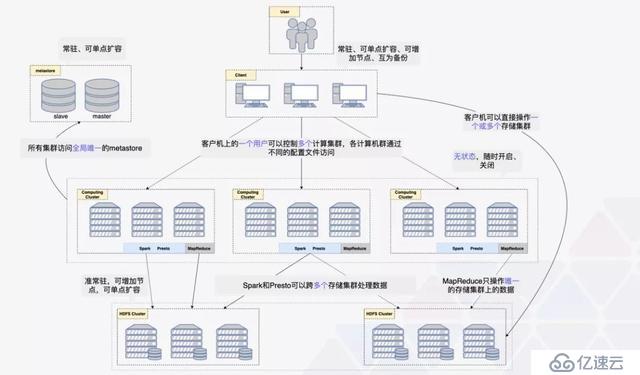
要實現存儲計算分離,首先存儲計算要分開,同時存儲內部要分離,計算內部也要分離。存儲集群是該架構的核心,因為大數據最重要的就是數據;計算集群是這個架構的靈魂,因為一切的靈活性都是由計算集群帶來的。此外,無阻塞網絡是此架構最重要的依賴,因為一旦出現網絡問題,存儲集群的讀取和寫入操作就不能持平。
說到存儲計算分離的優點,劉寶亮特別強調了 “彈性”,這是由于多集群的軟硬件升級更容易、數據可分級對待、可臨時創建新集群應對緊急問題等等都更加靈活,從而進一步提升了計算速度。
數據驅動 —— 從方法到實踐
所謂數據驅動,就是通過各種技術手段采集海量數據,并進行匯總形成信息,之后對相關的信息進行整合分析并形成決策指導。在這里神策聯合創始人 & 首席架構師付力力將整個數據驅動的環節總結為四步,分別是數據采集、數據建模、數據分析、數據反饋,并且這四個環節要形成閉環,也就是數據反饋最終要回歸到數據采集。
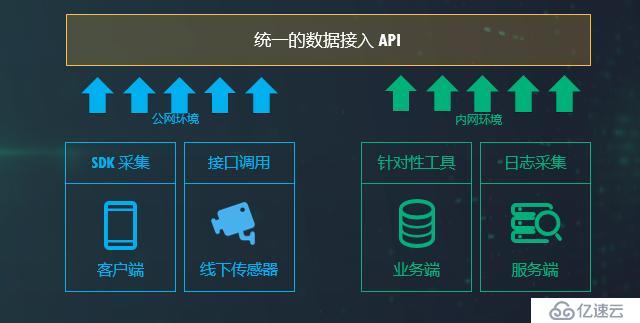
數據采集是一切數據應用的根基,可以通過客戶端、業務端、第三方數據、線下數據四個方面進行采集,無論以何種方式進行,建議在內部做技術架構設計的時候,要設定統一的數據接入 API,通過 SDK 或服務端的數據采集工具將數據做統一處理接收,方便后續的數據建模。
第二步是數據建模,一個基礎的數據模型分為三部分:事件、用戶、實體,在此之上,還可以做用戶分群,例如根據用戶的年齡、性別、省份、手機設備等屬性進行劃分。數據建模的過程中有一個難點就是 ETL,在多數據源采集的情況下,很難找到直接可用的 ETL 產品,因此我們可以搭建好調度、計算框架、質量管理和元數據管理等通用工作,盡量把數據的源頭建設好,從而降低運營成本。
第三步數據分析,這里有兩種非常典型的思路:一種是通過例行的報表滿足基本的指標獲取需求,如果是臨時性的需求就要通過新的開發解決;另一種是使用抽象的模型覆蓋指標體系以及大部分分析需求,通過友好的交互讓需要數據的人自主獲取數據。后者的靈活性遠遠大于前者,而數據分析對靈活性的要求會遠大于對響應時間的要求。除此之外,數據的可解釋性以及整體架構的簡潔性也是非常重要的考量因素。
數字時代業務風控的挑戰與機遇
企業的業務、營銷、生態、數據等正面臨日益嚴重的黑產威脅,面對黑產鏈條完備、分工明確的形勢,現有的風控方案面臨著哪些挑戰?
數美科技 CTO 梁堃歸納了三點:第一,防御能力單薄,依賴黑名單、依賴簡單人工規則、單點防御(SDK、驗證碼);第二,防御時效性差,依賴 T+1 離線挖掘、策略生效周期長;第三,防御進化慢,缺乏策略迭代閉環、無自學習機制。那么如何改善以上這些問題并建立完整的風控體系呢?
梁堃認為一個全棧式風控體系應該包括布控體系、策略體系、畫像體系和運營體系。在布控體系上,我們可以增加設備風險 SDK、增加登錄注冊保護、 提供業務行為保護。在策略體系上,可以對虛擬機設備農場等風險設備、對機器注冊撞庫***等風險操作、對欺詐團伙高危群體進行識別檢測等。畫像體系可以在多個場景進行數據打通,多行業聯防聯控,共同對抗黑產。運營體系可通過案例分析、***研究、策略的設計、研發、驗證、上線、運營等環節形成完整的閉環進行運轉,這樣才能保證風控一直有效。
這些體系跑在什么樣的架構上呢?首先風控系統要跟業務系統解耦,這樣業務規則隨時升級變化不會影響風控,風控規則的變化不會影響業務。另外一個風控平臺結構需要包括多場景策略體系、實時風控平臺和風險畫像網絡,如下圖所示:
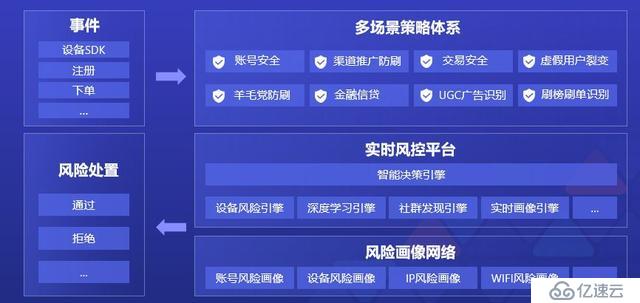
最后,這整個風控平臺的架構是運行在云服務基礎設施上的 7 個全球服務集群,每日請求量達 30 億,峰值 QPS 高達 10 萬 +。該架構可分為接入層、策略引擎層、模型引擎層和存儲層,通過負載均衡管理每一層的節點,實現動態的橫向擴展。
Spark 在 MobTech 應用實操分享
MobTech 作為全球領先的數據智能科技平臺,目前累計覆蓋設備量有 120 億,服務開發者 32 萬,累計接入 APP 數量達 50 萬,龐大的數據量也給 MobTech 帶來了諸多挑戰,例如運行的 Yarn/Spark 任務多、數據體量大、資源開銷大、運算時間較長等。
在 Mob 有大量復雜的任務,業務需求促使其將部分慢任務、Hive 任務遷移到 Spark 上面,取得性能的提升,同時還對一些 Spark 任務進行優化。MobTech 大數據技術架構師張峻滔圍繞復雜的 Spark 使用分享了兩個案例:第一個是 Spark 動態裁減在 MobTech 的應用。
所謂動態分區裁剪,就是基于運行時(run time)推斷出來的信息來進一步進行分區裁剪。假設 A 表有 20 億數據,B 表有 1000 萬數據,然后把 A 表和 B 表 join 起來,怎么才能過濾掉 A 表中無用的數據,這里我們引入了 bloomfilter。它的主要特性就是節省空間,如果 bloomfilter 判斷 key 不存在,那么就一定不存在;如果 bloomfilter 判斷 key 存在,那么可能存在,也可能不存在。簡而言之,這是一種犧牲精度來換取空間的數據結構。Bloomfilter 在 MobTech 具體應用實現如下圖所示:
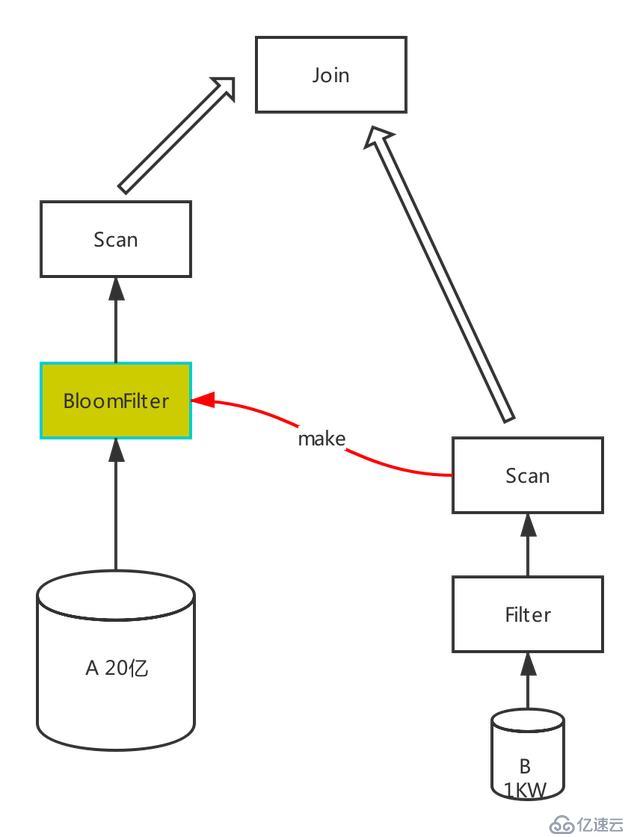
其邏輯 SQL 如下:
SELECT /+ bloomfilter(b.id) / a.,b.FROM a join b on a.id = b.id
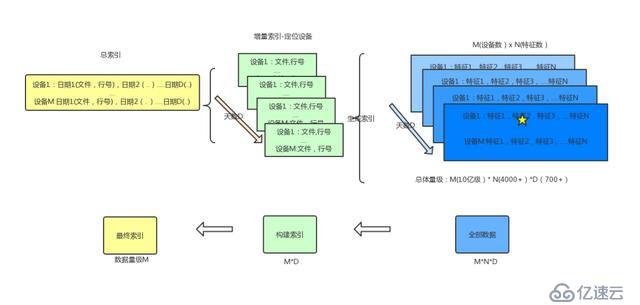
第二個案例是 Spark 在千億級別數據上的檢索與計算。MobTech 有 4000 多個標簽需要歷史回溯,且回溯時間周期長達 2 年,回溯頻次很低,面對這樣的冷數據,如何在資源開銷比較小的情況下完成業務檢索要求?由于數據分布太散,4000 多標簽分布在各個不同的表里面 (橫向), 歷史數據又分布在日表里面 (縱向), 間接造成搜索要在千億的數據中進行查找。這里,建立索引的思路有兩個:
橫向數據整合:將 4000 多個標簽的日數據索引整合到一個表里面;
縱向數據整合:將日數據進行周級別 / 月級別整合。
橫向整合的日表數據還是太大,于是決定將日期和數據 ID 整合做出一個索引表,來加快日表的查詢,確保能直接通過 ID 定位到具體在事實表中的哪個文件,哪一行有該 ID 的信息。日表的數據通過 Spark RDD 的 API 獲取 ID,ORC 文件名,行號的信息,生成增量索引;增量索引通過 UDAF 合并入全量索引。具體方案如下:
由于篇幅有限,更多精彩技術內容敬請關注 “UCloud 技術” 并回復 “大數據” 即可獲取講師 PPT~

免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





