溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關怎么在hadoop中實現一個java爬蟲,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
需要用到
Cygwin:一個在windows平臺上運行的類UNIX模擬環境,直接網上搜索下載,并且安裝;
Hadoop:配置Hadoop環境,實現了一個分布式文件系統(Hadoop Distributed File System),簡稱HDFS,用來將收集的數據直接上傳保存到HDFS,然后用MapReduce分析;
Eclipse:編寫代碼,需要導入hadoop的jar包,以可以創建MapReduce項目;
Jsoup:html的解析jar包,結合正則表達式能更好的解析網頁源碼;
----->
目錄:
1、配置Cygwin
2、配置Hadoop黃靜
3、Eclipse開發環境搭建
4、網絡數據爬取(jsoup)
-------->
1、安裝配置Cygwin
從官方網站下載Cygwin 安裝文件,地址:https://cygwin.com/install.html
下載運行后進入安裝界面。
安裝時直接從網絡鏡像中下載擴展包,至少需要選擇ssh和ssl支持包
安裝后進入cygwin控制臺界面,
運行ssh-host-config命令,安裝SSH
輸入:no,yes,ntsec,no,no
注意:win7下需要改為yes,yes,ntsec,no,yes,輸入密碼并確認這個步驟
完成后會在windows操作系統中配置好一個Cygwin sshd服務,啟動該服務即可。

然后要配置ssh免密碼登陸
重新運行cygwin。
執行ssh localhost,會要求使用密碼進行登陸。
使用ssh-keygen命令來生成一個ssh密鑰,一直回車結束即可。
生成后進入.ssh目錄,使用命令:cp id_rsa.pub authorized_keys 命令來配置密鑰。
之后使用exit退出即可。
重新進入系統后,通過ssh localhost就可以直接進入系統,不需要再輸入密碼了。
2、配置Hadoop環境
修改hadoop-env.sh文件,加入JDK安裝目錄的JAVA_HOME位置設置。
# The java implementation to use. Required. export JAVA_HOME=/cygdrive/c/Java/jdk1.7.0_67
如圖注意:Program Files縮寫為PROGRA~1

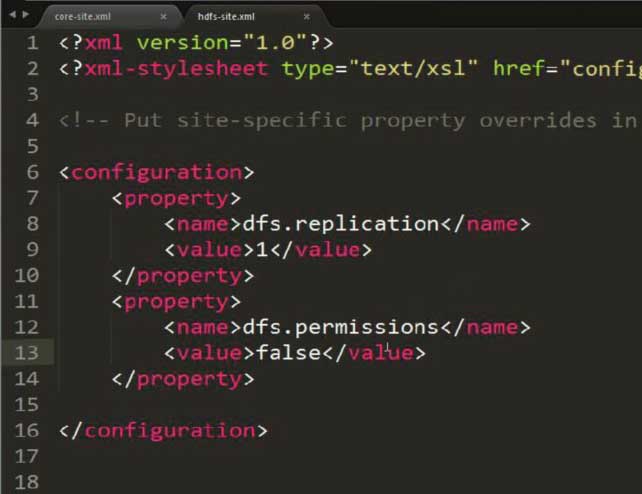
修改hdfs-site.xml,設置存放副本為1(因為配置的是偽分布式方式)
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
注意:此圖片多加了一個property,內容就是解決可能出現的權限問題!!!
HDFS:Hadoop 分布式文件系統
可以在HDFS中通過命令動態對文件或文件夾進行CRUD
注意有可能出現權限的問題,需要通過在hdfs-site.xml中配置以下內容來避免:
<property> <name>dfs.permissions</name> <value>false</value> </property>
修改mapred-site.xml,設置JobTracker運行的服務器與端口號(由于當前就是運行在本機上,直接寫localhost 即可,端口可以綁定任意空閑端口)
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration>
配置core-site.xml,配置HDFS文件系統所對應的服務器與端口號(同樣就在當前主機)
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
配置好以上內容后,在Cygwin中進入hadoop目錄

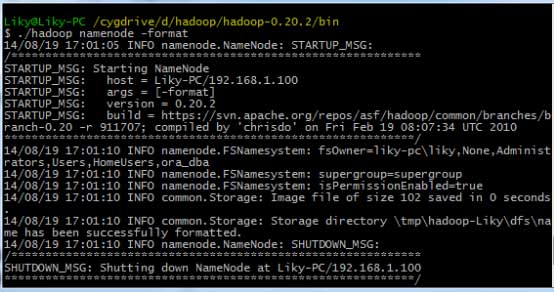
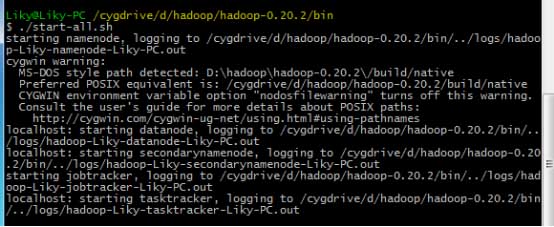
在bin目錄下,對HDFS文件系統進行格式化(第一次使用前必須格式化),然后輸入啟動命令:
3、Eclipse開發環境搭建
這個在我寫的博客 大數據【二】HDFS部署及文件讀寫(包含eclipse hadoop配置)中給出大致配置方法。不過此時需要完善一下。
將hadoop中的hadoop-eclipse-plugin.jar支持包拷貝到eclipse的plugin目錄下,為eclipse添加Hadoop支持。
啟動Eclipse后,切換到MapReduce界面。
在windows工具選項選擇showviews的others里面查找map/reduce locations。
在Map/Reduce Locations窗口中建立一個Hadoop Location,以便與Hadoop進行關聯。

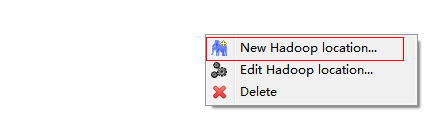
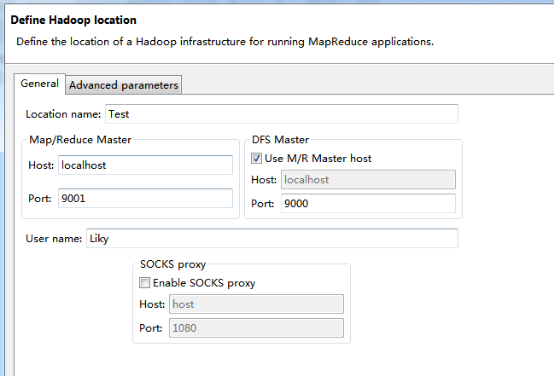
注意:此處的兩個端口應為你配置hadoop的時候設置的端口!!!
完成后會建立好一個Hadoop Location
在左側的DFS Location中,還可以看到HDFS中的各個目錄
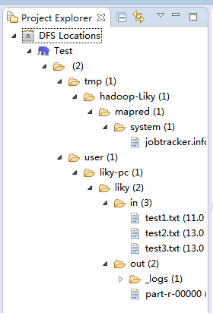
并且你可以在其目錄下自由創建文件夾來存取數據。
下面你就可以創建mapreduce項目了,方法同正常創建一樣。
4、網絡數據爬取
現在我們通過編寫一段程序,來將爬取的新聞內容的有效信息保存到HDFS中。
此時就有了兩種網絡爬蟲的方法:
其一就是利用heritrix工具獲取的數據;
其一就是java代碼結合jsoup編寫的網絡爬蟲。
方法一的信息保存到HDFS:
直接讀取生成的本地文件,用jsoup解析html,此時需要將jsoup的jar包導入到項目中。
package org.liky.sina.save;
//這里用到了JSoup開發包,該包可以很簡單的提取到HTML中的有效信息
import java.io.File;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class SinaNewsData {
private static Configuration conf = new Configuration();
private static FileSystem fs;
private static Path path;
private static int count = 0;
public static void main(String[] args) {
parseAllFile(new File(
"E:/heritrix-1.12.1/jobs/sina_news_job_02-20170814013255352/mirror/"));
}
public static void parseAllFile(File file) {
// 判斷類型
if (file.isDirectory()) {
// 文件夾
File[] allFile = file.listFiles();
if (allFile != null) {
for (File f : allFile) {
parseAllFile(f);
}
}
} else {
// 文件
if (file.getName().endsWith(".html")
|| file.getName().endsWith(".shtml")) {
parseContent(file.getAbsolutePath());
}
}
}
public static void parseContent(String filePath) {
try {
//用jsoup的方法讀取文件路徑
Document doc = Jsoup.parse(new File(filePath), "utf-8");
//讀取標題
String title = doc.title();
Elements descElem = doc.getElementsByAttributeValue("name",
"description");
Element descE = descElem.first();
// 讀取內容
String content = descE.attr("content");
if (title != null && content != null) {
//通過Path來保存數據到HDFS中
path = new Path("hdfs://localhost:9000/input/"
+ System.currentTimeMillis() + ".txt");
fs = path.getFileSystem(conf);
// 建立輸出流對象
FSDataOutputStream os = fs.create(path);
// 使用os完成輸出
os.writeChars(title + "\r\n" + content);
os.close();
count++;
System.out.println("已經完成" + count + " 個!");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}看完上述內容,你們對怎么在hadoop中實現一個java爬蟲有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





