溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文介紹的是關于Java中ArrayList的removeAll方法的相關內容,分享出來供大家參考學習,下面來一起看看詳細的介紹:
在開發過程中,遇到一個情況,就是從所有騎手Id中過濾沒有標簽的騎手Id(直接查詢沒有標簽的騎手不容易實現),
List<Integer> allRiderIdList = new ArrayList(); // 所有的騎手,大致有23W數據 List<Integer> hasAnyTagRiderId = new ArrayList(); // 有標簽的騎手, 大致有21W數據 List<Integer> withoutAnyTagRiderList = allRiderIdList.removeAll(hasAnyTagRiderId);
邏輯很簡單,就是取一個差集,這樣子就拿到沒有任何標簽的騎手數據。
但是在實際開發過程中,removeAll這個動作很耗時,做測試大概要4分鐘左右。查看ArrayList中removeAll的源碼片段:
public boolean removeAll(Collection<?> c) {
Objects.requireNonNull(c);
return batchRemove(c, false);
}
private boolean batchRemove(Collection<?> c, boolean complement) {
final Object[] elementData = this.elementData;
int r = 0, w = 0;
boolean modified = false;
try {
for (; r < size; r++) // 循環原來的list
if (c.contains(elementData[r]) complement) // 這里調用contains方法
elementData[w++] = elementData[r];
} finally {
....
}
return modified;
}
在循環過程中調用contains方法做比較,查一下ArrayList的contains方法,源代碼片段如下:
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
public int indexOf(Object o) {
if (o null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
這可以看出來,在比較的過程中,又調用了一次循環。
所以removeAll兩層for循環,復雜度O(m*n),所以在操作比較大的ArrayList時,這種方法是絕對不可取的。
下面看一下最終的實現方式:
private List<Integer> removeAll(List<Integer> src, List<Integer> target) {
LinkedList<Integer> result = new LinkedList<>(src); //大集合用linkedlist
HashSet<Integer> targetHash = new HashSet<>(target); //小集合用hashset
Iterator<Integer> iter = result.iterator(); //采用Iterator迭代器進行數據的操作
while(iter.hasNext()){
if(targetHash.contains(iter.next())){
iter.remove();
}
}
return result;
}
同樣數量級list, 整個過程只需要幾十毫秒,簡直天壤之別。
回過頭來,比較一下兩種實現方式,為什么差距這個大。
1、外層循環
一個是普通的for循環,一個迭代器遍歷元素,二者相差不大
2、內層數據比較
前者通過index方法把整個數組順序遍歷了一遍;
后者調用HashSet的contains方法,實際上是調用HashMap的containKey方法,查找時是通過hash表查找,復雜度為O(1)。
接下來我們簡單看一下hash表。
hash表是一種特殊的數據結構,它同數組、鏈表以及二叉排序樹等相比較有很明顯的區別,它能夠快速定位到想要查找的記錄,而不是與表中存在的記錄的關鍵字進行比較來進行查找。這個源于Hash表設計的特殊性,它采用了函數映射的思想將記錄的存儲位置與記錄的關鍵字關聯起來,從而能夠很快速地進行查找。可以簡單理解為,以空間換時間,犧牲空間復雜度來換取時間復雜度。
hash表采用一個映射函數 f : key —> address 將關鍵字映射到該記錄在表中的存儲位置,從而在想要查找該記錄時,可以直接根據關鍵字和映射關系計算出該記錄在表中的存儲位置,通常情況下,這種映射關系稱作為hash函數,而通過hash函數和關鍵字計算出來的存儲位置(注意這里的存儲位置只是表中的存儲位置,并不是實際的物理地址)稱作為hash地址。
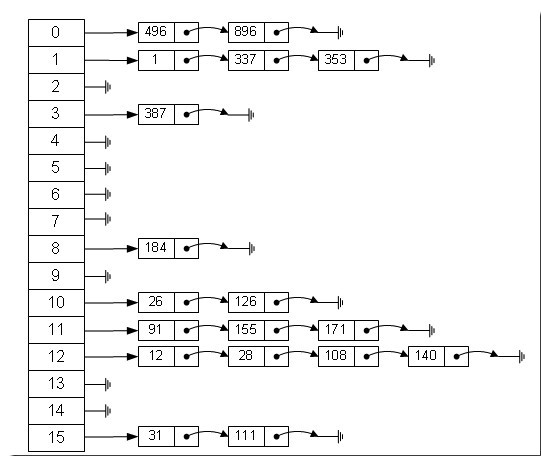
上面的圖大家應該都很熟悉,hash表的一種實現方式,是由數組+鏈表組成的。元素放入hash表的位置通過hash(key)%len獲得,也就是元素的key的哈希值對數組長度取模得到。
另外hash表大小的確定也很關鍵,如果hash表的空間遠遠大于最后實際存儲的記錄個數,則造成了很大的空間浪費,如果選取小了的話,則容易造成沖突。在實際情況中,一般需要根據最終記錄存儲個數和關鍵字的分布特點來確定Hash表的大小。還有一種情況時可能事先不知道最終需要存儲的記錄個數,則需要動態維護Hash表的容量,此時可能需要重新計算Hash地址。
當然,關于hash表要說的話太多,先簡單到此吧~~~
總結
以上就是這篇文章的全部內容了,希望本文的內容對大家的學習或者工作能帶來一定的幫助,如果有疑問大家可以留言交流,謝謝大家對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





