溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
人臉檢測中的AdaBoost算法,供大家參考,具體內容如下
第一章:引言
2017.7.31。英國測試人臉識別技術,不需要排隊購票就能刷臉進站。據BBC新聞報道,這項英國政府鐵路安全標準委員會資助的新技術,由布里斯托機器人實驗室(Bristol Robotics Laboratory) 負責開發。這個報道可能意味著我們將來的生活方式。雖然人臉識別技術已經研究了很多年了,比較成熟了,但是還遠遠不夠,我們以后的目標是通過識別面部表情來獲得人類心理想法。 長期以來,計算機就好像一個盲人,需要被動地接受由鍵盤、文件輸入的信息,而不能主動從這個世界獲取信息并自主處理。人們為了讓計算機看到這個世界并主動從這個世界尋找信息,發展了機器視覺;為了讓計算機自主處理和判斷所得到的信息,發展了人工智能科學。人們夢想,終有一天,人機之間的交流可以像人與人之間的交流一樣暢通和友好。 而這些技術實現的基礎是在人臉檢測上實現的,下面是我通過學習基于 AdaBoost 算法的人臉檢測,趙楠的論文的學習心得。
第二章:關于Adaptive Boosting
AdaBoost 全稱為Adaptive Boosting。Adaptively,即適應地,該方法根據弱學習的結果反饋適應地調整假設的錯誤率,所以Adaboost不需要預先知道假設的錯誤率下限。Boosting意思為提升、加強,現在一般指將弱學習提升為強學習的一類算法。實質上,AdaBoost算法是通過機器學習,將弱學習提升為強學習的一類算法的最典型代表。
第三章:AdaBoost算法檢測人臉的過程
先上一張完整的流程圖,下面我將對著這張圖作我的學習分享:

1.術語名詞解析:
弱學習,強學習:隨機猜測一個是或否的問題,將會有50%的正確率。如果一個假設能夠稍微地提高猜測正確的概率,那么這個假 設就是弱學習算法,得到這個算法的過程稱為弱學習。可以使用半自動化的方法為好幾個任務構造弱學習算法,構造過程需要數量巨大的假設集合,這個假設集合是基于某些簡單規則的組合和對樣本集的性能評估而生成的。如果一個假設能夠顯著地提高猜測正確的概率,那么這個假設就稱為強學習。特征模版:我們將使用簡單矩形組合作為我們的特征模板。這類特征模板都是由兩個或多個全等的矩形相鄰組合而成,特征模板內有白色和黑色兩種矩形(定義左上角的為白色,然后依次交錯),并將此特征模板的特征值定義為白色矩形像素和減去黑色矩形像素和。最簡單的 5 個特征模板:
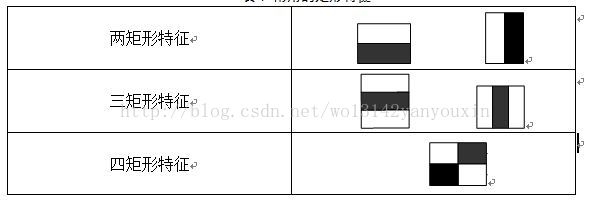
下面列出了,在不同子窗口大小內,特征的總數量:

積分圖:主要是為了利用積分圖計算矩形特征值,提高程序運行效率。下面給出非常形象的積分圖的來計算矩形特征值:
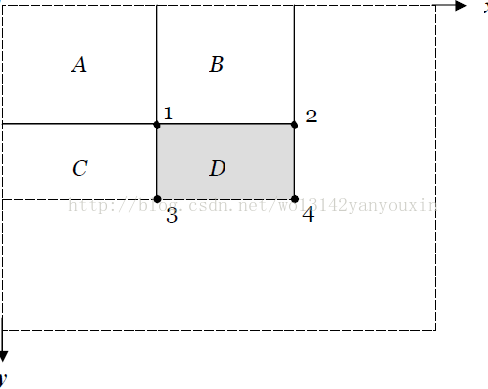
區域 D 的像素和可以用積分圖計算為: K1+K4 - (K2+K3)
K1=區域A 的像素值
K2=區域A 的像素值+區域B 的像素值
K3=區域A 的像素值+區域C 的像素值
K4 =區域A 的像素值+區域B 的像素值+區域C 的像素值+區域D 的像素值
2.算法基本描述
對照上面的流程圖:A給定一系列訓練樣本,B初始化權重,C歸一化權重,都挺好理解的。我現在需要著重說的是接下來的步驟,即如何選取,訓練弱分類器:
現在我們假設我們的計算機讀取一張圖片進來,在這張圖片上遍歷所有的特征,(例如20X20像素的圖片,一共有78460個特征),當遍歷到x個特征時,計算該特征在所有的訓練樣本中(人臉和非人臉圖)的特征值。并且將這些特征值排序,通過掃描一遍排好序的特征值,可以為這個特征確定一個最優的閾值,從而訓練成一個弱分類器。那么為什么掃描一遍就可以得出最優閾值?因為在掃描到每一個特征值時,當選取當前元素的特征值和它前面的一個特征值 之間的數作為閾值時,計算這個閾值所帶來的分類誤差為
e = min( S 1+ (T 2- S 2 ), S2 + (T 1- S 1 ))
其中:
全部人臉樣本的權重的和T 1
全部非人臉樣本的權重的和T 2
在此元素之前的人臉樣本的權重的和S 1
在此元素之前的非人臉樣本的權重的和S 2
將最小誤差記錄下來,選取該最小誤差的特征值,選取當前元素的特征值和它前面的一個特征值 之間的數作為閾值,那么x特征的最小誤差的弱分類器將出來了!以此類推,當遍歷了所以的特征了,就在這些弱分類器中找到誤差最小的分類器,就是最佳弱分類器。
接下來,就進入到調整最佳弱分類器的權重了。設置一個循環,用剛剛得到的最佳弱分類器去分類所有的訓練樣本,按照最上面的流程圖中的調整權重的部分來調整權重。
以上的步驟就是一個完整的adaboost算法的訓練過程!
最后,實驗結果表明,當T=200 時,構成的強分類器可以獲得很好的檢測效果。經過 200次迭代后,獲得了 200個最佳弱分類器 ,可以按照下面的方式組合成一個強分類器:
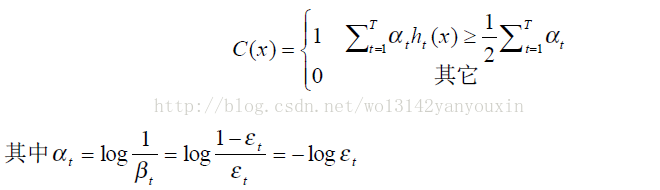
那么,這個強分類器對待一幅待檢測圖像時,相當于讓所有弱分類器投票,再對投票結果按照弱分類器的錯誤率加權求和,將投票加權求和的結果與平均投票結果比較得出最終的結果。
第4章、個人總結
前前后后將近花了3天時間來學習adaboost算法的人臉識別。在網上找了很多的資料,發現大部分關于每一個特征的弱分類器和所有圖像的最佳弱分類器的概念含糊不清,以及怎么用編程的思想來解讀這個算法的意識不明確,具體來說,只考慮算法的過程,而不考慮怎么用編程來實現這些過程。這也是我寫這個博客的主要目的。
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





