溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關Python3代理池的維護方法的內容。小編覺得挺實用的,因此分享給大家做個參考。一起跟隨小編過來看看吧。
利用代理我們可以解決目標網站封 IP 的問題,而在網上又有大量公開的免費代理,其中有一部分可以拿來使用,或者我們也可以購買付費的代理 IP,價格也不貴。但是不論是免費的還是付費的,都不能保證它們每一個都是可用的,畢竟可能其他人也可能在用此 IP 爬取同樣的目標站點而被封禁,或者代理服務器突然出故障或網絡繁忙。一旦我們選用了一個不可用的代理,勢必會影響我們爬蟲的工作效率。
所以說,在用代理時,我們需要提前做一下篩選,將不可用的代理剔除掉,保留下可用代理,接下來在獲取代理時從可用代理里面取出直接使用就好了。
所以本節我們來搭建一個高效易用的代理池。
1. 準備工作
要實現代理池我們首先需要成功安裝好了 Redis 數據庫并啟動服務,另外還需要安裝 Aiohttp、Requests、RedisPy、PyQuery、Flask 庫,如果沒有安裝可以參考第一章的安裝說明。
2. 代理池的目標
代理池要做到易用、高效,我們一般需要做到下面的幾個目標:
基本模塊分為四塊,獲取模塊、存儲模塊、檢查模塊、接口模塊。
獲取模塊需要定時去各大代理網站抓取代理,代理可以是免費公開代理也可以是付費代理,代理的形式都是 IP 加端口,盡量從不同來源獲取,盡量抓取高匿代理,抓取完之后將可用代理保存到數據庫中。
存儲模塊負責存儲抓取下來的代理。首先我們需要保證代理不重復,另外我們還需要標識代理的可用情況,而且需要動態實時處理每個代理,所以說,一種比較高效和方便的存儲方式就是使用 Redis 的 Sorted Set,也就是有序集合。
檢測模塊需要定時將數據庫中的代理進行檢測,在這里我們需要設置一個檢測鏈接,最好是爬取哪個網站就檢測哪個網站,這樣更加有針對性,如果要做一個通用型的代理,那可以設置百度等鏈接來檢測。另外我們需要標識每一個代理的狀態,如設置分數標識,100 分代表可用,分數越少代表越不可用,檢測一次如果可用,我們可以將其立即設置為100 滿分,也可以在原基礎上加 1 分,當不可用,可以將其減 1 分,當減到一定閾值后就直接從數據庫移除。通過這樣的標識分數,我們就可以區分出代理的可用情況,選用的時候會更有針對性。
接口模塊需要用 API 來提供對外服務的接口,其實我們可以直接連數據庫來取,但是這樣就需要知道數據庫的連接信息,不太安全,而且需要配置連接,所以一個比較安全和方便的方式就是提供一個 Web API 接口,通過訪問接口即可拿到可用代理。另外由于可用代理可能有多個,我們可以提供隨機返回一個可用代理的接口,這樣保證每個可用代理都可以取到,實現負載均衡。
以上便是設計代理的一些基本思路,那么接下來我們就設計一下整體的架構,然后用代碼該實現代理池。
3. 代理池的架構
根據上文的描述,代理池的架構可以是這樣的,如圖 9-1 所示:
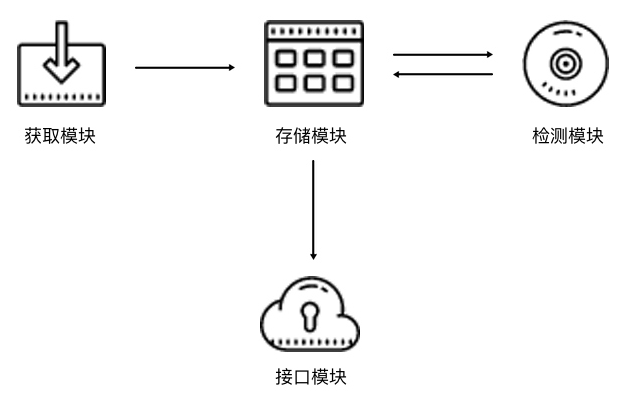
圖 9-1 代理池架構
代理池分為四個部分,獲取模塊、存儲模塊、檢測模塊、接口模塊。
存儲模塊使用Redis的有序集合,用以代理的去重和狀態標識,同時它也是中心模塊和基礎模塊,將其他模塊串聯起來。
獲取模塊定時從代理網站獲取代理,將獲取的代理傳遞給存儲模塊,保存到數據庫。
檢測模塊定時通過存儲模塊獲取所有代理,并對其進行檢測,根據不同的檢測結果對代理設置不同的標識。
接口模塊通過 Web API 提供服務接口,其內部還是連接存儲模塊,獲取可用的代理。
4. 代理池的實現
接下來我們分別用代碼來實現一下這四個模塊。
存儲模塊
存儲在這里我們使用 Redis 的有序集合,集合的每一個元素都是不重復的,對于代理代理池來說,集合的元素就變成了一個個代理,也就是 IP 加端口的形式,如 60.207.237.111:8888,這樣的一個代理就是集合的一個元素。另外有序集合的每一個元素還都有一個分數字段,分數是可以重復的,是一個浮點數類型,也可以是整數類型。該集合會根據每一個元素的分數對集合進行排序,數值小的排在前面,數值大的排在后面,這樣就可以實現集合元素的排序了。
對于代理池來說,這個分數可以作為我們判斷一個代理可用不可用的標志,我們將 100 設為最高分,代表可用,0 設為最低分,代表不可用。從代理池中獲取代理的時候會隨機獲取分數最高的代理,注意這里是隨機,這樣可以保證每個可用代理都會被調用到。
分數是我們判斷代理穩定性的重要標準,在這里我們設置分數規則如下:
分數 100 為可用,檢測器會定時循環檢測每個代理可用情況,一旦檢測到有可用的代理就立即置為 100,檢測到不可用就將分數減 1,減至 0 后移除。
新獲取的代理添加時將分數置為 10,當測試可行立即置 100,不可行分數減 1,減至 0 后移除。
這是一種解決方案,當然可能還有更合理的方案。此方案的設置有一定的原因,在此總結如下:
當檢測到代理可用時立即置為 100,這樣可以保證所有可用代理有更大的機會被獲取到。你可能會說為什么不直接將分數加 1 而是直接設為最高 100 呢?設想一下,我們有的代理是從各大免費公開代理網站獲取的,如果一個代理并沒有那么穩定,平均五次請求有兩次成功,三次失敗,如果按照這種方式來設置分數,那么這個代理幾乎不可能達到一個高的分數,也就是說它有時是可用的,但是我們篩選是篩選的分數最高的,所以這樣的代理就幾乎不可能被取到,當然如果想追求代理穩定性的化可以用這種方法,這樣可確保分數最高的一定是最穩定可用的。但是在這里我們采取可用即設置 100 的方法,確保只要可用的代理都可以被使用到。
當檢測到代理不可用時,將分數減 1,減至 0 后移除,一共 100 次機會,也就是說當一個可用代理接下來如果嘗試了 100 次都失敗了,就一直減分直到移除,一旦成功就重新置回 100,嘗試機會越多代表將這個代理拯救回來的機會越多,這樣不容易將曾經的一個可用代理丟棄,因為代理不可用的原因可能是網絡繁忙或者其他人用此代理請求太過頻繁,所以在這里設置為 100 級。
新獲取的代理分數設置為 10,檢測如果不可用就減 1,減到 0 就移除,如果可用就置 100。由于我們很多代理是從免費網站獲取的,所以新獲取的代理無效的可能性是非常高的,可能不足 10%,所以在這里我們將其設置為 10,檢測的機會沒有可用代理 100 次那么多,這也可以適當減少開銷。
以上便是代理分數的一個設置思路,不一定是最優思路,但個人實測實用性還是比較強的。
所以我們就需要定義一個類來操作數據庫的有序集合,定義一些方法來實現分數的設置,代理的獲取等等。
實現如下:
MAX_SCORE = 100
MIN_SCORE = 0
INITIAL_SCORE = 10
REDIS_HOST = 'localhost'
REDIS_PORT = 6379
REDIS_PASSWORD = None
REDIS_KEY = 'proxies'
import redis
from random import choice
class RedisClient(object):
def __init__(self, host=REDIS_HOST, port=REDIS_PORT, password=REDIS_PASSWORD):
"""
初始化
:param host: Redis 地址
:param port: Redis 端口
:param password: Redis密碼
"""
self.db = redis.StrictRedis(host=host, port=port, password=password, decode_responses=True)
def add(self, proxy, score=INITIAL_SCORE):
"""
添加代理,設置分數為最高
:param proxy: 代理
:param score: 分數
:return: 添加結果
"""
if not self.db.zscore(REDIS_KEY, proxy):
return self.db.zadd(REDIS_KEY, score, proxy)
def random(self):
"""
隨機獲取有效代理,首先嘗試獲取最高分數代理,如果不存在,按照排名獲取,否則異常
:return: 隨機代理
"""
result = self.db.zrangebyscore(REDIS_KEY, MAX_SCORE, MAX_SCORE)
if len(result):
return choice(result)
else:
result = self.db.zrevrange(REDIS_KEY, 0, 100)
if len(result):
return choice(result)
else:
raise PoolEmptyError
def decrease(self, proxy):
"""
代理值減一分,小于最小值則刪除
:param proxy: 代理
:return: 修改后的代理分數
"""
score = self.db.zscore(REDIS_KEY, proxy)
if score and score > MIN_SCORE:
print('代理', proxy, '當前分數', score, '減1')
return self.db.zincrby(REDIS_KEY, proxy, -1)
else:
print('代理', proxy, '當前分數', score, '移除')
return self.db.zrem(REDIS_KEY, proxy)
def exists(self, proxy):
"""
判斷是否存在
:param proxy: 代理
:return: 是否存在
"""
return not self.db.zscore(REDIS_KEY, proxy) == None
def max(self, proxy):
"""
將代理設置為MAX_SCORE
:param proxy: 代理
:return: 設置結果
"""
print('代理', proxy, '可用,設置為', MAX_SCORE)
return self.db.zadd(REDIS_KEY, MAX_SCORE, proxy)
def count(self):
"""
獲取數量
:return: 數量
"""
return self.db.zcard(REDIS_KEY)
def all(self):
"""
獲取全部代理
:return: 全部代理列表
"""
return self.db.zrangebyscore(REDIS_KEY, MIN_SCORE, MAX_SCORE)首先定義了一些常量,如 MAX_SCORE、MIN_SCORE、INITIAL_SCORE 分別代表最大分數、最小分數、初始分數。REDIS_HOST、REDIS_PORT、REDIS_PASSWORD 分別代表了 Redis 的連接信息,即地址、端口、密碼。REDIS_KEY 是有序集合的鍵名,可以通過它來獲取代理存儲所使用的有序集合。
接下來定義了一個 RedisClient 類,用以操作 Redis 的有序集合,其中定義了一些方法來對集合中的元素進行處理,主要功能如下:
init() 方法是初始化的方法,參數是Redis的連接信息,默認的連接信息已經定義為常量,在 init() 方法中初始化了一個 StrictRedis 的類,建立 Redis 連接。這樣當 RedisClient 類初始化的時候就建立了Redis的連接。
add() 方法向數據庫添加代理并設置分數,默認的分數是 INITIAL_SCORE 也就是 10,返回結果是添加的結果。
random() 方法是隨機獲取代理的方法,首先獲取 100 分的代理,然后隨機選擇一個返回,如果不存在 100 分的代理,則按照排名來獲取,選取前 100 名,然后隨機選擇一個返回,否則拋出異常。
decrease() 方法是在代理檢測無效的時候設置分數減 1 的方法,傳入代理,然后將此代理的分數減 1,如果達到最低值,那么就刪除。
exists() 方法判斷代理是否存在集合中
max() 方法是將代理的分數設置為 MAX_SCORE,即 100,也就是當代理有效時的設置。
count() 方法返回當前集合的元素個數。
all() 方法返回所有的代理列表,供檢測使用。
定義好了這些方法,我們可以在后續的模塊中調用此類來連接和操作數據庫,非常方便。如我們想要獲取隨機可用的代理,只需要調用 random() 方法即可,得到的就是隨機的可用代理。
獲取模塊
獲取模塊的邏輯相對簡單,首先需要定義一個 Crawler 來從各大網站抓取代理,示例如下:
import json
from .utils import get_page
from pyquery import PyQuery as pq
class ProxyMetaclass(type):
def __new__(cls, name, bases, attrs):
count = 0
attrs['__CrawlFunc__'] = []
for k, v in attrs.items():
if 'crawl_' in k:
attrs['__CrawlFunc__'].append(k)
count += 1
attrs['__CrawlFuncCount__'] = count
return type.__new__(cls, name, bases, attrs)
class Crawler(object, metaclass=ProxyMetaclass):
def get_proxies(self, callback):
proxies = []
for proxy in eval("self.{}()".format(callback)):
print('成功獲取到代理', proxy)
proxies.append(proxy)
return proxies
def crawl_daili66(self, page_count=4):
"""
獲取代理66
:param page_count: 頁碼
:return: 代理
"""
start_url = 'http://www.66ip.cn/{}.html'
urls = [start_url.format(page) for page in range(1, page_count + 1)]
for url in urls:
print('Crawling', url)
html = get_page(url)
if html:
doc = pq(html)
trs = doc('.containerbox table tr:gt(0)').items()
for tr in trs:
ip = tr.find('td:nth-child(1)').text()
port = tr.find('td:nth-child(2)').text()
yield ':'.join([ip, port])
def crawl_proxy360(self):
"""
獲取Proxy360
:return: 代理
"""
start_url = 'http://www.proxy#/Region/China'
print('Crawling', start_url)
html = get_page(start_url)
if html:
doc = pq(html)
lines = doc('div[name="list_proxy_ip"]').items()
for line in lines:
ip = line.find('.tbBottomLine:nth-child(1)').text()
port = line.find('.tbBottomLine:nth-child(2)').text()
yield ':'.join([ip, port])
def crawl_goubanjia(self):
"""
獲取Goubanjia
:return: 代理
"""
start_url = 'http://www.goubanjia.com/free/gngn/index.shtml'
html = get_page(start_url)
if html:
doc = pq(html)
tds = doc('td.ip').items()
for td in tds:
td.find('p').remove()
yield td.text().replace(' ', '')為了實現靈活,在這里我們將獲取代理的一個個方法統一定義一個規范,如統一定義以 crawl 開頭,這樣擴展的時候只需要添加 crawl 開頭的方法即可。
在這里實現了幾個示例,如抓取代理 66、Proxy360、Goubanjia 三個免費代理網站,這些方法都定義成了生成器,通過 yield 返回一個個代理。首先將網頁獲取,然后用PyQuery 解析,解析出IP加端口的形式的代理然后返回。
然后定義了一個 get_proxies() 方法,將所有以 crawl 開頭的方法調用一遍,獲取每個方法返回的代理并組合成列表形式返回。
你可能會想知道是怎樣獲取了所有以 crawl 開頭的方法名稱的。其實這里借助于元類來實現,定義了一個 ProxyMetaclass,Crawl 類將它設置為元類,元類中實現了 new() 方法,這個方法有固定的幾個參數,其中第四個參數 attrs 中包含了類的一些屬性,這其中就包含了類中方法的一些信息,我們可以遍歷 attrs 這個變量即可獲取類的所有方法信息。所以在這里我們在 new() 方法中遍歷了 attrs 的這個屬性,就像遍歷一個字典一樣,鍵名對應的就是方法的名稱,接下來判斷其開頭是否是 crawl,如果是,則將其加入到 CrawlFunc 屬性中,這樣我們就成功將所有以 crawl 開頭的方法定義成了一個屬性,就成功動態地獲取到所有以 crawl 開頭的方法列表了。
所以說,如果要做擴展的話,我們只需要添加一個以 crawl開頭的方法,例如抓取快代理,我們只需要在 Crawler 類中增加 crawl_kuaidaili() 方法,仿照其他的幾個方法將其定義成生成器,抓取其網站的代理,然后通過 yield 返回代理即可,所以這樣我們可以非常方便地擴展,而不用關心類其他部分的實現邏輯。
代理網站的添加非常靈活,不僅可以添加免費代理,也可以添加付費代理,一些付費代理的提取方式其實也類似,也是通過 Web 的形式獲取,然后進行解析,解析方式可能更加簡單,如解析純文本或 Json,解析之后以同樣的方式返回即可,在此不再添加,可以自行擴展。
既然定義了這個 Crawler 類,我們就要調用啊,所以在這里再定義一個 Getter 類,動態地調用所有以 crawl 開頭的方法,然后獲取抓取到的代理,將其加入到數據庫存儲起來。
from db import RedisClient
from crawler import Crawler
POOL_UPPER_THRESHOLD = 10000
class Getter():
def __init__(self):
self.redis = RedisClient()
self.crawler = Crawler()
def is_over_threshold(self):
"""
判斷是否達到了代理池限制
"""
if self.redis.count() >= POOL_UPPER_THRESHOLD:
return True
else:
return False
def run(self):
print('獲取器開始執行')
if not self.is_over_threshold():
for callback_label in range(self.crawler.__CrawlFuncCount__):
callback = self.crawler.__CrawlFunc__[callback_label]
proxies = self.crawler.get_proxies(callback)
for proxy in proxies:
self.redis.add(proxy)Getter 類就是獲取器類,這其中定義了一個變量 POOL_UPPER_THRESHOLD 表示代理池的最大數量,這個數量可以靈活配置,然后定義了 is_over_threshold() 方法判斷代理池是否已經達到了容量閾值,它就是調用了 RedisClient 的 count() 方法獲取代理的數量,然后加以判斷,如果數量達到閾值則返回 True,否則 False。如果不想加這個限制可以將此方法永久返回 True。
接下來定義了 run() 方法,首先判斷了代理池是否達到閾值,然后在這里就調用了 Crawler 類的 CrawlFunc 屬性,獲取到所有以 crawl 開頭的方法列表,依次通過 get_proxies() 方法調用,得到各個方法抓取到的代理,然后再利用 RedisClient 的 add() 方法加入數據庫,這樣獲取模塊的工作就完成了。
檢測模塊
在獲取模塊中,我們已經成功將各個網站的代理獲取下來了,然后就需要一個檢測模塊來對所有的代理進行一輪輪的檢測,檢測可用就設置為 100,不可用就分數減 1,這樣就可以實時改變每個代理的可用情況,在獲取有效代理的時候只需要獲取分數高的代理即可。
由于代理的數量非常多,為了提高代理的檢測效率,我們在這里使用異步請求庫 Aiohttp 來進行檢測。
Requests 作為一個同步請求庫,我們在發出一個請求之后需要等待網頁加載完成之后才能繼續執行程序。也就是這個過程會阻塞在等待響應這個過程,如果服務器響應非常慢,比如一個請求等待十幾秒,那么我們使用 Requests 完成一個請求就會需要十幾秒的時間,中間其實就是一個等待響應的過程,程序也不會繼續往下執行,而這十幾秒的時間其實完全可以去做其他的事情,比如調度其他的請求或者進行網頁解析等等。
異步請求庫就解決了這個問題,它類似 JavaScript 中的回調,意思是說在請求發出之后,程序可以繼續接下去執行去做其他的事情,當響應到達時,會通知程序再去處理這個響應,這樣程序就沒有被阻塞,充分把時間和資源利用起來,大大提高效率。
對于響應速度比較快的網站,可能 Requests 同步請求和 Aiohttp 異步請求的效果差距沒那么大,可對于檢測代理這種事情,一般是需要十多秒甚至幾十秒的時間,這時候使用 Aiohttp 異步請求庫的優勢就大大體現出來了,效率可能會提高幾十倍不止。
所以在這里我們的代理檢測使用異步請求庫 Aiohttp,實現示例如下:
VALID_STATUS_CODES = [200]
TEST_URL = 'http://www.baidu.com'
BATCH_TEST_SIZE = 100
class Tester(object):
def __init__(self):
self.redis = RedisClient()
async def test_single_proxy(self, proxy):
"""
測試單個代理
:param proxy: 單個代理
:return: None
"""
conn = aiohttp.TCPConnector(verify_ssl=False)
async with aiohttp.ClientSession(connector=conn) as session:
try:
if isinstance(proxy, bytes):
proxy = proxy.decode('utf-8')
real_proxy = 'http://' + proxy
print('正在測試', proxy)
async with session.get(TEST_URL, proxy=real_proxy, timeout=15) as response:
if response.status in VALID_STATUS_CODES:
self.redis.max(proxy)
print('代理可用', proxy)
else:
self.redis.decrease(proxy)
print('請求響應碼不合法', proxy)
except (ClientError, ClientConnectorError, TimeoutError, AttributeError):
self.redis.decrease(proxy)
print('代理請求失敗', proxy)
def run(self):
"""
測試主函數
:return: None
"""
print('測試器開始運行')
try:
proxies = self.redis.all()
loop = asyncio.get_event_loop()
# 批量測試
for i in range(0, len(proxies), BATCH_TEST_SIZE):
test_proxies = proxies[i:i + BATCH_TEST_SIZE]
tasks = [self.test_single_proxy(proxy) for proxy in test_proxies]
loop.run_until_complete(asyncio.wait(tasks))
time.sleep(5)
except Exception as e:
print('測試器發生錯誤', e.args)在這里定義了一個類 Tester,init() 方法中建立了一個 RedisClient 對象,供類中其他方法使用。接下來定義了一個 test_single_proxy() 方法,用來檢測單個代理的可用情況,其參數就是被檢測的代理,注意這個方法前面加了 async 關鍵詞,代表這個方法是異步的,方法內部首先創建了 Aiohttp 的 ClientSession 對象,此對象類似于 Requests 的 Session 對象,可以直接調用該對象的 get() 方法來訪問頁面,在這里代理的設置方式是通過 proxy 參數傳遞給 get() 方法,請求方法前面也需要加上 async 關鍵詞標明是異步請求,這也是 Aiohttp 使用時的常見寫法。
測試的鏈接在這里定義常量為 TEST_URL,如果針對某個網站有抓取需求,建議將 TEST_URL 設置為目標網站的地址,因為在抓取的過程中,可能代理本身是可用的,但是該代理的 IP 已經被目標網站封掉了。例如,如要抓取知乎,可能其中某些代理是可以正常使用,比如訪問百度等頁面是完全沒有問題的,但是可能對知乎來說可能就被封了,所以可以將 TEST_URL 設置為知乎的某個頁面的鏈接,當請求失敗時,當代理被封時,分數自然會減下來,就不會被取到了。
如果想做一個通用的代理池,則不需要專門設置 TEST_URL,可以設置為一個不會封 IP 的網站,也可以設置為百度這類響應穩定的網站。
另外我們還定義了 VALID_STATUS_CODES 變量,是一個列表形式,包含了正常的狀態碼,如可以定義成 [200],當然對于某些檢測目標網站可能會出現其他的狀態碼也是正常的,可以自行配置。
獲取 Response 后需要判斷響應的狀態,如果狀態碼在 VALID_STATUS_CODES 這個列表里,則代表代理可用,調用 RedisClient 的 max() 方法將代理分數設為 100,否則調用 decrease() 方法將代理分數減 1,如果出現異常也同樣將代理分數減 1。
另外在測試的時候設置了批量測試的最大值 BATCH_TEST_SIZE 為 100,也就是一批測試最多測試 100個,這可以避免當代理池過大時全部測試導致內存開銷過大的問題。
隨后在 run() 方法里面獲取了所有的代理列表,使用 Aiohttp 分配任務,啟動運行,這樣就可以進行異步檢測了,寫法可以參考 Aiohttp 的官方示例:http://aiohttp.readthedocs.io/。
這樣測試模塊的邏輯就完成了。
接口模塊
通過上述三個模塊我們已經可以做到代理的獲取、檢測和更新了,數據庫中就會以有序集合的形式存儲各個代理還有對應的分數,分數 100 代表可用,分數越小代表越不可用。
但是我們怎樣來方便地獲取可用代理呢?用 RedisClient 類來直接連接 Redis 然后調用 random() 方法獲取當然沒問題,這樣做效率很高,但是有這么幾個弊端:
需要知道 Redis 的用戶名和密碼,如果這個代理池是給其他人使用的就需要告訴他連接的用戶名和密碼信息,這樣是很不安全的。
代理池如果想持續運行需要部署在遠程服務器上運行,如果遠程服務器的 Redis 是只允許本地連接的,那么就沒有辦法遠程直連 Redis 獲取代理了。
如果爬蟲所在的主機沒有連接 Redis 的模塊,或者爬蟲不是由 Python 語言編寫的,那么就無法使用 RedisClient 來獲取代理了。
如果 RedisClient 類或者數據庫結構有更新,那么在爬蟲端還需要去同步這些更新。
綜上考慮,為了使得代理池可以作為一個獨立服務運行,我們最好增加一個接口模塊,以 Web API 的形式暴露可用代理。
這樣獲取代理只需要請求一下接口即可,以上的幾個缺點弊端可以解決。
我們在這里使用一個比較輕量級的庫 Flask 來實現這個接口模塊,實現示例如下:
from flask import Flask, g
from db import RedisClient
__all__ = ['app']
app = Flask(__name__)
def get_conn():
if not hasattr(g, 'redis'):
g.redis = RedisClient()
return g.redis
@app.route('/')
def index():
return '<h3>Welcome to Proxy Pool System</h3>'
@app.route('/random')
def get_proxy():
"""
獲取隨機可用代理
:return: 隨機代理
"""
conn = get_conn()
return conn.random()
@app.route('/count')
def get_counts():
"""
獲取代理池總量
:return: 代理池總量
"""
conn = get_conn()
return str(conn.count())
if __name__ == '__main__':
app.run()在這里我們聲明了一個 Flask 對象,定義了三個接口,分別是首頁、隨機代理頁、獲取數量頁。
運行之后 Flask 會啟動一個 Web 服務,我們只需要訪問對應的接口即可獲取到可用代理。
調度模塊
這個模塊其實就是調用以上所定義的三個模塊,將以上三個模塊通過多進程的形式運行起來,示例如下:
TESTER_CYCLE = 20
GETTER_CYCLE = 20
TESTER_ENABLED = True
GETTER_ENABLED = True
API_ENABLED = True
from multiprocessing import Process
from api import app
from getter import Getter
from tester import Tester
class Scheduler():
def schedule_tester(self, cycle=TESTER_CYCLE):
"""
定時測試代理
"""
tester = Tester()
while True:
print('測試器開始運行')
tester.run()
time.sleep(cycle)
def schedule_getter(self, cycle=GETTER_CYCLE):
"""
定時獲取代理
"""
getter = Getter()
while True:
print('開始抓取代理')
getter.run()
time.sleep(cycle)
def schedule_api(self):
"""
開啟API
"""
app.run(API_HOST, API_PORT)
def run(self):
print('代理池開始運行')
if TESTER_ENABLED:
tester_process = Process(target=self.schedule_tester)
tester_process.start()
if GETTER_ENABLED:
getter_process = Process(target=self.schedule_getter)
getter_process.start()
if API_ENABLED:
api_process = Process(target=self.schedule_api)
api_process.start()在這里還有三個常量,TESTER_ENABLED、GETTER_ENABLED、API_ENABLED 都是布爾類型,True 或者 False。標明了測試模塊、獲取模塊、接口模塊的開關,如果為 True,則代表模塊開啟。
啟動入口是 run() 方法,其分別判斷了三個模塊的開關,如果開啟的話,就新建一個 Process 進程,設置好啟動目標,然后調用 start() 方法運行,這樣三個進程就可以并行執行,互不干擾。
三個調度方法結構也非常清晰,比如 schedule_tester() 方法,這是用來調度測試模塊的方法,首先聲明一個 Tester 對象,然后進入死循環不斷循環調用其 run() 方法,執行完一輪之后就休眠一段時間,休眠結束之后重新再執行。在這里休眠時間也定義為一個常量,如 20 秒,這樣就會每隔 20 秒進行一次代理檢測。
最后整個代理池的運行只需要調用 Scheduler 的 run() 方法即可啟動。
以上便是整個代理池的架構和相應實現邏輯。
5. 運行
接下來我們將代碼整合一下,將代理運行起來,運行之后的輸出結果如圖 9-2 所示:
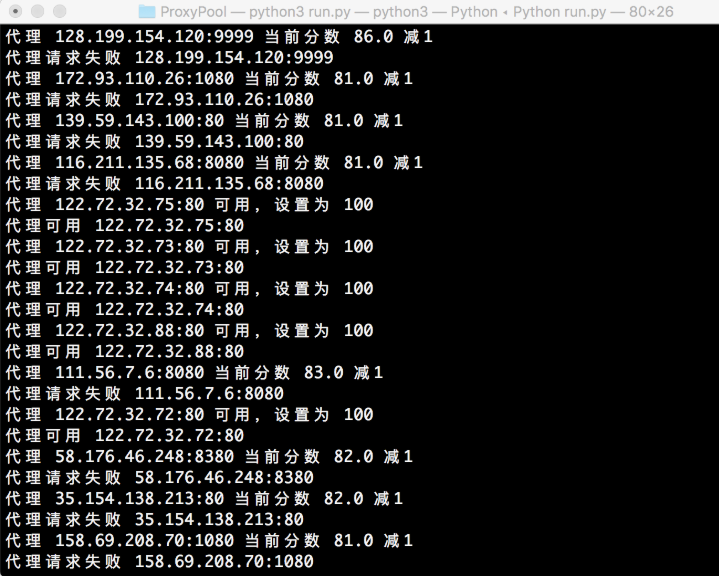
圖 9-2 運行結果
以上是代理池的控制臺輸出,可以看到可用代理設置為 100,不可用代理分數減 1。
接下來我們再打開瀏覽器,當前配置了運行在 5555 端口,所以打開:http://127.0.0.1:5555,即可看到其首頁,如圖 9-3 所示:
圖 9-3 首頁頁面
再訪問:http://127.0.0.1:5555/random,即可獲取隨機可用代理,如圖 9-4 所示:
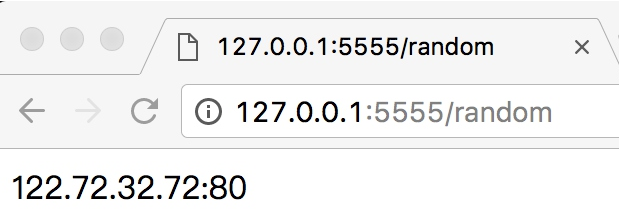
圖 9-4 獲取代理頁面
所以后面我們只需要訪問此接口即可獲取一個隨機可用代理,非常方便。
獲取代理的代碼如下:
import requests PROXY_POOL_URL = 'http://localhost:5555/random' def get_proxy(): try: response = requests.get(PROXY_POOL_URL) if response.status_code == 200: return response.text except ConnectionError: return None
獲取下來之后便是一個字符串類型的代理,可以按照上一節所示的方法設置代理,如 Requests 的使用方法如下:
import requests
proxy = get_proxy()
proxies = {
'http': 'http://' + proxy,
'https': 'https://' + proxy,
}
try:
response = requests.get('http://httpbin.org/get', proxies=proxies)
print(response.text)
except requests.exceptions.ConnectionError as e:
print('Error', e.args)有了代理池之后,我們再取出代理即可有效防止IP被封禁的情況。
感謝各位的閱讀!關于Python3代理池的維護方法就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





