溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
一、故障描述
機房突然斷電導致整個存儲癱瘓,加電后存儲依然無法使用。經過用戶方工程師診斷后認為是斷電導致存儲陣列損壞。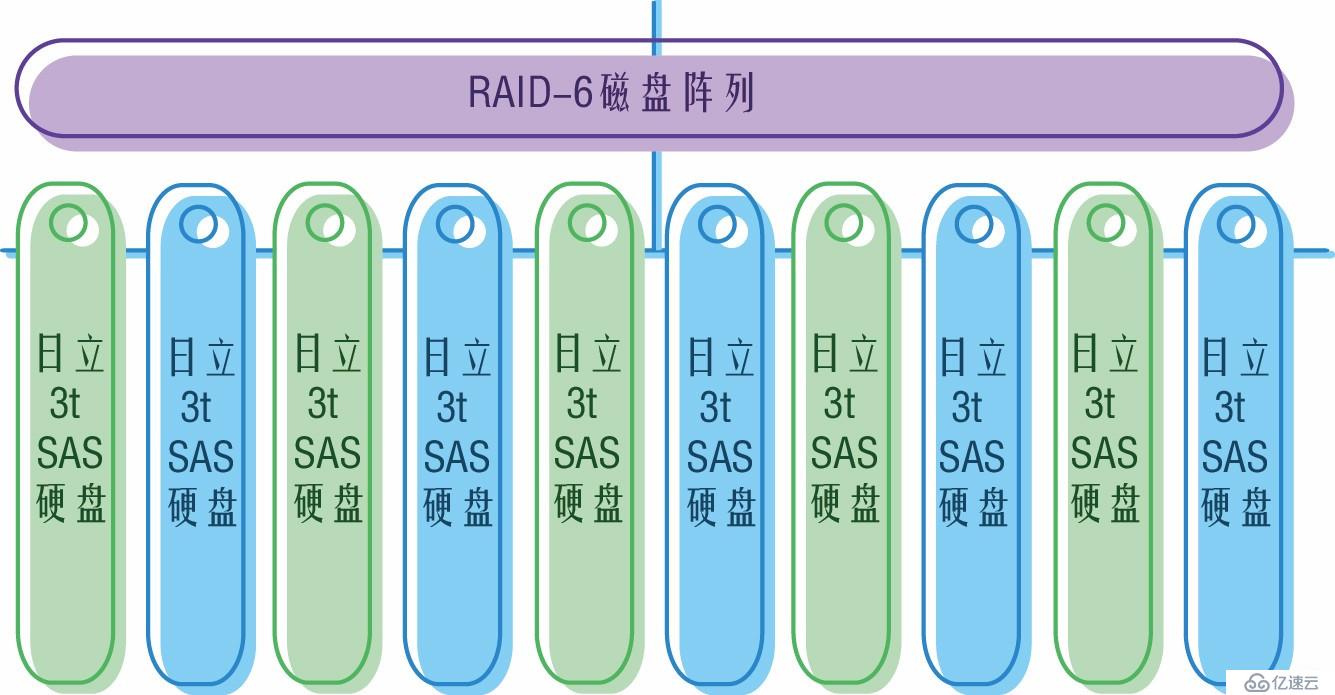
整個存儲是由12塊日立硬盤(3T SAS硬盤)組成的RAID-6磁盤陣列,被分成一個卷,分配給幾臺Vmware的ESXI主機做共享存儲。整個卷中存放了大量的Windows虛擬機,虛擬機基本都是模板創建的,因此系統盤都統一為160G。數據盤大小不確定,并且數據盤都是精簡模式。
二、備份數據
將故障存儲的所有磁盤和備份sss數據的目標磁盤連入到一臺Windows Server 2008的服務器上。故障磁盤都設為脫機(只讀)狀態,在專業工具WinHex下看到連接狀態如下圖所示:(圖中HD1-HD12為目標備份磁盤,HD13-HD24為源故障磁盤,型號為HUS723030ALS640):
圖一: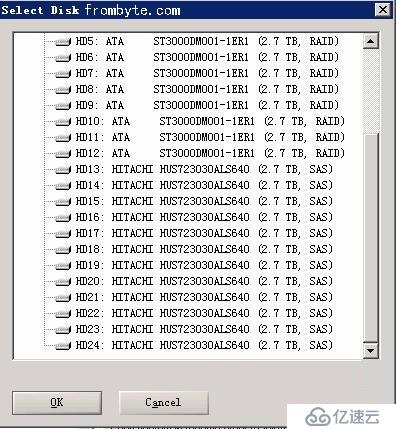
使用WinHex 對HD13-HD24以底層方式讀取扇區,發現了大量損壞扇區。初步判斷可能是這種硬盤的讀取機制與常見的硬盤不一樣。嘗試更換操作主機,更換HBA卡,更換擴展柜,更換為Linux操作系統,均呈現相同故障。與用戶方工程師聯系,對方回應此控制器對磁盤沒有特殊要求。
使用專業工具對硬盤損壞扇區的分布規律進行檢測,發現如下規則:
1、損壞扇區分布以256個扇區為單位。
2、除損壞扇區片斷的起始位置不固定外,后面的損壞扇區都是以2816個扇區為間隔。
所有磁盤的損壞扇區分布如下表(只列出前3個損壞扇區):
ID號 硬盤序列號 第1個損壞扇區 第2個損壞扇區 第3個損壞扇區
13 YHJ7L3DD 5376 8192 11008
14 YHJ6YW9D 2304 5120 7936
15 YHJ7M77D 2048 4864 7680
16 YHJ4M5AD 1792 4608 7424
17 YHJ4MERD 1536 4352 7168
18 YHJ4MH9D 1280 6912 9728
19 YHJ7JYYD 1024 6656 9472
20 YHJ4MHMD 768 6400 9216
21 YHJ7M4YD 512 6144 8960
22 YHJ632UD 256 5888 8704
23 YHJ6LEUD 5632 8448 11264
24 YHHLDLRA 256 5888 8704
臨時寫了個小程序,對每個磁盤的損壞扇區做繞過處理。用此程序鏡像完所有盤的數據。
三、故障分析
1、分析損壞扇區
仔細分析損壞扇區發現,損壞扇區呈規律性出現。
-每段損壞扇區區域大小總為256。
-損壞扇區分布為固定區域,每跳過11個256扇區遇到一個壞的256扇區。
-損壞扇區的位置一直存在于RAID的P校驗或Q校驗區域。
-所有硬盤中只有10號盤中有一個自然壞道。
2、分析分區大小
對HD13、HD23、HD24的0-2扇區做分析,可知分區大小為52735352798扇區,此大小按RAID-6的模式計算,除以9,等于5859483644扇區,與物理硬盤大小1049524,和DS800控制器中保留的RAID信息區域大小吻合;同時根據物理硬盤底層表現,分區表大小為512字節,后面無8字節校驗,大量的0扇區也無8字節校驗。故可知,原存儲并未啟用存儲中常用的DA技術(520字節扇區)。
分區大小如下圖(GPT分區表項底層表現,涂色部分表示分區大小,單位512字節扇區,64bit):
圖二: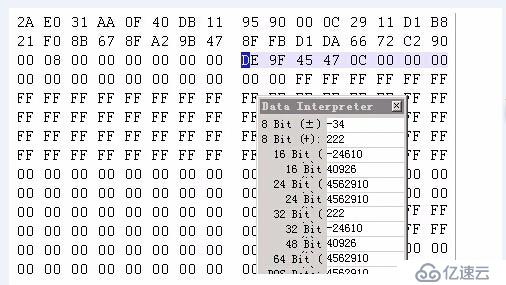
四、重組RAID
1、分析RAID結構
存儲使用的是標準的RAID-6陣列,接下來只需要分析出RAID 成員數量以及RAID的走向就可以重組RAID。
-分析RAID條帶大小
整個存儲被分成一個大的卷,分配給幾臺ESXI做共享存儲,因此卷的文件系統肯定是VMFS文件系統。而VMFS卷中又有存放了大量的Windows 虛擬機。Windows虛擬機中大多使用的是NTFS文件系統,因此可以根據NTFS中的MFT的順序分析出RAID條帶的大小以及RAID的走向。
-分析RAID是否存在掉線盤
鏡像完所有磁盤。后發現最后一塊硬盤中并沒有像其他硬盤一樣有大量的壞道。其中有大量未損壞扇區,這些未損壞扇區大多是全0扇區。因此可以判斷這塊硬盤是熱備盤。
2、重組RAID
根據分析出來的RAID結構重組RAID,能看到目錄結構。但是不確定是否為最新狀態,檢測幾個虛擬機發現有部分虛擬機正常,但也有很多虛擬機數據異常。初步判斷RAID中存在掉線的磁盤,依次將RAID中的每一塊磁盤踢掉,然后查看剛才數據異常的地方,未果。又仔細分析底層數據發現問題不是出在RAID層面,而是出在VMFS文件系統上。VMFS文件系統如果大于16TB的話會存在一些其他的記錄信息,因此在組建RAID的時候需要跳過這些記錄信息。再次重組RAID,查看以前數據異常的地方可以對上了。針對其中的一臺虛擬機做驗證,將所有磁盤加入RIAD中后,這臺虛擬機是可以啟動的,但缺盤的情況下啟動有問題。因此判斷整個RAID處在不缺盤的狀態為最佳。
五、驗證數據
1、驗證虛擬機
針對用戶較為重要的虛擬機做驗證,發現虛擬機大多都可以開機,可以進入登陸界面。有部分虛擬機開機藍屏或開機檢測磁盤,但是光盤修復之后都可以啟動。
部分虛擬機現象開機如下:
圖三: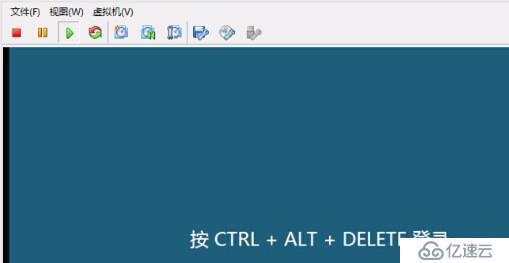
2、驗證數據庫
針對重要的虛擬機中的數據庫做驗證,發現數據庫都正常。其中有一個數據庫,據用戶描述是缺少部分數據,但是經過仔細核對后發現這些數據在數據庫中本來就不存在。通過查詢 master 數據庫中的系統視圖,查出原來的所有數據庫信息如下:
圖四:
3、檢測整個VMFS卷是否完整
由于虛擬機的數量很多,每臺都驗證的話,所需的時間會很長,因此我們對整個VMFS卷做檢測。在檢測VMFS卷的過程中發現有部分虛擬機或虛擬機的文件被破壞。列表如下:
圖五: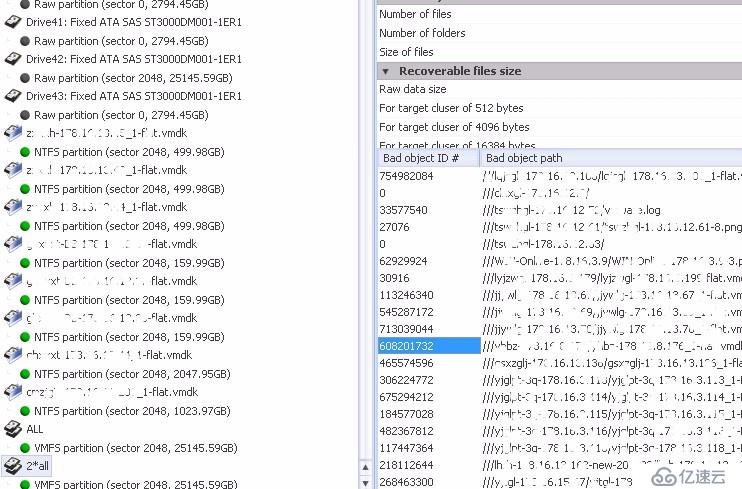
六、恢復數據
1、生成數據
北亞工程師跟客戶溝通并且描述了目前恢復的情況。用戶經過對幾臺重要的虛擬機驗證后,用戶反應恢復的數據可以接受,接著北亞工程師立即著手準備恢復所有數據。
先準備目標磁盤,使用一臺dell 的MD 1200加上11塊3T的硬盤組成一個RAID陣列。接著將重組的RAID數據鏡像到目標陣列上。然后利用專業的工具UFS解析整個VMFS文件系統。
2、嘗試掛載恢復的VMFS卷
將恢復好的VMFS卷連接到我們的虛擬化環境中的一臺ESXI5.5主機上,嘗試將其掛載到的ESXI5.5的環境中。但是由于版本(客戶的ESXI主機是5.0版本)原因或VMFS本身有損壞,導致其掛載不成功。繼續嘗試使用ESXI的命令掛載也不成功,于是放棄掛載VMFS卷。
七、移交數據
由于時間緊迫,先安排北亞工程師將MD 1200 陣列上的數據帶到用戶現場。然后使用專業工具”UFS”依次導出VMFS卷中的虛擬機。
1、將MD 1200陣列上的數據通過HBA卡連接到用戶的VCenter服務器上。
2、在VCenter服務器安裝“UFS”工具,然后使用“UFS”工具解釋VMFS卷。
3、使用“UFS”工具將VMFS卷中的虛擬機導入到VCenter服務器上。
4、使用VCenter的上傳功能將虛擬機上傳到ESXI的存儲中。
5、接著將上傳完的虛擬機添加到清單,開機驗證即可。
6、如果有虛擬機開機有問題,則嘗試使用命令行模式修復。或者重建虛擬機并將恢復的虛擬機磁盤(既VMDK文件)拷貝過去。
7、由于部分虛擬機的數據盤很大,而數據很少。像這種情況就可以直接導出數據,然后新建一個虛擬磁盤,最后將導出的數據拷貝至新建的虛擬磁盤中即可。
統計了一下整個存儲中虛擬機的數量,大約有200臺虛擬機。目前的情況只能通過上述方式將恢復的虛擬機一臺一臺的恢復到用戶的ESXI中。由于是通過網絡傳輸,因此整個遷移的過程中網絡是一個瓶頸。經過不斷的調試以及更換主機最終還是無法達到一個理想的狀態,由于時間緊張,最終還是決定在當前的環境遷移數據。
八、數據恢復總結
1、故障總結
所有磁盤壞道的規律如下表: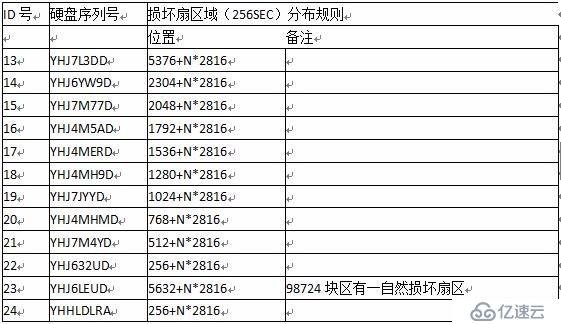
經過仔細分析后得出壞道的結論如下:
-除去SN:YHJ6LEUD上的一個自然壞道外,其余壞道均分布于RAID-6的Q校驗塊中。
-壞道區域多數表現為完整的256個扇區,正好當時創建RAID-6時的一個完整RAID塊大小。
-活動區域表現為壞道,非活動區域壞道有可能不出現,如熱備盤,上線不足10%,壞道數量就比其他在線盤少(熱備盤的鏡像4小時完成,其他有壞道盤大概花費40小時)
-其他非Q校驗區域完好,無任何故障。
結論:
通常情況,經如上壞道規則表現可推斷,壞道為控制器生成Q校驗,向硬盤下達IO指令時,可能表現為非標指令,硬盤內部處理異常,導致出現規律性壞道。
2、數據恢復總結
數據恢復過程中由于壞道數量太多,以致備份數據時花費了很長世間。整個存儲是由壞道引起的,導致最終恢復的數據有部分破壞,但不影響整體數據,最終的結果也在可接受范圍內。
整個恢復過程,用戶方要求緊急,我方也安排工程師加班加點,最終在最短的時間內將數據恢復出來。后續的數據遷移過程中由我方工程師和用戶方工程師配合完成。
九、項目成員?
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





