溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
一、故障描述
北京一家醫院的EMC FC AX-4存儲崩潰、raid癱瘓。北亞數據恢復中心接到客戶電話后第一時間安排工程師攜帶服務器趕赴用戶現場。經過工程師初檢發現存儲空間由1TB STAT的硬盤共12塊組成raid5,其中兩塊是熱備盤,目前設備中有兩塊硬盤損壞但只有一塊熱備盤激活成功,因此此raid5陣列癱瘓、上層lun無法正常使用。先對所以磁盤進行物理檢測沒有發現物理故障,后使用壞道檢測工具進行壞道檢測也沒有壞道存在。</br>
</br>
二、備份數據
由于數據恢復工作的特殊性,在數據恢復之前必須對所有原始數據進行備份,在本次raid5數據恢復中我們使用winhex把全部磁盤鏡像成文件,由于源磁盤的扇區大小是520字節,所以還需要使用特殊工具把所有備份的數據再做520 to 512字節的轉換。
</br>
三、故障分析及恢復過程
1、分析故障原因。由于設備中并不存在物理故障和壞道,由此推斷故障原因是部分磁盤讀寫不穩定導致的,因為EMC控制器有著非常嚴格的檢查磁盤策略,如果發生磁盤性能不穩定的情況就會被EMC控制器認定為壞盤踢出raid組,當raid組中掉線盤達到raid級別的允許掉盤極限,此raid組即不可用,基于此raid的上層lun不可用。在本案例中只有一個lun分配給sun小機,上層文件系統是ZFS。</br>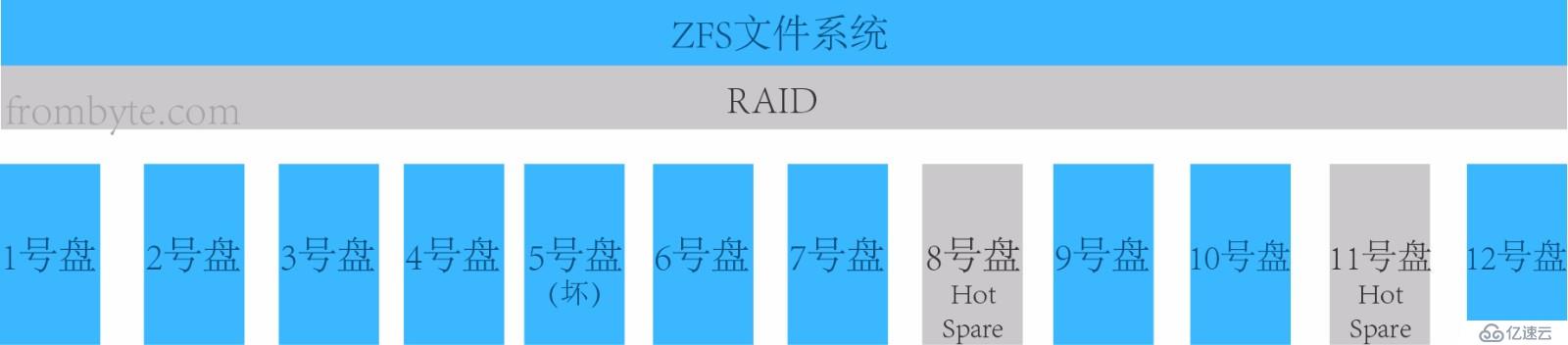
</br>
2、分析RAID組結構。EMC存儲的LUN都是基于RAID組的,因此需要先分析底層RAID組的信息,然后根據分析的信息重構原始的RAID組。通過對所有硬盤數據分析發現8號盤和11號盤完全沒有數據,從管理界面上可以看到8號盤和11號盤都屬于Hot Spare,但8號盤的Hot Spare替換了5號盤的壞盤。因此可以判斷雖然8號盤的Hot Spare雖然成功激活,但由于RAID級別為RAID5,此時RAID組中還缺失一塊硬盤,所以導致數據沒有同步到8號硬盤中(frombyte.com)。繼續分析其他10塊硬盤,分析數據在硬盤中分布的規律,RAID條帶的大小,以及每塊磁盤的順序。
</br>
3、分析RAID組掉線盤。根據上述分析的RAID信息,嘗試通過北亞自主開發的RAID虛擬程序將原始的RAID組虛擬出來。但由于整個RAID組中一共掉線兩塊盤,因此需要分析這兩塊硬盤掉線的順序。仔細分析每一塊硬盤中的數據,發現有一塊硬盤在同一個條帶上的數據和其他硬盤明顯不一樣,因此初步判斷此硬盤可能是最先掉線的,通過北亞自主開發的RAID校驗程序對這個條帶做校驗,發現除掉剛才分析的那塊硬盤得出的數據是最好的,因此可以明確最先掉線的硬盤了。
</br>
4、分析RAID組中的LUN信息。由于LUN是基于RAID組的,因此需要根據上述分析的信息將RAID組重組出來。然后分析LUN在RAID組中的分配信息,以及LUN分配的數據塊MAP。由于底層只有一個LUN,因此只需要分析一份LUN信息就OK了。然后根據這些信息使用北亞raid恢復(frombyte.com)程序,解釋LUN的數據MAP并導出LUN的所有數據。
</br>
四、解釋ZFS文件系統并修復
1、解釋ZFS文件系統。利用北亞數據恢復自主開發的ZFS文件系統解釋程序對生成的LUN做文件系統解釋,發現程序在解釋某些文件系統元文件的時候報錯。于是安排開發工程師對程序做debug調試并分析程序報錯原因。接著安排文件系統工程師分析ZFS文件系統是否因為版本原因,導致程序不支持。經過長達7小時的分析與調試,發現ZFS文件系統因存儲突然癱瘓導致其中某些元文件損壞,從而導致解釋ZFS文件系統的程序無法正常解釋。
</br>
2、修復ZFS文件系統。以上分析明確了ZFS文件系統因存儲癱瘓導致部分文件系統元文件損壞,因此需要對這些損壞的文件系統元文件做修復才能正常解析ZFS文件系統。分析損壞的元文件發現,因當初ZFS文件正在進行IO操作的同時存儲癱瘓,導致部分文件系統元文件沒有更新以及損壞。人工對這些損壞的元文件進行手工修復,保證ZFS文件系統能夠正常解析。
</br>
五、導出并驗證數據
利用程序對修復好的ZFS文件系統做解析,解析所有文件節點及目錄結構。由于數據都是文本類型及DCM圖片,需要搭建太多的環境。由用戶方工程師指點某些數據進行驗證,驗證結果都沒有問題,數據均完整。
</br>
六、數據恢復結論
由于故障發生后保存現場環境良好,沒用做相關危險的操作,對后期的數據恢復有很大的幫助。整個數據恢復過程中雖然遇到好多技術瓶頸,但也都一一解決。最終在預期的時間內完成整個數據恢復,恢復的數據用戶方也相當滿意。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





