溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下關于Python爬蟲的簡介,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
很多人都或多或少聽說過 Python 爬蟲,我也一直很感興趣,所以也花了一個下午入門了一下輕量級的爬蟲。為啥是輕量級的爬蟲呢,因為有的網頁是比較復雜的,比如需要驗證碼、登錄驗證或者需要證書才能訪問,我們了解爬蟲的概念和架構,只需要做一些簡單的爬取工作即可,比如爬取百度百科這種純信息展示的網頁,這些都是不需要登錄的靜態網頁。即便再復雜的爬蟲網頁和爬蟲框架,實際上都離不開這一套基本的爬蟲架構。
爬蟲簡介
爬蟲是一段自動抓取互聯網信息的程序。每個網頁都有一個URL,從一個網頁入口開始,通過各種URL的跳轉形成一個相互指向的關系,最終可以形成一種網狀結構,這就是互聯網。理論上來說,一個龐大的網頁項目,從入口開始,總能通過某種跳轉路徑到達項目系統中的任何一個網頁,當我們人工的從網頁上獲取信息的時候,只能跟著步驟,一步一步的點擊跳轉,最終獲取到我們希望得到的信息。
比如典型的,我昨天想領養一只貓咪,我先點開同城網站,然后找到寵物分類,再找到貓咪分類,再選擇一些條目,比如是領養而不是購買,年齡在半歲以下,貍花貓等等這些特性,最后點擊搜索,網頁給了我具體的條目列表,我通過人工的方式,獲取了我想要的信息。雖然定位精準,但不免很浪費人力時間。
而爬蟲就是一個這樣的自動程序,我們設定好我們需要的主題和目標,比如「貓咪」、「6個月」等標簽,爬蟲會從某個特定URL入手,自動的訪問它所關聯的URL,并且提取出我們需要的數據。可以說爬蟲就是自動訪問互聯網,并且提取價值數據的程序。
爬蟲的價值就在于此,可以獲取將互聯網上巨量的數據都為我所用,有了這些數據,我們就可以進行學習和分析,或者利用數據做出相關的產品。
爬取 GitHub 中一天瀏覽量和 star 提升數最高的項目,有了這個數據,就可以做出一個 GitHub 開源項目推薦的項目。
現在各大網站的歌曲都有版權保護,下載歌曲不太方便,可以通過歌曲名字,爬取網上所有免費下載鏈接,這樣就可以輕易做出一個歌曲搜索下載的聚類工具。
可以說,只要有數據,沒有做不到的,只有你想不到的,數據就在放在互聯網上,通過爬蟲我們可以讓數據發揮更大的作用和價值,在大數據時代,爬蟲毋庸置疑是一門一線技術。
爬蟲基本架構
我們先來看一下簡單的爬蟲架構圖
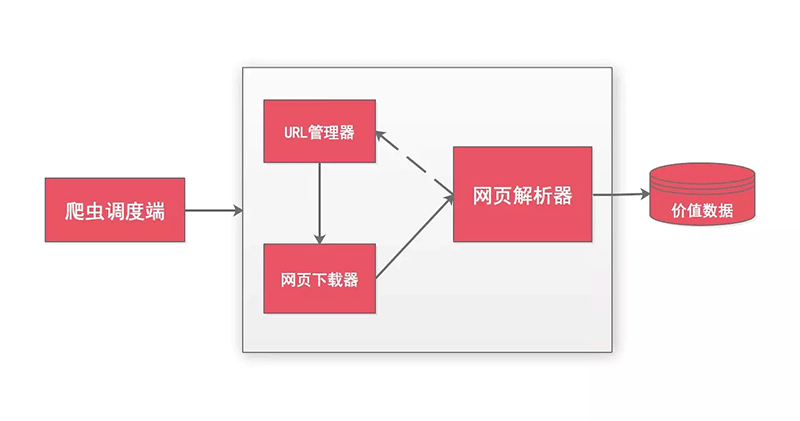
首先我們需要一個爬蟲調度端來啟動和停止爬蟲,同時也要通過它來監視爬蟲的狀態,并通過它提供接口來作具體的數據應用。這個部分不屬于爬蟲本身。
圖中陰影方框中的部分就是我們爬蟲程序。因為有的頁面的入口有很多,我們可以通過不同的URL調度路徑來訪問這個界面,那么作為一個智能的爬蟲軟件,當遇到我們已經爬取過的URL的時候,應該選擇過濾,而不是再次爬取。URL管理器就是用來存儲已經爬取URL和將要爬取URL的工具的。
從URL管理器中選擇一個待爬取的URL,將其傳送給網頁下載器,下載器會把網頁以字符串的形式下載下來,并把這個字符串交給網頁解析器去解析,網頁解析器一方面會把你需要獲取的價值信息提取出來歸還給調度器,另一方面,如果遇到該網頁有新的URL待爬取,就會把這個URL傳送給URL管理器。從此,這三個模塊進行循環,直到該網頁相關的所有URL都爬取完畢。
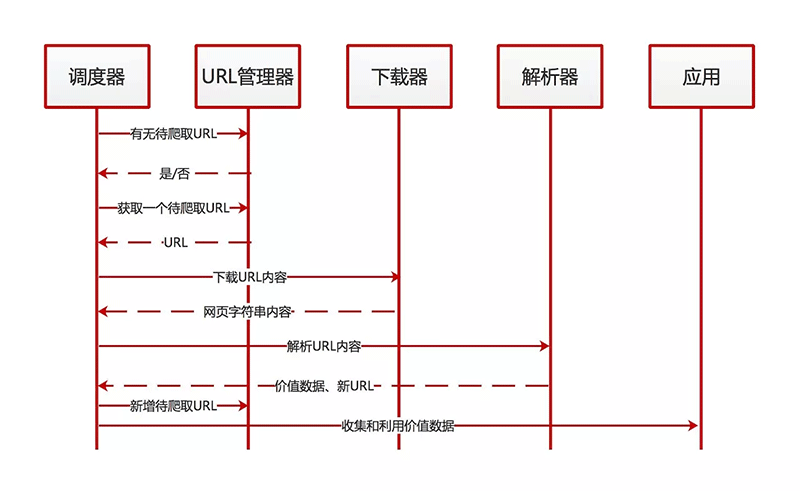
更加清晰的動態運行流程,可以用一個時序圖來表示。大家可以對照著上面的步驟理解下。
以上是關于Python爬蟲的簡介的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





