溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Java的流體系十分龐大,我們來看看體系圖:
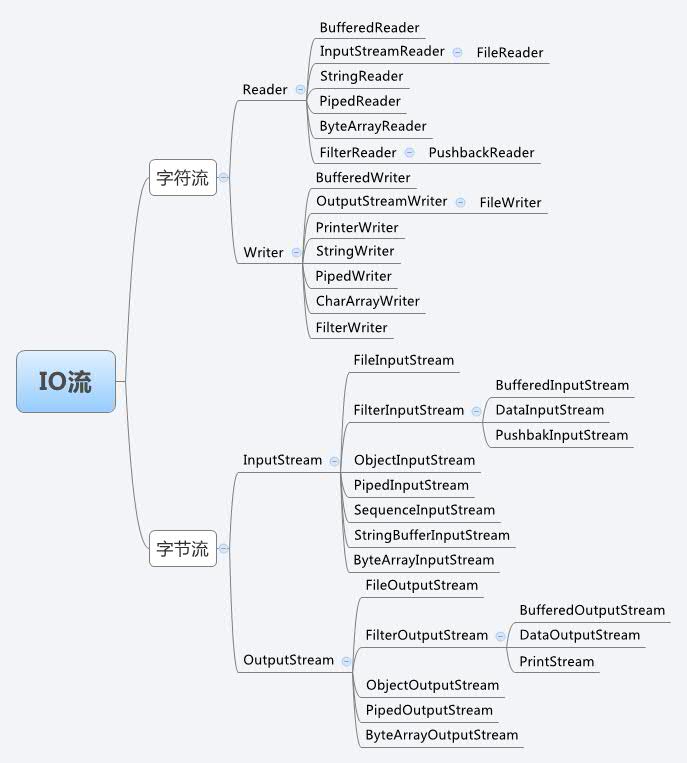
這么龐大的體系里面,常用的就那么幾個,我們把它們抽取出來,如下圖:

一:字節流
1:字節輸入流
字節輸入流的抽象基類是InputStream,常用的子類是 FileInputStream和BufferedInputStream。
1)FileInputStream
文件字節輸入流:一切文件在系統中都是以字節的形式保存的,無論你是文檔文件、視頻文件、音頻文件...,需要讀取這些文件都可以用FileInputStream去讀取其保存在存儲介質(磁盤等)上的字節序列。
FileInputStream在創建時通過把文件名作為構造參數連接到該文件的字節內容,建立起字節流傳輸通道。
然后通過 read()、read(byte[])、read(byte[],int begin,int len) 三種方法從字節流中讀取 一個字節、一組字節。
2)BufferedInputStream
帶緩沖的字節輸入流:上面我們知道文件字節輸入流的讀取時,是直接同字節流中讀取的。由于字節流是與硬件(存儲介質)進行的讀取,所以速度較慢。而CPU需要使用數據時通過read()、read(byte[])讀取數據時就要受到硬件IO的慢速度限制。我們又知道,CPU與內存發生的讀寫速度比硬件IO快10倍不止,所以優化讀寫的思路就有了:在內存中建立緩存區,先把存儲介質中的字節讀取到緩存區中。CPU需要數據時直接從緩沖區讀就行了,緩沖區要足夠大,在被讀完后又觸發fill()函數自動從存儲介質的文件字節內容中讀取字節存儲到緩沖區數組。
BufferedInputStream 內部有一個緩沖區,默認大小為8M,每次調用read方法的時候,它首先嘗試從緩沖區里讀取數據,若讀取失敗(緩沖區無可讀數據),則選擇從物理數據源 (譬如文件)讀取新數據(這里會嘗試盡可能讀取多的字節)放入到緩沖區中,最后再將緩沖區中的內容返回給用戶.由于從緩沖區里讀取數據遠比直接從存儲介質讀取速度快,所以BufferedInputStream的效率很高。
public class OutputStreamWriter extends Writer {
// 流編碼類,所有操作都交給它完成。
private final StreamEncoder se;
// 創建使用指定字符的OutputStreamWriter。
public OutputStreamWriter(OutputStream out, String charsetName)
throws UnsupportedEncodingException
{
super(out);
if (charsetName == null)
throw new NullPointerException("charsetName");
se = StreamEncoder.forOutputStreamWriter(out, this, charsetName);
}
// 創建使用默認字符的OutputStreamWriter。
public OutputStreamWriter(OutputStream out) {
super(out);
try {
se = StreamEncoder.forOutputStreamWriter(out, this, (String)null);
}
catch (UnsupportedEncodingException e) {
throw new Error(e);
}
}
// 創建使用指定字符集的OutputStreamWriter。
public OutputStreamWriter(OutputStream out, Charset cs) {
super(out);
if (cs == null)
throw new NullPointerException("charset");
se = StreamEncoder.forOutputStreamWriter(out, this, cs);
}
// 創建使用指定字符集編碼器的OutputStreamWriter。
public OutputStreamWriter(OutputStream out, CharsetEncoder enc) {
super(out);
if (enc == null)
throw new NullPointerException("charset encoder");
se = StreamEncoder.forOutputStreamWriter(out, this, enc);
}
// 返回該流使用的字符編碼名。如果流已經關閉,則此方法可能返回 null。
public String getEncoding() {
return se.getEncoding();
}
// 刷新輸出緩沖區到底層字節流,而不刷新字節流本身。該方法可以被PrintStream調用。
void flushBuffer() throws IOException {
se.flushBuffer();
}
// 寫入單個字符
public void write(int c) throws IOException {
se.write(c);
}
// 寫入字符數組的一部分
public void write(char cbuf[], int off, int len) throws IOException {
se.write(cbuf, off, len);
}
// 寫入字符串的一部分
public void write(String str, int off, int len) throws IOException {
se.write(str, off, len);
}
// 刷新該流。可以發現,刷新緩沖區其實是通過流編碼類的flush()實現的,故可以看出,緩沖區是流編碼類自帶的而不是OutputStreamWriter實現的。
public void flush() throws IOException {
se.flush();
}
// 關閉該流。
public void close() throws IOException {
se.close();
}
}
每次調用 write() 方法都會導致在給定字符(或字符集)上調用編碼轉換器。在寫入底層輸出流之前,得到的這些字節將在緩沖區中累積(傳遞給 write() 方法的字符沒有緩沖,輸出數組才有緩沖)。為了獲得最高效率,可考慮將 OutputStreamWriter 包裝到 BufferedWriter 中,以避免頻繁調用轉換器。
2)BufferedWriter
帶緩沖的字符輸出流:與OutputStreamWriter的緩沖不同,BufferedWriter的緩沖是真正由自己創建的緩沖數組來實現的。故此:不需要頻繁調用編碼轉換器進行緩沖,而且,它可以提供單個字符、數組和字符串的緩沖(編碼轉換器只能緩沖字符數組和字符串)。
BufferedWriter可以在創建時把一個OutputStreamWriter進行包裝,為輸出流建立緩沖;
然后,通過
void write(char[] cbuf, int off, int len)
寫入字符數組的某一部分。
void write(int c)
寫入單個字符。
void write(String s, int off, int len)
寫入字符串的某一部分。
向緩沖區寫入數據。
還可以通過
void newLine()
寫入一個行分隔符。
最后,可以手動控制緩沖區的數據刷新:
void flush() 刷新該流的緩沖。
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





