溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關查看Linux服務器性能的日常命令和工具有哪些,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
概述
通過使用以下命令和工具,可以在1分鐘內對系統資源使用情況有個大致的了解
uptime
dmesg | tail
vmstat 1
mpstat -P ALL 1
pidstat 1
iostat -xz 1
free -m
sar -n DEV 1
sar -n TCP,ETCP 1
top
lsof
tcpdump
netstat
htop
iotop
IPTraf
Psacct 或者 Acct
Monit
NetHogs
iftop
Monitorix
Arpwatch
Suricata
VnStat PHP
Nagios
Nmon
Collectl
其中一些命令需要安裝sysstat包,有一些由procps包提供。這些命令的輸出,有助于快速定位性能瓶頸,檢查出所有資源(CPU、內存、磁盤IO等)的利用率(utilization)、飽和度(saturation)和錯誤(error)度量,也就是所謂的USE方法
下面我們來逐一介紹下這些命令和工具,有關這些命令和工具更多的參數和說明,請參照手冊
1.uptime
$ uptime 23:51:26 up 21:31, 1 user, load average: 30.02, 26.43, 19.02
這個命令可以快速查看機器的負載情況。在Linux系統中,這些數據表示等待CPU資源的進程和阻塞在不可中斷IO進程(進程狀態為D)的數量。這些數據可以讓我們對系統資源使用有一個宏觀的了解。
命令的輸出分別表示1分鐘、5分鐘、15分鐘的平均負載情況。通過這三個數據,可以了解服務器負載是在趨于緊張還是區域緩解。如果1分鐘平均負載很高,而15分鐘平均負載很低,說明服務器正在命令高負載情況,需要進一步排查CPU資源都消耗在了哪里。反之,如果15分鐘平均負載很高,1分鐘平均負載較低,則有可能是CPU資源緊張時刻已經過去。
上面例子中的輸出,可以看見最近1分鐘的平均負載非常高,且遠高于最近15分鐘負載,因此我們需要繼續排查當前系統中有什么進程消耗了大量的資源。可以通過下文將會介紹的vmstat、mpstat等命令進一步排查。
2.dmesg | tail
$ dmesg | tail [1880957.563150] perl invoked oom-killer: gfp_mask=0x280da, order=0, oom_score_adj=0 [...] [1880957.563400] Out of memory: Kill process 18694 (perl) score 246 or sacrifice child [1880957.563408] Killed process 18694 (perl) total-vm:1972392kB, anon-rss:1953348kB, file-rss:0kB [2320864.954447] TCP: Possible SYN flooding on port 7001. Dropping request. Check SNMP counters.
該命令會輸出系統日志的最后10行。示例中的輸出,可以看見一次內核的oom kill和一次TCP丟包。這些日志可以幫助排查性能問題。千萬不要忘了這一步。
vmstat 命令是用于顯示虛擬內存、內核線程、磁盤、系統進程、I/O 模塊、中斷、CPU 活躍狀態等更多信息
在默認的情況下,Linux 系統是沒有 vmstat 這個命令的,如果你要使用它
必須安裝一個包名叫 sysstat 的程序包。命令格式常用用法如下:
$ vmstat 1 procs ---------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 34 0 0 200889792 73708 591828 0 0 0 5 6 10 96 1 3 0 0 32 0 0 200889920 73708 591860 0 0 0 592 13284 4282 98 1 1 0 0 32 0 0 200890112 73708 591860 0 0 0 0 9501 2154 99 1 0 0 0 32 0 0 200889568 73712 591856 0 0 0 48 11900 2459 99 0 0 0 0 32 0 0 200890208 73712 591860 0 0 0 0 15898 4840 98 1 1 0 0 ^C
vmstat(8) 命令,每行會輸出一些系統核心指標,這些指標可以讓我們更詳細的了解系統狀態。后面跟的參數1,表示每秒輸出一次統計信息,表頭提示了每一列的含義,這幾介紹一些和性能調優相關的列:
r:等待在CPU資源的進程數。這個數據比平均負載更加能夠體現CPU負載情況,數據中不包含等待IO的進程。如果這個數值大于機器CPU核數,那么機器的CPU資源已經飽和。
free:系統可用內存數(以千字節為單位),如果剩余內存不足,也會導致系統性能問題。下文介紹到的free命令,可以更詳細的了解系統內存的使用情況。
si, so:交換區寫入和讀取的數量。如果這個數據不為0,說明系統已經在使用交換區(swap),機器物理內存已經不足。
us, sy, id, wa, st:這些都代表了CPU時間的消耗,它們分別表示用戶時間(user)、系統(內核)時間(sys)、空閑時間(idle)、IO等待時間(wait)和被偷走的時間(stolen,一般被其他虛擬機消耗)。
上述這些CPU時間,可以讓我們很快了解CPU是否出于繁忙狀態。一般情況下,如果用戶時間和系統時間相加非常大,CPU出于忙于執行指令。如果IO等待時間很長,那么系統的瓶頸可能在磁盤IO。
示例命令的輸出可以看見,大量CPU時間消耗在用戶態,也就是用戶應用程序消耗了CPU時間。這不一定是性能問題,需要結合r隊列,一起分析。
4.mpstat -P ALL 1
$ mpstat -P ALL 1 Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU) 07:38:49 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 07:38:50 PM all 98.47 0.00 0.75 0.00 0.00 0.00 0.00 0.00 0.00 0.78 07:38:50 PM 0 96.04 0.00 2.97 0.00 0.00 0.00 0.00 0.00 0.00 0.99 07:38:50 PM 1 97.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 2.00 07:38:50 PM 2 98.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 1.00 07:38:50 PM 3 96.97 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 3.03 [...]
該命令可以顯示每個CPU的占用情況,如果有一個CPU占用率特別高,那么有可能是一個單線程應用程序引起的。
5.pidstat 1
$ pidstat 1 Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU) 07:41:02 PM UID PID %usr %system %guest %CPU CPU Command 07:41:03 PM 0 9 0.00 0.94 0.00 0.94 1 rcuos/0 07:41:03 PM 0 4214 5.66 5.66 0.00 11.32 15 mesos-slave 07:41:03 PM 0 4354 0.94 0.94 0.00 1.89 8 java 07:41:03 PM 0 6521 1596.23 1.89 0.00 1598.11 27 java 07:41:03 PM 0 6564 1571.70 7.55 0.00 1579.25 28 java 07:41:03 PM 60004 60154 0.94 4.72 0.00 5.66 9 pidstat 07:41:03 PM UID PID %usr %system %guest %CPU CPU Command 07:41:04 PM 0 4214 6.00 2.00 0.00 8.00 15 mesos-slave 07:41:04 PM 0 6521 1590.00 1.00 0.00 1591.00 27 java 07:41:04 PM 0 6564 1573.00 10.00 0.00 1583.00 28 java 07:41:04 PM 108 6718 1.00 0.00 0.00 1.00 0 snmp-pass 07:41:04 PM 60004 60154 1.00 4.00 0.00 5.00 9 pidstat ^C
pidstat命令輸出進程的CPU占用率,該命令會持續輸出,并且不會覆蓋之前的數據,可以方便觀察系統動態。如上的輸出,可以看見兩個JAVA進程占用了將近1600%的CPU時間,既消耗了大約16個CPU核心的運算資源。
iostat 是收集和展示系統輸入和輸出存儲設備統計的簡單工具
這個工具通常用于查找存儲設備性能問題,包括設備、本地磁盤、例如 NFS 遠程磁盤
$ iostat -xz 1 Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU) avg-cpu: %user %nice %system %iowait %steal %idle 73.96 0.00 3.73 0.03 0.06 22.21 Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util xvda 0.00 0.23 0.21 0.18 4.52 2.08 34.37 0.00 9.98 13.80 5.42 2.44 0.09 xvdb 0.01 0.00 1.02 8.94 127.97 598.53 145.79 0.00 0.43 1.78 0.28 0.25 0.25 xvdc 0.01 0.00 1.02 8.86 127.79 595.94 146.50 0.00 0.45 1.82 0.30 0.27 0.26 dm-0 0.00 0.00 0.69 2.32 10.47 31.69 28.01 0.01 3.23 0.71 3.98 0.13 0.04 dm-1 0.00 0.00 0.00 0.94 0.01 3.78 8.00 0.33 345.84 0.04 346.81 0.01 0.00 dm-2 0.00 0.00 0.09 0.07 1.35 0.36 22.50 0.00 2.55 0.23 5.62 1.78 0.03 [...] ^C
iostat命令主要用于查看機器磁盤IO情況。該命令輸出的列,主要含義是:
r/s, w/s, rkB/s, wkB/s:分別表示每秒讀寫次數和每秒讀寫數據量(千字節)。讀寫量過大,可能會引起性能問題。
await:IO操作的平均等待時間,單位是毫秒。這是應用程序在和磁盤交互時,需要消耗的時間,包括IO等待和實際操作的耗時。如果這個數值過大,可能是硬件設備遇到了瓶頸或者出現故障。
avgqu-sz:向設備發出的請求平均數量。如果這個數值大于1,可能是硬件設備已經飽和(部分前端硬件設備支持并行寫入)。
%util:設備利用率。這個數值表示設備的繁忙程度,經驗值是如果超過60,可能會影響IO性能(可以參照IO操作平均等待時間)。如果到達100%,說明硬件設備已經飽和。
如果顯示的是邏輯設備的數據,那么設備利用率不代表后端實際的硬件設備已經飽和。值得注意的是,即使IO性能不理想,也不一定意味這應用程序性能會不好,可以利用諸如預讀取、寫緩存等策略提升應用性能。
7.free –m
$ free -m total used free shared buffers cached Mem: 245998 24545 221453 83 59 541 -/+ buffers/cache: 23944 222053 Swap: 0 0 0
free命令可以查看系統內存的使用情況,-m參數表示按照兆字節展示。最后兩列分別表示用于IO緩存的內存數,和用于文件系統頁緩存的內存數。需要注意的是,第二行-/+ buffers/cache,看上去緩存占用了大量內存空間。這是Linux系統的內存使用策略,盡可能的利用內存,如果應用程序需要內存,這部分內存會立即被回收并分配給應用程序。因此,這部分內存一般也被當成是可用內存。
如果可用內存非常少,系統可能會動用交換區(如果配置了的話),這樣會增加IO開銷(可以在iostat命令中提現),降低系統性能。
8.sar -n DEV 1
$ sar -n DEV 1 Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU) 12:16:48 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil 12:16:49 AM eth0 18763.00 5032.00 20686.42 478.30 0.00 0.00 0.00 0.00 12:16:49 AM lo 14.00 14.00 1.36 1.36 0.00 0.00 0.00 0.00 12:16:49 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 12:16:49 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil 12:16:50 AM eth0 19763.00 5101.00 21999.10 482.56 0.00 0.00 0.00 0.00 12:16:50 AM lo 20.00 20.00 3.25 3.25 0.00 0.00 0.00 0.00 12:16:50 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 ^C
sar命令在這里可以查看網絡設備的吞吐率。在排查性能問題時,可以通過網絡設備的吞吐量,判斷網絡設備是否已經飽和。如示例輸出中,eth0網卡設備,吞吐率大概在22 Mbytes/s,既176 Mbits/sec,沒有達到1Gbit/sec的硬件上限。
9.sar -n TCP,ETCP 1
$ sar -n TCP,ETCP 1 Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU) 12:17:19 AM active/s passive/s iseg/s oseg/s 12:17:20 AM 1.00 0.00 10233.00 18846.00 12:17:19 AM atmptf/s estres/s retrans/s isegerr/s orsts/s 12:17:20 AM 0.00 0.00 0.00 0.00 0.00 12:17:20 AM active/s passive/s iseg/s oseg/s 12:17:21 AM 1.00 0.00 8359.00 6039.00 12:17:20 AM atmptf/s estres/s retrans/s isegerr/s orsts/s 12:17:21 AM 0.00 0.00 0.00 0.00 0.00 ^C
sar命令在這里用于查看TCP連接狀態,其中包括:
active/s:每秒本地發起的TCP連接數,既通過connect調用創建的TCP連接;
passive/s:每秒遠程發起的TCP連接數,即通過accept調用創建的TCP連接;
retrans/s:每秒TCP重傳數量;
TCP連接數可以用來判斷性能問題是否由于建立了過多的連接,進一步可以判斷是主動發起的連接,還是被動接受的連接。TCP重傳可能是因為網絡環境惡劣,或者服務器壓力過大導致丟包。
10.top — Linux 系統進程監控
top 命令是性能監控程序,它可以在很多 Linux/Unix 版本下使用,并且它也是 Linux 系統管理員經常使用的監控系統性能的工具。Top 命令可以定期顯示所有正在運行和實際運行并且更新到列表中,它顯示出 CPU 的使用、內存的使用、交換內存、緩存大小、緩沖區大小、過程控制、用戶和更多命令。它也會顯示內存和 CPU 使用率過高的正在運行的進程。當我們對 Linux 系統需要去監控和采取正確的行動時,top 命令對于系統管理員是非常有用的。讓我們看下 top 命令的實際操作。
$ top top - 00:15:40 up 21:56, 1 user, load average: 31.09, 29.87, 29.92 Tasks: 871 total, 1 running, 868 sleeping, 0 stopped, 2 zombie %Cpu(s): 96.8 us, 0.4 sy, 0.0 ni, 2.7 id, 0.1 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem: 25190241+total, 24921688 used, 22698073+free, 60448 buffers KiB Swap: 0 total, 0 used, 0 free. 554208 cached Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 20248 root 20 0 0.227t 0.012t 18748 S 3090 5.2 29812:58 java 4213 root 20 0 2722544 64640 44232 S 23.5 0.0 233:35.37 mesos-slave 66128 titancl+ 20 0 24344 2332 1172 R 1.0 0.0 0:00.07 top 5235 root 20 0 38.227g 547004 49996 S 0.7 0.2 2:02.74 java 4299 root 20 0 20.015g 2.682g 16836 S 0.3 1.1 33:14.42 java 1 root 20 0 33620 2920 1496 S 0.0 0.0 0:03.82 init 2 root 20 0 0 0 0 S 0.0 0.0 0:00.02 kthreadd 3 root 20 0 0 0 0 S 0.0 0.0 0:05.35 ksoftirqd/0 5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H 6 root 20 0 0 0 0 S 0.0 0.0 0:06.94 kworker/u256:0 8 root 20 0 0 0 0 S 0.0 0.0 2:38.05 rcu_sched
top命令包含了前面好幾個命令的檢查的內容。比如系統負載情況(uptime)、系統內存使用情況(free)、系統CPU使用情況(vmstat)等。因此通過這個命令,可以相對全面的查看系統負載的來源。同時,top命令支持排序,可以按照不同的列排序,方便查找出諸如內存占用最多的進程、CPU占用率最高的進程等。
但是,top命令相對于前面一些命令,輸出是一個瞬間值,如果不持續盯著,可能會錯過一些線索。這時可能需要暫停top命令刷新,來記錄和比對數據。
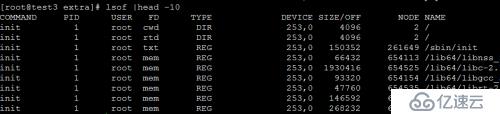
lsof 命令對于很多 Linux/Unix 系統都可以使用,主要以列表的形式顯示打開的文件和進程。
打開的文件主要包括磁盤文件、網絡套接字、管道、設備和進程。使用這個命令的主要原因是一個一個盤不能卸載并且顯示文件正在使用或者打開的錯誤信息。這個命令很容易看出哪些文件正在使用
這個命令最常用的格式:
tcpdump 是一種使用最廣泛的命令行網絡數據包分析器或數據包嗅探程序,主要用于捕獲和過濾 TCP/IP 包收到或者轉移在一個網絡的特定借口信息。它也提供了一個選項參數去保存將捕獲的包在一個文件中用于以后分析使用,tcpdump 幾乎在所有的 Linux 版本中都是可用的。

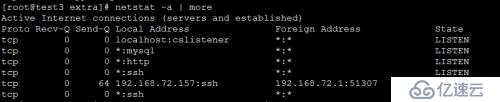
netstat 命令是一個監控網絡數據包傳入和傳出的統計界面的命令行工具
它對于許多系統管理員去監控網絡性能和解決網絡相關問題是一個非常有用的工具
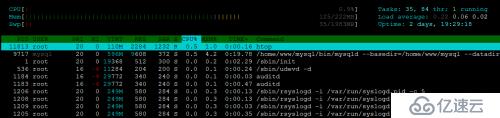
htop 是一個更加先進的交互式的實時監控工具。htop 與 top 命令非常相似,但是他有一些非常豐富的功能,如用戶友好界面管理進程、快捷鍵、橫向和縱向進程等更多的。htop 是一個第三方工具并不包括在 Linux 系統中,你需要使用包管理工具進行安裝

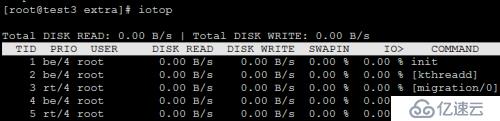
iotop 也是和 top 和 htop 命令相似,但是它會有一個報告功能去監控和顯示實時的磁盤 I/O 輸入和輸出和程序進程。這個工具對于查找精確的高的磁盤讀/寫過程是非常有用的
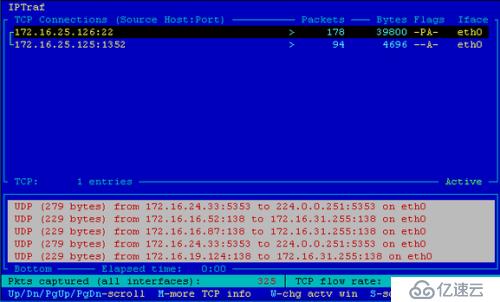
IPTraf 是一個基于開源的 Linux 系統實時網絡(IP 網絡)監測工具。它能收集到各種各樣的信息,如通過網絡對 IP 流量監測,包括 TCP 標志信息、ICMP 詳細細節、TCP/UDP 流量故障、TCP 連接的數據包和拜恩計數
并且它還收集 TCP,UDP,ICMP,IP,非 IP,IP 校驗錯誤,界面活性等一般信息和詳細信息的接口統計數據
Psacct 或者 Acct 是用于監測每個用戶對系統的活躍狀態的一個非常有用的工具。在后臺有兩個守護進程在運行,一個是密切關注系統上每個用戶的整體活動,另一個進程關注有哪些資源被它們消耗
這個工具對于系統管理員是非常有用的去跟蹤每個用戶的活動,可以知道用戶正在做什么,發出了什么樣的命令,占用了多少資源,多長時間活躍在系統上
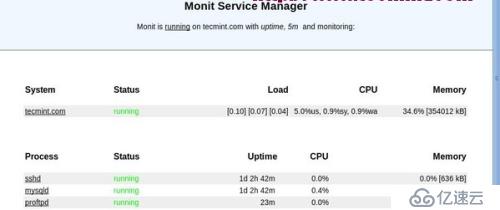
這是一個免費的開源的基于 web 程序的自動監控和管理系統進程、程序、文件、目錄、權限、校驗文件系統
它監控的服務包括 Apache、MYSQL、Mail、FTP、Nginx 等。系統狀態可以從命令行或自己的網絡接口來查看

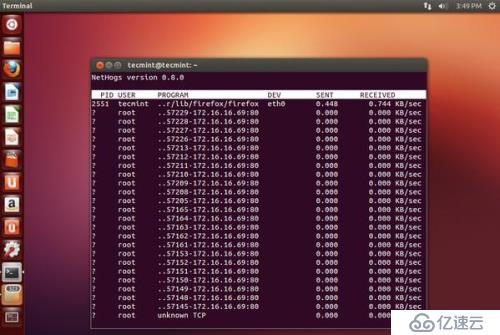
NetHogs 是一個開源的漂亮的小程序(類似于 Linux 上面的 top 命令)
在您的系統上保持每個進程的網絡活動狀態。它也保持了一個程序或者應用實時的網絡流量帶寬使用情況
iftop 是另一個基于終端的開源的系統監測工具,主要功能是通過你自己系統上的網絡接口顯示一個經常更新的網絡帶寬利用率的列表(即源主機和目的主機)。iftop 監控的是網絡的使用情況,而 top 監控的是 CPU 的使用情況。iftop 監視一個選定的接口并且顯示兩臺主機之間當前寬帶的使用情況

Monitorix 是一個盡可能多的在 Linux/Unix 上一個輕量級監控工具,主要設計是監控正在運行的系統和網絡資源。它有一個內置的 HTTP web 服務去定期收集系統和網絡信息并顯示成圖片。它可以監視系統的平均負載使用、內存的分配、磁盤驅動器、系統服務、網絡端口、郵件統計(Sendmail、Postfix、Dovecot )MYSQL 數據庫等更多的服務。它的主要目的是監控整個系統的性能,并且有助于監測故障、瓶頸、異常活動等狀況
Arpwatch是一種用來監視 Linux 網絡的以太網的網絡流量的地址解析(網絡地址轉換)的一個程序,它一直隨著網絡時間戳的變化監視以太網流量和產生日志的 IP 和 MAC 地址對,當一個 IP 地址或 MAC 地址對發生變化的時候,它會發送電子郵件通知管理員;并且它在檢測 ARP ***是非常有用的
Suricata 是一個高性能的開源的網絡安全與***檢測與預防 Linux、FreeBSD、Windows
等操作系統的監控工具。它是一個非營利基金 OISF(Open Information Security Foundation)擁有的
VnStat PHP 是一個 web 前端應用最流行的社交工具叫“vnstat”。 VnStat PHP 使用了很好的圖形模式監控網絡流量的使用情況。它顯示了每時、每天、每月的總結報告中的網絡流量使用情況
Nagios 是一個領先的開源的強大的監控系統,網絡/系統管理員在他們影響主要業務流程之前識別和解決服務器相關的問題。Nagios 可以監控遠程 Linux、Windows、開關、單窗口的路由器和打印機
它能顯示你的網絡和服務器關鍵的告警,有利于在錯誤反生之前幫助你解決問題
Nmon(即奈吉爾性能監視器)工具用來監視 Linux 系統的所有資源包括:CPU、內存、磁盤使用率、網絡上的進程、NFS、內核等等。這個工具有兩個模式:即在線模式和捕捉模式,在線模式適用于實時監控,捕捉模式用于存儲輸出為 CSV 格式后的處理
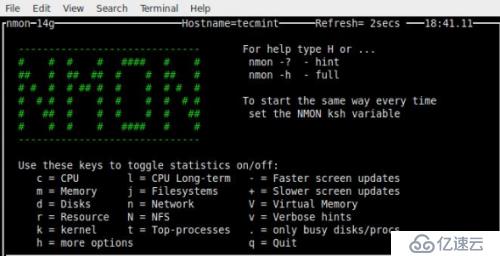
Collectl 是另一個功能強大的基于命令行的監控工具,它可用于收集有關系統資源的信息
包括 CPU 使用率、內存、網絡、節點、進程、NFS、TCP 套接等等
關于“查看Linux服務器性能的日常命令和工具有哪些”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





