溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
起因
最近遇到一個問題,把某個字符串計算MD5,之后把該字符串加密與MD5一起上傳到服務端,服務端解密后重新計算md5發現與上傳的MD5不一致,而出問題的字符串中無一例外都有Emoji表情。但我自己弄個帶表情的字符串上傳卻沒有什么問題。
最終確認這是在Android 5.1以下 jstring -> char數組 時出的問題。下面通過一個示例來還原這個過程。
事件還原
假設有一個字符串s,String s = "\uD83D\uDC8B"; ,對應表情💋。通過調用getBytes()方法,會看到對應的byte數組為[-16, -97, -110, -117] ,按16進制輸出為[f0, 9f, 92, 8b] 。
定義一個參數為String的native方法,public native String test(String str); ,在對應的C/C++代碼中,通過env->GetStringUTFChars獲取傳入的String對應的char數組,把char數組的每一個元素按16進制輸出。
在Android 7.1.2的測試機上,native層輸出的結果為[f0, 9f, 92, 8b] ,與Java的byte數組是一樣的,但是在Android 4.4.4的測試機上,輸出結果為[ed, a0, bd, ed, b2, 8b] 。從而導致加密后的結果不一樣。
服務端收到舊版Android的數據解密后得到[ed, a0, bd, ed, b2, 8b] ,計算MD5自然無法與[f0, 9f, 92, 8b]計算MD5一樣。
Unicode、UTF-8、UTF-16
可能有人不是很清楚上面那2種byte數組是怎么來的。首先我們要知道,UTF-8和UTF-16都是Unicode的實現。\uD83D\uDC8B其實是UTF-16大端的表現形式,對于大于0xFFFF(0x10000~0x10FFFF)的Unicode,轉換為UTF-16的步驟如下:
按照這個步驟反推:
所以,表情💋對應的Unicode為0x1F48B。
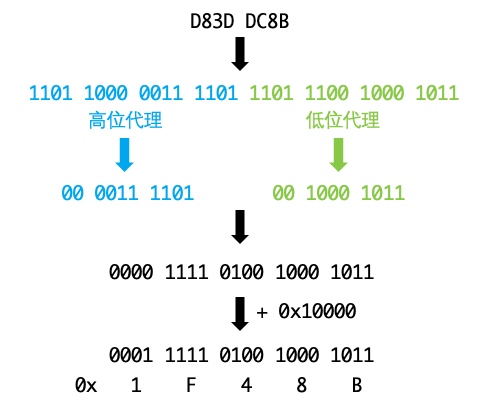
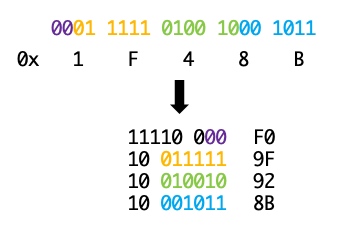
UTF-8的規則是,對于占N個字節的符號(N>1),第一個字節前N位都是1,N+1位是0,后面的字節前2位為10,然后把Unicode的二進制位填入空缺的二進制位中,空出的位置補0。因此,上面的Unicode 0x1F48B轉為UTF-8需要占4個字節,為:
11110 000
10 011111
10 010010
10 001011
即0xF09F928B,這也就是[f0, 9f, 92, 8b]這個byte數組的由來。
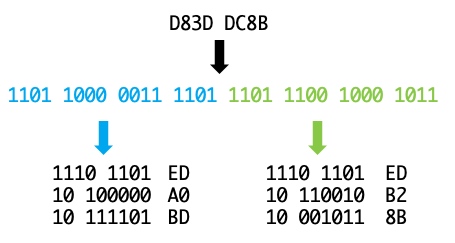
那么[ed, a0, bd, ed, b2, 8b]這個byte數組又是怎么來的呢?這是把\uD83D\uDC8B當成2個單獨的字符處理了,按照上面Unicode轉UTF-8的邏輯,Unicode 0xD83D轉為UTF-8為1110 1101 10 100000 10 111101,即0xEDA0BD,Unicode 0xDC8B轉為UTF-8為1110 1101 10 110010 10 001011,即0xEDB28B。
總結
以上就是這篇文章的全部內容了,希望本文的內容對大家的學習或者工作具有一定的參考學習價值,謝謝大家對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





