溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下如何用python實現專業評估舞蹈程序,希望大家閱讀完這篇文章后大所收獲,下面讓我們一起去探討方法吧!
整體實現思路
主要以安崎小甜心的主題曲直拍視頻作為標準視頻,謝可寅shaking的主題曲直拍視頻作為測試視頻
1、將標準視頻進行爬取,將視頻逐幀讀取成圖片;
2、由于圖片背景光線不太利于關鍵點捕抓,利用deeplabv3p_xception65_humanseg進行摳圖處理;
3、基于pose_resnet50_mpii模型進行關鍵點檢測并存儲檢測結果;
4、然后對測試視頻作同樣處理存儲檢測結果;
5、基于單通道的直方圖對標準檢測結果集以及測試檢測結果集進行圖片相似度計算,取結果均值作為選手的主題曲實力值;
6、將獲取的實力值合成到選手圖片并輸出
7、爬取微博測試選手相關評論,統計高頻詞輸出圖
8、對評論進行情感分析,輸出總體評論積極與消極的對比餅圖
提前披露效果
看了那么長我的肺腑之言,來看點效果,提升閱讀欲望
首先我們接下來會用人體關鍵點識別模型去識別動作,識別的效果大概是這樣的,可以看到我們把安崎小甜心的四肢都能識別到。

然后為了方便比對,我們直接把四肢關鍵點畫線部分單獨提取出來,方便后面對比
對比項:

計算每一幀的對比結果,得出評估分值,合成到選手圖片上

最后通過爬取微博評論,經過LSTM模型進行情感分析后,得出選手的大眾好感度對比
舞蹈實力評估
舞蹈實力評估主要對選手的舞蹈動作進行關鍵點檢測與標準的動作進行對比,得出相似度,計算每一幀的動作相似度均值,得出選手舞蹈實力評估值。
模型介紹
主要使用的模型是pose_resnet50_mpii
人體骨骼關鍵點檢測(Pose Estimation) 是計算機視覺的基礎性算法之一,
在諸多計算機視覺任務起到了基礎性的作用,如行為識別、人物跟蹤、步態識別等相關領域。
具體應用主要集中在智能視頻監控,病人監護系統,人機交互,虛擬現實,人體動畫,智能家居,智能安防,運動員輔助訓練等等。
環境準備
終端下載最新版的paddlehub以及paddlepaddle
pip install --upgrade paddlepaddle pip install --upgrade paddlehub
引入庫
#相關庫的導入 import os import cv2 import paddlehub as hub from moviepy.editor import * from matplotlib import pyplot as plt import numpy as np import matplotlib.pyplot as plt import matplotlib.image as mpimg from PIL import ImageFont, ImageDraw, Image import requests
打開終端下載模型
hub install pose_resnet50_mpii
引入模型
pose_resnet50_mpii = hub.Module(name="pose_resnet50_mpii")
人體骨骼關鍵點檢測
定義數據轉化格式
函數change_data(result)
輸入參數:人體骨骼關鍵點檢測模型的輸出結果
輸出參數:關于人體關鍵點的全局變量
函數功能 :將位置點預測模型輸出的數據形式轉為預期的數據
def change_data(result): global left_ankle,left_knee,left_hip,right_hip,right_knee,right_ankle,pelvis,thorax,upper_neck global right_wrist,right_elbow,right_shoulder,left_shoulder,left_elbow,left_wrist,head_top left_ankle = result['data']['left_ankle'] left_knee = result['data']['left_knee'] left_hip = result['data']['left_hip'] right_hip = result['data']['right_hip'] right_knee = result['data']['right_knee'] right_ankle = result['data']['right_ankle'] pelvis = result['data']['pelvis'] thorax = result['data']['thorax'] upper_neck = result['data']['upper neck'] head_top = result['data']['head top'] right_wrist = result['data']['right_wrist'] right_elbow = result['data']['right_elbow'] right_shoulder = result['data']['right_shoulder'] left_shoulder = result['data']['left_shoulder'] left_elbow = result['data']['left_elbow'] left_wrist = result['data']['left_wrist']
將位置點連線
格式 cv2.circle(img, point, point_size, point_color, thickness)
輸入參數:predict_img_path為輸入圖片的地址
輸出參數:由兩個分別是將人體關鍵點的線畫在空白背景上/模型輸出的圖片上
功能:給圖片劃線并寫入將圖片按一定順序保存
def write_line(predict_img_path,output_path): global count_frame print(predict_img_path) img = cv2.imread(predict_img_path) thickness = 2 point_color = (0, 255, 0) # BGR # 格式cv2.circle(img, point, point_size, point_color, thickness) cv2.line(img, (head_top[0],head_top[1]), (upper_neck[0],upper_neck[1]), point_color, 1) cv2.line(img, (upper_neck[0],upper_neck[1]), (thorax[0],thorax[1]), point_color, thickness) cv2.line(img, (upper_neck[0],upper_neck[1]), (left_shoulder[0],left_shoulder[1]), point_color, thickness) cv2.line(img, (upper_neck[0],upper_neck[1]), (right_shoulder[0],right_shoulder[1]), point_color, thickness) cv2.line(img, (left_shoulder[0],left_shoulder[1]), (left_elbow[0],left_elbow[1]), point_color, thickness) cv2.line(img, (left_elbow[0],left_elbow[1]), (left_wrist[0],left_wrist[1]), point_color, thickness) cv2.line(img, (right_shoulder[0],right_shoulder[1]), (right_elbow[0],right_elbow[1]), point_color, thickness) cv2.line(img, (right_elbow[0],right_elbow[1]), (right_wrist[0],right_wrist[1]), point_color, thickness) cv2.line(img, (left_hip[0],left_hip[1]), (left_knee[0],left_knee[1]), point_color, thickness) cv2.line(img, (left_knee[0],left_knee[1]), (left_ankle[0],left_ankle[1]), point_color, thickness) cv2.line(img, (right_hip[0],right_hip[1]), (right_knee[0],right_knee[1]), point_color, thickness) cv2.line(img, (right_knee[0],right_knee[1]), (right_ankle[0],right_ankle[1]), point_color, thickness) cv2.line(img, (thorax[0],thorax[1]), (left_hip[0],left_hip[1]), point_color, thickness) cv2.line(img, (thorax[0],thorax[1]), (right_hip[0],right_hip[1]), point_color, thickness) true_count = count_frame //2 cv2.imwrite(output_path+ str(true_count) +".jpg",img) count_frame = count_frame +1
連接監測點進行畫線并輸出
def GetOutputPose(frame_path,output_black_path,output_pose_path):
"輸入需要進行關鍵點檢測的圖片目錄,進行檢測后分別輸出原圖加線的圖片以及只有關鍵點連線的圖"
"black_path:只有關鍵點連線的圖片目錄"
"frame_path:需要處理的圖片目錄"
"output_pose_path:帶原圖加連線的圖片目錄"
# 配置
num = os.listdir(frame_path)
for i in range(0,len(num)-1):
img_black = np.zeros((size_x,size_y,3), np.uint8)
img_black.fill(255)
img_black_path =output_black_path + str(i) + ".jpg"
cv2.imwrite(img_black_path,img_black)
for i in range(0,len(num)-1):
path_dict = frame_path + str(i) + ".jpg"
input_dict = {"image":[path_dict]}
print("This is OutputPose {} pictrue".format(i))
results = pose_resnet50_mpii.keypoint_detection(data=input_dict)
for result in results:
change_data(result)
write_line(path_dict,output_pose_path)
write_line(img_black_path,output_black_path)輸出結果,獲取每一幀的人體骨骼檢測圖

動作評估
上面我們已經生成了青春有你2的主題曲標準舞蹈的關鍵點畫線集合,接下來,我們需要實現對比標準舞蹈動作以及測試舞蹈動作,計算每一幀圖片的相似度,然后通過均值計算獲取選手主題曲的舞蹈實力分數
相似值計算
基于直方圖計算兩個圖片之間的相似度
import cv2 # 計算單通道的直方圖的相似值 def calculate(image1, image2): hist1 = cv2.calcHist([image1], [0], None, [256], [0.0, 255.0]) hist2 = cv2.calcHist([image2], [0], None, [256], [0.0, 255.0]) # 計算直方圖的重合度 degree = 0 for i in range(len(hist1)): if hist1[i] != hist2[i]: degree = degree + (1 - abs(hist1[i] - hist2[i]) / max(hist1[i], hist2[i])) else: degree = degree + 1 degree = degree / len(hist1) return degree
將實力值合成到測試選手的圖片上面
from PIL import Image from PIL import ImageFilter from PIL import ImageEnhance from PIL import ImageDraw , ImageFont def draw_text(bg_path,text,output_path): """ 實現圖片上面疊加中文 bg_path:需要加中文的圖片 text: 添加的中文內容 output_path: 合成后輸出的圖片路徑 """ im = Image.open(bg_path) draw = ImageDraw.Draw(im) fnt = ImageFont.truetype(r'fonts/SimHei.ttf',32) draw.text((100, 600), text, fill='red', font=fnt) im.show() im.save(output_path)
輸出結果

大眾好感分析
主要是基于LSTM模型對微博評論進行情感分析
1.爬取與測試選手相關微博評論
2.訓練模型
3.得出選手好感度以及搜索輸出選手話題詞頻統計
模型介紹
情感傾向分析(Sentiment Classification,簡稱Senta)針對帶有主觀描述的中文文本,可自動判斷該文本的情感極性類別并給出相應的置信度,能夠幫助企業理解用戶消費習慣、分析熱點話題和危機輿情監控,為企業提供有利的決策支持。該模型基于一個LSTM結構,情感類型分為積極、消極。該PaddleHub Module支持預測和Fine-tune。
引入模型
下載
hub install senta_lstm
引入
senta = hub.Module(name="senta_lstm")
爬取微博評論
import requests
from pyquery import PyQuery as pq
import time
from urllib.parse import quote
import os
def get_page(page):
"""
通過微博api獲取微博數據
page: 分頁頁數
"""
headers = {
'Host': 'm.weibo.cn',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
url = 'https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D'+quote(m)+'&page_type=searchall&page='+str(page)#將你檢索內容轉為超鏈接
print(url)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
print(page)
return response.json()
except requests.ConnectionError as e:
print('Error', e.args)
def parse_page(json):
f_comments=open('comment/comment.txt','a')
f_user=open('comment/weibo_user.txt','a')
if json:
items = json.get('data').get('cards')
for i in items:
item = i.get('mblog')
if item == None:
continue
weibo = {}
weibo['id'] = item.get('id')
weibo['text'] = pq(item.get('text')).text()
weibo['name'] = item.get('user').get('screen_name')
if item.get('longText') != None :#要注意微博分長文本與文本,較長的文本在文本中會顯示不全,故我們要判斷并抓取。
weibo['longText'] = item.get('longText').get('longTextContent')
else:
weibo['longText'] =None
# print(weibo['name'])
# print(weibo['text'])
if weibo['longText'] !=None:
f_comments.write(weibo['longText'])
f_comments.write(weibo['text']+'\n')
f_user.write(weibo['name']+'\n')
# yield weibo
f_comments.close()
f_user.close()
if __name__ == '__main__':
m = '謝可寅'
n = 50
for page in range(1,n+1):
time.sleep(1) #設置睡眠時間,防止被封號
json = get_page(page)
parse_page(json)爬取評論結果:

清洗評論以及去除停用詞
由于評論中含有一些表情包什么的,得處理一下
import re #正則匹配
import jieba #中文分詞
#去除文本中特殊字符
def clear_special_char(content):
'''
正則處理特殊字符
參數 content:原文本
return: 清除后的文本
'''
f_clear = open('comment/clear_comment.txt','a')
clear_content = re.findall('[\u4e00-\u9fa5a-zA-Z0-9]+',content,re.S) #只要字符串中的中文,字母,數字
str=','.join(clear_content)
f_clear.write(str+'\n')
f_clear.close
return str
def fenci(content):
'''
利用jieba進行分詞
參數 text:需要分詞的句子或文本
return:分詞結果
'''
jieba.load_userdict(r"dic/user_dic.txt")
seg_list = jieba.cut(content)
return seg_list
def stopwordslist():
'''
創建停用詞表
參數 file_path:停用詞文本路徑
return:停用詞list
'''
stopwords = [line.strip() for line in open('work/stopwords.txt',encoding='UTF-8').readlines()]
acstopwords=['哦','因此','不然','謝可寅','超話']
stopwords.extend(acstopwords)
return stopwords
import pandas as pd
def movestopwords(sentence_depart,stopwords):
'''
去除停用詞,統計詞頻
參數 file_path:停用詞文本路徑 stopwords:停用詞list counts: 詞頻統計結果
return:None
'''
segments = []
# 去停用詞
for word in sentence_depart:
if word not in stopwords:
if word != '\t':
# outstr += word
# outstr += " "
segments.append(word)
return segments處理結果:

統計選手高頻TOP10詞
通過微博評論 統計選手高頻TOP10詞
import collections
def drawcounts(segments):
'''
繪制詞頻統計表
參數 counts: 詞頻統計結果 num:繪制topN
return:none
'''
# 詞頻統計
word_counts = collections.Counter(segments) # 對分詞做詞頻統計
word_counts_top10 = word_counts.most_common(10) # 獲取前10最高頻的詞
print (word_counts_top10)
dic=dict(word_counts_top10)
print(dic)
x_values=[]
y_values=[]
for k in dic:
x_values.append(k)
y_values.append(dic[k])
# 設置顯示中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默認字體
plt.figure(figsize=(20,15))
plt.bar(range(len(y_values)), y_values,color='r',tick_label=x_values,facecolor='#9999ff',edgecolor='white')
# 這里是調節橫坐標的傾斜度,rotation是度數,以及設置刻度字體大小
plt.xticks(rotation=45,fontsize=20)
plt.yticks(fontsize=20)
plt.legend()
plt.title('''謝可寅微博評論詞頻統計''',fontsize = 24)
plt.savefig('highwords.jpg')
plt.show()
return word_counts
if __name__ == '__main__':
stopwords=stopwordslist()
f = open(r"comment/comment.txt")
line = f.readline()
segments=[]
while line:
line = f.readline()
clear_line=clear_special_char(line)
seg_list= fenci(clear_line)
segments_list=movestopwords(seg_list,stopwords)
segments.extend(segments_list)
f.close()
drawcounts(segments)輸出結果:

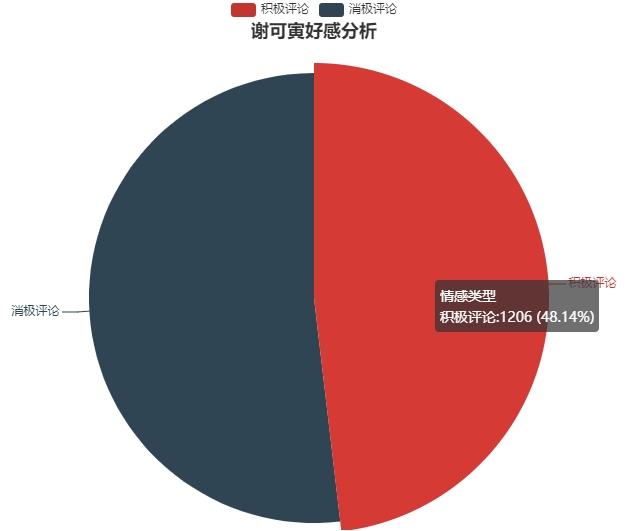
對評論進行情感分析
定義餅圖繪制方法
使用pyecharts庫進行餅圖繪制
# from pyecharts import Pie
# from pyecharts.charts.basic_charts.pie import Pie
from pyecharts.charts import Pie
from pyecharts import options as opts
def draw_pie(data,labels):
"""
繪制餅圖
"""
data_pie = [list(i) for i in zip(labels,data)]
# 創建實例對象
pie = Pie(init_opts=opts.InitOpts(width='1000px',height='600px'))
# 添加數據
pie.add(series_name="情感類型",data_pair=data_pie)
# 設置全局項
pie.set_global_opts(title_opts=opts.TitleOpts(title="謝可寅好感分析",pos_left='center',pos_top=20))
#設置每項數據占比
pie.set_series_opts(tooltip_opts=opts.TooltipOpts(trigger='item',formatter="{a} <br/> {b}:{c} (aegqsqibtmh%)"))
pie.render("pie_charts.html")lstm模型分析評論
if __name__ == '__main__':
f = open(r"comment/clear_comment.txt")
line = f.readline()
comments=[]
while line:
comments.append(line)
line = f.readline()
f.close()
input_dict = {"text": comments}
## 情感分析
results = senta.sentiment_classify(data=input_dict,batch_size=5)
positive_num=0
negative_num=0
for result in results:
if result['sentiment_key'] == 'positive':
positive_num+=1
else:
negative_num+=1
print("total:%f,pos:%f,neg:%f"%(len(results),positive_num,negative_num))
data=[positive_num,negative_num]
labels=['積極評論','消極評論']
draw_pie(data,labels)輸出結果:
看完了這篇文章,相信你對如何用python實現專業評估舞蹈程序有了一定的了解,想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





