溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關使用Java怎么對微信公眾號批量獲取,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
首先為代理服務器安裝證書,anyproxy默認不解析https鏈接,安裝證書后就可以解析了,在cmd執行anyproxy --root 就會安裝證書,之后還得在模擬器也下載這個證書。
然后輸入anyproxy -i 命令 打開代理服務。(記得加上參數!)

記住這個ip和端口,之后安卓模擬器的代理就用這個。現在用瀏覽器打開網頁:http://localhost:8002/ 這是anyproxy的網頁界面,用于顯示http傳輸數據。
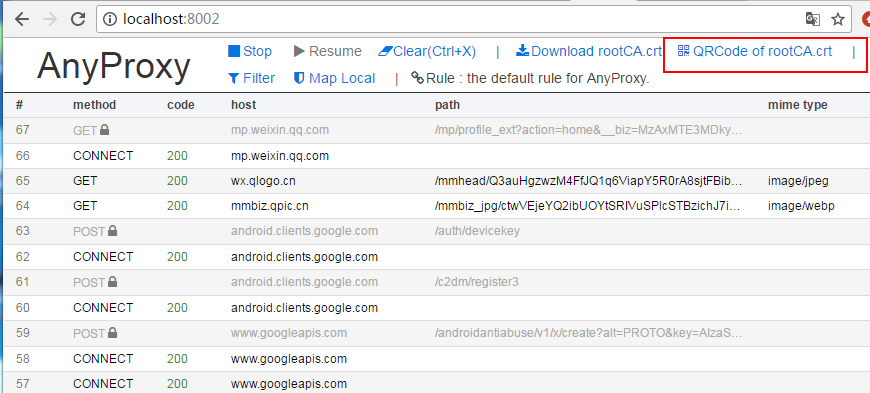
點擊上面紅框框里面的菜單,會出一個二維碼,用安卓模擬器掃碼識別,模擬器(手機)就會下載證書了,安裝上就好了。
現在準備為模擬器設置代理,代理方式設置為手動,代理ip為運行anyproxy機器的ip,端口是8001
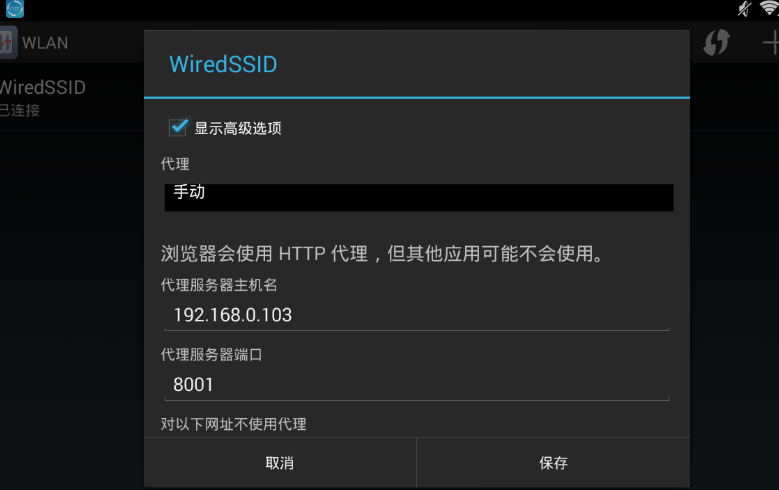
到這里準備工作基本完成,在模擬器上打開微信隨便打開一個公眾號的文章,就能從你剛打開的web界面中看到anyproxy抓取到的數據:
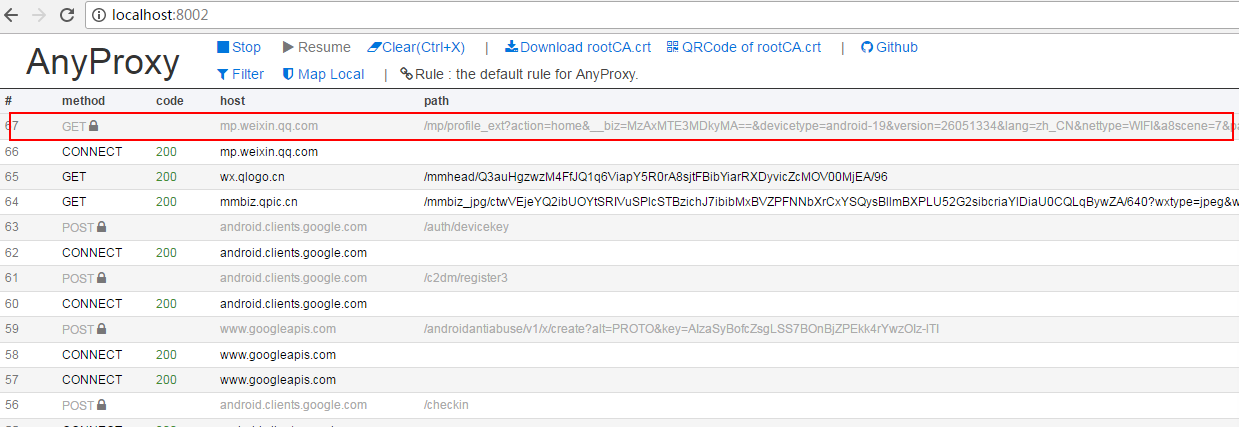
上面紅框內就是微信文章的鏈接,點擊進去可以看到具體的數據。如果response body里面什么都沒有可能證書安裝有問題。
如果上面都走通了,就可以接著往下走了。
這里我們靠代理服務抓微信數據,但總不能抓取一條數據就自己操作一下微信,那樣還不如直接人工復制。所以我們需要微信客戶端自己跳轉頁面。這時就可以使用anyproxy攔截微信服務器返回的數據,往里面注入頁面跳轉代碼,再把加工的數據返回給模擬器實現微信客戶端自動跳轉。
打開anyproxy中的一個叫rule_default.js的js文件,windows下該文件在:C:\Users\Administrator\AppData\Roaming\npm\node_modules\anyproxy\lib
在文件里面有個叫replaceServerResDataAsync: function(req,res,serverResData,callback)的方法,這個方法就是負責對anyproxy拿到的數據進行各種操作。一開始應該只有callback(serverResData);這條語句的意思是直接返回服務器響應數據給客戶端。直接刪掉這條語句,替換成大牛寫的如下代碼。這里的代碼我并沒有做什么改動,里面的注釋也解釋的給非常清楚,直接按邏輯看懂就行,問題不大。
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//當鏈接地址為公眾號歷史消息頁面時(第一種頁面形式)
//console.log("開始第一種頁面爬取");
if(serverResData.toString() !== ""){
6 try {//防止報錯退出程序
var reg = /msgList = (.*?);/;//定義歷史消息正則匹配規則
var ret = reg.exec(serverResData.toString());//轉換變量為string
HttpPost(ret[1],req.url,"/InternetSpider/getData/showBiz");//這個函數是后文定義的,將匹配到的歷史消息json發送到自己的服務器
var http = require('http');
http.get('http://xxx/getWxHis', function(res) {//這個地址是自己服務器上的一個程序,目的是為了獲取到下一個鏈接地址,將地址放在一個js腳本中,將頁面自動跳轉到下一頁。后文將介紹getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//將返回的代碼插入到歷史消息頁面中,并返回顯示出來
})
});
}catch(e){//如果上面的正則沒有匹配到,那么這個頁面內容可能是公眾號歷史消息頁面向下翻動的第二頁,因為歷史消息第一頁是html格式的,第二頁就是json格式的。
//console.log("開始第一種頁面爬取向下翻形式");
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//這個函數和上面的一樣是后文定義的,將第二頁歷史消息的json發送到自己的服務器
}
}catch(e){
console.log(e);//錯誤捕捉
}
callback(serverResData);//直接返回第二頁json內容
}
}
//console.log("開始第一種頁面爬取 結束");
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//當鏈接地址為公眾號歷史消息頁面時(第二種頁面形式)
try {
var reg = /var msgList = \'(.*?)\';/;//定義歷史消息正則匹配規則(和第一種頁面形式的正則不同)
var ret = reg.exec(serverResData.toString());//轉換變量為string
HttpPost(ret[1],req.url,"/xxx/showBiz");//這個函數是后文定義的,將匹配到的歷史消息json發送到自己的服務器
var http = require('http');
http.get('xxx/getWxHis', function(res) {//這個地址是自己服務器上的一個程序,目的是為了獲取到下一個鏈接地址,將地址放在一個js腳本中,將頁面自動跳轉到下一頁。后文將介紹getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//將返回的代碼插入到歷史消息頁面中,并返回顯示出來
})
});
}catch(e){
//console.log(e);
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二種頁面表現形式的向下翻頁后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//這個函數和上面的一樣是后文定義的,將第二頁歷史消息的json發送到自己的服務器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//當鏈接地址為公眾號文章閱讀量和點贊量時
try {
HttpPost(serverResData,req.url,"/xxx/getMsgExt");//函數是后文定義的,功能是將文章閱讀量點贊量的json發送到服務器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//當鏈接地址為公眾號文章時(rumor這個地址是公眾號文章被辟謠了)
try {
var http = require('http');
http.get('http://xxx/getWxPost', function(res) {//這個地址是自己服務器上的另一個程序,目的是為了獲取到下一個鏈接地址,將地址放在一個js腳本中,將頁面自動跳轉到下一頁。后文將介紹getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
//callback(serverResData);
},這里簡單解釋一下,微信公眾號的歷史消息頁鏈接有兩種形式:一種以 mp.weixin.qq.com/mp/getmasssendmsg 開頭,另一種是 mp.weixin.qq.com/mp/profile_ext 開頭。歷史頁是可以向下翻的,如果向下翻將觸發js事件發送請求得到json數據(下一頁內容)。還有公眾號文章鏈接,以及文章的閱讀量和點贊量的鏈接(返回的是json數據),這幾種鏈接的形式是固定的可以通過邏輯判斷來區分。這里有個問題就是歷史頁如果需要全部爬取到該怎么做到。我的思路是通過js去模擬鼠標向下滑動,從而觸發提交加載下一部分列表的請求。或者直接利用anyproxy分析下滑加載的請求,直接向微信服務器發生這個請求。但都有一個問題就是如何判斷已經沒有余下數據了。我是爬取最新數據,暫時沒這個需求,可能以后要。如果有需求的可以嘗試一下。
下圖是上文中的HttpPost方法內容。
function HttpPost(str,url,path) {//將json發送到服務器,str為json內容,url為歷史消息頁面地址,path是接收程序的路徑和文件名
console.log("開始執行轉發操作");
try{
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
data = require('querystring').stringify(data);
var options = {
method: "POST",
host: "xxx",//注意沒有http://,這是服務器的域名。
port: xxx,
path: path,//接收程序的路徑和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": data.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(data);
req.end();
}catch(e){
console.log("錯誤信息:"+e);
}
console.log("轉發操作結束");
}做完以上工作,接下來就是按自己業務來完成服務端代碼了,我們的服務用于接收代理服務器發過來的數據進行處理,進行持久化操作,同時向代理服務器發送需要注入到微信的js代碼。針對代理服務器攔截到的幾種不同鏈接發來的數據,我們就需要設計相應的方法來處理這些數據。從anyproxy處理微信數據的js方法replaceServerResDataAsync: function(req,res,serverResData,callback)中,我們可以知道至少需要對公眾號歷史頁數據、公眾號文章頁數據、公眾號文章點贊量和閱讀量數據設計三種方法來處理。同時我們還需要設計一個方法來生成爬取任務,完成公眾號的輪尋爬取。如果需要爬取更多數據,可以從anyproxy抓取到的鏈接中分析出更多需要的數據,然后往replaceServerResDataAsync: function(req,res,serverResData,callback)中添加判定,攔截到需要的數據發送到自己的服務器,相應的在服務端添加方法處理該類數據就行了。
我是用java寫的服務端代碼。
處理公眾號歷史頁數據方法:
public void getMsgJson(String str ,String url) throws UnsupportedEncodingException {
// TODO Auto-generated method stub
String biz = "";
Map<String,String> queryStrs = HttpUrlParser.parseUrl(url);
if(queryStrs != null){
biz = queryStrs.get("__biz");
biz = biz + "==";
}
/**
* 從數據庫中查詢biz是否已經存在,如果不存在則插入,
* 這代表著我們新添加了一個采集目標公眾號。
*/
List<WeiXin> results = weiXinMapper.selectByBiz(biz);
if(results == null || results.size() == 0){
WeiXin weiXin = new WeiXin();
weiXin.setBiz(biz);
weiXin.setCollect(System.currentTimeMillis());
weiXinMapper.insert(weiXin);
}
//System.out.println(str);
//解析str變量
List<Object> lists = JsonPath.read(str, "['list']");
for(Object list : lists){
Object json = list;
int type = JsonPath.read(json, "['comm_msg_info']['type']");
if(type == 49){//type=49表示是圖文消息
String content_url = JsonPath.read(json, "$.app_msg_ext_info.content_url");
content_url = content_url.replace("\\", "").replaceAll("amp;", "");//獲得圖文消息的鏈接地址
int is_multi = JsonPath.read(json, "$.app_msg_ext_info.is_multi");//是否是多圖文消息
Integer datetime = JsonPath.read(json, "$.comm_msg_info.datetime");//圖文消息發送時間
/**
* 在這里將圖文消息鏈接地址插入到采集隊列庫tmplist中
* (隊列庫將在后文介紹,主要目的是建立一個批量采集隊列,
* 另一個程序將根據隊列安排下一個采集的公眾號或者文章內容)
*/
try{
if(content_url != null && !"".equals(content_url)){
TmpList tmpList = new TmpList();
tmpList.setContentUrl(content_url);
tmpListMapper.insertSelective(tmpList);
}
}catch(Exception e){
System.out.println("隊列已存在,不插入!");
}
/**
* 在這里根據$content_url從數據庫post中判斷一下是否重復
*/
List<Post> postList = postMapper.selectByContentUrl(content_url);
boolean contentUrlExist = false;
if(postList != null && postList.size() != 0){
contentUrlExist = true;
}
if(!contentUrlExist){//'數據庫post中不存在相同的$content_url'
Integer fileid = JsonPath.read(json, "$.app_msg_ext_info.fileid");//一個微信給的id
String title = JsonPath.read(json, "$.app_msg_ext_info.title");//文章標題
String title_encode = URLEncoder.encode(title, "utf-8");
String digest = JsonPath.read(json, "$.app_msg_ext_info.digest");//文章摘要
String source_url = JsonPath.read(json, "$.app_msg_ext_info.source_url");//閱讀原文的鏈接
source_url = source_url.replace("\\", "");
String cover = JsonPath.read(json, "$.app_msg_ext_info.cover");//封面圖片
cover = cover.replace("\\", "");
/**
* 存入數據庫
*/
// System.out.println("頭條標題:"+title);
// System.out.println("微信ID:"+fileid);
// System.out.println("文章摘要:"+digest);
// System.out.println("閱讀原文鏈接:"+source_url);
// System.out.println("封面圖片地址:"+cover);
Post post = new Post();
post.setBiz(biz);
post.setTitle(title);
post.setTitleEncode(title_encode);
post.setFieldId(fileid);
post.setDigest(digest);
post.setSourceUrl(source_url);
post.setCover(cover);
post.setIsTop(1);//標記一下是頭條內容
post.setIsMulti(is_multi);
post.setDatetime(datetime);
post.setContentUrl(content_url);
postMapper.insert(post);
}
if(is_multi == 1){//如果是多圖文消息
List<Object> multiLists = JsonPath.read(json, "['app_msg_ext_info']['multi_app_msg_item_list']");
for(Object multiList : multiLists){
Object multiJson = multiList;
content_url = JsonPath.read(multiJson, "['content_url']").toString().replace("\\", "").replaceAll("amp;", "");//圖文消息鏈接地址
/**
* 這里再次根據$content_url判斷一下數據庫中是否重復以免出錯
*/
contentUrlExist = false;
List<Post> posts = postMapper.selectByContentUrl(content_url);
if(posts != null && posts.size() != 0){
contentUrlExist = true;
}
if(!contentUrlExist){//'數據庫中不存在相同的$content_url'
/**
* 在這里將圖文消息鏈接地址插入到采集隊列庫中
* (隊列庫將在后文介紹,主要目的是建立一個批量采集隊列,
* 另一個程序將根據隊列安排下一個采集的公眾號或者文章內容)
*/
if(content_url != null && !"".equals(content_url)){
TmpList tmpListT = new TmpList();
tmpListT.setContentUrl(content_url);
tmpListMapper.insertSelective(tmpListT);
}
String title = JsonPath.read(multiJson, "$.title");
String title_encode = URLEncoder.encode(title, "utf-8");
Integer fileid = JsonPath.read(multiJson, "$.fileid");
String digest = JsonPath.read(multiJson, "$.digest");
String source_url = JsonPath.read(multiJson, "$.source_url");
source_url = source_url.replace("\\", "");
String cover = JsonPath.read(multiJson, "$.cover");
cover = cover.replace("\\", "");
// System.out.println("標題:"+title);
// System.out.println("微信ID:"+fileid);
// System.out.println("文章摘要:"+digest);
// System.out.println("閱讀原文鏈接:"+source_url);
// System.out.println("封面圖片地址:"+cover);
Post post = new Post();
post.setBiz(biz);
post.setTitle(title);
post.setTitleEncode(title_encode);
post.setFieldId(fileid);
post.setDigest(digest);
post.setSourceUrl(source_url);
post.setCover(cover);
post.setIsTop(0);//標記一下不是頭條內容
post.setIsMulti(is_multi);
post.setDatetime(datetime);
post.setContentUrl(content_url);
postMapper.insert(post);
}
}
}
}
}
}處理公眾號文章頁的方法:
public String getWxPost() {
// TODO Auto-generated method stub
/**
* 當前頁面為公眾號文章頁面時,讀取這個程序
* 首先刪除采集隊列表中load=1的行
* 然后從隊列表中按照“order by id asc”選擇多行(注意這一行和上面的程序不一樣)
*/
tmpListMapper.deleteByLoad(1);
List<TmpList> queues = tmpListMapper.selectMany(5);
String url = "";
if(queues != null && queues.size() != 0 && queues.size() > 1){
TmpList queue = queues.get(0);
url = queue.getContentUrl();
queue.setIsload(1);
int result = tmpListMapper.updateByPrimaryKey(queue);
System.out.println("update result:"+result);
}else{
System.out.println("getpost queues is null?"+queues==null?null:queues.size());
WeiXin weiXin = weiXinMapper.selectOne();
String biz = weiXin.getBiz();
if((Math.random()>0.5?1:0) == 1){
url = "http://mp.weixin.qq.com/mp/getmasssendmsg?__biz=" + biz +
"#wechat_webview_type=1&wechat_redirect";//拼接公眾號歷史消息url地址(第一種頁面形式)
}else{
url = "https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=" + biz +
"#wechat_redirect";//拼接公眾號歷史消息url地址(第二種頁面形式)
}
url = "https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=" + biz +
"#wechat_redirect";//拼接公眾號歷史消息url地址(第二種頁面形式)
//更新剛才提到的公眾號表中的采集時間time字段為當前時間戳。
weiXin.setCollect(System.currentTimeMillis());
int result = weiXinMapper.updateByPrimaryKey(weiXin);
System.out.println("getPost weiXin updateResult:"+result);
}
int randomTime = new Random().nextInt(3) + 3;
String jsCode = "<script>setTimeout(function(){window.location.href='"+url+"';},"+randomTime*1000+");</script>";
return jsCode;
}處理公眾號點贊量和閱讀量的方法:
public void getMsgExt(String str,String url) {
// TODO Auto-generated method stub
String biz = "";
String sn = "";
Map<String,String> queryStrs = HttpUrlParser.parseUrl(url);
if(queryStrs != null){
biz = queryStrs.get("__biz");
biz = biz + "==";
sn = queryStrs.get("sn");
sn = "%" + sn + "%";
}
/**
* $sql = "select * from `文章表` where `biz`='".$biz."'
* and `content_url` like '%".$sn."%'" limit 0,1;
* 根據biz和sn找到對應的文章
*/
Post post = postMapper.selectByBizAndSn(biz, sn);
if(post == null){
System.out.println("biz:"+biz);
System.out.println("sn:"+sn);
tmpListMapper.deleteByLoad(1);
return;
}
// System.out.println("json數據:"+str);
Integer read_num;
Integer like_num;
try{
read_num = JsonPath.read(str, "['appmsgstat']['read_num']");//閱讀量
like_num = JsonPath.read(str, "['appmsgstat']['like_num']");//點贊量
}catch(Exception e){
read_num = 123;//閱讀量
like_num = 321;//點贊量
System.out.println("read_num:"+read_num);
System.out.println("like_num:"+like_num);
System.out.println(e.getMessage());
}
/**
* 在這里同樣根據sn在采集隊列表中刪除對應的文章,代表這篇文章可以移出采集隊列了
* $sql = "delete from `隊列表` where `content_url` like '%".$sn."%'"
*/
tmpListMapper.deleteBySn(sn);
//然后將閱讀量和點贊量更新到文章表中。
post.setReadnum(read_num);
post.setLikenum(like_num);
postMapper.updateByPrimaryKey(post);
}處理跳轉向微信注入js的方法:
public String getWxHis() {
String url = "";
// TODO Auto-generated method stub
/**
* 當前頁面為公眾號歷史消息時,讀取這個程序
* 在采集隊列表中有一個load字段,當值等于1時代表正在被讀取
* 首先刪除采集隊列表中load=1的行
* 然后從隊列表中任意select一行
*/
tmpListMapper.deleteByLoad(1);
TmpList queue = tmpListMapper.selectRandomOne();
System.out.println("queue is null?"+queue);
if(queue == null){//隊列表為空
/**
* 隊列表如果空了,就從存儲公眾號biz的表中取得一個biz,
* 這里我在公眾號表中設置了一個采集時間的time字段,按照正序排列之后,
* 就得到時間戳最小的一個公眾號記錄,并取得它的biz
*/
WeiXin weiXin = weiXinMapper.selectOne();
String biz = weiXin.getBiz();
url = "https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=" + biz +
"#wechat_redirect";//拼接公眾號歷史消息url地址(第二種頁面形式)
//更新剛才提到的公眾號表中的采集時間time字段為當前時間戳。
weiXin.setCollect(System.currentTimeMillis());
int result = weiXinMapper.updateByPrimaryKey(weiXin);
System.out.println("getHis weiXin updateResult:"+result);
}else{
//取得當前這一行的content_url字段
url = queue.getContentUrl();
//將load字段update為1
tmpListMapper.updateByContentUrl(url);
}
//將下一個將要跳轉的$url變成js腳本,由anyproxy注入到微信頁面中。
//echo "<script>setTimeout(function(){window.location.href='".$url."';},2000);</script>";
int randomTime = new Random().nextInt(3) + 3;
String jsCode = "<script>setTimeout(function(){window.location.href='"+url+"';},"+randomTime*1000+");</script>";
return jsCode;
}以上就是對處理代理服務器攔截到的數據進行處理的程序。這里有一個需要注意的問題,程序會對數據庫中的每個收錄的公眾號進行輪循訪問,甚至是已經存儲的文章也會再次訪問,目的是為了一直更新文章的閱讀數和點贊數。如果需要抓取大量的公眾號建議對添加任務隊列的代碼進行修改,添加條件限制,否則公眾號一多 輪循抓取重復數據將十分影響效率。
至此就將微信公眾號的文章鏈接全部爬取到,而且這個鏈接是永久有效而且可以在瀏覽器打開的鏈接,接下來就是寫爬蟲程序從數據庫中拿鏈接爬取文章內容等信息了。
我是用webmagic寫的爬蟲,輕量好用。
public class SpiderModel implements PageProcessor{
private static PostMapper postMapper;
private static List<Post> posts;
// 抓取網站的相關配置,包括編碼、抓取間隔、重試次數等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public Site getSite() {
// TODO Auto-generated method stub
return this.site;
}
public void process(Page page) {
// TODO Auto-generated method stub
Post post = posts.remove(0);
String content = page.getHtml().xpath("//div[@id='js_content']").get();
//存在和諧文章 此處做判定如果有直接刪除記錄或設置表示位表示文章被和諧
if(content == null){
System.out.println("文章已和諧!");
//postMapper.deleteByPrimaryKey(post.getId());
return;
}
String contentSnap = content.replaceAll("data-src", "src").replaceAll("preview.html", "player.html");//快照
String contentTxt = HtmlToWord.stripHtml(content);//純文本內容
Selectable metaContent = page.getHtml().xpath("//div[@id='meta_content']");
String pubTime = null;
String wxname = null;
String author = null;
if(metaContent != null){
pubTime = metaContent.xpath("//em[@id='post-date']").get();
if(pubTime != null){
pubTime = HtmlToWord.stripHtml(pubTime);//文章發布時間
}
wxname = metaContent.xpath("//a[@id='post-user']").get();
if(wxname != null){
wxname = HtmlToWord.stripHtml(wxname);//公眾號名稱
}
author = metaContent.xpath("//em[@class='rich_media_meta rich_media_meta_text' and @id!='post-date']").get();
if(author != null){
author = HtmlToWord.stripHtml(author);//文章作者
}
}
// System.out.println("發布時間:"+pubTime);
// System.out.println("公眾號名稱:"+wxname);
// System.out.println("文章作者:"+author);
String title = post.getTitle().replaceAll(" ", "");//文章標題
String digest = post.getDigest();//文章摘要
int likeNum = post.getLikenum();//文章點贊數
int readNum = post.getReadnum();//文章閱讀數
String contentUrl = post.getContentUrl();//文章鏈接
WechatInfoBean wechatBean = new WechatInfoBean();
wechatBean.setTitle(title);
wechatBean.setContent(contentTxt);//純文本內容
wechatBean.setSourceCode(contentSnap);//快照
wechatBean.setLikeCount(likeNum);
wechatBean.setViewCount(readNum);
wechatBean.setAbstractText(digest);//摘要
wechatBean.setUrl(contentUrl);
wechatBean.setPublishTime(pubTime);
wechatBean.setSiteName(wxname);//站點名稱 公眾號名稱
wechatBean.setAuthor(author);
wechatBean.setMediaType("微信公眾號");//來源媒體類型
WechatStorage.saveWechatInfo(wechatBean);
//標示文章已經被爬取
post.setIsSpider(1);
postMapper.updateByPrimaryKey(post);
}
public static void startSpider(List<Post> inposts,PostMapper myPostMapper,String... urls){
long startTime, endTime;
startTime = System.currentTimeMillis();
postMapper = myPostMapper;
posts = inposts;
HttpClientDownloader httpClientDownloader = new HttpClientDownloader();
SpiderModel spiderModel = new SpiderModel();
Spider mySpider = Spider.create(spiderModel).addUrl(urls);
mySpider.setDownloader(httpClientDownloader);
try {
SpiderMonitor.instance().register(mySpider);
mySpider.thread(1).run();
} catch (JMException e) {
e.printStackTrace();
}
endTime = System.currentTimeMillis();
System.out.println("爬取時間" + ((endTime - startTime) / 1000) + "秒--");
}
}其它的一些無關邏輯的存儲數據代碼就不貼了,這里我把代理服務器抓取到的數據存在了mysql,把自己的爬蟲程序爬到的數據存儲在了mongodb。
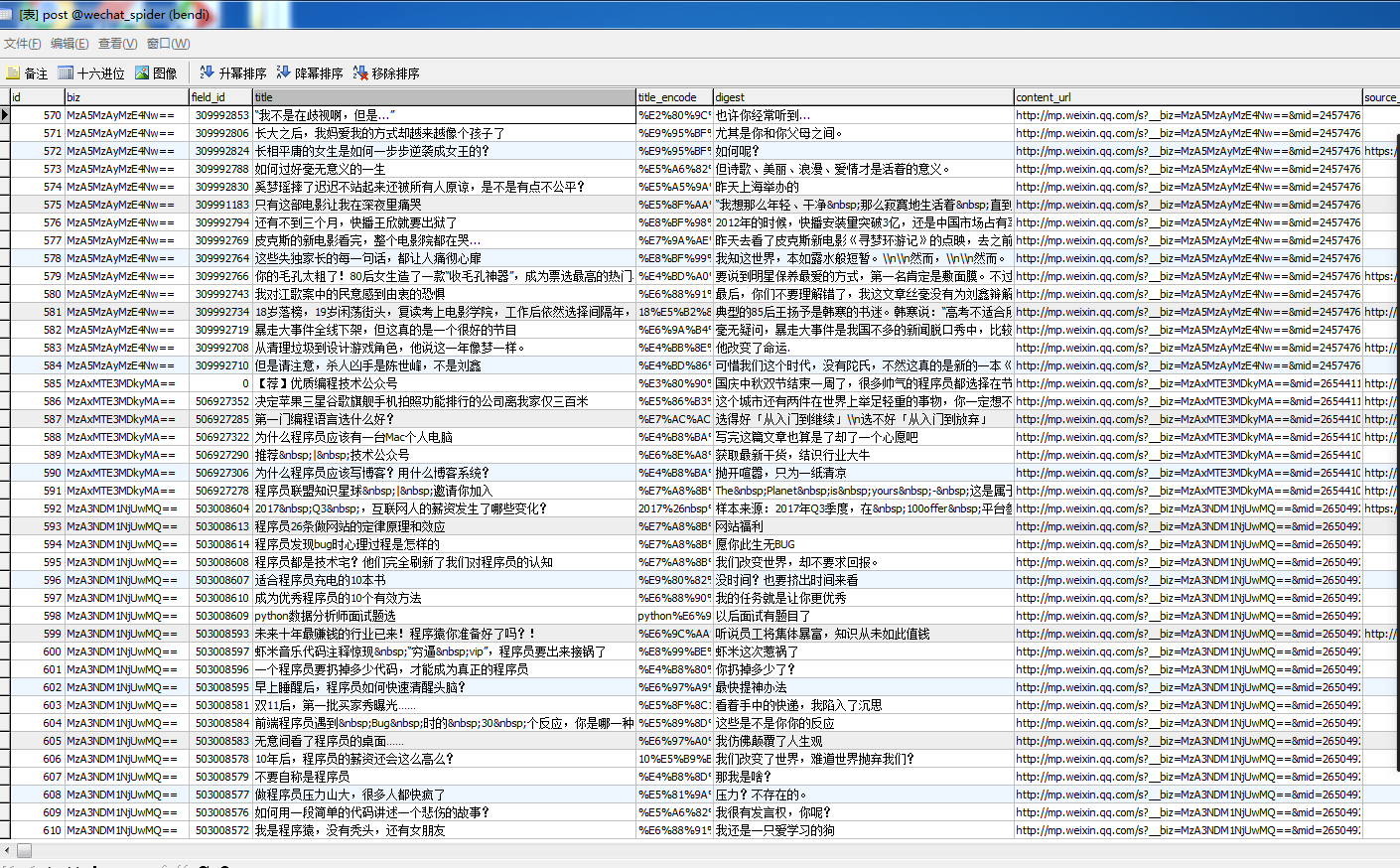
下面是自己爬取到的公眾號號的信息:
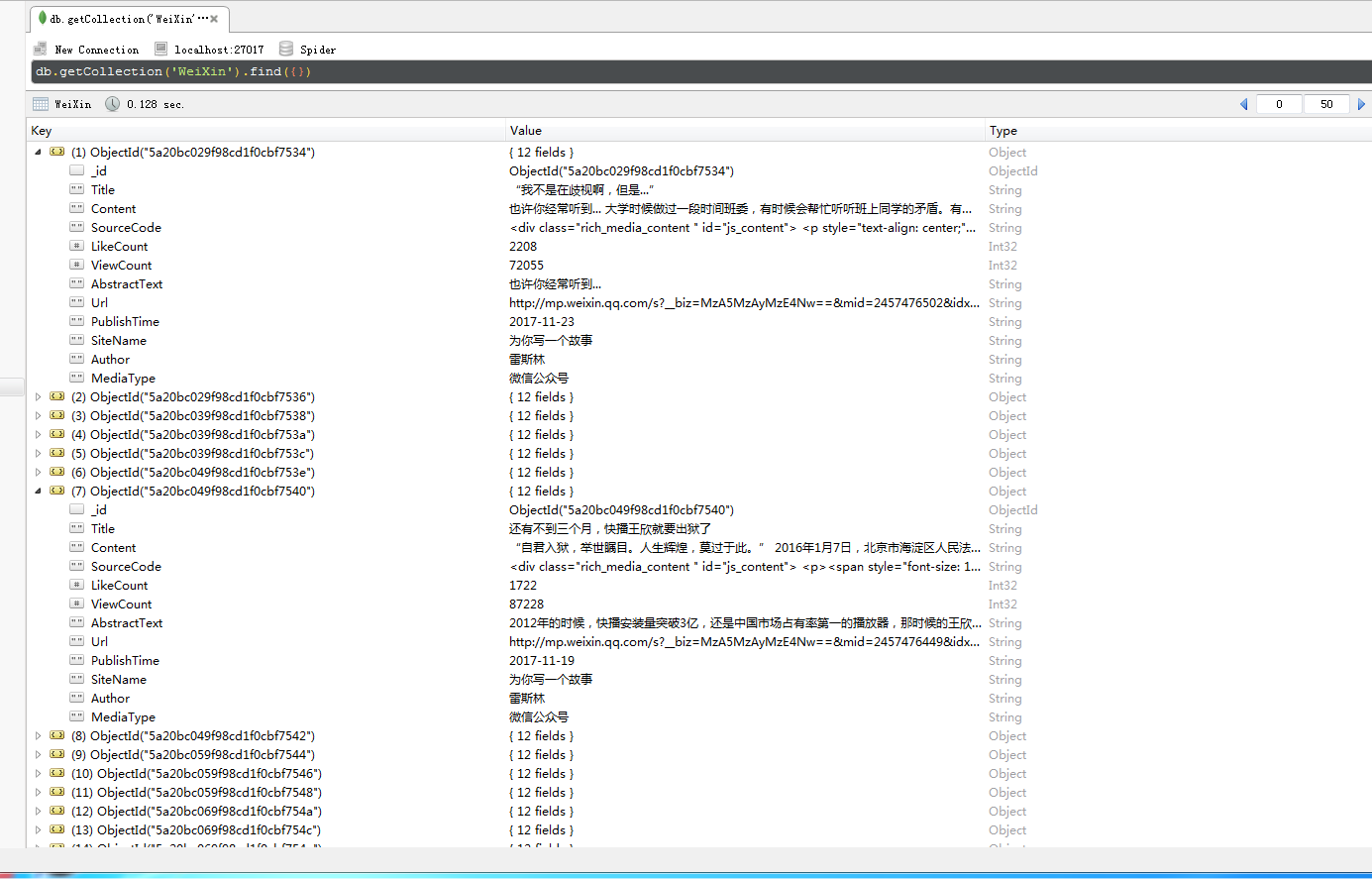
看完上述內容,你們對使用Java怎么對微信公眾號批量獲取有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





